 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord Play for Playing Othello (Reverses)
Jul 18, 2022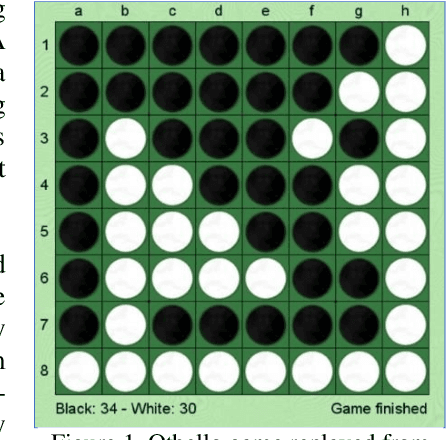
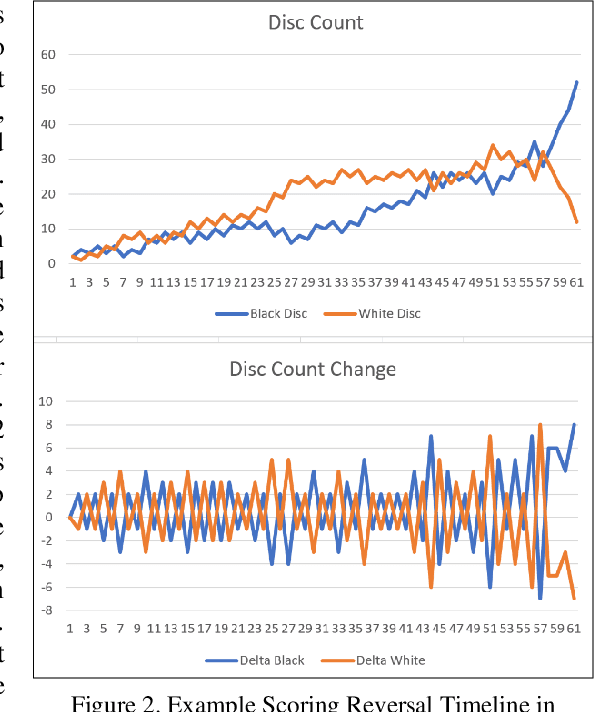
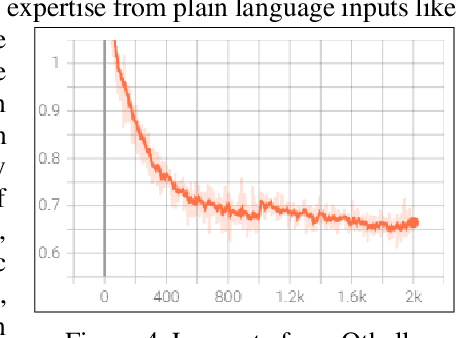
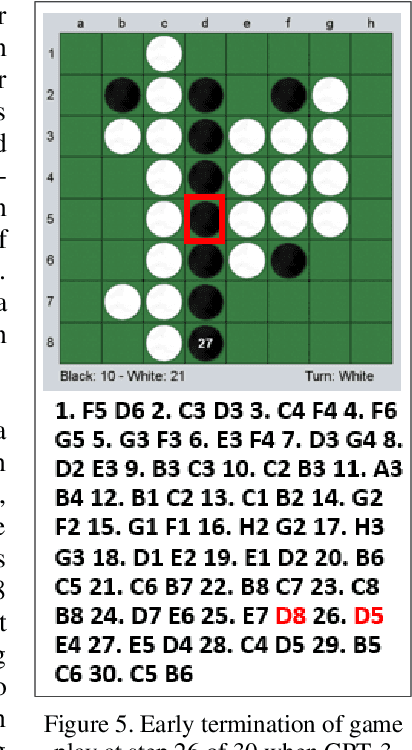
Language models like OpenAI's Generative Pre-Trained Transformers (GPT-2/3) capture the long-term correlations needed to generate text in a variety of domains (such as language translators) and recently in gameplay (chess, Go, and checkers). The present research applies both the larger (GPT-3) and smaller (GPT-2) language models to explore the complex strategies for the game of Othello (or Reverses). Given the game rules for rapid reversals of fortune, the language model not only represents a candidate predictor of the next move based on previous game moves but also avoids sparse rewards in gameplay. The language model automatically captures or emulates championship-level strategies. The fine-tuned GPT-2 model generates Othello games ranging from 13-71% completion, while the larger GPT-3 model reaches 41% of a complete game. Like previous work with chess and Go, these language models offer a novel way to generate plausible game archives, particularly for comparing opening moves across a larger sample than humanly possible to explore. A primary contribution of these models magnifies (by two-fold) the previous record for player archives (120,000 human games over 45 years from 1977-2022), thus supplying the research community with more diverse and original strategies for sampling with other reinforcement learning techniques.
Rock Hunting With Martian Machine Vision
Apr 09, 2021



The Mars Perseverance rover applies computer vision for navigation and hazard avoidance. The challenge to do onboard object recognition highlights the need for low-power, customized training, often including low-contrast backgrounds. We investigate deep learning methods for the classification and detection of Martian rocks. We report greater than 97% accuracy for binary classifications (rock vs. rover). We fine-tune a detector to render geo-located bounding boxes while counting rocks. For these models to run on microcontrollers, we shrink and quantize the neural networks' weights and demonstrate a low-power rock hunter with faster frame rates (1 frame per second) but lower accuracy (37%).
Reading Isn't Believing: Adversarial Attacks On Multi-Modal Neurons
Mar 18, 2021

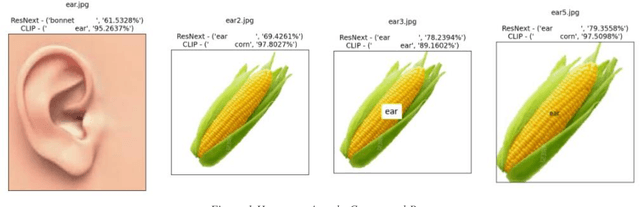

With Open AI's publishing of their CLIP model (Contrastive Language-Image Pre-training), multi-modal neural networks now provide accessible models that combine reading with visual recognition. Their network offers novel ways to probe its dual abilities to read text while classifying visual objects. This paper demonstrates several new categories of adversarial attacks, spanning basic typographical, conceptual, and iconographic inputs generated to fool the model into making false or absurd classifications. We demonstrate that contradictory text and image signals can confuse the model into choosing false (visual) options. Like previous authors, we show by example that the CLIP model tends to read first, look later, a phenomenon we describe as reading isn't believing.
Image Classifiers for Network Intrusions
Mar 13, 2021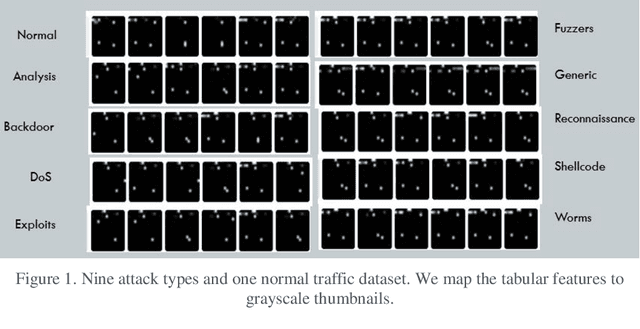
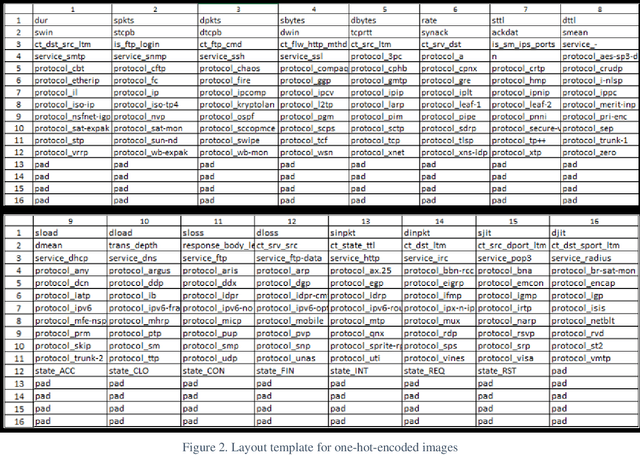
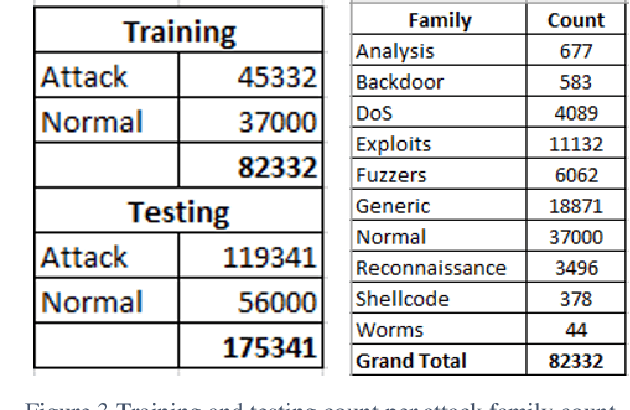
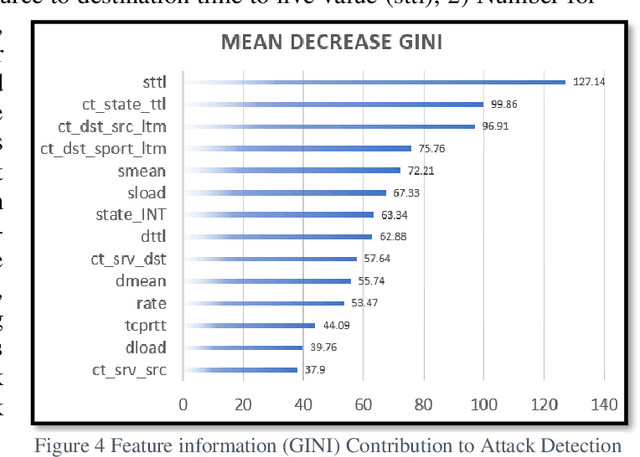
This research recasts the network attack dataset from UNSW-NB15 as an intrusion detection problem in image space. Using one-hot-encodings, the resulting grayscale thumbnails provide a quarter-million examples for deep learning algorithms. Applying the MobileNetV2's convolutional neural network architecture, the work demonstrates a 97% accuracy in distinguishing normal and attack traffic. Further class refinements to 9 individual attack families (exploits, worms, shellcodes) show an overall 56% accuracy. Using feature importance rank, a random forest solution on subsets show the most important source-destination factors and the least important ones as mainly obscure protocols. The dataset is available on Kaggle.
Virus-MNIST: A Benchmark Malware Dataset
Feb 28, 2021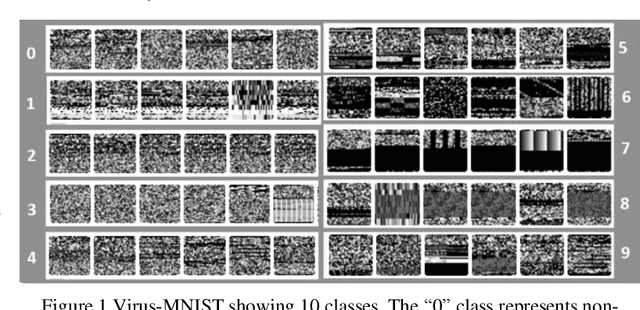
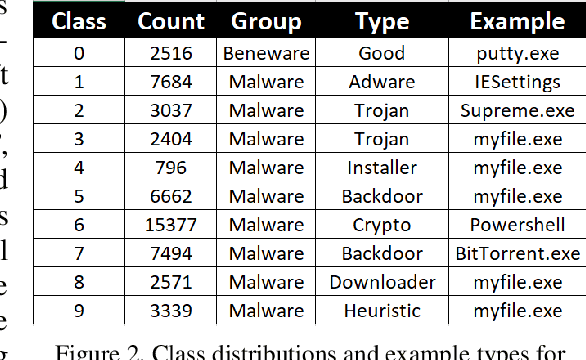
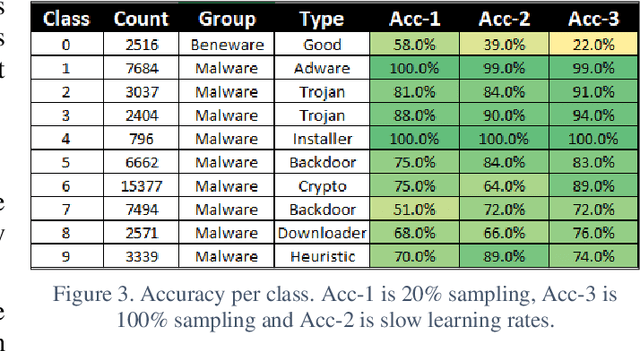
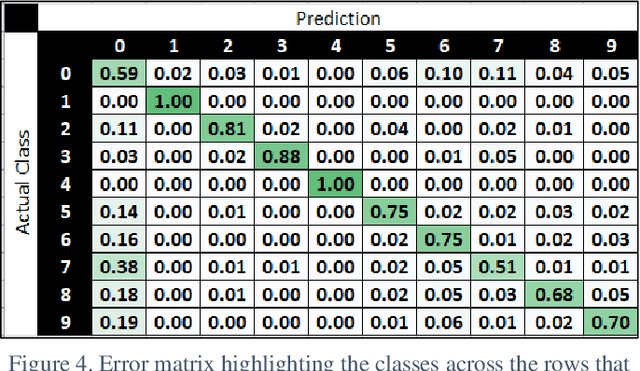
The short note presents an image classification dataset consisting of 10 executable code varieties and approximately 50,000 virus examples. The malicious classes include 9 families of computer viruses and one benign set. The image formatting for the first 1024 bytes of the Portable Executable (PE) mirrors the familiar MNIST handwriting dataset, such that most of the previously explored algorithmic methods can transfer with minor modifications. The designation of 9 virus families for malware derives from unsupervised learning of class labels; we discover the families with KMeans clustering that excludes the non-malicious examples. As a benchmark using deep learning methods (MobileNetV2), we find an overall 80% accuracy for virus identification by families when beneware is included. We also find that once a positive malware detection occurs (by signature or heuristics), the projection of the first 1024 bytes into a thumbnail image can classify with 87% accuracy the type of virus. The work generalizes what other malware investigators have demonstrated as promising convolutional neural networks originally developed to solve image problems but applied to a new abstract domain in pixel bytes from executable files. The dataset is available on Kaggle and Github.
Overhead MNIST: A Benchmark Satellite Dataset
Feb 08, 2021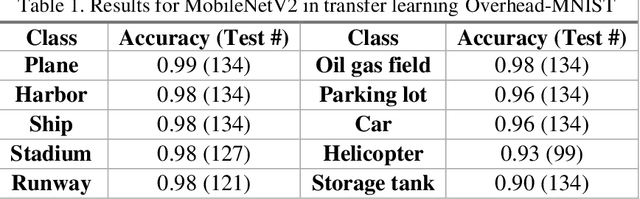

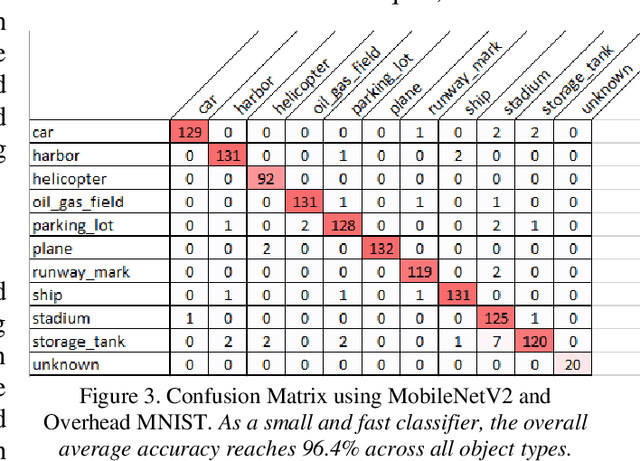
The research presents an overhead view of 10 important objects and follows the general formatting requirements of the most popular machine learning task: digit recognition with MNIST. This dataset offers a public benchmark extracted from over a million human-labelled and curated examples. The work outlines the key multi-class object identification task while matching with prior work in handwriting, cancer detection, and retail datasets. A prototype deep learning approach with transfer learning and convolutional neural networks (MobileNetV2) correctly identifies the ten overhead classes with an average accuracy of 96.7%. This model exceeds the peak human performance of 93.9%. For upgrading satellite imagery and object recognition, this new dataset benefits diverse endeavors such as disaster relief, land use management, and other traditional remote sensing tasks. The work extends satellite benchmarks with new capabilities to identify efficient and compact algorithms that might work on-board small satellites, a practical task for future multi-sensor constellations. The dataset is available on Kaggle and Github.