 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Extreme Rotation Estimation using Dense Correlation Volumes
Apr 28, 2021




We present a technique for estimating the relative 3D rotation of an RGB image pair in an extreme setting, where the images have little or no overlap. We observe that, even when images do not overlap, there may be rich hidden cues as to their geometric relationship, such as light source directions, vanishing points, and symmetries present in the scene. We propose a network design that can automatically learn such implicit cues by comparing all pairs of points between the two input images. Our method therefore constructs dense feature correlation volumes and processes these to predict relative 3D rotations. Our predictions are formed over a fine-grained discretization of rotations, bypassing difficulties associated with regressing 3D rotations. We demonstrate our approach on a large variety of extreme RGB image pairs, including indoor and outdoor images captured under different lighting conditions and geographic locations. Our evaluation shows that our model can successfully estimate relative rotations among non-overlapping images without compromising performance over overlapping image pairs.
Forgery Detection in a Questioned Hyperspectral Document Image using K-means Clustering
Jun 29, 2020
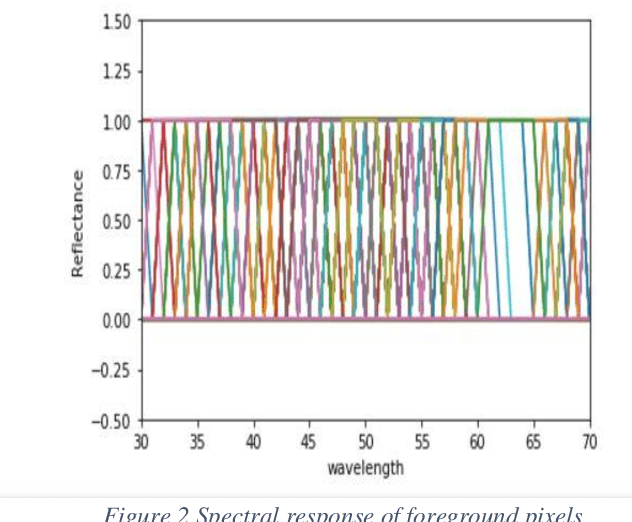

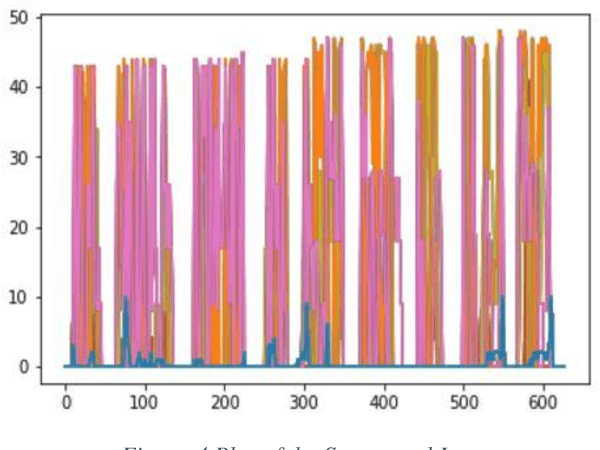
Hyperspectral imaging allows for analysis of images in several hundred of spectral bands depending on the spectral resolution of the imaging sensor. Hyperspectral document image is the one which has been captured by a hyperspectral camera so that the document can be observed in the different bands on the basis of their unique spectral signatures. To detect the forgery in a document various Ink mismatch detection techniques based on hyperspectral imaging have presented vast potential in differentiating visually similar inks. Inks of different materials exhibit different spectral signature even if they have the same color. Hyperspectral analysis of document images allows identification and discrimination of visually similar inks. Based on this analysis forensic experts can identify the authenticity of the document. In this paper an extensive ink mismatch detection technique is presented which uses KMean Clustering to identify different inks on the basis of their unique spectral response and separates them into different clusters.
End-to-End Deep Convolutional Active Contours for Image Segmentation
Sep 29, 2019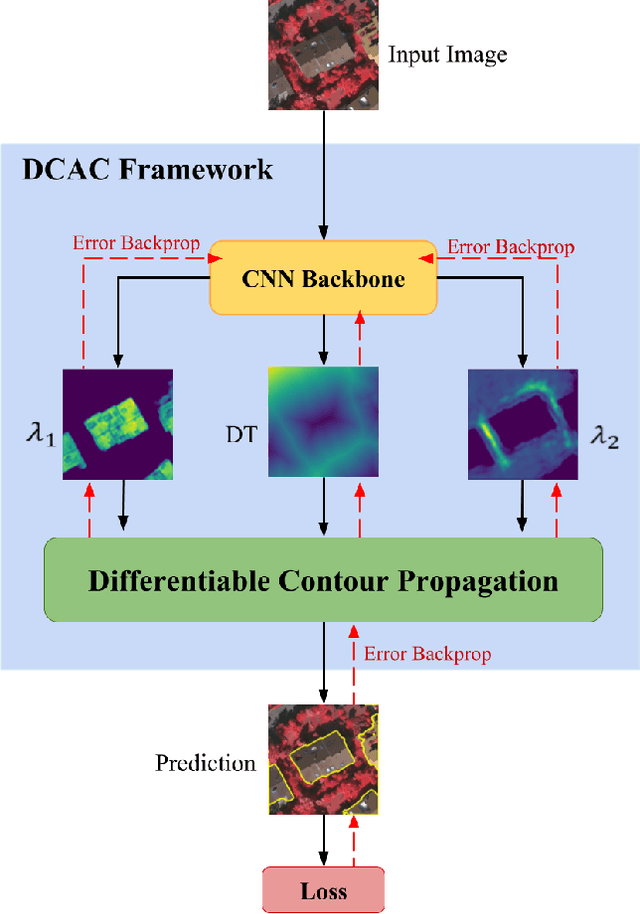
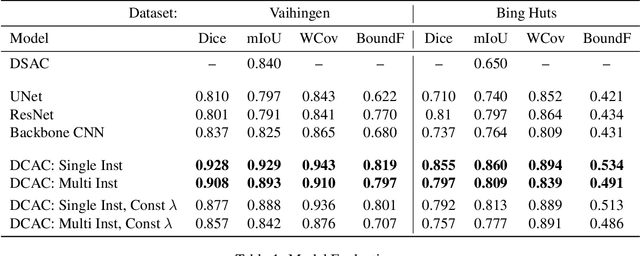
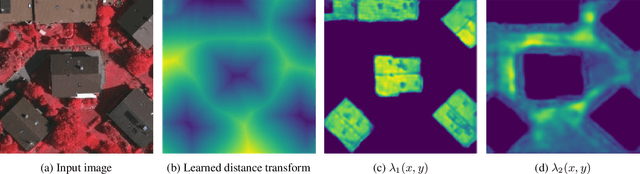
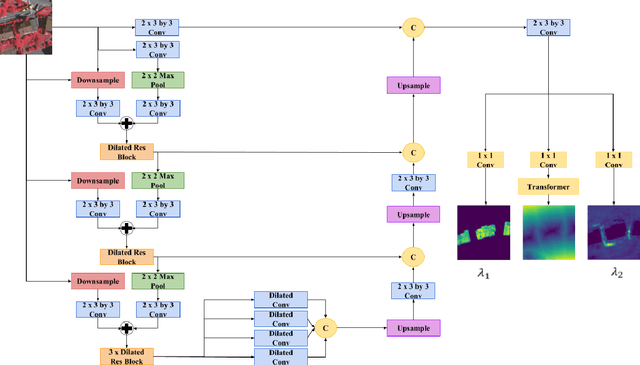
The Active Contour Model (ACM) is a standard image analysis technique whose numerous variants have attracted an enormous amount of research attention across multiple fields. Incorrectly, however, the ACM's differential-equation-based formulation and prototypical dependence on user initialization have been regarded as being largely incompatible with the recently popular deep learning approaches to image segmentation. This paper introduces the first tight unification of these two paradigms. In particular, we devise Deep Convolutional Active Contours (DCAC), a truly end-to-end trainable image segmentation framework comprising a Convolutional Neural Network (CNN) and an ACM with learnable parameters. The ACM's Eulerian energy functional includes per-pixel parameter maps predicted by the backbone CNN, which also initializes the ACM. Importantly, both the CNN and ACM components are fully implemented in TensorFlow, and the entire DCAC architecture is end-to-end automatically differentiable and backpropagation trainable without user intervention. As a challenging test case, we tackle the problem of building instance segmentation in aerial images and evaluate DCAC on two publicly available datasets, Vaihingen and Bing Huts. Our reseults demonstrate that, for building segmentation, the DCAC establishes a new state-of-the-art performance by a wide margin.
Towards Better Model Understanding with Path-Sufficient Explanations
Sep 13, 2021

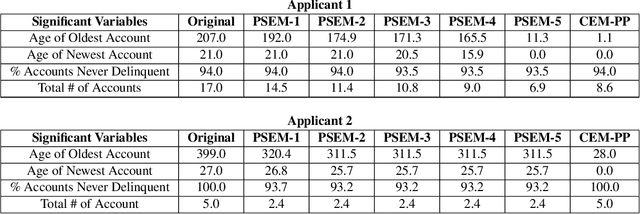

Feature based local attribution methods are amongst the most prevalent in explainable artificial intelligence (XAI) literature. Going beyond standard correlation, recently, methods have been proposed that highlight what should be minimally sufficient to justify the classification of an input (viz. pertinent positives). While minimal sufficiency is an attractive property, the resulting explanations are often too sparse for a human to understand and evaluate the local behavior of the model, thus making it difficult to judge its overall quality. To overcome these limitations, we propose a novel method called Path-Sufficient Explanations Method (PSEM) that outputs a sequence of sufficient explanations for a given input of strictly decreasing size (or value) -- from original input to a minimally sufficient explanation -- which can be thought to trace the local boundary of the model in a smooth manner, thus providing better intuition about the local model behavior for the specific input. We validate these claims, both qualitatively and quantitatively, with experiments that show the benefit of PSEM across all three modalities (image, tabular and text). A user study depicts the strength of the method in communicating the local behavior, where (many) users are able to correctly determine the prediction made by a model.
ViPTT-Net: Video pretraining of spatio-temporal model for tuberculosis type classification from chest CT scans
May 26, 2021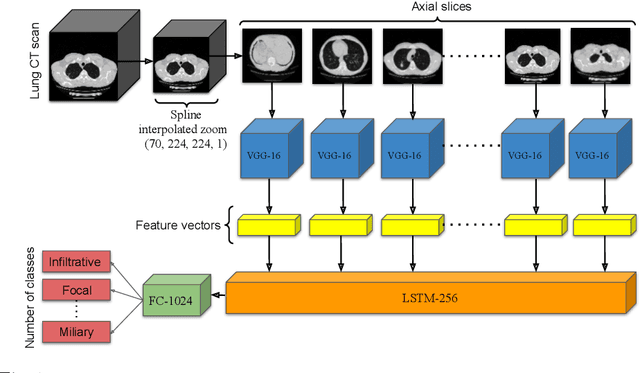
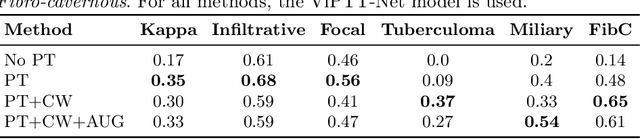
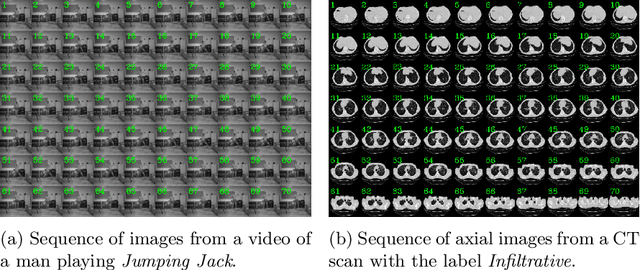

Pretraining has sparked groundswell of interest in deep learning workflows to learn from limited data and improve generalization. While this is common for 2D image classification tasks, its application to 3D medical imaging tasks like chest CT interpretation is limited. We explore the idea of whether pretraining a model on realistic videos could improve performance rather than training the model from scratch, intended for tuberculosis type classification from chest CT scans. To incorporate both spatial and temporal features, we develop a hybrid convolutional neural network (CNN) and recurrent neural network (RNN) model, where the features are extracted from each axial slice of the CT scan by a CNN, these sequence of image features are input to a RNN for classification of the CT scan. Our model termed as ViPTT-Net, was trained on over 1300 video clips with labels of human activities, and then fine-tuned on chest CT scans with labels of tuberculosis type. We find that pretraining the model on videos lead to better representations and significantly improved model validation performance from a kappa score of 0.17 to 0.35, especially for under-represented class samples. Our best method achieved 2nd place in the ImageCLEF 2021 Tuberculosis - TBT classification task with a kappa score of 0.20 on the final test set with only image information (without using clinical meta-data). All codes and models are made available.
Stereo Computation for a Single Mixture Image
Aug 27, 2018

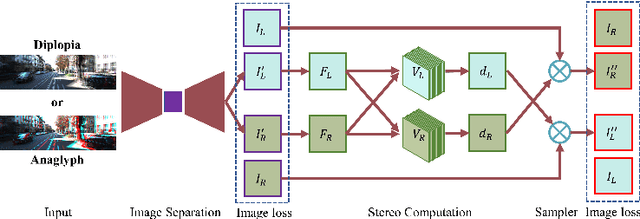
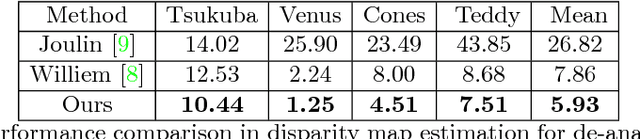
This paper proposes an original problem of \emph{stereo computation from a single mixture image}-- a challenging problem that had not been researched before. The goal is to separate (\ie, unmix) a single mixture image into two constitute image layers, such that the two layers form a left-right stereo image pair, from which a valid disparity map can be recovered. This is a severely illposed problem, from one input image one effectively aims to recover three (\ie, left image, right image and a disparity map). In this work we give a novel deep-learning based solution, by jointly solving the two subtasks of image layer separation as well as stereo matching. Training our deep net is a simple task, as it does not need to have disparity maps. Extensive experiments demonstrate the efficacy of our method.
LocalNorm: Robust Image Classification through Dynamically Regularized Normalization
Feb 19, 2019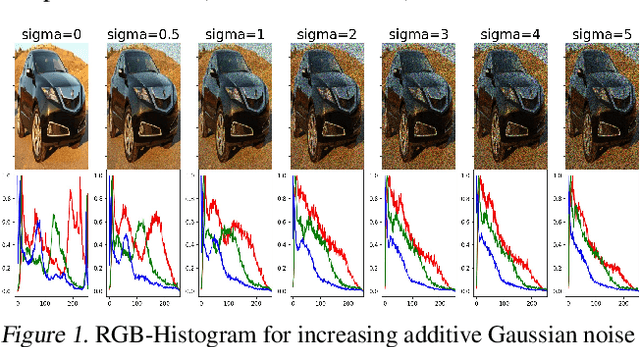
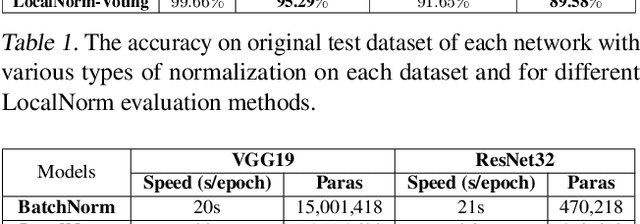

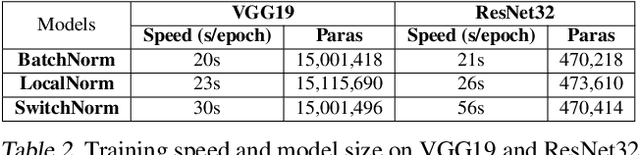
While modern convolutional neural networks achieve outstanding accuracy on many image classification tasks, they are, compared to humans, much more sensitive to image degradation. Here, we describe a variant of Batch Normalization, LocalNorm, that regularizes the normalization layer in the spirit of Dropout while dynamically adapting to the local image intensity and contrast at test-time. We show that the resulting deep neural networks are much more resistant to noise-induced image degradation, improving accuracy by up to three times, while achieving the same or slightly better accuracy on non-degraded classical benchmarks. In computational terms, LocalNorm adds negligible training cost and little or no cost at inference time, and can be applied to already-trained networks in a straightforward manner.
Quantum Deep Learning: Sampling Neural Nets with a Quantum Annealer
Jul 19, 2021
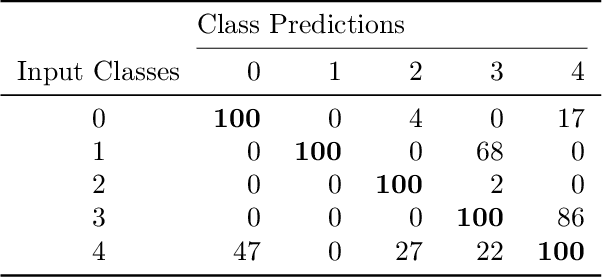
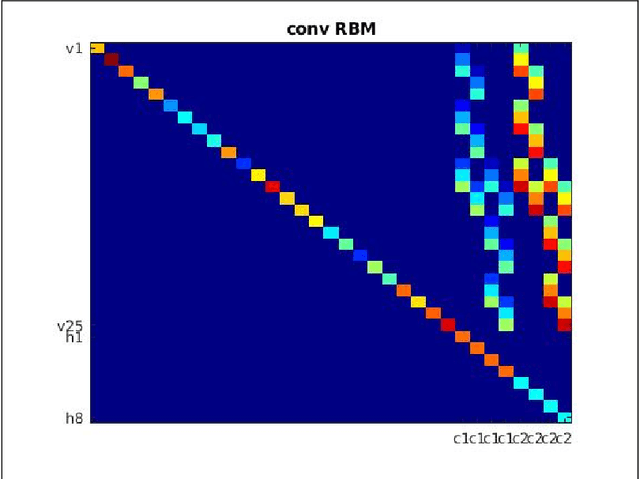
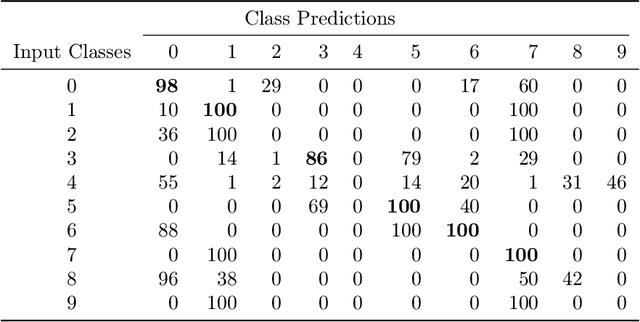
We demonstrate the feasibility of framing a classically learned deep neural network as an energy based model that can be processed on a one-step quantum annealer in order to exploit fast sampling times. We propose approaches to overcome two hurdles for high resolution image classification on a quantum processing unit (QPU): the required number and binary nature of the model states. With this novel method we successfully transfer a convolutional neural network to the QPU and show the potential for classification speedup of at least one order of magnitude.
Anabranch Network for Camouflaged Object Segmentation
May 20, 2021

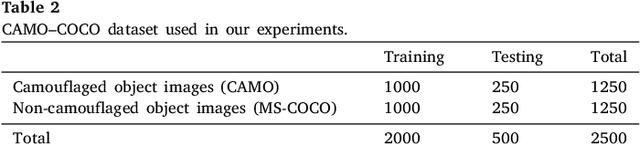
Camouflaged objects attempt to conceal their texture into the background and discriminating them from the background is hard even for human beings. The main objective of this paper is to explore the camouflaged object segmentation problem, namely, segmenting the camouflaged object(s) for a given image. This problem has not been well studied in spite of a wide range of potential applications including the preservation of wild animals and the discovery of new species, surveillance systems, search-and-rescue missions in the event of natural disasters such as earthquakes, floods or hurricanes. This paper addresses a new challenging problem of camouflaged object segmentation. To address this problem, we provide a new image dataset of camouflaged objects for benchmarking purposes. In addition, we propose a general end-to-end network, called the Anabranch Network, that leverages both classification and segmentation tasks. Different from existing networks for segmentation, our proposed network possesses the second branch for classification to predict the probability of containing camouflaged object(s) in an image, which is then fused into the main branch for segmentation to boost up the segmentation accuracy. Extensive experiments conducted on the newly built dataset demonstrate the effectiveness of our network using various fully convolutional networks. \url{https://sites.google.com/view/ltnghia/research/camo}
* Published in CVIU 2019. Project page: https://sites.google.com/view/ltnghia/research/camo
Physics-Informed Deep Reversible Regression Model for Temperature Field Reconstruction of Heat-Source Systems
Jul 05, 2021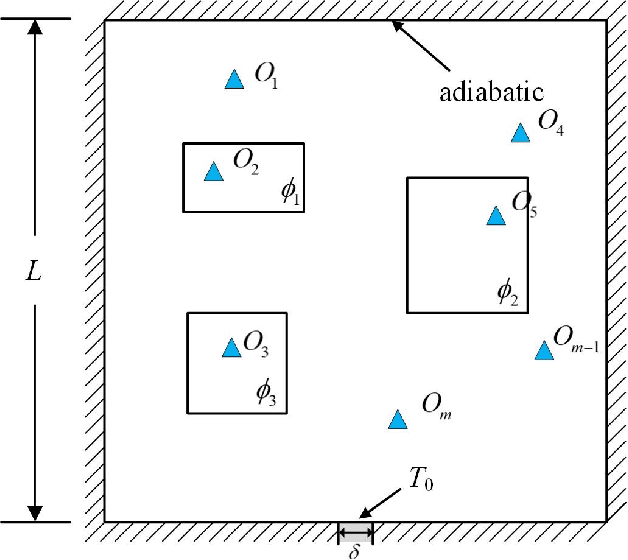
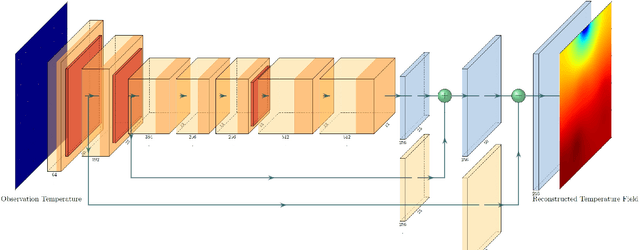
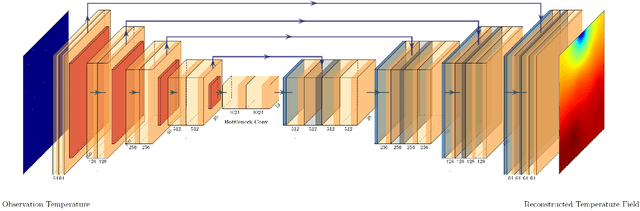
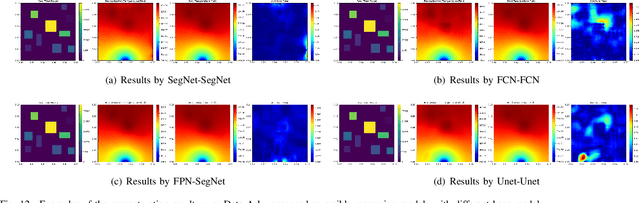
Temperature monitoring during the life time of heat source components in engineering systems becomes essential to guarantee the normal work and the working life of these components. However, prior methods, which mainly use the interpolate estimation to reconstruct the temperature field from limited monitoring points, require large amounts of temperature tensors for an accurate estimation. This may decrease the availability and reliability of the system and sharply increase the monitoring cost. To solve this problem, this work develops a novel physics-informed deep reversible regression models for temperature field reconstruction of heat-source systems (TFR-HSS), which can better reconstruct the temperature field with limited monitoring points unsupervisedly. First, we define the TFR-HSS task mathematically, and numerically model the task, and hence transform the task as an image-to-image regression problem. Then this work develops the deep reversible regression model which can better learn the physical information, especially over the boundary. Finally, considering the physical characteristics of heat conduction as well as the boundary conditions, this work proposes the physics-informed reconstruction loss including four training losses and jointly learns the deep surrogate model with these losses unsupervisedly. Experimental studies have conducted over typical two-dimensional heat-source systems to demonstrate the effectiveness of the proposed method.