 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Two-dimensional Deep Regression for Early Yield Prediction of Winter Wheat
Nov 15, 2021
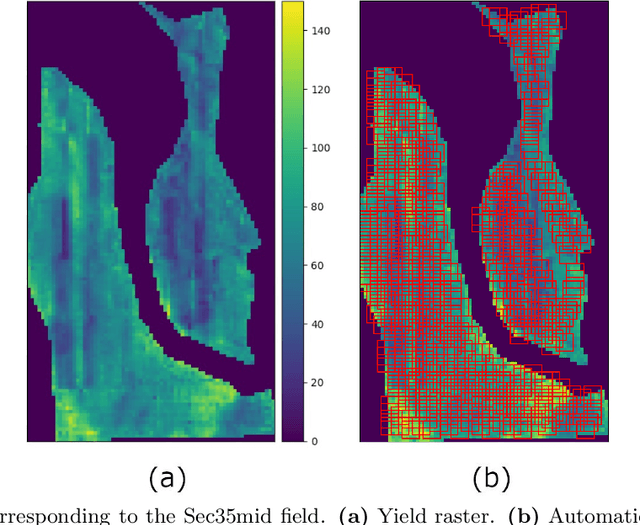
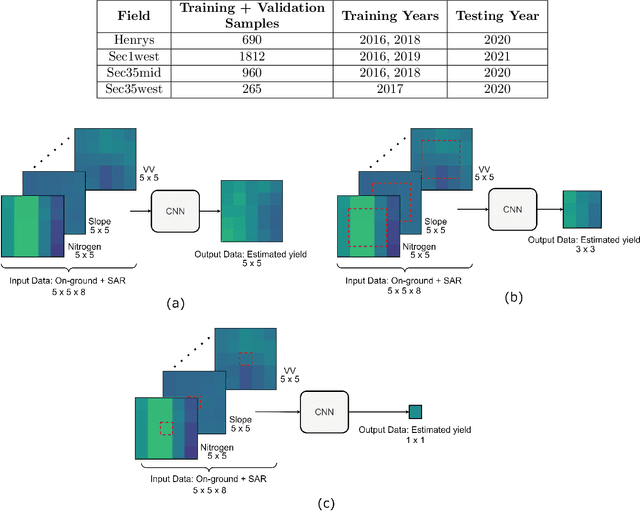
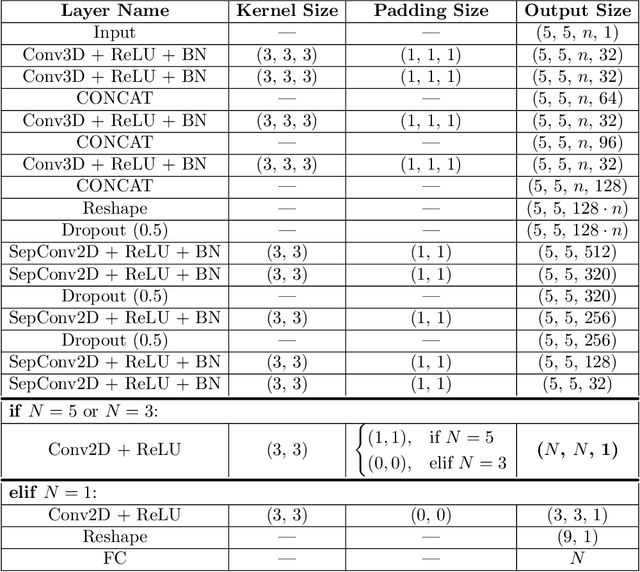
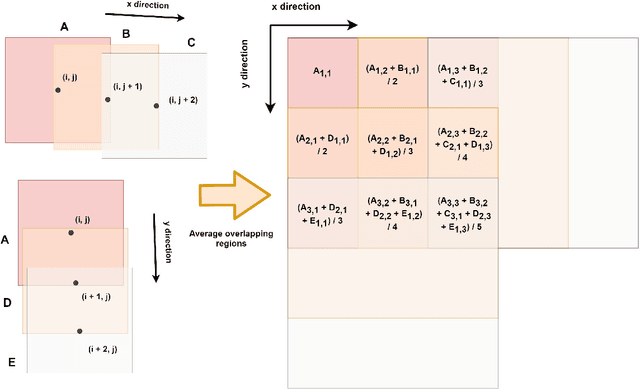
Crop yield prediction is one of the tasks of Precision Agriculture that can be automated based on multi-source periodic observations of the fields. We tackle the yield prediction problem using a Convolutional Neural Network (CNN) trained on data that combines radar satellite imagery and on-ground information. We present a CNN architecture called Hyper3DNetReg that takes in a multi-channel input image and outputs a two-dimensional raster, where each pixel represents the predicted yield value of the corresponding input pixel. We utilize radar data acquired from the Sentinel-1 satellites, while the on-ground data correspond to a set of six raster features: nitrogen rate applied, precipitation, slope, elevation, topographic position index (TPI), and aspect. We use data collected during the early stage of the winter wheat growing season (March) to predict yield values during the harvest season (August). We present experiments over four fields of winter wheat and show that our proposed methodology yields better results than five compared methods, including multiple linear regression, an ensemble of feedforward networks using AdaBoost, a stacked autoencoder, and two other CNN architectures.
ZFlow: Gated Appearance Flow-based Virtual Try-on with 3D Priors
Sep 14, 2021
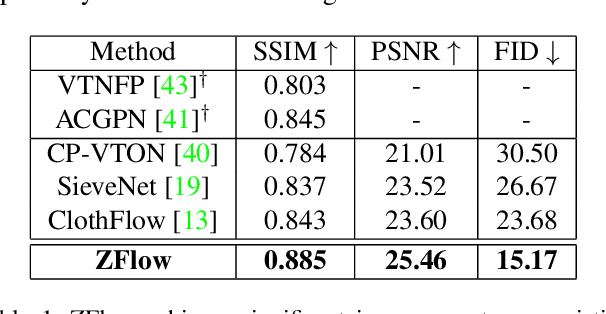
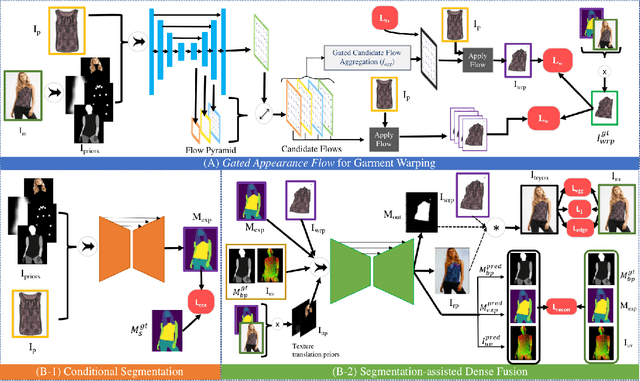
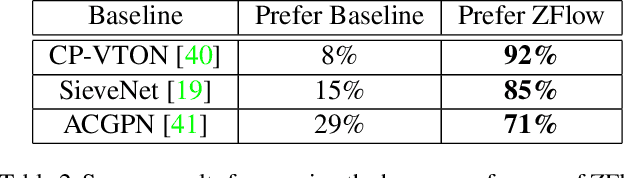
Image-based virtual try-on involves synthesizing perceptually convincing images of a model wearing a particular garment and has garnered significant research interest due to its immense practical applicability. Recent methods involve a two stage process: i) warping of the garment to align with the model ii) texture fusion of the warped garment and target model to generate the try-on output. Issues arise due to the non-rigid nature of garments and the lack of geometric information about the model or the garment. It often results in improper rendering of granular details. We propose ZFlow, an end-to-end framework, which seeks to alleviate these concerns regarding geometric and textural integrity (such as pose, depth-ordering, skin and neckline reproduction) through a combination of gated aggregation of hierarchical flow estimates termed Gated Appearance Flow, and dense structural priors at various stage of the network. ZFlow achieves state-of-the-art results as observed qualitatively, and on quantitative benchmarks of image quality (PSNR, SSIM, and FID). The paper presents extensive comparisons with other existing solutions including a detailed user study and ablation studies to gauge the effect of each of our contributions on multiple datasets.
IC-U-Net: A U-Net-based Denoising Autoencoder Using Mixtures of Independent Components for Automatic EEG Artifact Removal
Nov 22, 2021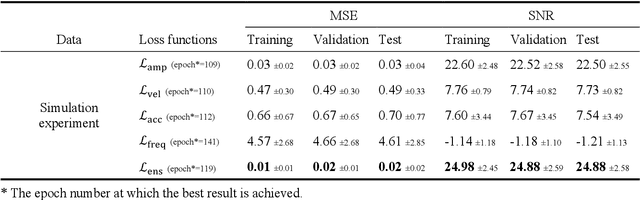
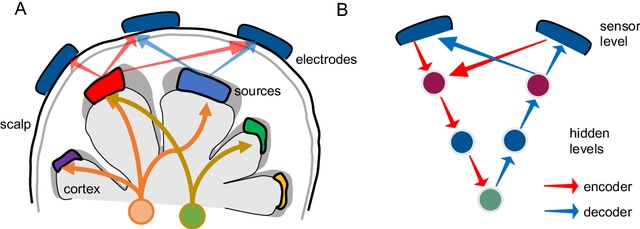
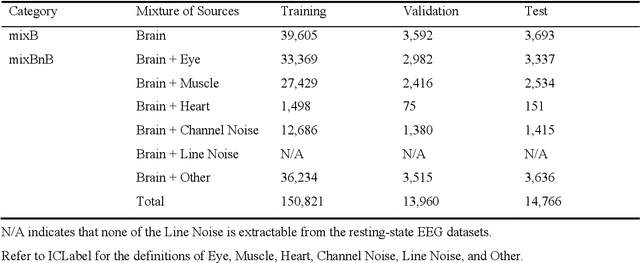
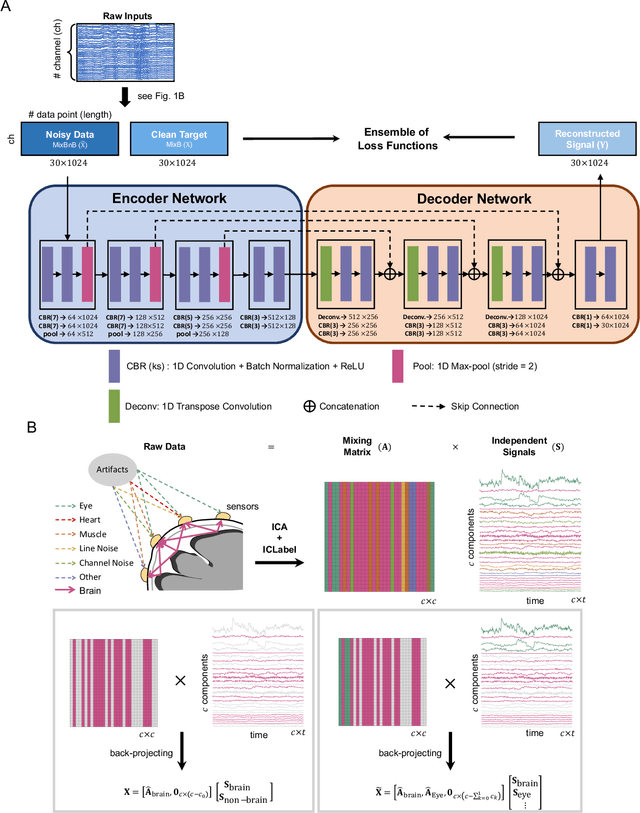
Electroencephalography (EEG) signals are often contaminated with artifacts. It is imperative to develop a practical and reliable artifact removal method to prevent misinterpretations of neural signals and underperformance of brain-computer interfaces. This study developed a new artifact removal method, IC-U-Net, which is based on the U-Net architecture for removing pervasive EEG artifacts and reconstructing brain sources. The IC-U-Net was trained using mixtures of brain and non-brain sources decomposed by independent component analysis and employed an ensemble of loss functions to model complex signal fluctuations in EEG recordings. The effectiveness of the proposed method in recovering brain sources and removing various artifacts (e.g., eye blinks/movements, muscle activities, and line/channel noises) was demonstrated in a simulation study and three real-world EEG datasets collected at rest and while driving and walking. IC-U-Net is user-friendly and publicly available, does not require parameter tuning or artifact type designations, and has no limitations on channel numbers. Given the increasing need to image natural brain dynamics in a mobile setting, IC-U-Net offers a promising end-to-end solution for automatically removing artifacts from EEG recordings.
Common Language for Goal-Oriented Semantic Communications: A Curriculum Learning Framework
Nov 15, 2021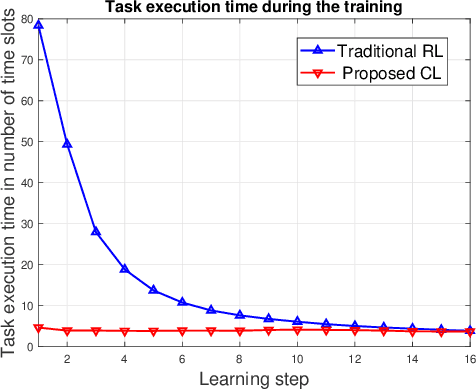
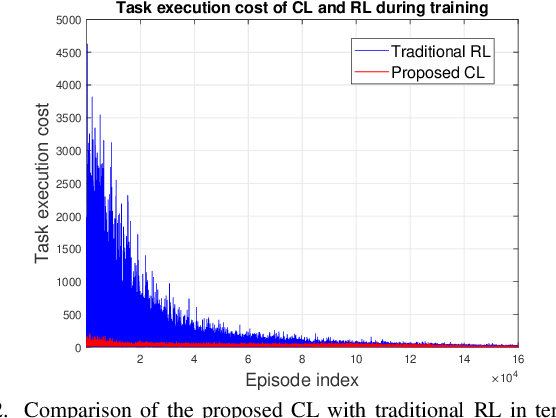
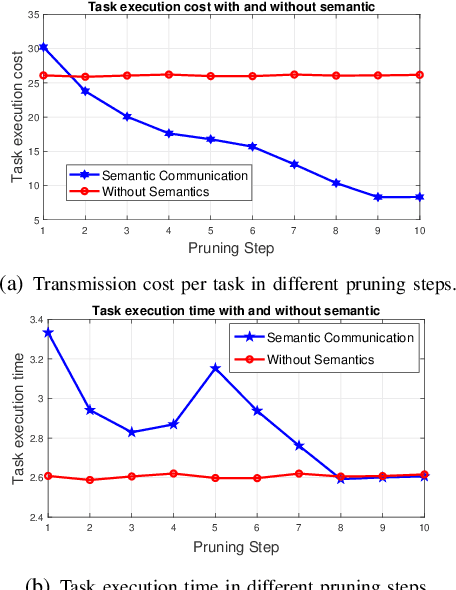
Semantic communications will play a critical role in enabling goal-oriented services over next-generation wireless systems. However, most prior art in this domain is restricted to specific applications (e.g., text or image), and it does not enable goal-oriented communications in which the effectiveness of the transmitted information must be considered along with the semantics so as to execute a certain task. In this paper, a comprehensive semantic communications framework is proposed for enabling goal-oriented task execution. To capture the semantics between a speaker and a listener, a common language is defined using the concept of beliefs to enable the speaker to describe the environment observations to the listener. Then, an optimization problem is posed to choose the minimum set of beliefs that perfectly describes the observation while minimizing the task execution time and transmission cost. A novel top-down framework that combines curriculum learning (CL) and reinforcement learning (RL) is proposed to solve this problem. Simulation results show that the proposed CL method outperforms traditional RL in terms of convergence time, task execution time, and transmission cost during training.
Estimation of excess air coefficient on coal combustion processes via gauss model and artificial neural network
Jul 23, 2021

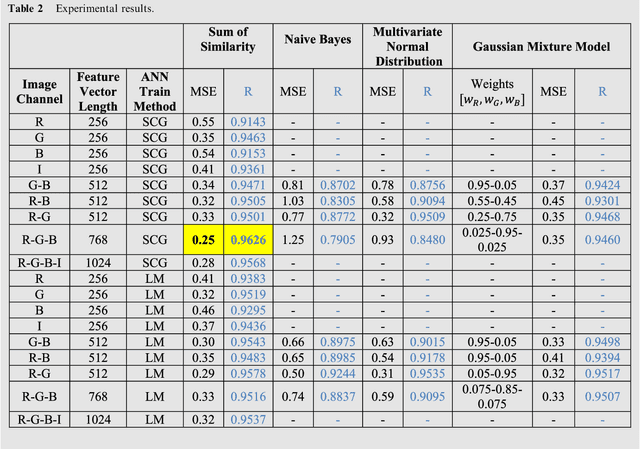

It is no doubt that the most important contributing cause of global efficiency of coal fired thermal systems is combustion efficiency. In this study, the relationship between the flame image obtained by a CCD camera and the excess air coefficient ({\lambda}) has been modelled. The model has been obtained with a three-stage approach: 1) Data collection and synchronization: Obtaining the flame images by means of a CCD camera mounted on a 10 cm diameter observation port, {\lambda} data has been coordinately measured and recorded by the flue gas analyzer. 2) Feature extraction: Gridding the flame image, it is divided into small pieces. The uniformity of each piece to the optimal flame image has been calculated by means of modelling with single and multivariable Gaussian, calculating of color probabilities and Gauss mixture approach. 3) Matching and testing: A multilayer artificial neural network (ANN) has been used for the matching of feature-{\lambda}.
Painting Style-Aware Manga Colorization Based on Generative Adversarial Networks
Jul 16, 2021
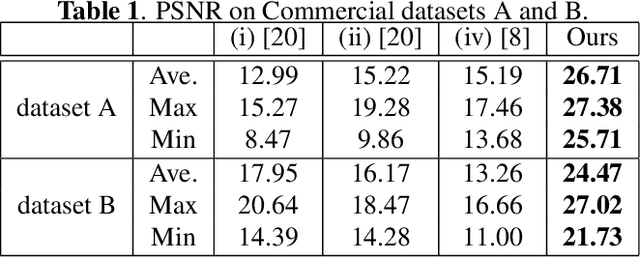
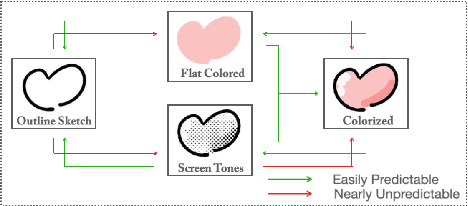
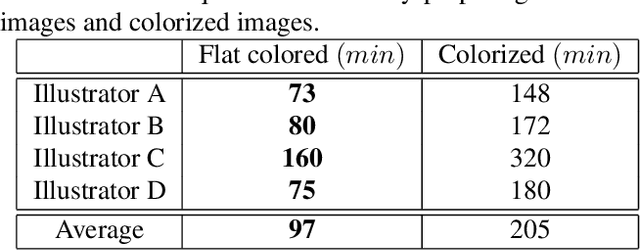
Japanese comics (called manga) are traditionally created in monochrome format. In recent years, in addition to monochrome comics, full color comics, a more attractive medium, have appeared. Unfortunately, color comics require manual colorization, which incurs high labor costs. Although automatic colorization methods have been recently proposed, most of them are designed for illustrations, not for comics. Unlike illustrations, since comics are composed of many consecutive images, the painting style must be consistent. To realize consistent colorization, we propose here a semi-automatic colorization method based on generative adversarial networks (GAN); the method learns the painting style of a specific comic from small amount of training data. The proposed method takes a pair of a screen tone image and a flat colored image as input, and outputs a colorized image. Experiments show that the proposed method achieves better performance than the existing alternatives.
PACE: Posthoc Architecture-Agnostic Concept Extractor for Explaining CNNs
Aug 31, 2021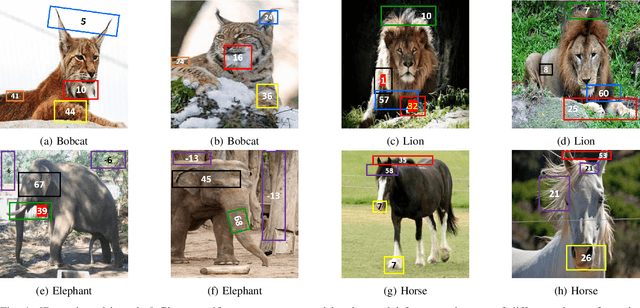
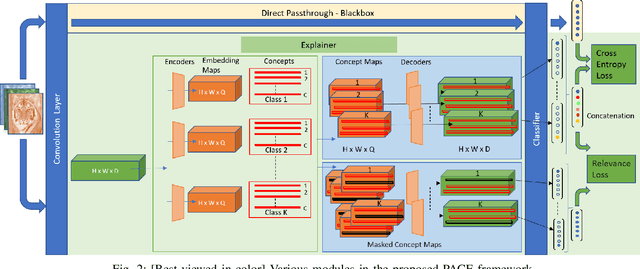
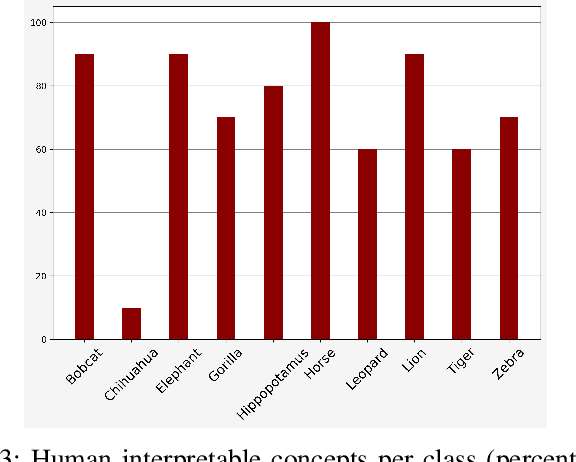

Deep CNNs, though have achieved the state of the art performance in image classification tasks, remain a black-box to a human using them. There is a growing interest in explaining the working of these deep models to improve their trustworthiness. In this paper, we introduce a Posthoc Architecture-agnostic Concept Extractor (PACE) that automatically extracts smaller sub-regions of the image called concepts relevant to the black-box prediction. PACE tightly integrates the faithfulness of the explanatory framework to the black-box model. To the best of our knowledge, this is the first work that extracts class-specific discriminative concepts in a posthoc manner automatically. The PACE framework is used to generate explanations for two different CNN architectures trained for classifying the AWA2 and Imagenet-Birds datasets. Extensive human subject experiments are conducted to validate the human interpretability and consistency of the explanations extracted by PACE. The results from these experiments suggest that over 72% of the concepts extracted by PACE are human interpretable.
Learned holographic light transport
Aug 01, 2021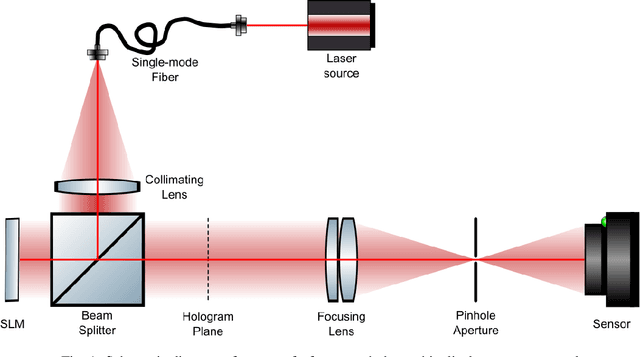

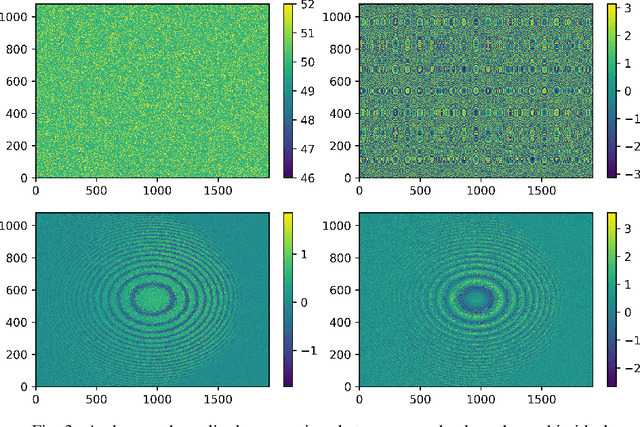

Computer-Generated Holography (CGH) algorithms often fall short in matching simulations with results from a physical holographic display. Our work addresses this mismatch by learning the holographic light transport in holographic displays. Using a camera and a holographic display, we capture the image reconstructions of optimized holograms that rely on ideal simulations to generate a dataset. Inspired by the ideal simulations, we learn a complex-valued convolution kernel that can propagate given holograms to captured photographs in our dataset. Our method can dramatically improve simulation accuracy and image quality in holographic displays while paving the way for physically informed learning approaches.
Analyzing Images for Music Recommendation
May 15, 2021
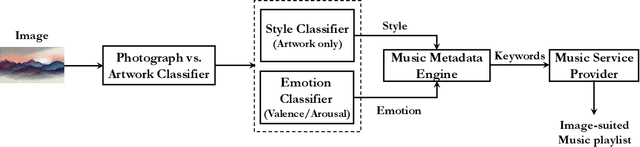


Experiencing images with suitable music can greatly enrich the overall user experience. The proposed image analysis method treats an artwork image differently from a photograph image. Automatic image classification is performed using deep-learning based models. An illustrative analysis showcasing the ability of our deep-models to inherently learn and utilize perceptually relevant features when classifying artworks is also presented. The Mean Opinion Score (MOS) obtained from subjective assessments of the respective image and recommended music pairs supports the effectiveness of our approach.
Text Guided Person Image Synthesis
Apr 10, 2019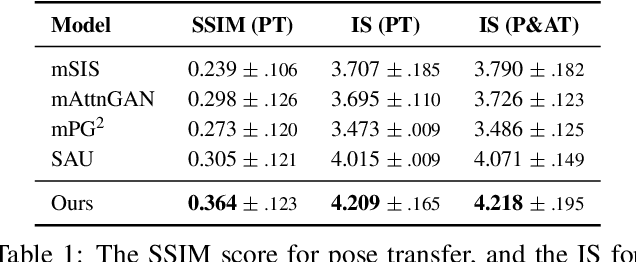
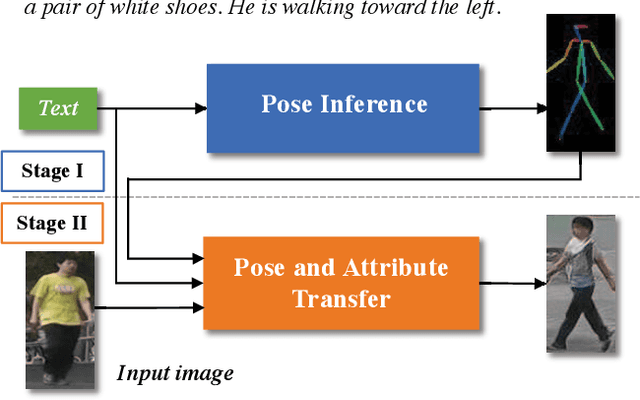
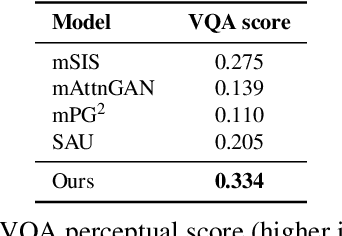
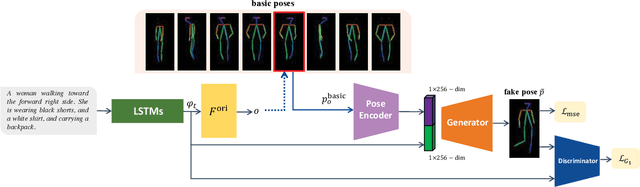
This paper presents a novel method to manipulate the visual appearance (pose and attribute) of a person image according to natural language descriptions. Our method can be boiled down to two stages: 1) text guided pose generation and 2) visual appearance transferred image synthesis. In the first stage, our method infers a reasonable target human pose based on the text. In the second stage, our method synthesizes a realistic and appearance transferred person image according to the text in conjunction with the target pose. Our method extracts sufficient information from the text and establishes a mapping between the image space and the language space, making generating and editing images corresponding to the description possible. We conduct extensive experiments to reveal the effectiveness of our method, as well as using the VQA Perceptual Score as a metric for evaluating the method. It shows for the first time that we can automatically edit the person image from the natural language descriptions.