 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Automated Side Channel Analysis of Media Software with Manifold Learning
Dec 10, 2021
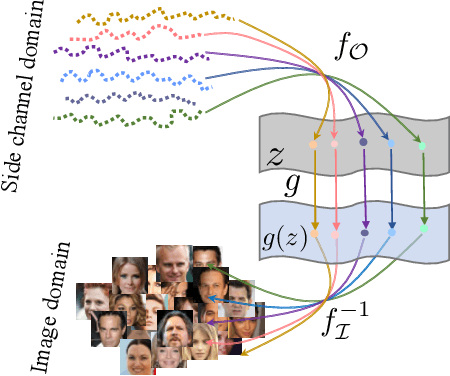

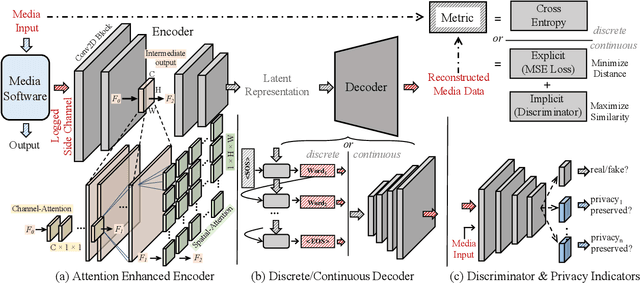

The prosperous development of cloud computing and machine learning as a service has led to the widespread use of media software to process confidential media data. This paper explores an adversary's ability to launch side channel analyses (SCA) against media software to reconstruct confidential media inputs. Recent advances in representation learning and perceptual learning inspired us to consider the reconstruction of media inputs from side channel traces as a cross-modality manifold learning task that can be addressed in a unified manner with an autoencoder framework trained to learn the mapping between media inputs and side channel observations. We further enhance the autoencoder with attention to localize the program points that make the primary contribution to SCA, thus automatically pinpointing information-leakage points in media software. We also propose a novel and highly effective defensive technique called perception blinding that can perturb media inputs with perception masks and mitigate manifold learning-based SCA. Our evaluation exploits three popular media software to reconstruct inputs in image, audio, and text formats. We analyze three common side channels - cache bank, cache line, and page tables - and userspace-only cache set accesses logged by standard Prime+Probe. Our framework successfully reconstructs high-quality confidential inputs from the assessed media software and automatically pinpoint their vulnerable program points, many of which are unknown to the public. We further show that perception blinding can mitigate manifold learning-based SCA with negligible extra cost.
A high performance fingerprint liveness detection method based on quality related features
Nov 02, 2021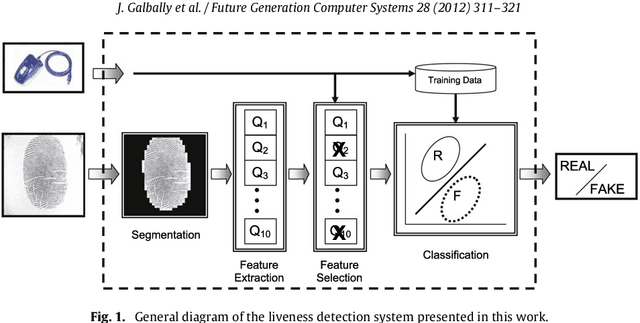
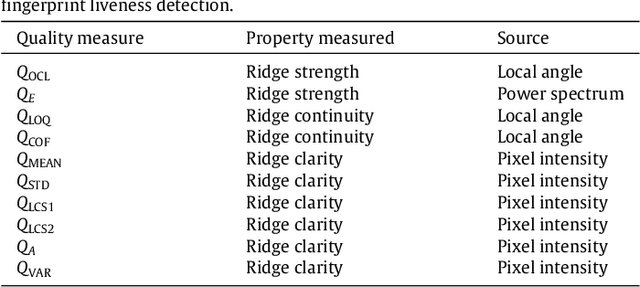


A new software-based liveness detection approach using a novel fingerprint parameterization based on quality related features is proposed. The system is tested on a highly challenging database comprising over 10,500 real and fake images acquired with five sensors of different technologies and covering a wide range of direct attack scenarios in terms of materials and procedures followed to generate the gummy fingers. The proposed solution proves to be robust to the multi-scenario dataset, and presents an overall rate of 90% correctly classified samples. Furthermore, the liveness detection method presented has the added advantage over previously studied techniques of needing just one image from a finger to decide whether it is real or fake. This last characteristic provides the method with very valuable features as it makes it less intrusive, more user friendly, faster and reduces its implementation costs.
Image biomarker standardisation initiative
Sep 17, 2018
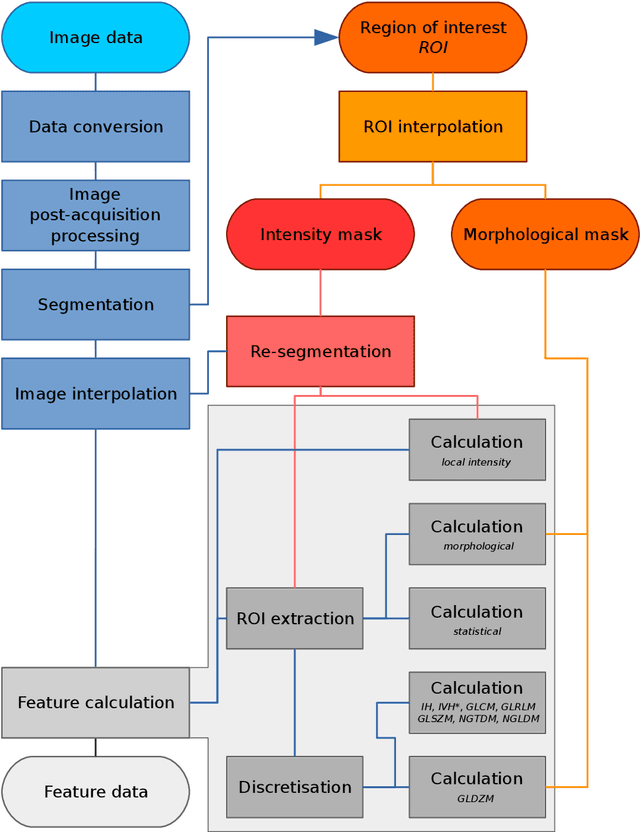

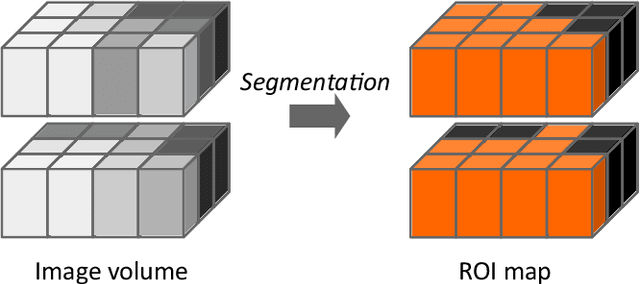
The image biomarker standardisation initiative (IBSI) is an independent international collaboration which works towards standardising the extraction of image biomarkers from acquired imaging for the purpose of high-throughput quantitative image analysis (radiomics). Lack of reproducibility and validation of high-throughput quantitative image analysis studies is considered to be a major challenge for the field. Part of this challenge lies in the scantiness of consensus-based guidelines and definitions for the process of translating acquired imaging into high-throughput image biomarkers. The IBSI therefore seeks to provide image biomarker nomenclature and definitions, benchmark data sets, and benchmark values to verify image processing and image biomarker calculations, as well as reporting guidelines, for high-throughput image analysis.
Dynamic hardware system for cascade SVM classification of melanoma
Dec 10, 2021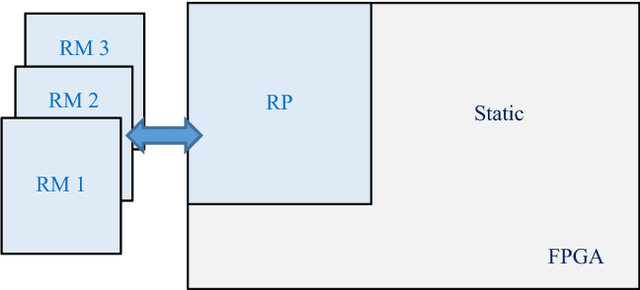


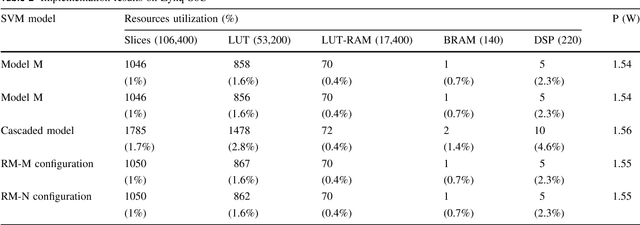
Melanoma is the most dangerous form of skin cancer, which is responsible for the majority of skin cancer-related deaths. Early diagnosis of melanoma can significantly reduce mortality rates and treatment costs. Therefore, skin cancer specialists are using image-based diagnostic tools for detecting melanoma earlier. We aim to develop a handheld device featured with low cost and high performance to enhance early detection of melanoma at the primary healthcare. But, developing this device is very challenging due to the complicated computations required by the embedded diagnosis system. Thus, we aim to exploit the recent hardware technology in reconfigurable computing to achieve a high-performance embedded system at low cost. Support vector machine (SVM) is a common classifier that shows high accuracy for classifying melanoma within the diagnosis system and is considered as the most compute-intensive task in the system. In this paper, we propose a dynamic hardware system for implementing a cascade SVM classifier on FPGA for early melanoma detection. A multi-core architecture is proposed to implement a two-stage cascade classifier using two classifiers with accuracies of 98% and 73%. The hardware implementation results were optimized by using the dynamic partial reconfiguration technology, where very low resource utilization of 1% slices and power consumption of 1.5 W were achieved. Consequently, the implemented dynamic hardware system meets vital embedded system constraints of high performance and low cost, resource utilization, and power consumption, while achieving efficient classification with high accuracy.
* Journal paper, 9 pages, 4 figures, 4 tables
FabricFlowNet: Bimanual Cloth Manipulation with a Flow-based Policy
Nov 10, 2021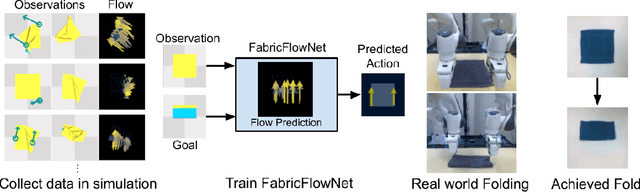

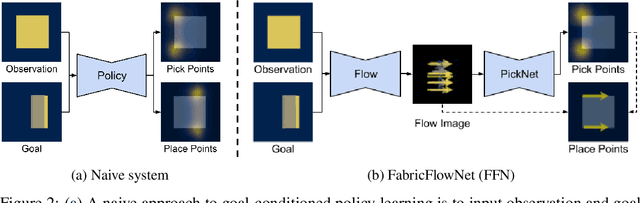

We address the problem of goal-directed cloth manipulation, a challenging task due to the deformability of cloth. Our insight is that optical flow, a technique normally used for motion estimation in video, can also provide an effective representation for corresponding cloth poses across observation and goal images. We introduce FabricFlowNet (FFN), a cloth manipulation policy that leverages flow as both an input and as an action representation to improve performance. FabricFlowNet also elegantly switches between bimanual and single-arm actions based on the desired goal. We show that FabricFlowNet significantly outperforms state-of-the-art model-free and model-based cloth manipulation policies that take image input. We also present real-world experiments on a bimanual system, demonstrating effective sim-to-real transfer. Finally, we show that our method generalizes when trained on a single square cloth to other cloth shapes, such as T-shirts and rectangular cloths. Video and other supplementary materials are available at: https://sites.google.com/view/fabricflownet.
Sem-GAN: Semantically-Consistent Image-to-Image Translation
Jul 12, 2018
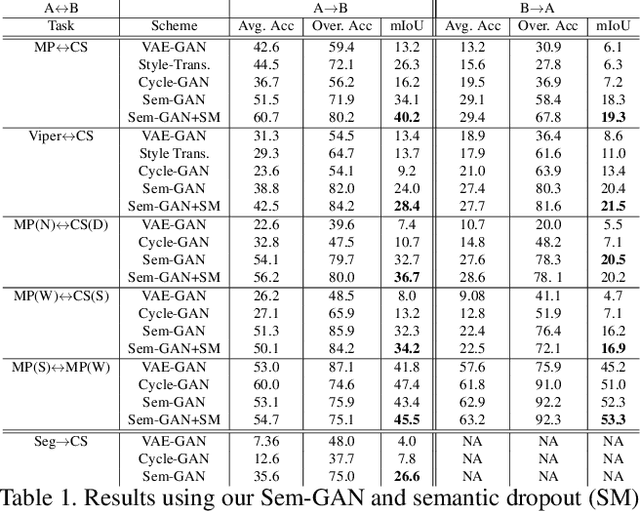
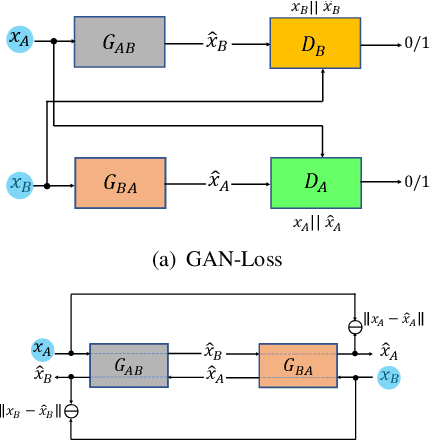
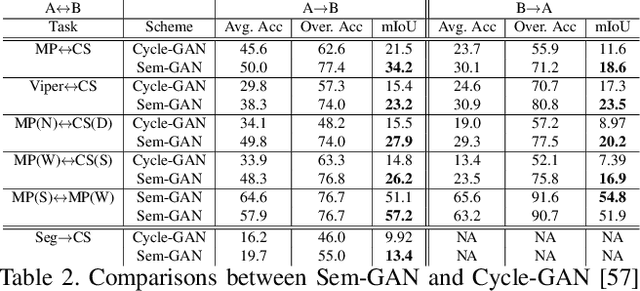
Unpaired image-to-image translation is the problem of mapping an image in the source domain to one in the target domain, without requiring corresponding image pairs. To ensure the translated images are realistically plausible, recent works, such as Cycle-GAN, demands this mapping to be invertible. While, this requirement demonstrates promising results when the domains are unimodal, its performance is unpredictable in a multi-modal scenario such as in an image segmentation task. This is because, invertibility does not necessarily enforce semantic correctness. To this end, we present a semantically-consistent GAN framework, dubbed Sem-GAN, in which the semantics are defined by the class identities of image segments in the source domain as produced by a semantic segmentation algorithm. Our proposed framework includes consistency constraints on the translation task that, together with the GAN loss and the cycle-constraints, enforces that the images when translated will inherit the appearances of the target domain, while (approximately) maintaining their identities from the source domain. We present experiments on several image-to-image translation tasks and demonstrate that Sem-GAN improves the quality of the translated images significantly, sometimes by more than 20% on the FCN score. Further, we show that semantic segmentation models, trained with synthetic images translated via Sem-GAN, leads to significantly better segmentation results than other variants.
Automatic image-based identification and biomass estimation of invertebrates
Feb 05, 2020
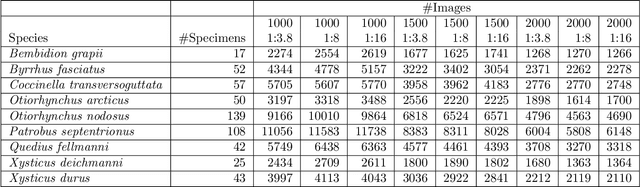
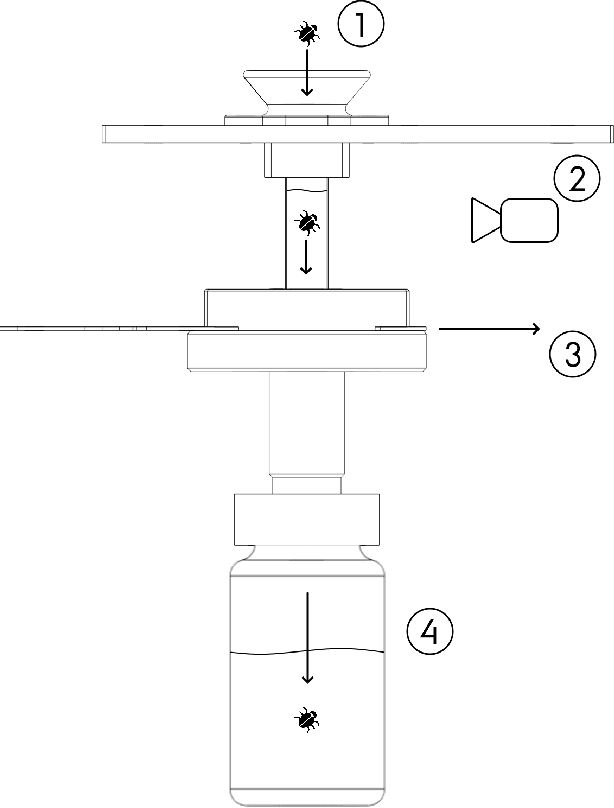

Understanding how biological communities respond to environmental changes is a key challenge in ecology and ecosystem management. The apparent decline of insect populations necessitates more biomonitoring but the time-consuming sorting and identification of taxa pose strong limitations on how many insect samples can be processed. In turn, this affects the scale of efforts to map invertebrate diversity altogether. Given recent advances in computer vision, we propose to replace the standard manual approach of human expert-based sorting and identification with an automatic image-based technology. We describe a robot-enabled image-based identification machine, which can automate the process of invertebrate identification, biomass estimation and sample sorting. We use the imaging device to generate a comprehensive image database of terrestrial arthropod species. We use this database to test the classification accuracy i.e. how well the species identity of a specimen can be predicted from images taken by the machine. We also test sensitivity of the classification accuracy to the camera settings (aperture and exposure time) in order to move forward with the best possible image quality. We use state-of-the-art Resnet-50 and InceptionV3 CNNs for the classification task. The results for the initial dataset are very promising ($\overline{ACC}=0.980$). The system is general and can easily be used for other groups of invertebrates as well. As such, our results pave the way for generating more data on spatial and temporal variation in invertebrate abundance, diversity and biomass.
Neural Fields in Visual Computing and Beyond
Nov 29, 2021
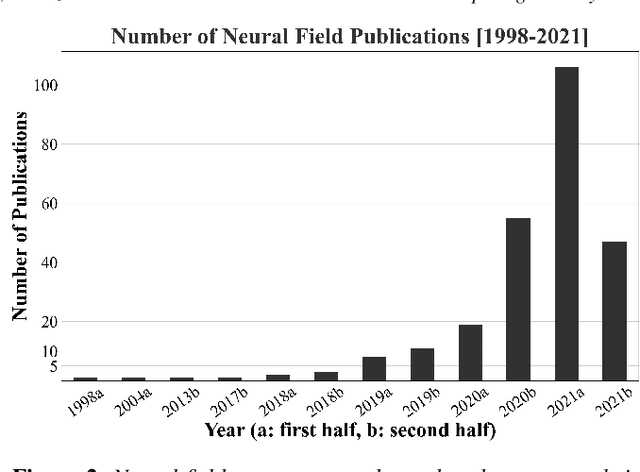

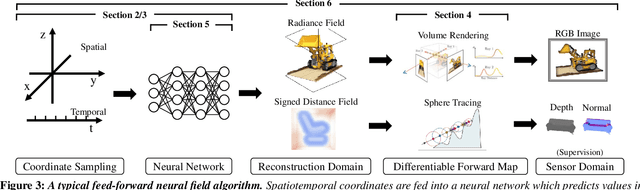
Recent advances in machine learning have created increasing interest in solving visual computing problems using a class of coordinate-based neural networks that parametrize physical properties of scenes or objects across space and time. These methods, which we call neural fields, have seen successful application in the synthesis of 3D shapes and image, animation of human bodies, 3D reconstruction, and pose estimation. However, due to rapid progress in a short time, many papers exist but a comprehensive review and formulation of the problem has not yet emerged. In this report, we address this limitation by providing context, mathematical grounding, and an extensive review of literature on neural fields. This report covers research along two dimensions. In Part I, we focus on techniques in neural fields by identifying common components of neural field methods, including different representations, architectures, forward mapping, and generalization methods. In Part II, we focus on applications of neural fields to different problems in visual computing, and beyond (e.g., robotics, audio). Our review shows the breadth of topics already covered in visual computing, both historically and in current incarnations, demonstrating the improved quality, flexibility, and capability brought by neural fields methods. Finally, we present a companion website that contributes a living version of this review that can be continually updated by the community.
Kernel density estimation-based sampling for neural network classification
Oct 25, 2021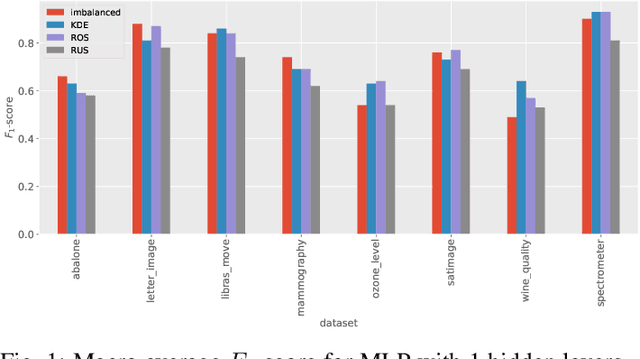
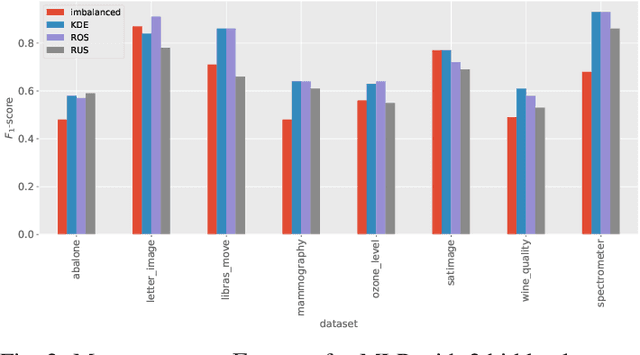
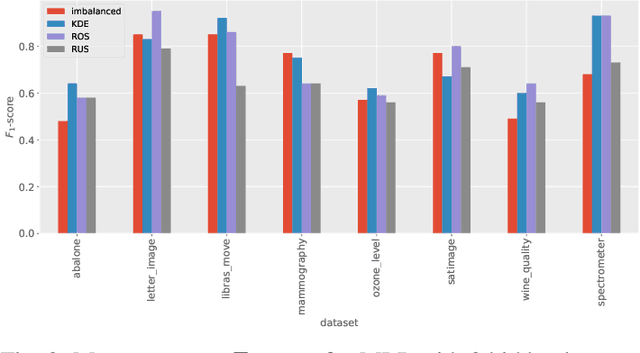
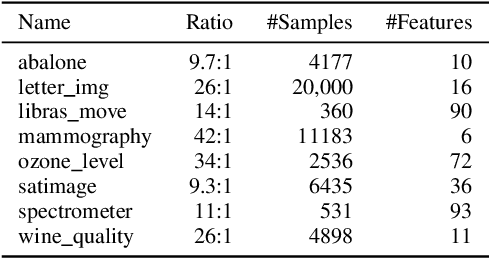
Imbalanced data occurs in a wide range of scenarios. The skewed distribution of the target variable elicits bias in machine learning algorithms. One of the popular methods to combat imbalanced data is to artificially balance the data through resampling. In this paper, we compare the efficacy of a recently proposed kernel density estimation (KDE) sampling technique in the context of artificial neural networks. We benchmark the KDE sampling method against two base sampling techniques and perform comparative experiments using 8 datasets and 3 neural networks architectures. The results show that KDE sampling produces the best performance on 6 out of 8 datasets. However, it must be used with caution on image datasets. We conclude that KDE sampling is capable of significantly improving the performance of neural networks.
Learning to Downsample for Segmentation of Ultra-High Resolution Images
Sep 22, 2021
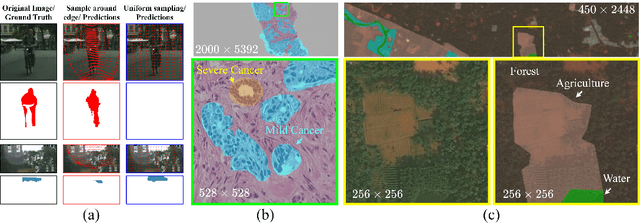
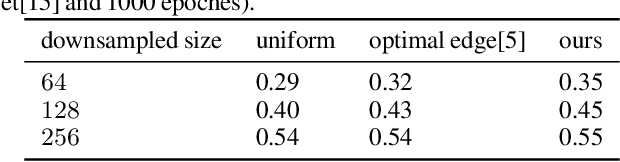

Segmentation of ultra-high resolution images with deep learning is challenging because of their enormous size, often millions or even billions of pixels. Typical solutions drastically downsample the image uniformly to meet memory constraints, implicitly assuming all pixels equally important by sampling at the same density at all spatial locations. However this assumption is not true and compromises the performance of deep learning techniques that have proved powerful on standard-sized images. For example with uniform downsampling, see green boxed region in Fig.1, the rider and bike do not have enough corresponding samples while the trees and buildings are oversampled, and lead to a negative effect on the segmentation prediction from the low-resolution downsampled image. In this work we show that learning the spatially varying downsampling strategy jointly with segmentation offers advantages in segmenting large images with limited computational budget. Fig.1 shows that our method adapts the sampling density over different locations so that more samples are collected from the small important regions and less from the others, which in turn leads to better segmentation accuracy. We show on two public and one local high-resolution datasets that our method consistently learns sampling locations preserving more information and boosting segmentation accuracy over baseline methods.