 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Rotation Equivariant Deforestation Segmentation and Driver Classification
Oct 25, 2021
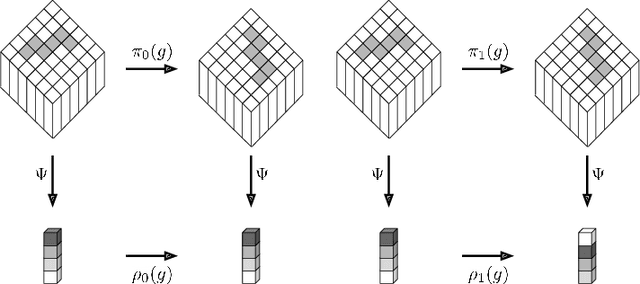


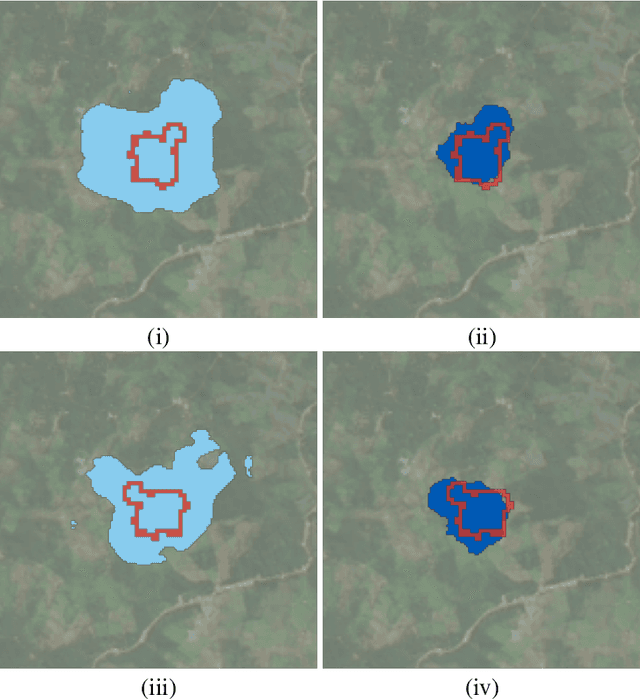
Deforestation has become a significant contributing factor to climate change and, due to this, both classifying the drivers and predicting segmentation maps of deforestation has attracted significant interest. In this work, we develop a rotation equivariant convolutional neural network model to predict the drivers and generate segmentation maps of deforestation events from Landsat 8 satellite images. This outperforms previous methods in classifying the drivers and predicting the segmentation map of deforestation, offering a 9% improvement in classification accuracy and a 7% improvement in segmentation map accuracy. In addition, this method predicts stable segmentation maps under rotation of the input image, which ensures that predicted regions of deforestation are not dependent upon the rotational orientation of the satellite.
Deep Relighting Networks for Image Light Source Manipulation
Aug 19, 2020

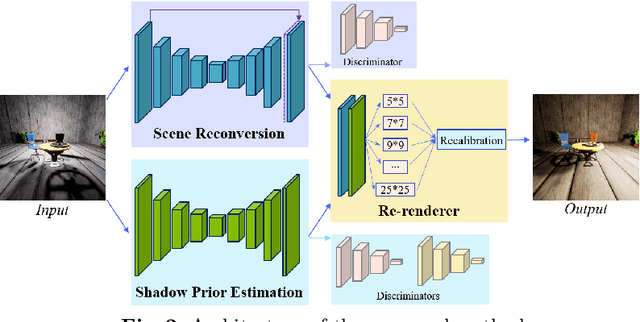
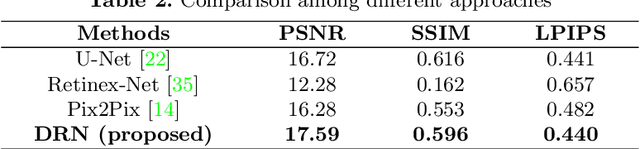
Manipulating the light source of given images is an interesting task and useful in various applications, including photography and cinematography. Existing methods usually require additional information like the geometric structure of the scene, which may not be available for most images. In this paper, we formulate the single image relighting task and propose a novel Deep Relighting Network (DRN) with three parts: 1) scene reconversion, which aims to reveal the primary scene structure through a deep auto-encoder network, 2) shadow prior estimation, to predict light effect from the new light direction through adversarial learning, and 3) re-renderer, to combine the primary structure with the reconstructed shadow view to form the required estimation under the target light source. Experimental results show that the proposed method outperforms other possible methods, both qualitatively and quantitatively. Specifically, the proposed DRN has achieved the best PSNR in the "AIM2020 - Any to one relighting challenge" of the 2020 ECCV conference.
Self-supervised Semi-supervised Learning for Data Labeling and Quality Evaluation
Nov 22, 2021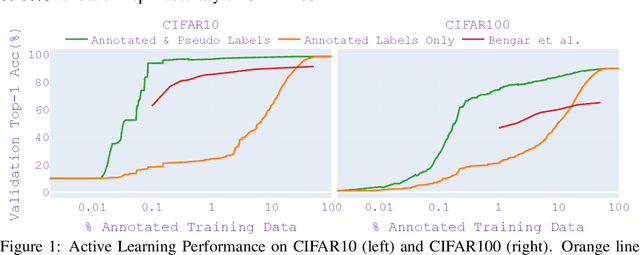
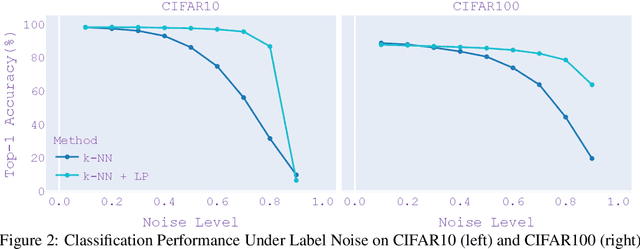
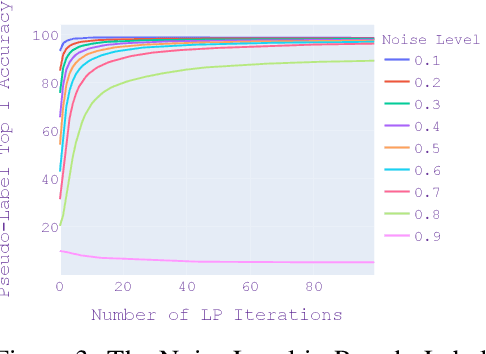
As the adoption of deep learning techniques in industrial applications grows with increasing speed and scale, successful deployment of deep learning models often hinges on the availability, volume, and quality of annotated data. In this paper, we tackle the problems of efficient data labeling and annotation verification under the human-in-the-loop setting. We showcase that the latest advancements in the field of self-supervised visual representation learning can lead to tools and methods that benefit the curation and engineering of natural image datasets, reducing annotation cost and increasing annotation quality. We propose a unifying framework by leveraging self-supervised semi-supervised learning and use it to construct workflows for data labeling and annotation verification tasks. We demonstrate the effectiveness of our workflows over existing methodologies. On active learning task, our method achieves 97.0% Top-1 Accuracy on CIFAR10 with 0.1% annotated data, and 83.9% Top-1 Accuracy on CIFAR100 with 10% annotated data. When learning with 50% of wrong labels, our method achieves 97.4% Top-1 Accuracy on CIFAR10 and 85.5% Top-1 Accuracy on CIFAR100.
Nice perfume. How long did you marinate in it? Multimodal Sarcasm Explanation
Dec 09, 2021
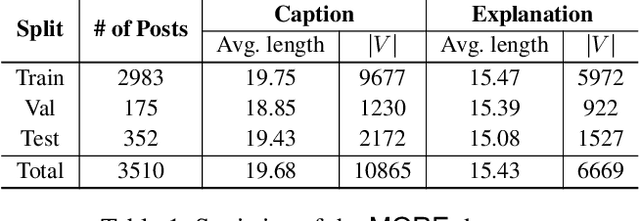

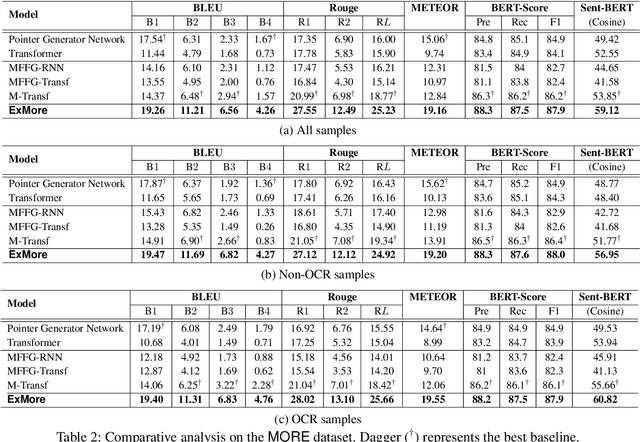
Sarcasm is a pervading linguistic phenomenon and highly challenging to explain due to its subjectivity, lack of context and deeply-felt opinion. In the multimodal setup, sarcasm is conveyed through the incongruity between the text and visual entities. Although recent approaches deal with sarcasm as a classification problem, it is unclear why an online post is identified as sarcastic. Without proper explanation, end users may not be able to perceive the underlying sense of irony. In this paper, we propose a novel problem -- Multimodal Sarcasm Explanation (MuSE) -- given a multimodal sarcastic post containing an image and a caption, we aim to generate a natural language explanation to reveal the intended sarcasm. To this end, we develop MORE, a new dataset with explanation of 3510 sarcastic multimodal posts. Each explanation is a natural language (English) sentence describing the hidden irony. We benchmark MORE by employing a multimodal Transformer-based architecture. It incorporates a cross-modal attention in the Transformer's encoder which attends to the distinguishing features between the two modalities. Subsequently, a BART-based auto-regressive decoder is used as the generator. Empirical results demonstrate convincing results over various baselines (adopted for MuSE) across five evaluation metrics. We also conduct human evaluation on predictions and obtain Fleiss' Kappa score of 0.4 as a fair agreement among 25 evaluators.
Image compression optimized for 3D reconstruction by utilizing deep neural networks
Mar 27, 2020
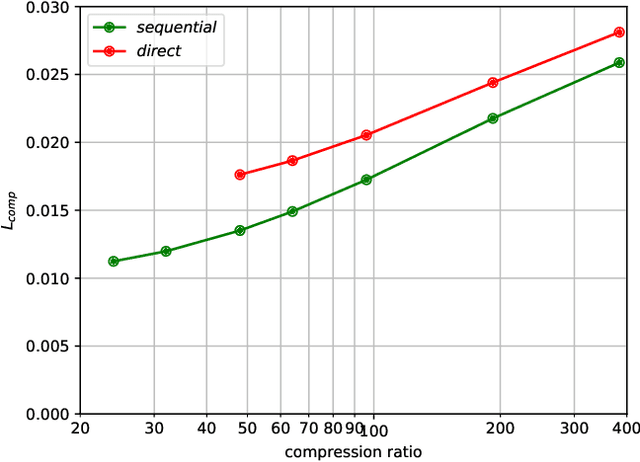
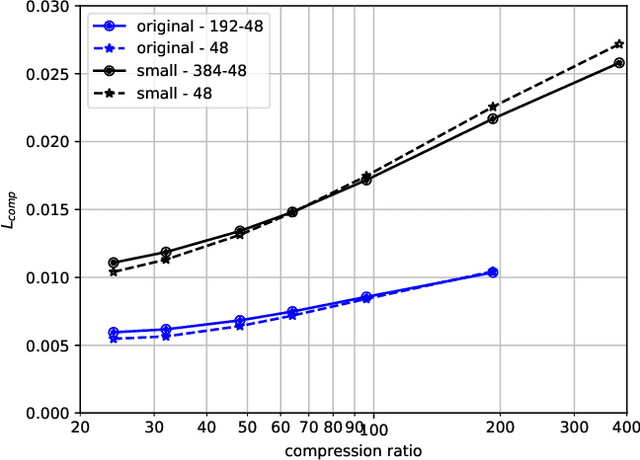
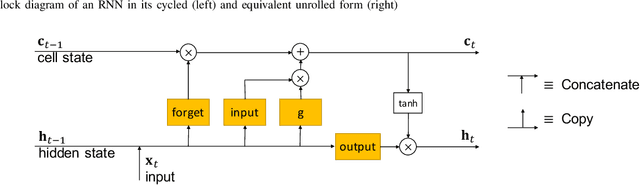
Computer vision tasks are often expected to be executed on compressed images. Classical image compression standards like JPEG 2000 are widely used. However, they do not account for the specific end-task at hand. Motivated by works on recurrent neural network (RNN)-based image compression and three-dimensional (3D) reconstruction, we propose unified network architectures to solve both tasks jointly. These joint models provide image compression tailored for the specific task of 3D reconstruction. Images compressed by our proposed models, yield 3D reconstruction performance superior as compared to using JPEG 2000 compression. Our models significantly extend the range of compression rates for which 3D reconstruction is possible. We also show that this can be done highly efficiently at almost no additional cost to obtain compression on top of the computation already required for performing the 3D reconstruction task.
HHF: Hashing-guided Hinge Function for Deep Hashing Retrieval
Dec 04, 2021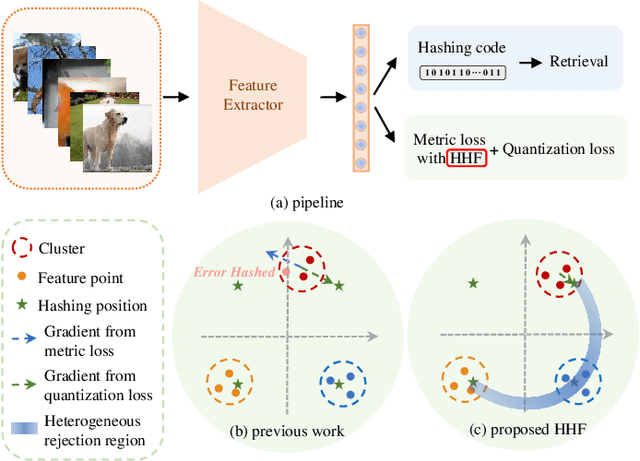

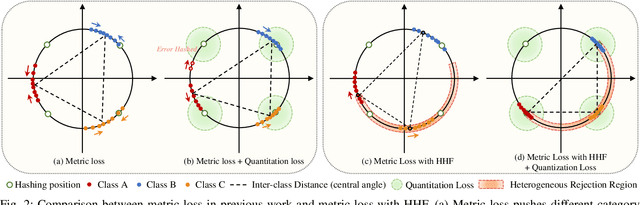
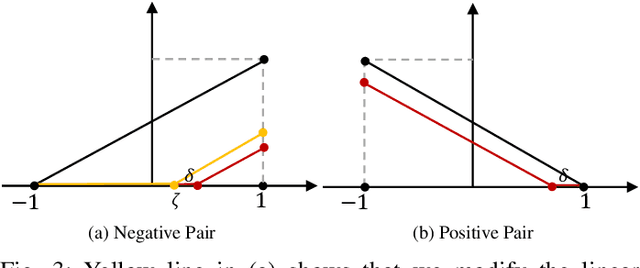
Deep hashing has shown promising performance in large-scale image retrieval. However, latent codes extracted by \textbf{D}eep \textbf{N}eural \textbf{N}etwork (DNN) will inevitably lose semantic information during the binarization process, which damages the retrieval efficiency and make it challenging. Although many existing approaches perform regularization to alleviate quantization errors, we figure out an incompatible conflict between the metric and quantization losses. The metric loss penalizes the inter-class distances to push different classes unconstrained far away. Worse still, it tends to map the latent code deviate from ideal binarization point and generate severe ambiguity in the binarization process. Based on the minimum distance of the binary linear code, \textbf{H}ashing-guided \textbf{H}inge \textbf{F}unction (HHF) is proposed to avoid such conflict. In detail, we carefully design a specific inflection point, which relies on the hash bit length and category numbers to balance metric learning and quantization learning. Such a modification prevents the network from falling into local metric optimal minima in deep hashing. Extensive experiments in CIFAR-10, CIFAR-100, ImageNet, and MS-COCO show that HHF consistently outperforms existing techniques, and is robust and flexible to transplant into other methods.
EGFN: Efficient Geometry Feature Network for Fast Stereo 3D Object Detection
Nov 28, 2021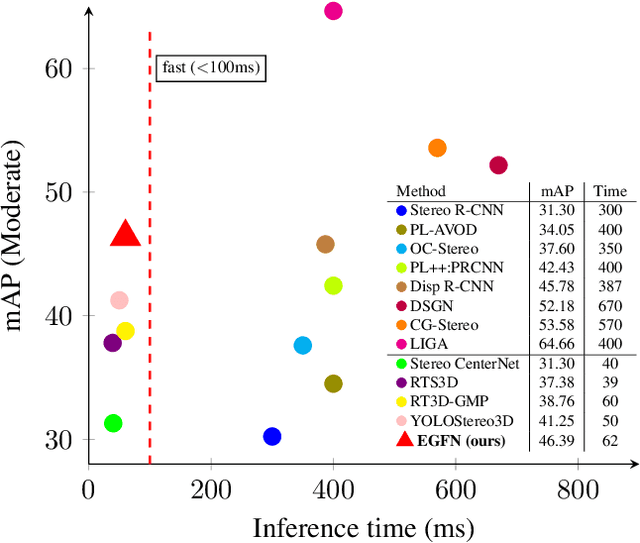
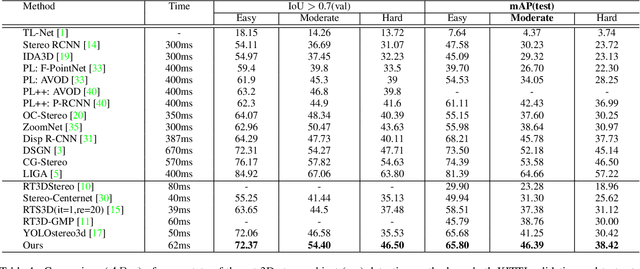
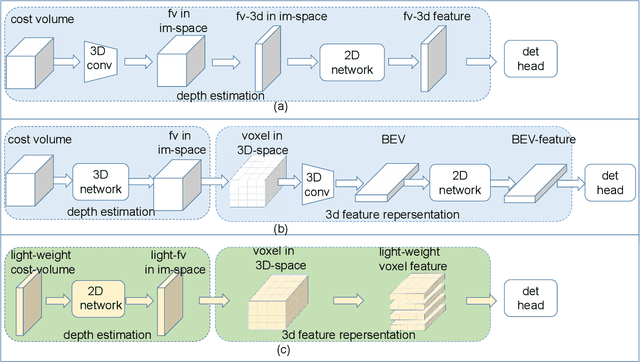
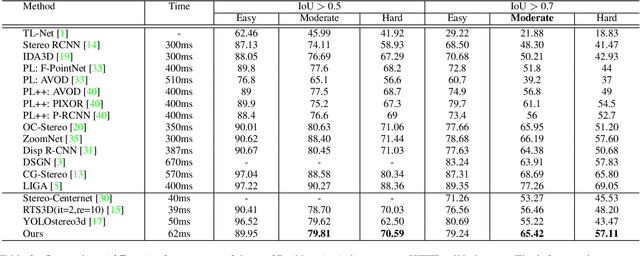
Fast stereo based 3D object detectors have made great progress in the sense of inference time recently. However, they lag far behind high-precision oriented methods in accuracy. We argue that the main reason is the missing or poor 3D geometry feature representation in fast stereo based methods. To solve this problem, we propose an efficient geometry feature generation network (EGFN). The key of our EGFN is an efficient and effective 3D geometry feature representation (EGFR) module. In the EGFR module, light-weight cost volume features are firstly generated, then are efficiently converted into 3D space, and finally multi-scale features enhancement in in both image and 3D spaces is conducted to obtain the 3D geometry features: enhanced light-weight voxel features. In addition, we introduce a novel multi-scale knowledge distillation strategy to guide multi-scale 3D geometry features learning. Experimental results on the public KITTI test set shows that the proposed EGFN outperforms YOLOStsereo3D, the advanced fast method, by 5.16\% on mAP$_{3d}$ at the cost of merely additional 12 ms and hence achieves a better trade-off between accuracy and efficiency for stereo 3D object detection. Our code will be publicly available.
Impact of Benign Modifications on Discriminative Performance of Deepfake Detectors
Nov 14, 2021
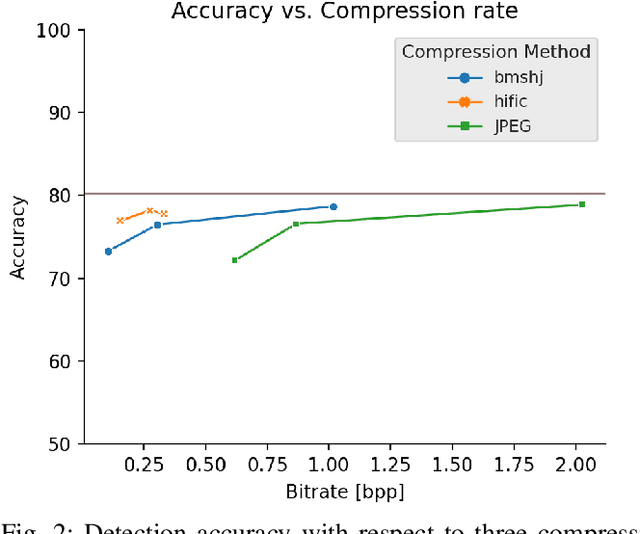
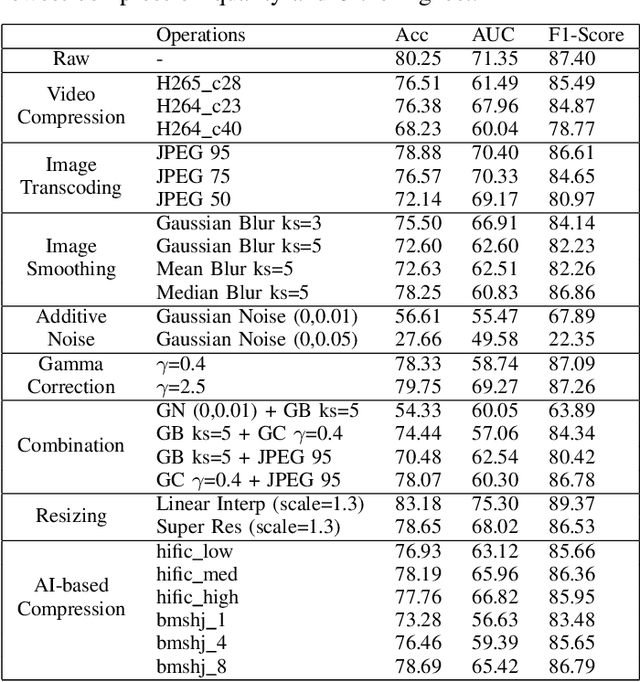
Deepfakes are becoming increasingly popular in both good faith applications such as in entertainment and maliciously intended manipulations such as in image and video forgery. Primarily motivated by the latter, a large number of deepfake detectors have been proposed recently in order to identify such content. While the performance of such detectors still need further improvements, they are often assessed in simple if not trivial scenarios. In particular, the impact of benign processing operations such as transcoding, denoising, resizing and enhancement are not sufficiently studied. This paper proposes a more rigorous and systematic framework to assess the performance of deepfake detectors in more realistic situations. It quantitatively measures how and to which extent each benign processing approach impacts a state-of-the-art deepfake detection method. By illustrating it in a popular deepfake detector, our benchmark proposes a framework to assess robustness of detectors and provides valuable insights to design more efficient deepfake detectors.
Improving accuracy and speeding up Document Image Classification through parallel systems
Jun 16, 2020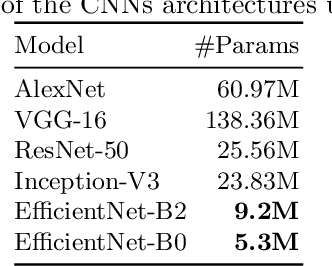
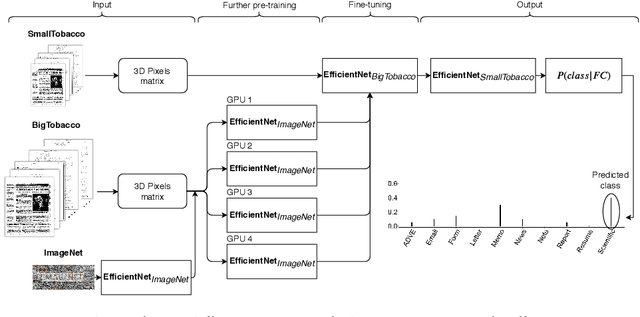
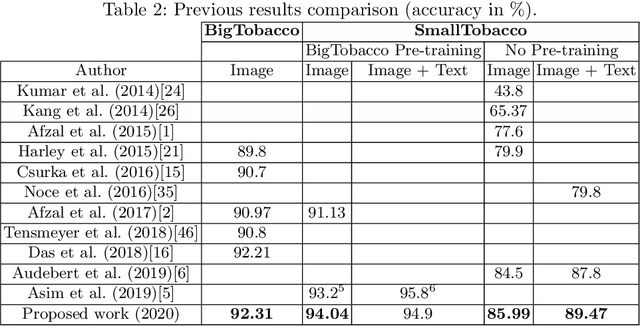
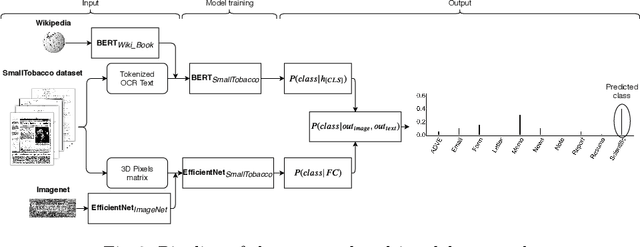
This paper presents a study showing the benefits of the EfficientNet models compared with heavier Convolutional Neural Networks (CNNs) in the Document Classification task, essential problem in the digitalization process of institutions. We show in the RVL-CDIP dataset that we can improve previous results with a much lighter model and present its transfer learning capabilities on a smaller in-domain dataset such as Tobacco3482. Moreover, we present an ensemble pipeline which is able to boost solely image input by combining image model predictions with the ones generated by BERT model on extracted text by OCR. We also show that the batch size can be effectively increased without hindering its accuracy so that the training process can be sped up by parallelizing throughout multiple GPUs, decreasing the computational time needed. Lastly, we expose the training performance differences between PyTorch and Tensorflow Deep Learning frameworks.
CRANE: a 10 Degree-of-Freedom, Tele-surgical System for Dexterous Manipulation within Imaging Bores
Sep 28, 2021
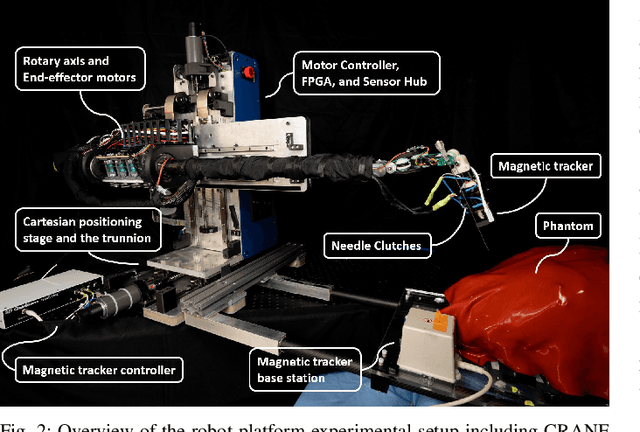


Physicians perform minimally invasive percutaneous procedures under Computed Tomography (CT) image guidance both for the diagnosis and treatment of numerous diseases. For these procedures performed within Computed Tomography Scanners, robots can enable physicians to more accurately target sub-dermal lesions while increasing safety. However, existing robots for this application have limited dexterity, workspace, or accuracy. This paper describes the design, manufacture, and performance of a highly dexterous, low-profile, 8+2 Degree-ofFreedom (DoF) robotic arm for CT guided percutaneous needle biopsy. In this article, we propose CRANE: CT Robot and Needle Emplacer. The design focuses on system dexterity with high accuracy: extending physicians' ability to manipulate and insert needles within the scanner bore while providing the high accuracy possible with a robot. We also propose and validate a system architecture and control scheme for low profile and highly accurate image-guided robotics, that meets the clinical requirements for target accuracy during an in-situ evaluation. The accuracy is additionally evaluated through a trajectory tracking evaluation resulting in <0.2mm and <0.71degree tracking error. Finally, we present a novel needle driving and grasping mechanism with controlling electronics that provides simple manufacturing, sterilization, and adaptability to accommodate different sizes and types of needles.