 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
GANILLA: Generative Adversarial Networks for Image to Illustration Translation
Feb 13, 2020

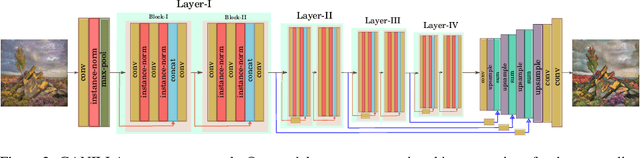

In this paper, we explore illustrations in children's books as a new domain in unpaired image-to-image translation. We show that although the current state-of-the-art image-to-image translation models successfully transfer either the style or the content, they fail to transfer both at the same time. We propose a new generator network to address this issue and show that the resulting network strikes a better balance between style and content. There are no well-defined or agreed-upon evaluation metrics for unpaired image-to-image translation. So far, the success of image translation models has been based on subjective, qualitative visual comparison on a limited number of images. To address this problem, we propose a new framework for the quantitative evaluation of image-to-illustration models, where both content and style are taken into account using separate classifiers. In this new evaluation framework, our proposed model performs better than the current state-of-the-art models on the illustrations dataset. Our code and pretrained models can be found at https://github.com/giddyyupp/ganilla.
Intrinsic Autoencoders for Joint Neural Rendering and Intrinsic Image Decomposition
Jul 01, 2020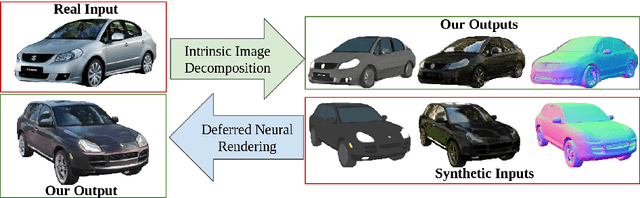

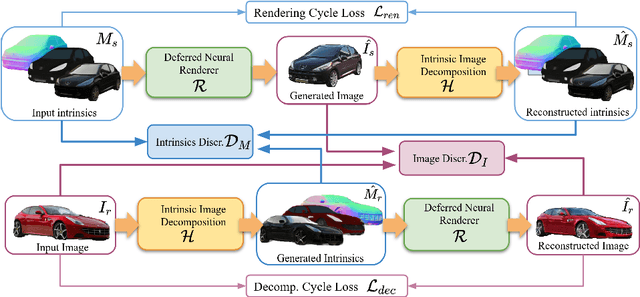
Neural rendering techniques promise efficient photo-realistic image synthesis while at the same time providing rich control over scene parameters by learning the physical image formation process. While several supervised methods have been proposed for this task, acquiring a dataset of images with accurately aligned 3D models is very difficult. The main contribution of this work is to lift this restriction by training a neural rendering algorithm from unpaired data. More specifically, we propose an autoencoder for joint generation of realistic images from synthetic 3D models while simultaneously decomposing real images into their intrinsic shape and appearance properties. In contrast to a traditional graphics pipeline, our approach does not require to specify all scene properties, such as material parameters and lighting by hand. Instead, we learn photo-realistic deferred rendering from a small set of 3D models and a larger set of unaligned real images, both of which are easy to acquire in practice. Simultaneously, we obtain accurate intrinsic decompositions of real images while not requiring paired ground truth. Our experiments confirm that a joint treatment of rendering and decomposition is indeed beneficial and that our approach outperforms state-of-the-art image-to-image translation baselines both qualitatively and quantitatively.
BadEncoder: Backdoor Attacks to Pre-trained Encoders in Self-Supervised Learning
Aug 01, 2021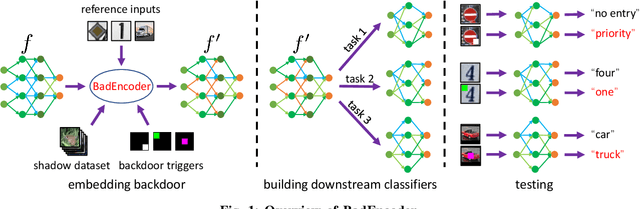

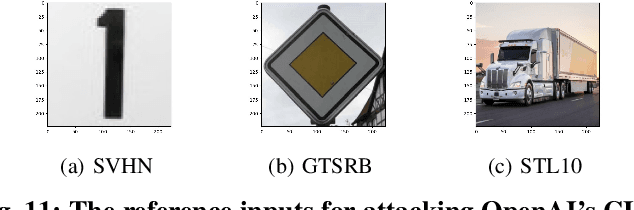

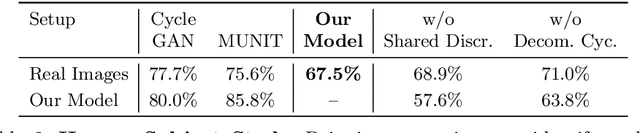
Self-supervised learning in computer vision aims to pre-train an image encoder using a large amount of unlabeled images or (image, text) pairs. The pre-trained image encoder can then be used as a feature extractor to build downstream classifiers for many downstream tasks with a small amount of or no labeled training data. In this work, we propose BadEncoder, the first backdoor attack to self-supervised learning. In particular, our BadEncoder injects backdoors into a pre-trained image encoder such that the downstream classifiers built based on the backdoored image encoder for different downstream tasks simultaneously inherit the backdoor behavior. We formulate our BadEncoder as an optimization problem and we propose a gradient descent based method to solve it, which produces a backdoored image encoder from a clean one. Our extensive empirical evaluation results on multiple datasets show that our BadEncoder achieves high attack success rates while preserving the accuracy of the downstream classifiers. We also show the effectiveness of BadEncoder using two publicly available, real-world image encoders, i.e., Google's image encoder pre-trained on ImageNet and OpenAI's Contrastive Language-Image Pre-training (CLIP) image encoder pre-trained on 400 million (image, text) pairs collected from the Internet. Moreover, we consider defenses including Neural Cleanse and MNTD (empirical defenses) as well as PatchGuard (a provable defense). Our results show that these defenses are insufficient to defend against BadEncoder, highlighting the needs for new defenses against our BadEncoder. Our code is publicly available at: https://github.com/jjy1994/BadEncoder.
X2CT-FLOW: Reconstruction of multiple volumetric chest computed tomography images with different likelihoods from a uni- or biplanar chest X-ray image using a flow-based generative model
Apr 09, 2021
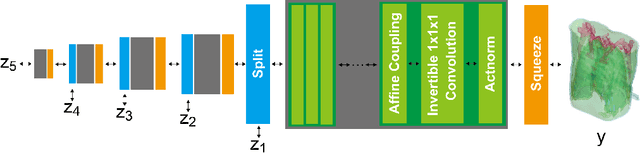

We propose X2CT-FLOW for the reconstruction of volumetric chest computed tomography (CT) images from uni- or biplanar digitally reconstructed radiographs (DRRs) or chest X-ray (CXR) images on the basis of a flow-based deep generative (FDG) model. With the adoption of X2CT-FLOW, all the reconstructed volumetric chest CT images satisfy the condition that each of those projected onto each plane coincides with each input DRR or CXR image. Moreover, X2CT-FLOW can reconstruct multiple volumetric chest CT images with different likelihoods. The volumetric chest CT images reconstructed from biplanar DRRs showed good agreement with ground truth images in terms of the structural similarity index (0.931 on average). Moreover, we show that X2CT-FLOW can actually reconstruct such multiple volumetric chest CT images from DRRs. Finally, we demonstrate that X2CT-FLOW can reconstruct multiple volumetric chest CT images from a real uniplanar CXR image.
Analyzing Overfitting under Class Imbalance in Neural Networks for Image Segmentation
Feb 20, 2021
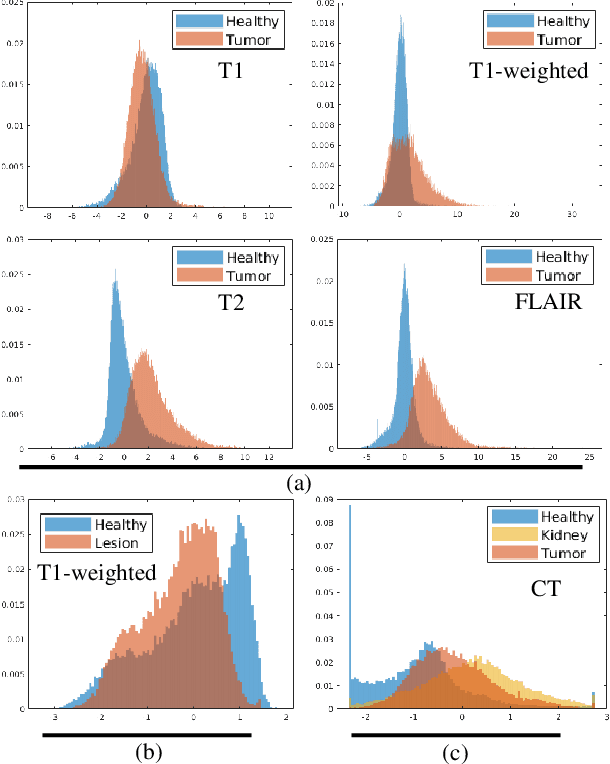
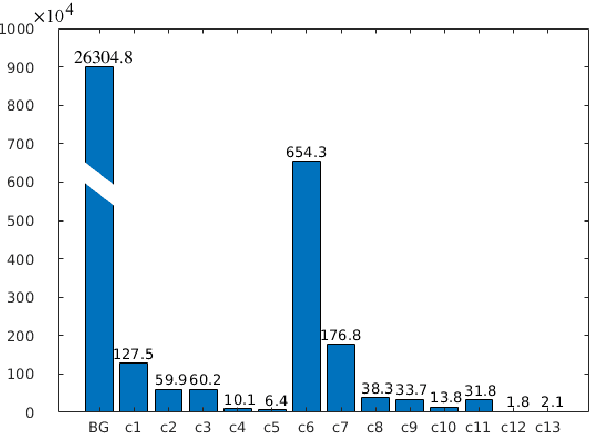
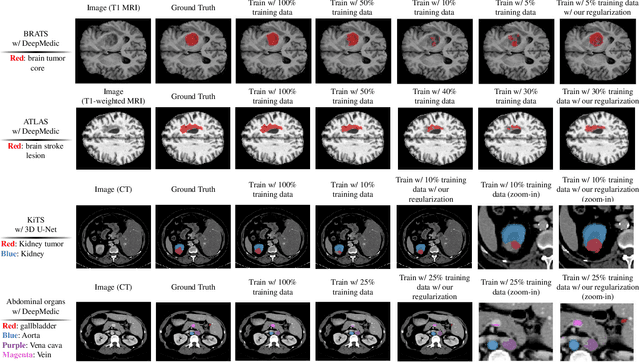
Class imbalance poses a challenge for developing unbiased, accurate predictive models. In particular, in image segmentation neural networks may overfit to the foreground samples from small structures, which are often heavily under-represented in the training set, leading to poor generalization. In this study, we provide new insights on the problem of overfitting under class imbalance by inspecting the network behavior. We find empirically that when training with limited data and strong class imbalance, at test time the distribution of logit activations may shift across the decision boundary, while samples of the well-represented class seem unaffected. This bias leads to a systematic under-segmentation of small structures. This phenomenon is consistently observed for different databases, tasks and network architectures. To tackle this problem, we introduce new asymmetric variants of popular loss functions and regularization techniques including a large margin loss, focal loss, adversarial training, mixup and data augmentation, which are explicitly designed to counter logit shift of the under-represented classes. Extensive experiments are conducted on several challenging segmentation tasks. Our results demonstrate that the proposed modifications to the objective function can lead to significantly improved segmentation accuracy compared to baselines and alternative approaches.
Efficient OCT Image Segmentation Using Neural Architecture Search
Jul 28, 2020


In this work, we propose a Neural Architecture Search (NAS) for retinal layer segmentation in Optical Coherence Tomography (OCT) scans. We incorporate the Unet architecture in the NAS framework as its backbone for the segmentation of the retinal layers in our collected and pre-processed OCT image dataset. At the pre-processing stage, we conduct super resolution and image processing techniques on the raw OCT scans to improve the quality of the raw images. For our search strategy, different primitive operations are suggested to find the down- & up-sampling cell blocks, and the binary gate method is applied to make the search strategy practical for the task in hand. We empirically evaluated our method on our in-house OCT dataset. The experimental results demonstrate that the self-adapting NAS-Unet architecture substantially outperformed the competitive human-designed architecture by achieving 95.4% in mean Intersection over Union metric and 78.7% in Dice similarity coefficient.
Feature matching for multi-epoch historical aerial images
Dec 08, 2021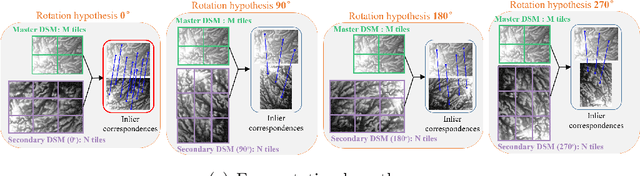
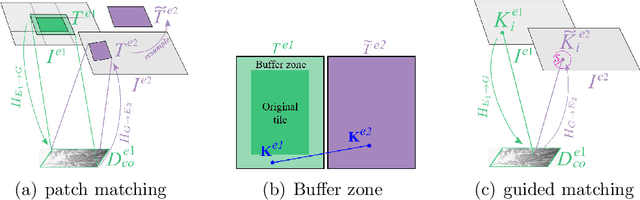
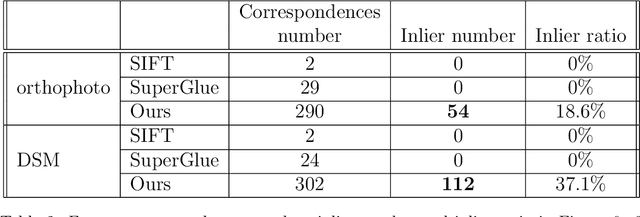
Historical imagery is characterized by high spatial resolution and stereo-scopic acquisitions, providing a valuable resource for recovering 3D land-cover information. Accurate geo-referencing of diachronic historical images by means of self-calibration remains a bottleneck because of the difficulty to find sufficient amount of feature correspondences under evolving landscapes. In this research, we present a fully automatic approach to detecting feature correspondences between historical images taken at different times (i.e., inter-epoch), without auxiliary data required. Based on relative orientations computed within the same epoch (i.e., intra-epoch), we obtain DSMs (Digital Surface Model) and incorporate them in a rough-to-precise matching. The method consists of: (1) an inter-epoch DSMs matching to roughly co-register the orientations and DSMs (i.e, the 3D Helmert transformation), followed by (2) a precise inter-epoch feature matching using the original RGB images. The innate ambiguity of the latter is largely alleviated by narrowing down the search space using the co-registered data. With the inter-epoch features, we refine the image orientations and quantitatively evaluate the results (1) with DoD (Difference of DSMs), (2) with ground check points, and (3) by quantifying ground displacement due to an earthquake. We demonstrate that our method: (1) can automatically georeference diachronic historical images; (2) can effectively mitigate systematic errors induced by poorly estimated camera parameters; (3) is robust to drastic scene changes. Compared to the state-of-the-art, our method improves the image georeferencing accuracy by a factor of 2. The proposed methods are implemented in MicMac, a free, open-source photogrammetric software.
* 34 pages
Implicit Euler ODE Networks for Single-Image Dehazing
Jul 13, 2020
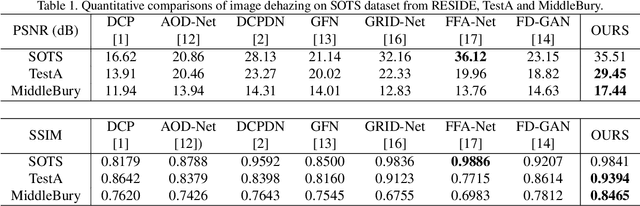
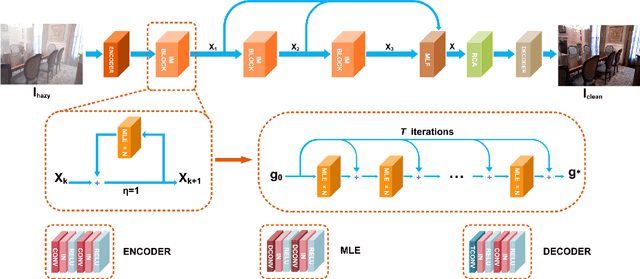

Deep convolutional neural networks (CNN) have been applied for image dehazing tasks, where the residual network (ResNet) is often adopted as the basic component to avoid the vanishing gradient problem. Recently, many works indicate that the ResNet can be considered as the explicit Euler forward approximation of an ordinary differential equation (ODE). In this paper, we extend the explicit forward approximation to the implicit backward counterpart, which can be realized via a recursive neural network, named IM-block. Given that, we propose an efficient end-to-end multi-level implicit network (MI-Net) for the single image dehazing problem. Moreover, multi-level fusing (MLF) mechanism and residual channel attention block (RCA-block) are adopted to boost performance of our network. Experiments on several dehazing benchmark datasets demonstrate that our method outperforms existing methods and achieves the state-of-the-art performance.
Spatial Attention as an Interface for Image Captioning Models
Sep 29, 2020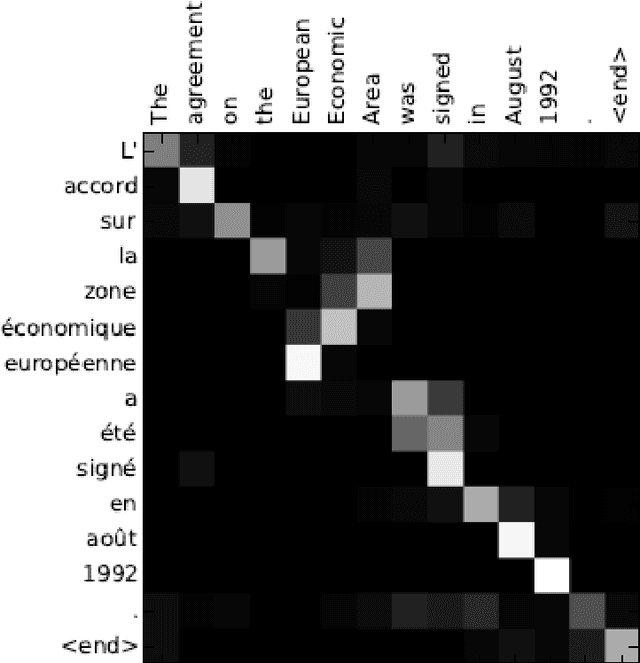

The internal workings of modern deep learning models stay often unclear to an external observer, although spatial attention mechanisms are involved. The idea of this work is to translate these spatial attentions into natural language to provide a simpler access to the model's function. Thus, I took a neural image captioning model and measured the reactions to external modification in its spatial attention for three different interface methods: a fixation over the whole generation process, a fixation for the first time-steps and an addition to the generator's attention. The experimental results for bounding box based spatial attention vectors have shown that the captioning model reacts to method dependent changes in up to 52.65% and includes in 9.00% of the cases object categories, which were otherwise unmentioned. Afterwards, I established such a link to a hierarchical co-attention network for visual question answering by extraction of its word, phrase and question level spatial attentions. Here, generated captions for the word level included details of the question-answer pairs in up to 55.20% of the cases. This work indicates that spatial attention seen as an external interface for image caption generators is an useful method to access visual functions in natural language.
Image Co-skeletonization via Co-segmentation
Apr 12, 2020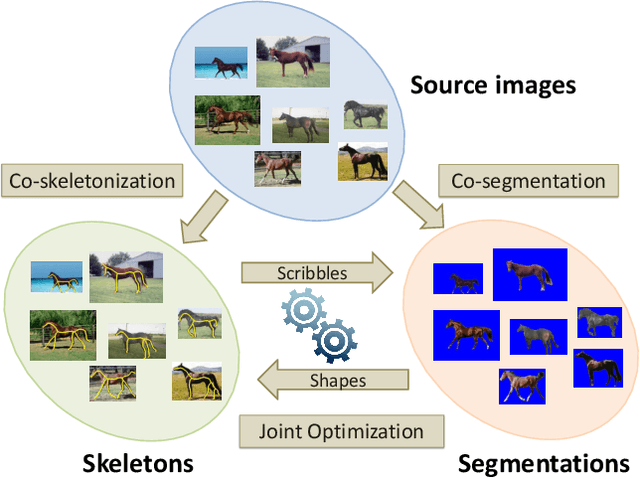


Recent advances in the joint processing of images have certainly shown its advantages over individual processing. Different from the existing works geared towards co-segmentation or co-localization, in this paper, we explore a new joint processing topic: image co-skeletonization, which is defined as joint skeleton extraction of objects in an image collection. Object skeletonization in a single natural image is a challenging problem because there is hardly any prior knowledge about the object. Therefore, we resort to the idea of object co-skeletonization, hoping that the commonness prior that exists across the images may help, just as it does for other joint processing problems such as co-segmentation. We observe that the skeleton can provide good scribbles for segmentation, and skeletonization, in turn, needs good segmentation. Therefore, we propose a coupled framework for co-skeletonization and co-segmentation tasks so that they are well informed by each other, and benefit each other synergistically. Since it is a new problem, we also construct a benchmark dataset by annotating nearly 1.8k images spread across 38 categories. Extensive experiments demonstrate that the proposed method achieves promising results in all the three possible scenarios of joint-processing: weakly-supervised, supervised, and unsupervised.