 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Robust Wavelet-based Assessment of Scaling with Applications
Jan 23, 2022
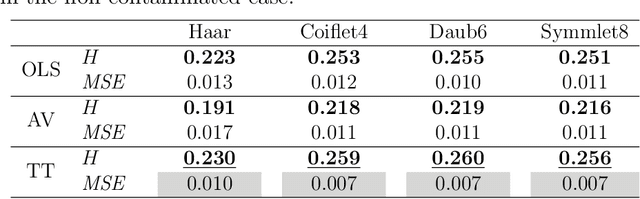
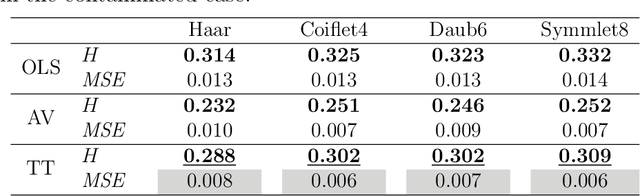
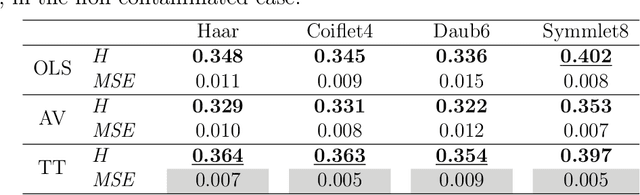
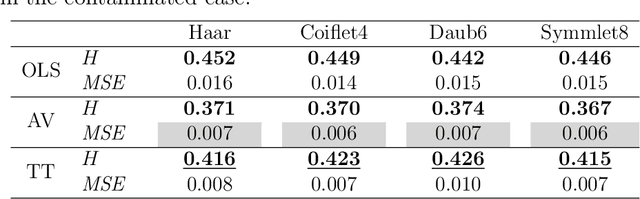
A number of approaches have dealt with statistical assessment of self-similarity, and many of those are based on multiscale concepts. Most rely on certain distributional assumptions which are usually violated by real data traces, often characterized by large temporal or spatial mean level shifts, missing values or extreme observations. A novel, robust approach based on Theil-type weighted regression is proposed for estimating self-similarity in two-dimensional data (images). The method is compared to two traditional estimation techniques that use wavelet decompositions; ordinary least squares (OLS) and Abry-Veitch bias correcting estimator (AV). As an application, the suitability of the self-similarity estimate resulting from the the robust approach is illustrated as a predictive feature in the classification of digitized mammogram images as cancerous or non-cancerous. The diagnostic employed here is based on the properties of image backgrounds, which is typically an unused modality in breast cancer screening. Classification results show nearly 68% accuracy, varying slightly with the choice of wavelet basis, and the range of multiresolution levels used.
TorchPRISM: Principal Image Sections Mapping, a novel method for Convolutional Neural Network features visualization
Jan 27, 2021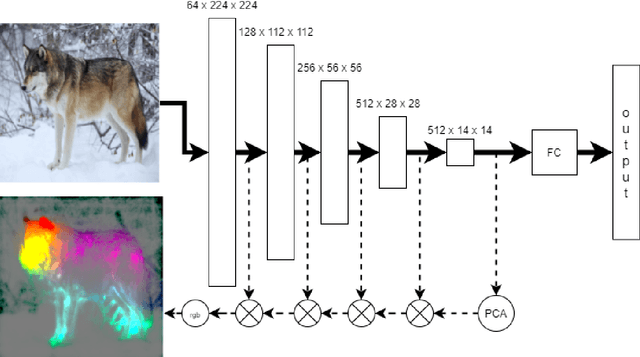


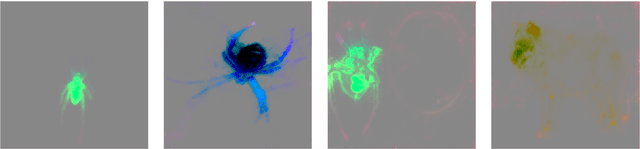
In this paper we introduce a tool called Principal Image Sections Mapping - PRISM, dedicated for PyTorch, but can be easily ported to other deep learning frameworks. Presented software relies on Principal Component Analysis to visualize the most significant features recognized by a given Convolutional Neural Network. Moreover, it allows to display comparative set features between images processed in the same batch, therefore PRISM can be a method well synerging with technique Explanation by Example.
A Content Transformation Block For Image Style Transfer
Mar 18, 2020
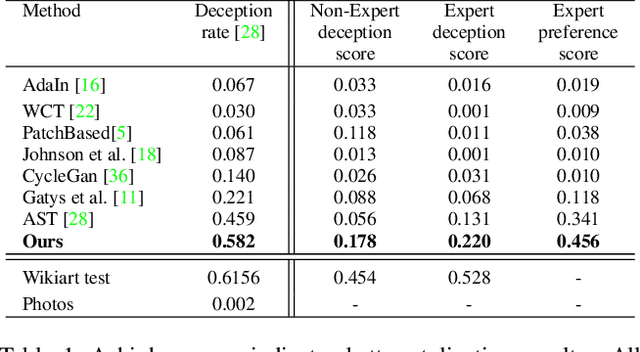
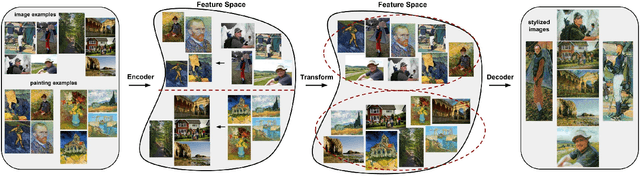
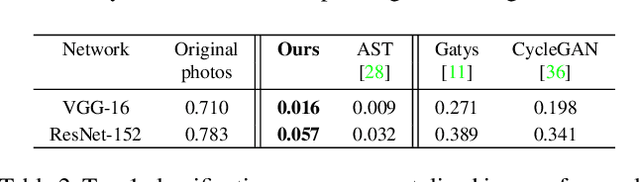
Style transfer has recently received a lot of attention, since it allows to study fundamental challenges in image understanding and synthesis. Recent work has significantly improved the representation of color and texture and computational speed and image resolution. The explicit transformation of image content has, however, been mostly neglected: while artistic style affects formal characteristics of an image, such as color, shape or texture, it also deforms, adds or removes content details. This paper explicitly focuses on a content-and style-aware stylization of a content image. Therefore, we introduce a content transformation module between the encoder and decoder. Moreover, we utilize similar content appearing in photographs and style samples to learn how style alters content details and we generalize this to other class details. Additionally, this work presents a novel normalization layer critical for high resolution image synthesis. The robustness and speed of our model enables a video stylization in real-time and high definition. We perform extensive qualitative and quantitative evaluations to demonstrate the validity of our approach.
Mitigating the Bias of Centered Objects in Common Datasets
Dec 16, 2021



Convolutional networks are considered shift invariant, but it was demonstrated that their response may vary according to the exact location of the objects. In this paper we will demonstrate that most commonly investigated datasets have a bias, where objects are over-represented at the center of the image during training. This bias and the boundary condition of these networks can have a significant effect on the performance of these architectures and their accuracy drops significantly as an object approaches the boundary. We will also demonstrate how this effect can be mitigated with data augmentation techniques.
SCOUTER: Slot Attention-based Classifier for Explainable Image Recognition
Sep 14, 2020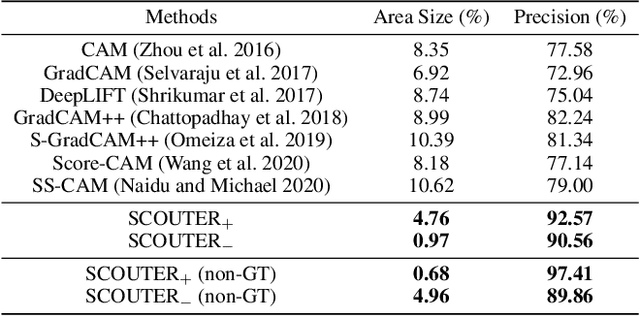
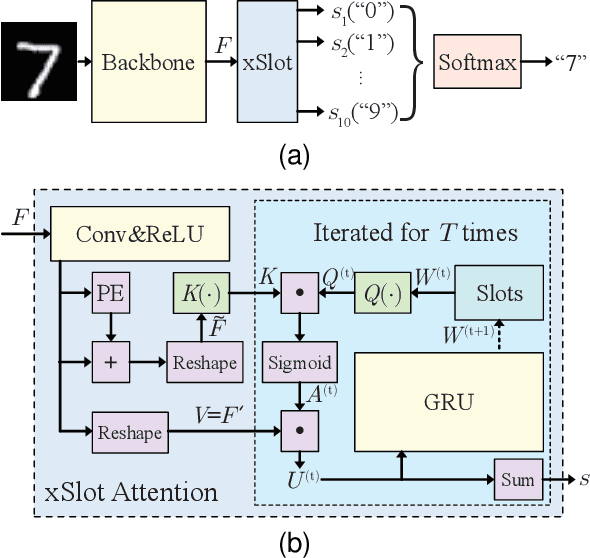
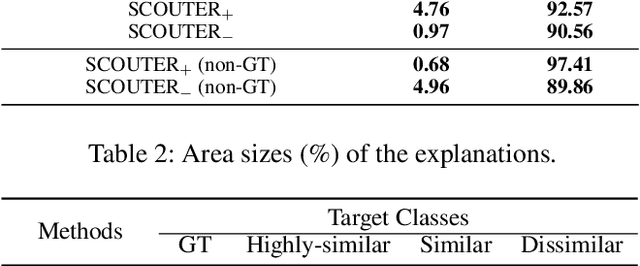

Explainable artificial intelligence is gaining attention. However, most existing methods are based on gradients or intermediate features, which are not directly involved in the decision-making process of the classifier. In this paper, we propose a slot attention-based light-weighted classifier called SCOUTER for transparent yet accurate classification. Two major differences from other attention-based methods include: (a) SCOUTER's explanation involves the final confidence for each category, offering more intuitive interpretation, and (b) all the categories have their corresponding positive or negative explanation, which tells "why the image is of a certain category" or "why the image is not of a certain category." We design a new loss tailored for SCOUTER that controls the model's behavior to switch between positive and negative explanations, as well as the size of explanatory regions. Experimental results show that SCOUTER can give better visual explanations while keeping good accuracy on a large dataset.
Nonlocal Adaptive Direction-Guided Structure Tensor Total Variation For Image Recovery
Aug 28, 2020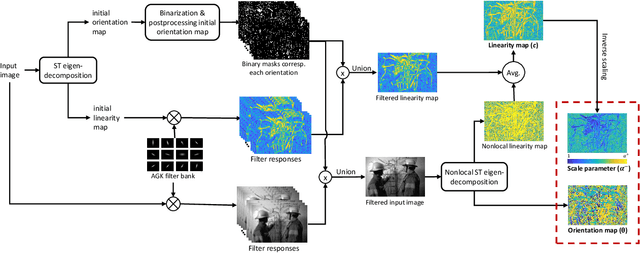
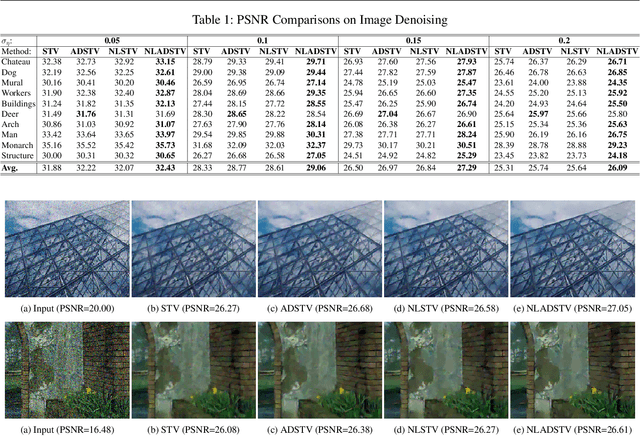

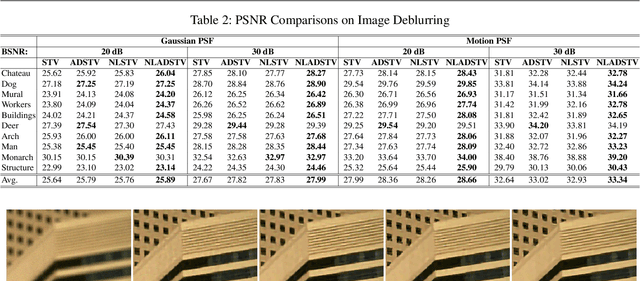
A common strategy in variational image recovery is utilizing the nonlocal self-similarity (NSS) property, when designing energy functionals. One such contribution is nonlocal structure tensor total variation (NLSTV), which lies at the core of this study. This paper is concerned with boosting the NLSTV regularization term through the use of directional priors. More specifically, NLSTV is leveraged so that, at each image point, it gains more sensitivity in the direction that is presumed to have the minimum local variation. The actual difficulty here is capturing this directional information from the corrupted image. In this regard, we propose a method that employs anisotropic Gaussian kernels to estimate directional features to be later used by our proposed model. The experiments validate that our entire two-stage framework achieves better results than the NLSTV model and two other competing local models, in terms of visual and quantitative evaluation.
Retinex-inspired Unrolling with Cooperative Prior Architecture Search for Low-light Image Enhancement
Dec 10, 2020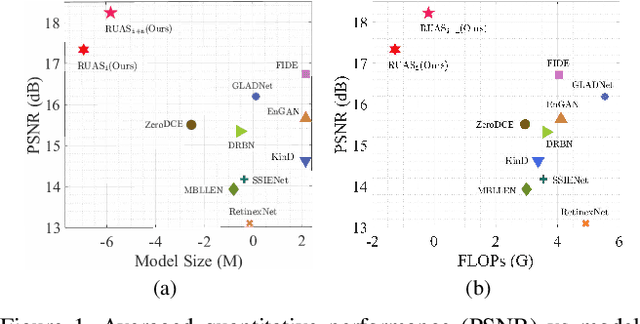

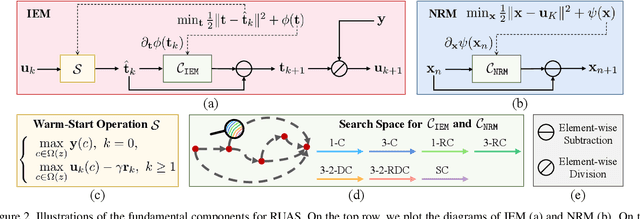

Low-light image enhancement plays very important roles in low-level vision field. Recent works have built a large variety of deep learning models to address this task. However, these approaches mostly rely on significant architecture engineering and suffer from high computational burden. In this paper, we propose a new method, named Retinex-inspired Unrolling with Architecture Search (RUAS), to construct lightweight yet effective enhancement network for low-light images in real-world scenario. Specifically, building upon Retinex rule, RUAS first establishes models to characterize the intrinsic underexposed structure of low-light images and unroll their optimization processes to construct our holistic propagation structure. Then by designing a cooperative reference-free learning strategy to discover low-light prior architectures from a compact search space, RUAS is able to obtain a top-performing image enhancement network, which is with fast speed and requires few computational resources. Extensive experiments verify the superiority of our RUAS framework against recently proposed state-of-the-art methods.
UniMS: A Unified Framework for Multimodal Summarization with Knowledge Distillation
Sep 13, 2021
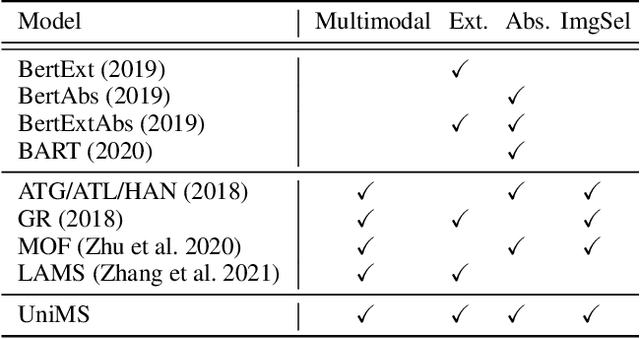
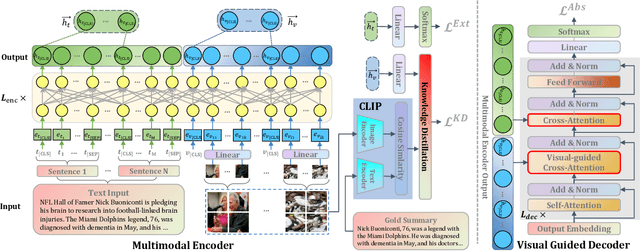
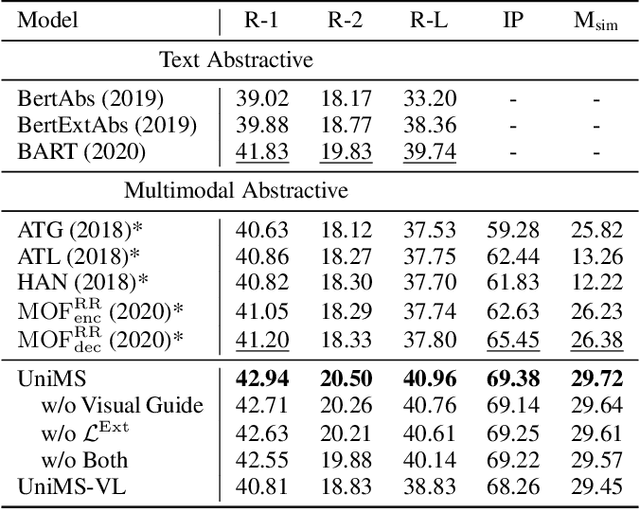
With the rapid increase of multimedia data, a large body of literature has emerged to work on multimodal summarization, the majority of which target at refining salient information from textual and visual modalities to output a pictorial summary with the most relevant images. Existing methods mostly focus on either extractive or abstractive summarization and rely on qualified image captions to build image references. We are the first to propose a Unified framework for Multimodal Summarization grounding on BART, UniMS, that integrates extractive and abstractive objectives, as well as selecting the image output. Specially, we adopt knowledge distillation from a vision-language pretrained model to improve image selection, which avoids any requirement on the existence and quality of image captions. Besides, we introduce a visual guided decoder to better integrate textual and visual modalities in guiding abstractive text generation. Results show that our best model achieves a new state-of-the-art result on a large-scale benchmark dataset. The newly involved extractive objective as well as the knowledge distillation technique are proven to bring a noticeable improvement to the multimodal summarization task.
Per Garment Capture and Synthesis for Real-time Virtual Try-on
Sep 10, 2021
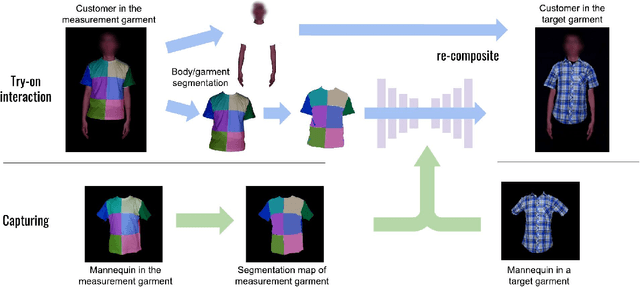


Virtual try-on is a promising application of computer graphics and human computer interaction that can have a profound real-world impact especially during this pandemic. Existing image-based works try to synthesize a try-on image from a single image of a target garment, but it inherently limits the ability to react to possible interactions. It is difficult to reproduce the change of wrinkles caused by pose and body size change, as well as pulling and stretching of the garment by hand. In this paper, we propose an alternative per garment capture and synthesis workflow to handle such rich interactions by training the model with many systematically captured images. Our workflow is composed of two parts: garment capturing and clothed person image synthesis. We designed an actuated mannequin and an efficient capturing process that collects the detailed deformations of the target garments under diverse body sizes and poses. Furthermore, we proposed to use a custom-designed measurement garment, and we captured paired images of the measurement garment and the target garments. We then learn a mapping between the measurement garment and the target garments using deep image-to-image translation. The customer can then try on the target garments interactively during online shopping.
On sensitivity of meta-learning to support data
Oct 26, 2021
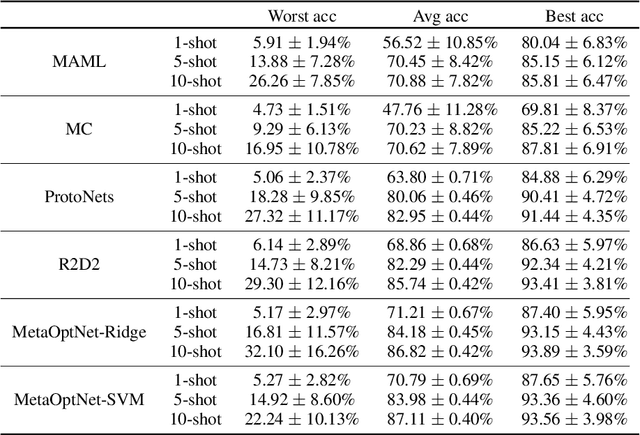

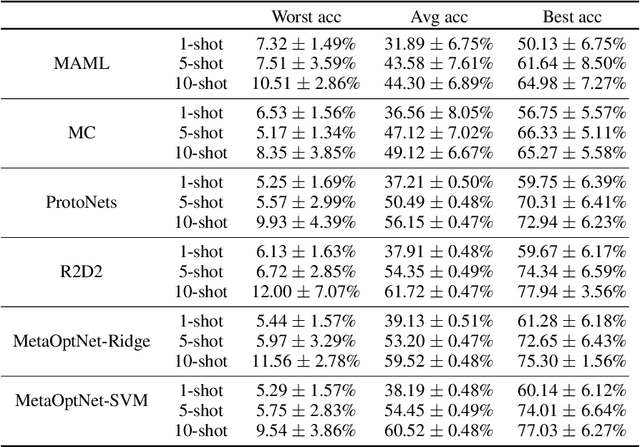
Meta-learning algorithms are widely used for few-shot learning. For example, image recognition systems that readily adapt to unseen classes after seeing only a few labeled examples. Despite their success, we show that modern meta-learning algorithms are extremely sensitive to the data used for adaptation, i.e. support data. In particular, we demonstrate the existence of (unaltered, in-distribution, natural) images that, when used for adaptation, yield accuracy as low as 4\% or as high as 95\% on standard few-shot image classification benchmarks. We explain our empirical findings in terms of class margins, which in turn suggests that robust and safe meta-learning requires larger margins than supervised learning.