 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting an Old Perspective Projection for Monocular 3D Morphable Models Regression
Mar 05, 2026We introduce a novel camera model for monocular 3D Morphable Model (3DMM) regression methods that effectively captures the perspective distortion effect commonly seen in close-up facial images. Fitting 3D morphable models to video is a key technique in content creation. In particular, regression-based approaches have produced fast and accurate results by matching the rendered output of the morphable model to the target image. These methods typically achieve stable performance with orthographic projection, which eliminates the ambiguity between focal length and object distance. However, this simplification makes them unsuitable for close-up footage, such as that captured with head-mounted cameras. We extend orthographic projection with a new shrinkage parameter, incorporating a pseudo-perspective effect while preserving the stability of the original projection. We present several techniques that allow finetuning of existing models, and demonstrate the effectiveness of our modification through both quantitative and qualitative comparisons using a custom dataset recorded with head-mounted cameras.
RoCap: A Robotic Data Collection Pipeline for the Pose Estimation of Appearance-Changing Objects
Jul 10, 2024



Object pose estimation plays a vital role in mixed-reality interactions when users manipulate tangible objects as controllers. Traditional vision-based object pose estimation methods leverage 3D reconstruction to synthesize training data. However, these methods are designed for static objects with diffuse colors and do not work well for objects that change their appearance during manipulation, such as deformable objects like plush toys, transparent objects like chemical flasks, reflective objects like metal pitchers, and articulated objects like scissors. To address this limitation, we propose Rocap, a robotic pipeline that emulates human manipulation of target objects while generating data labeled with ground truth pose information. The user first gives the target object to a robotic arm, and the system captures many pictures of the object in various 6D configurations. The system trains a model by using captured images and their ground truth pose information automatically calculated from the joint angles of the robotic arm. We showcase pose estimation for appearance-changing objects by training simple deep-learning models using the collected data and comparing the results with a model trained with synthetic data based on 3D reconstruction via quantitative and qualitative evaluation. The findings underscore the promising capabilities of Rocap.
Per Garment Capture and Synthesis for Real-time Virtual Try-on
Sep 10, 2021
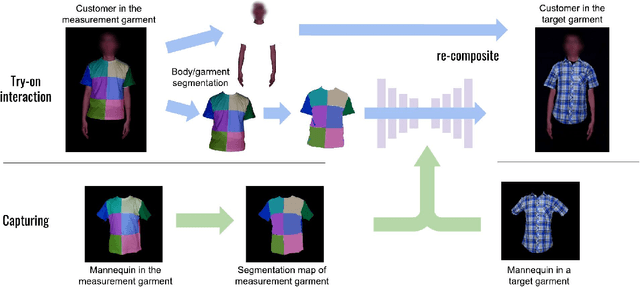


Virtual try-on is a promising application of computer graphics and human computer interaction that can have a profound real-world impact especially during this pandemic. Existing image-based works try to synthesize a try-on image from a single image of a target garment, but it inherently limits the ability to react to possible interactions. It is difficult to reproduce the change of wrinkles caused by pose and body size change, as well as pulling and stretching of the garment by hand. In this paper, we propose an alternative per garment capture and synthesis workflow to handle such rich interactions by training the model with many systematically captured images. Our workflow is composed of two parts: garment capturing and clothed person image synthesis. We designed an actuated mannequin and an efficient capturing process that collects the detailed deformations of the target garments under diverse body sizes and poses. Furthermore, we proposed to use a custom-designed measurement garment, and we captured paired images of the measurement garment and the target garments. We then learn a mapping between the measurement garment and the target garments using deep image-to-image translation. The customer can then try on the target garments interactively during online shopping.
AugLimb: Compact Robotic Limb for Human Augmentation
Sep 01, 2021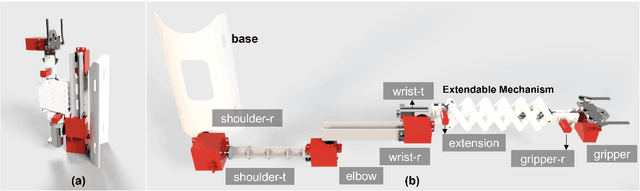

This work proposes a compact robotic limb, AugLimb, that can augment our body functions and support the daily activities. AugLimb adopts the double-layer scissor unit for the extendable mechanism which can achieve 2.5 times longer than the forearm length. The proposed device can be mounted on the user's upper arm, and transform into compact state without obstruction to wearers. The proposed device is lightweight with low burden exerted on the wearer. We developed the prototype of AugLimb to demonstrate the proposed mechanisms. We believe that the design methodology of AugLimb can facilitate human augmentation research for practical use. see http://www.jaist.ac.jp/~xie/auglimb.html
Exploring a Makeup Support System for Transgender Passing based on Automatic Gender Recognition
Mar 08, 2021
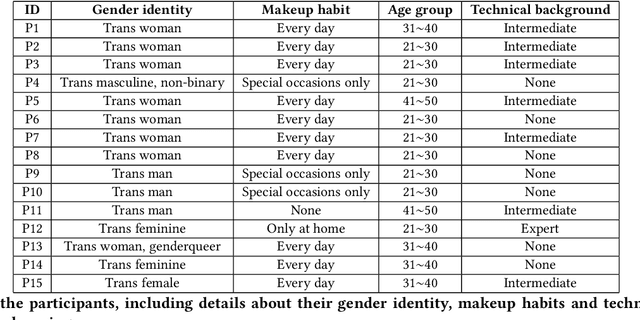
How to handle gender with machine learning is a controversial topic. A growing critical body of research brought attention to the numerous issues transgender communities face with the adoption of current automatic gender recognition (AGR) systems. In contrast, we explore how such technologies could potentially be appropriated to support transgender practices and needs, especially in non-Western contexts like Japan. We designed a virtual makeup probe to assist transgender individuals with passing, that is to be perceived as the gender they identify as. To understand how such an application might support expressing transgender individuals gender identity or not, we interviewed 15 individuals in Tokyo and found that in the right context and under strict conditions, AGR based systems could assist transgender passing.