 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Cellular automata can classify data by inducing trajectory phase coexistence
Mar 10, 2022
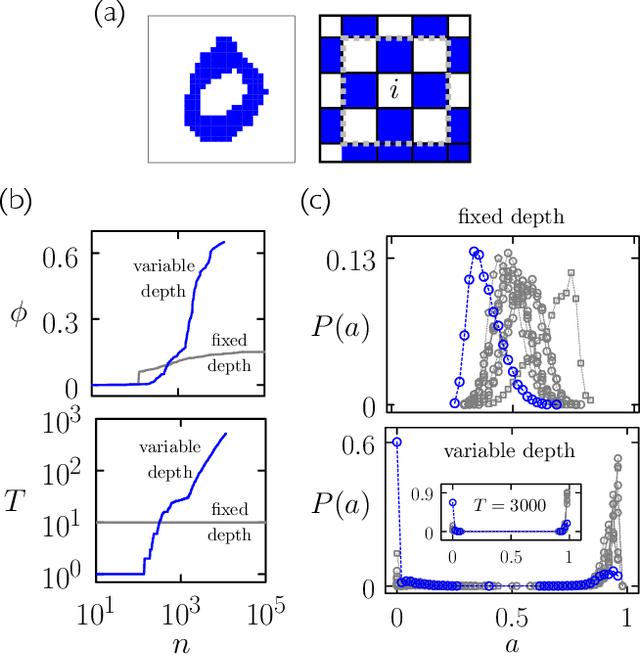
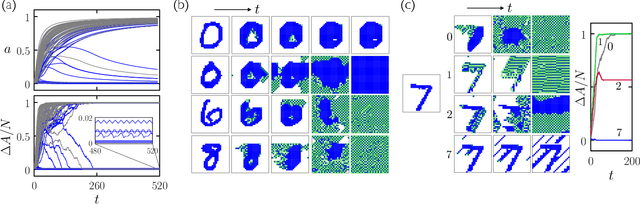
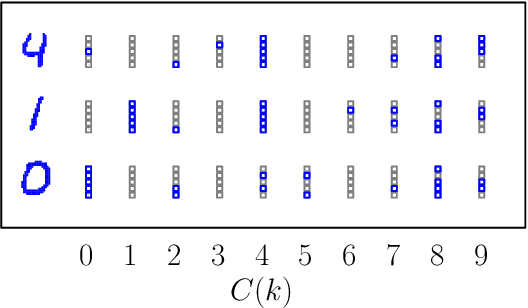
We show that cellular automata can classify data by inducing a form of dynamical phase coexistence. We use Monte Carlo methods to search for general two-dimensional deterministic automata that classify images on the basis of activity, the number of state changes that occur in a trajectory initiated from the image. When the depth of the automaton is a trainable parameter, the search scheme identifies automata that generate a population of dynamical trajectories displaying high or low activity, depending on initial conditions. Automata of this nature behave as nonlinear activation functions with an output that is effectively binary, resembling an emergent version of a spiking neuron. Our work connects machine learning and reservoir computing to phenomena conceptually similar to those seen in physical systems such as magnets and glasses.
Fine-Grained Predicates Learning for Scene Graph Generation
Apr 08, 2022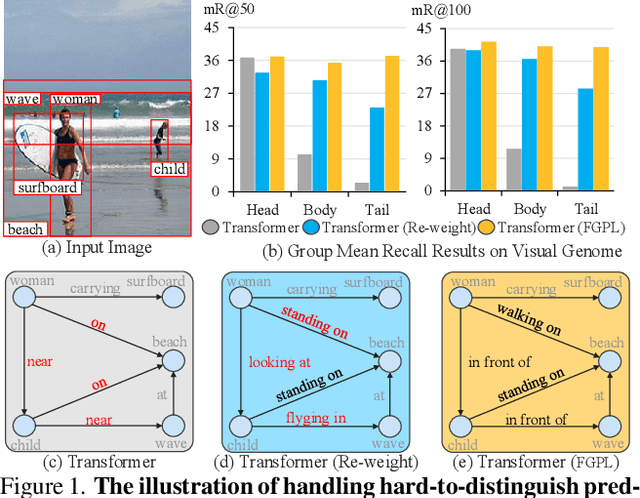
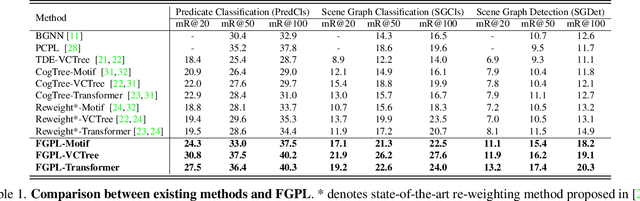
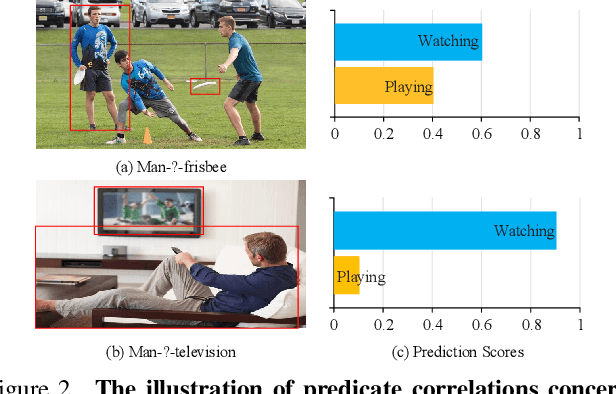
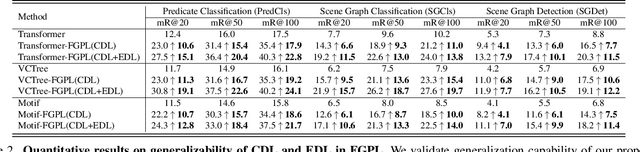
The performance of current Scene Graph Generation models is severely hampered by some hard-to-distinguish predicates, e.g., "woman-on/standing on/walking on-beach" or "woman-near/looking at/in front of-child". While general SGG models are prone to predict head predicates and existing re-balancing strategies prefer tail categories, none of them can appropriately handle these hard-to-distinguish predicates. To tackle this issue, inspired by fine-grained image classification, which focuses on differentiating among hard-to-distinguish object classes, we propose a method named Fine-Grained Predicates Learning (FGPL) which aims at differentiating among hard-to-distinguish predicates for Scene Graph Generation task. Specifically, we first introduce a Predicate Lattice that helps SGG models to figure out fine-grained predicate pairs. Then, utilizing the Predicate Lattice, we propose a Category Discriminating Loss and an Entity Discriminating Loss, which both contribute to distinguishing fine-grained predicates while maintaining learned discriminatory power over recognizable ones. The proposed model-agnostic strategy significantly boosts the performances of three benchmark models (Transformer, VCTree, and Motif) by 22.8\%, 24.1\% and 21.7\% of Mean Recall (mR@100) on the Predicate Classification sub-task, respectively. Our model also outperforms state-of-the-art methods by a large margin (i.e., 6.1\%, 4.6\%, and 3.2\% of Mean Recall (mR@100)) on the Visual Genome dataset.
Why adversarial training can hurt robust accuracy
Mar 03, 2022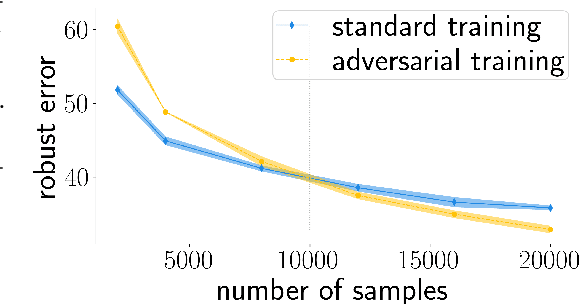

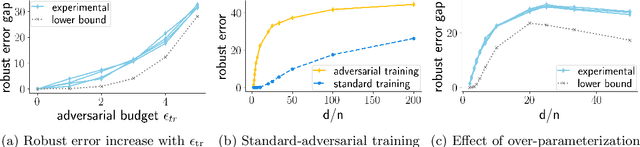
Machine learning classifiers with high test accuracy often perform poorly under adversarial attacks. It is commonly believed that adversarial training alleviates this issue. In this paper, we demonstrate that, surprisingly, the opposite may be true -- Even though adversarial training helps when enough data is available, it may hurt robust generalization in the small sample size regime. We first prove this phenomenon for a high-dimensional linear classification setting with noiseless observations. Our proof provides explanatory insights that may also transfer to feature learning models. Further, we observe in experiments on standard image datasets that the same behavior occurs for perceptible attacks that effectively reduce class information such as mask attacks and object corruptions.
IAE-Net: Integral Autoencoders for Discretization-Invariant Learning
Mar 30, 2022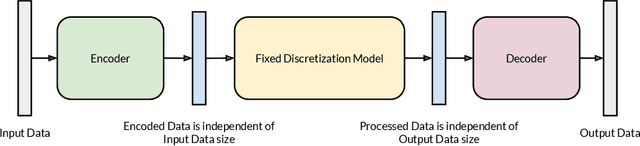

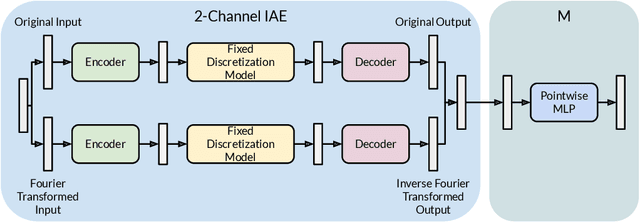

Discretization invariant learning aims at learning in the infinite-dimensional function spaces with the capacity to process heterogeneous discrete representations of functions as inputs and/or outputs of a learning model. This paper proposes a novel deep learning framework based on integral autoencoders (IAE-Net) for discretization invariant learning. The basic building block of IAE-Net consists of an encoder and a decoder as integral transforms with data-driven kernels, and a fully connected neural network between the encoder and decoder. This basic building block is applied in parallel in a wide multi-channel structure, which are repeatedly composed to form a deep and densely connected neural network with skip connections as IAE-Net. IAE-Net is trained with randomized data augmentation that generates training data with heterogeneous structures to facilitate the performance of discretization invariant learning. The proposed IAE-Net is tested with various applications in predictive data science, solving forward and inverse problems in scientific computing, and signal/image processing. Compared with alternatives in the literature, IAE-Net achieves state-of-the-art performance in existing applications and creates a wide range of new applications.
Vision Transformer Compression with Structured Pruning and Low Rank Approximation
Mar 25, 2022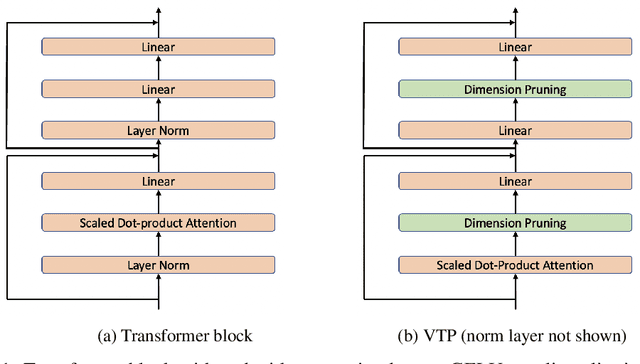
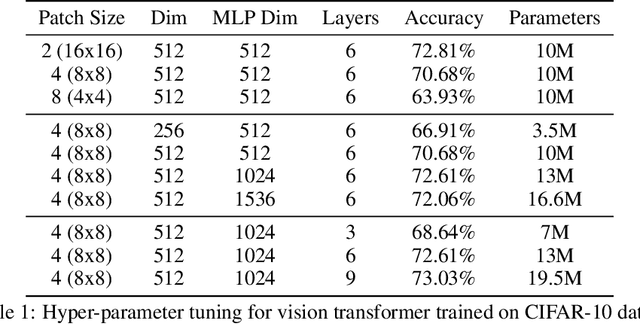
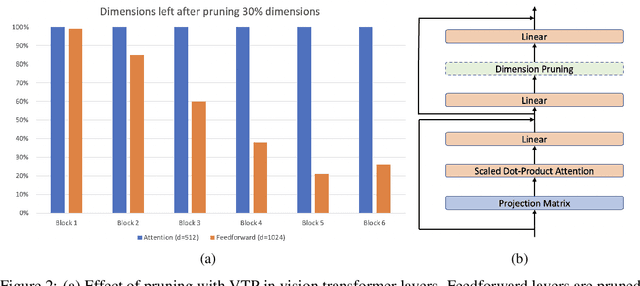
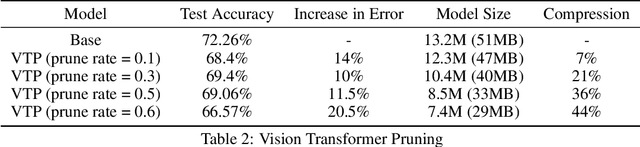
Transformer architecture has gained popularity due to its ability to scale with large dataset. Consequently, there is a need to reduce the model size and latency, especially for on-device deployment. We focus on vision transformer proposed for image recognition task (Dosovitskiy et al., 2021), and explore the application of different compression techniques such as low rank approximation and pruning for this purpose. Specifically, we investigate a structured pruning method proposed recently in Zhu et al. (2021) and find that mostly feedforward blocks are pruned with this approach, that too, with severe degradation in accuracy. We propose a hybrid compression approach to mitigate this where we compress the attention blocks using low rank approximation and use the previously mentioned pruning with a lower rate for feedforward blocks in each transformer layer. Our technique results in 50% compression with 14% relative increase in classification error whereas we obtain 44% compression with 20% relative increase in error when only pruning is applied. We propose further enhancements to bridge the accuracy gap but leave it as a future work.
A Structurally Regularized Convolutional Neural Network for Image Classification using Wavelet-based SubBand Decomposition
Mar 02, 2021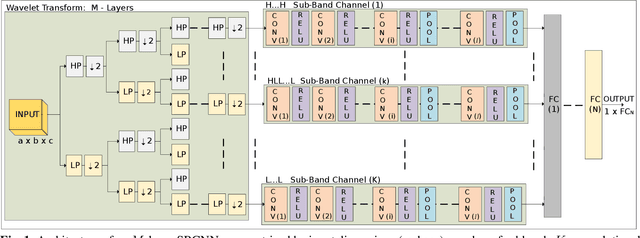
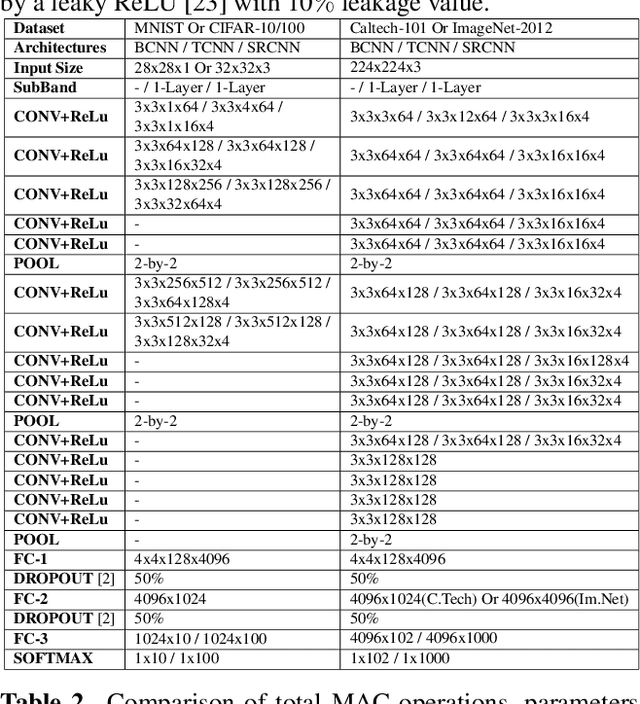
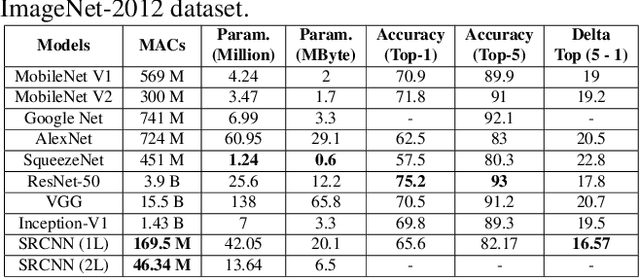
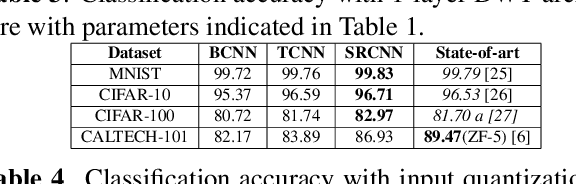
We propose a convolutional neural network (CNN) architecture for image classification based on subband decomposition of the image using wavelets. The proposed architecture decomposes the input image spectra into multiple critically sampled subbands, extracts features using a single CNN per subband, and finally, performs classification by combining the extracted features using a fully connected layer. Processing each of the subbands by an individual CNN, thereby limiting the learning scope of each CNN to a single subband, imposes a form of structural regularization. This provides better generalization capability as seen by the presented results. The proposed architecture achieves best-in-class performance in terms of total multiply-add-accumulator operations and nearly best-in-class performance in terms of total parameters required, yet it maintains competitive classification performance. We also show the proposed architecture is more robust than the regular full-band CNN to noise caused by weight-and-bias quantization and input quantization.
Protecting Celebrities with Identity Consistency Transformer
Mar 03, 2022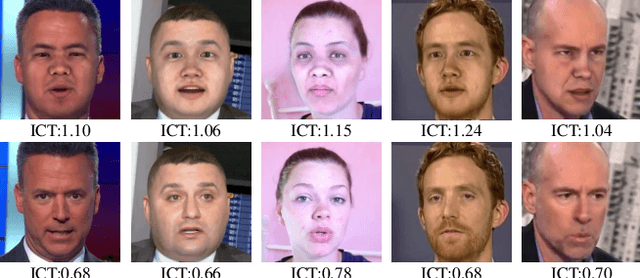
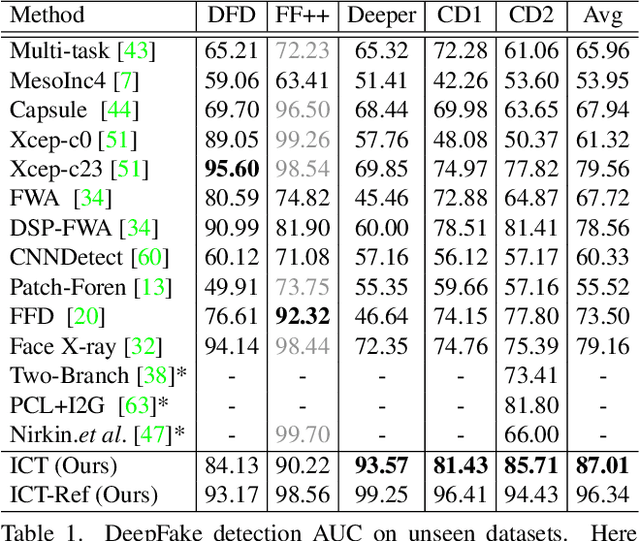

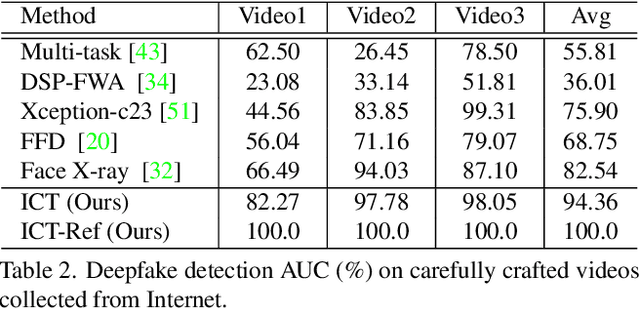
In this work we propose Identity Consistency Transformer, a novel face forgery detection method that focuses on high-level semantics, specifically identity information, and detecting a suspect face by finding identity inconsistency in inner and outer face regions. The Identity Consistency Transformer incorporates a consistency loss for identity consistency determination. We show that Identity Consistency Transformer exhibits superior generalization ability not only across different datasets but also across various types of image degradation forms found in real-world applications including deepfake videos. The Identity Consistency Transformer can be easily enhanced with additional identity information when such information is available, and for this reason it is especially well-suited for detecting face forgeries involving celebrities.
BankNote-Net: Open dataset for assistive universal currency recognition
Apr 07, 2022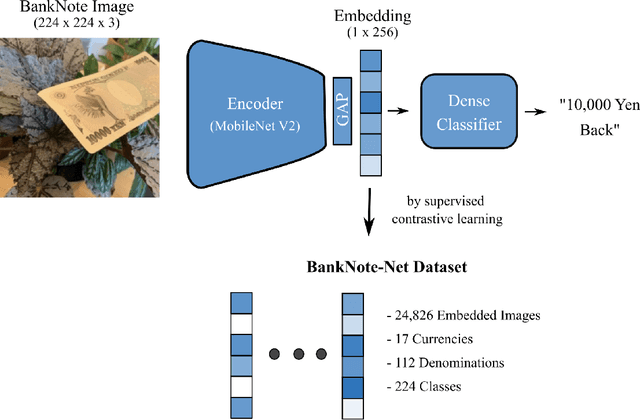
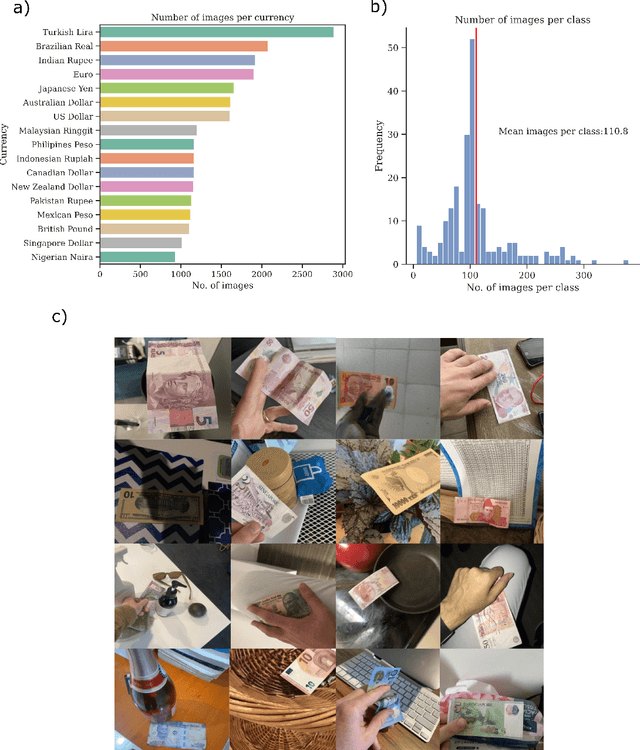
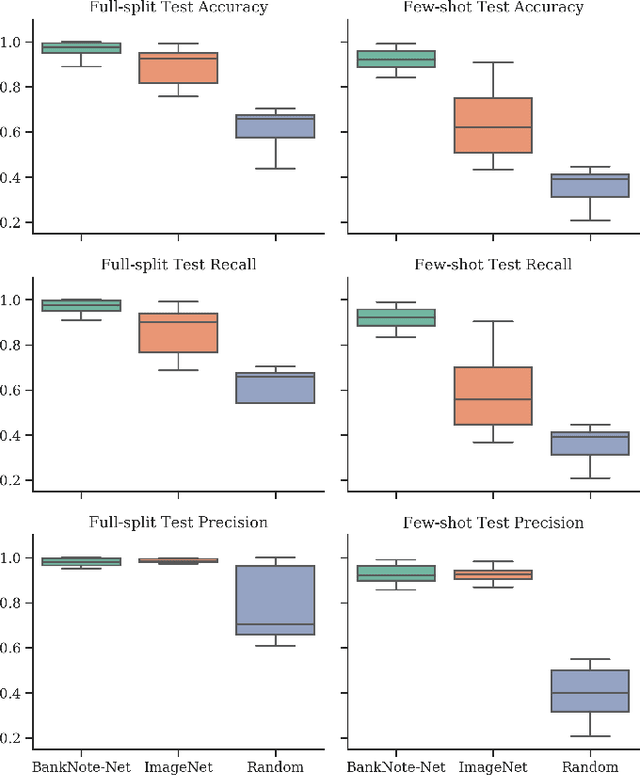
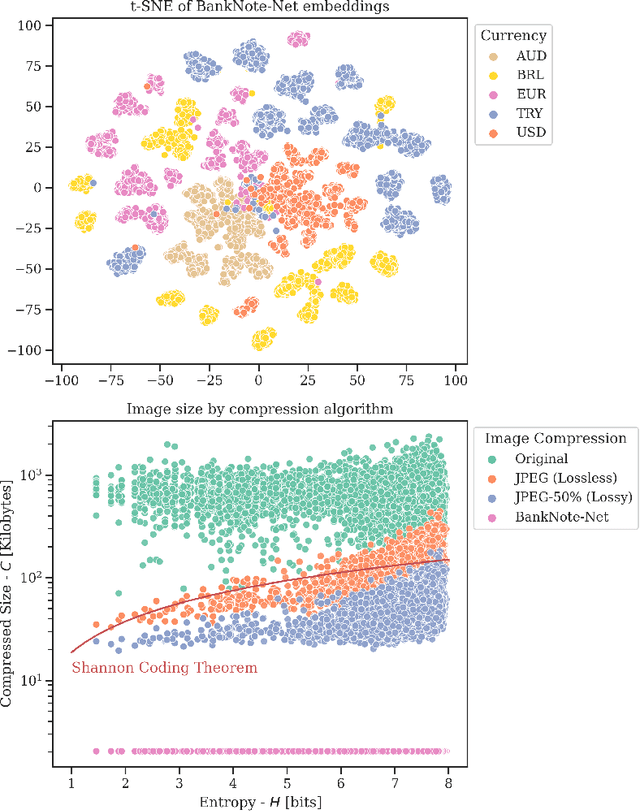
Millions of people around the world have low or no vision. Assistive software applications have been developed for a variety of day-to-day tasks, including optical character recognition, scene identification, person recognition, and currency recognition. This last task, the recognition of banknotes from different denominations, has been addressed by the use of computer vision models for image recognition. However, the datasets and models available for this task are limited, both in terms of dataset size and in variety of currencies covered. In this work, we collect a total of 24,826 images of banknotes in variety of assistive settings, spanning 17 currencies and 112 denominations. Using supervised contrastive learning, we develop a machine learning model for universal currency recognition. This model learns compliant embeddings of banknote images in a variety of contexts, which can be shared publicly (as a compressed vector representation), and can be used to train and test specialized downstream models for any currency, including those not covered by our dataset or for which only a few real images per denomination are available (few-shot learning). We deploy a variation of this model for public use in the last version of the Seeing AI app developed by Microsoft. We share our encoder model and the embeddings as an open dataset in our BankNote-Net repository.
Fast and Scalable Computation of the Forward and Inverse Discrete Periodic Radon Transform
Dec 24, 2021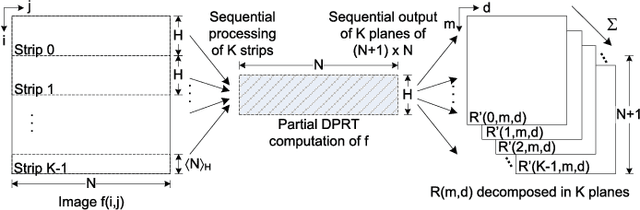
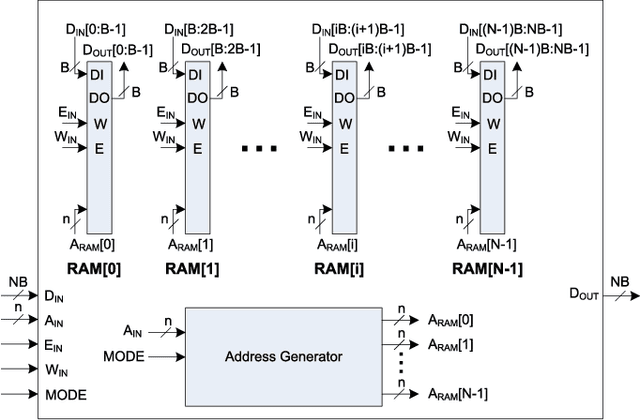

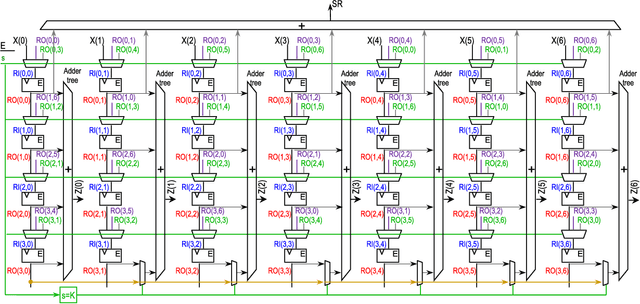
The Discrete Periodic Radon Transform (DPRT) has been extensively used in applications that involve image reconstructions from projections. This manuscript introduces a fast and scalable approach for computing the forward and inverse DPRT that is based on the use of: (i) a parallel array of fixed-point adder trees, (ii) circular shift registers to remove the need for accessing external memory components when selecting the input data for the adder trees, (iii) an image block-based approach to DPRT computation that can fit the proposed architecture to available resources, and (iv) fast transpositions that are computed in one or a few clock cycles that do not depend on the size of the input image. As a result, for an $N\times N$ image ($N$ prime), the proposed approach can compute up to $N^{2}$ additions per clock cycle. Compared to previous approaches, the scalable approach provides the fastest known implementations for different amounts of computational resources. For example, for a $251\times 251$ image, for approximately $25\%$ fewer flip-flops than required for a systolic implementation, we have that the scalable DPRT is computed 36 times faster. For the fastest case, we introduce optimized architectures that can compute the DPRT and its inverse in just $2N+\left\lceil \log_{2}N\right\rceil+1$ and $2N+3\left\lceil \log_{2}N\right\rceil+B+2$ cycles respectively, where $B$ is the number of bits used to represent each input pixel. On the other hand, the scalable DPRT approach requires more 1-bit additions than for the systolic implementation and provides a trade-off between speed and additional 1-bit additions. All of the proposed DPRT architectures were implemented in VHDL and validated using an FPGA implementation.
* This paper has been published as follows: C. Carranza, D. Llamocca, and M. Pattichis. "Fast and scalable computation of the forward and inverse discrete periodic radon transform", IEEE Transactions on Image Processing, 25(1):119-133, Jan 2016
PAT image reconstruction using augmented sparsity regularization with semi-automated tuning of regularization weight
Mar 24, 2021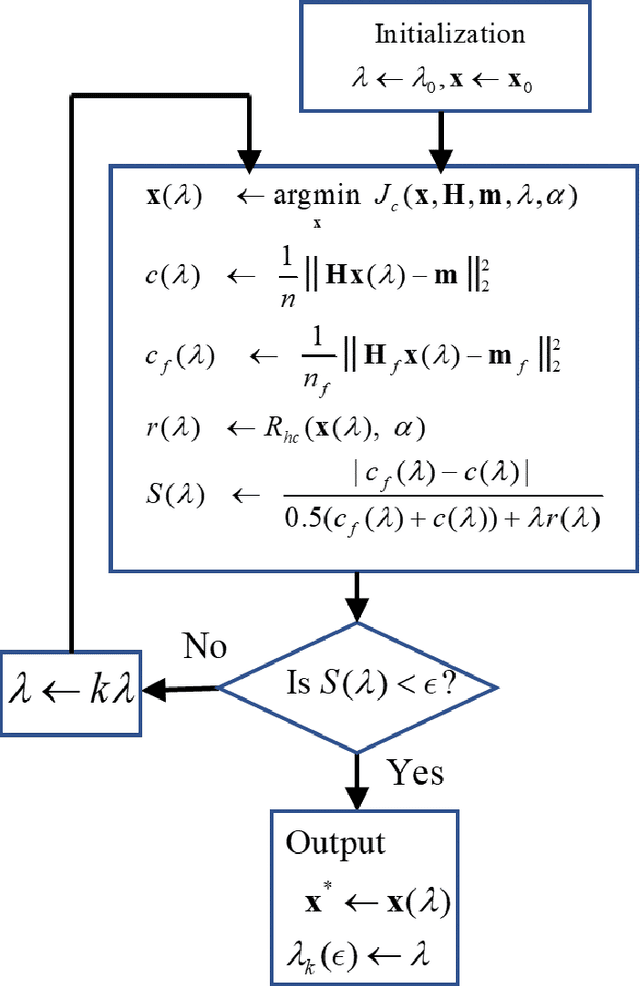
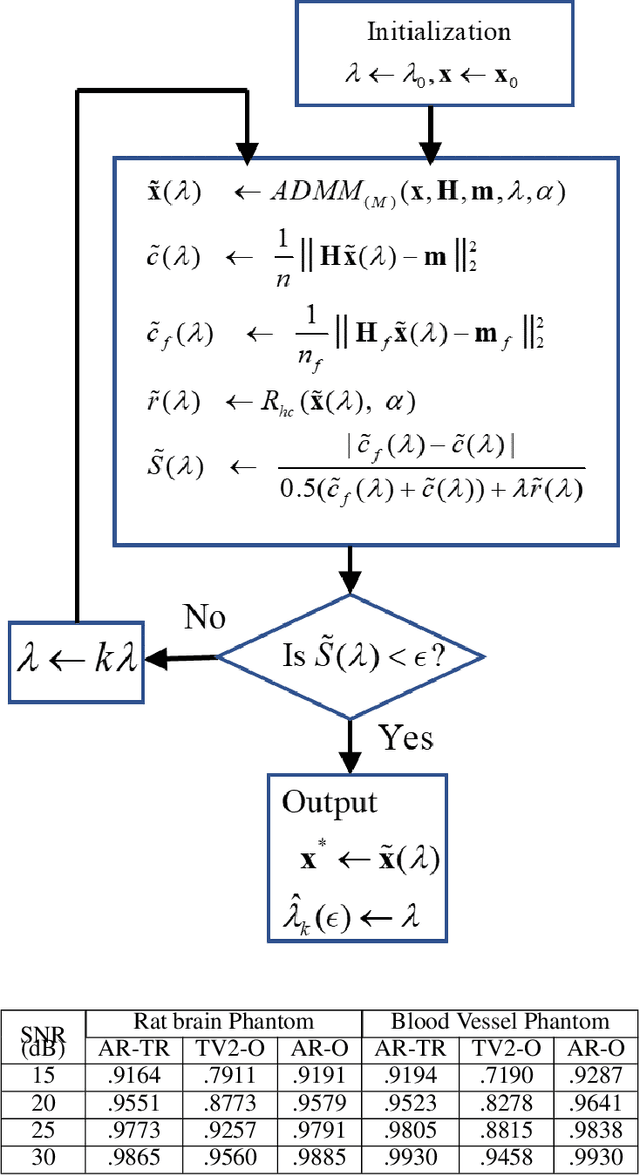
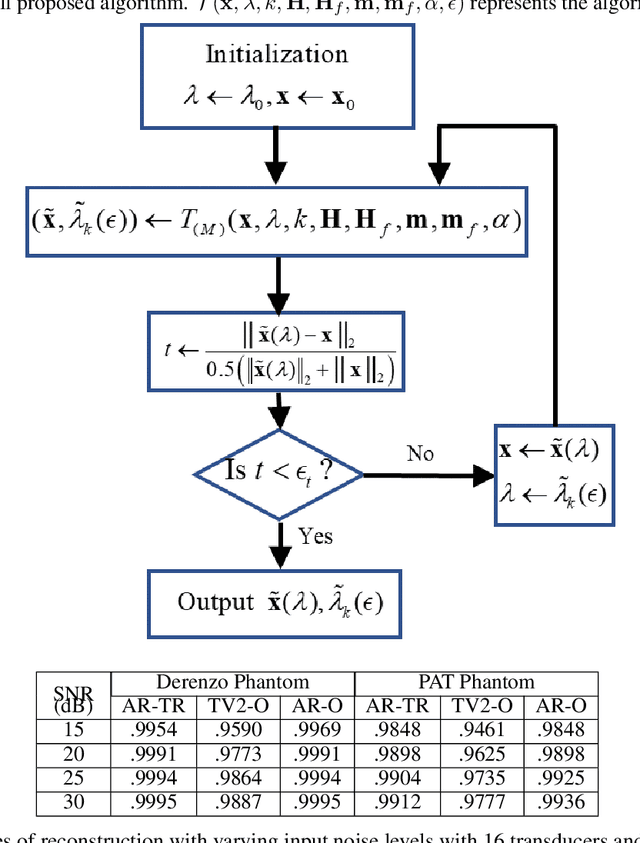
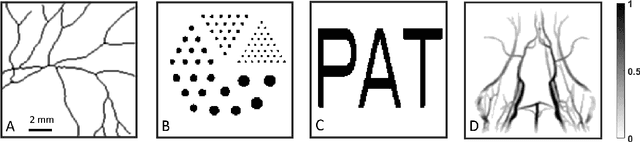
Among all tissue imaging modalities, photo-acoustic tomography (PAT) has been getting increasing attention in the recent past due to the fact that it has high contrast, high penetrability, and has capability of retrieving high resolution. The reconstruction methods used in PAT plays a crucial role in the applicability of PAT, and PAT finds particularly a wider applicability if a model-based regularized reconstruction method is used. A crucial factor that determines the quality of reconstruction in such methods is the choice of regularization weight. Unfortunately, an appropriately tuned value of regularization weight varies significantly with variation in the noise level, as well as, with the variation in the high resolution contents of the image, in a way that has not been well understood. There has been attempts to determine optimum regularization weight from the measured data in the context of using elementary and general purpose regularizations. In this paper, we develop a method for semi-automated tuning of the regularization weight in the context of using a modern type of regularization that was specifically designed for PAT image reconstruction. As a first step, we introduce a relative smoothness constraint with a parameter; this parameter computationally maps into the actual regularization weight, but, its tuning does not vary significantly with variation in the noise level, and with the variation in the high resolution contents of the image. Next, we construct an algorithm that integrates the task of determining this mapping along with obtaining the reconstruction. Finally we demonstrate experimentally that we can run this algorithm with a nominal value of the relative smoothness parameter -- a value independent of the noise level and the structure of the underlying image -- to obtain good quality reconstructions.