 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
You Only Cut Once: Boosting Data Augmentation with a Single Cut
Jan 28, 2022

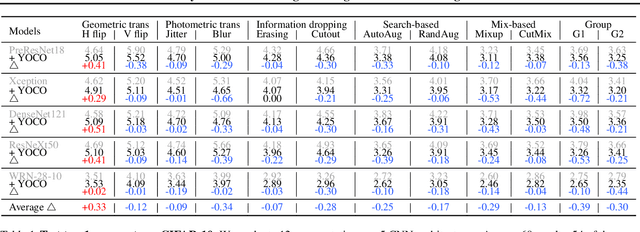

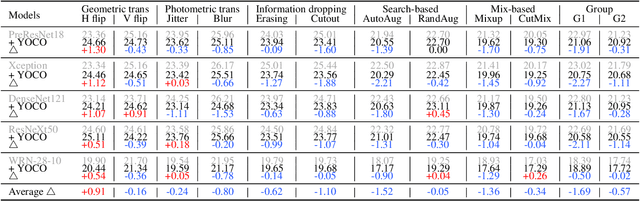
We present You Only Cut Once (YOCO) for performing data augmentations. YOCO cuts one image into two pieces and performs data augmentations individually within each piece. Applying YOCO improves the diversity of the augmentation per sample and encourages neural networks to recognize objects from partial information. YOCO enjoys the properties of parameter-free, easy usage, and boosting almost all augmentations for free. Thorough experiments are conducted to evaluate its effectiveness. We first demonstrate that YOCO can be seamlessly applied to varying data augmentations, neural network architectures, and brings performance gains on CIFAR and ImageNet classification tasks, sometimes surpassing conventional image-level augmentation by large margins. Moreover, we show YOCO benefits contrastive pre-training toward a more powerful representation that can be better transferred to multiple downstream tasks. Finally, we study a number of variants of YOCO and empirically analyze the performance for respective settings. Code is available at GitHub.
Blended Diffusion for Text-driven Editing of Natural Images
Nov 29, 2021
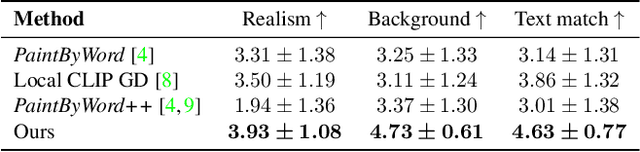
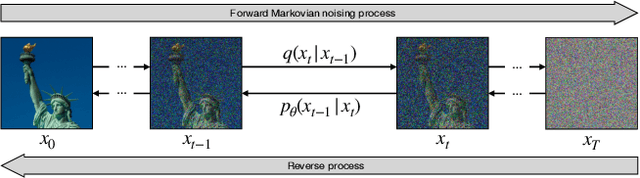
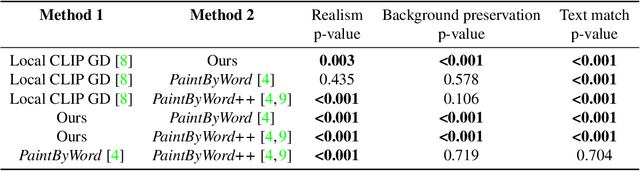
Natural language offers a highly intuitive interface for image editing. In this paper, we introduce the first solution for performing local (region-based) edits in generic natural images, based on a natural language description along with an ROI mask. We achieve our goal by leveraging and combining a pretrained language-image model (CLIP), to steer the edit towards a user-provided text prompt, with a denoising diffusion probabilistic model (DDPM) to generate natural-looking results. To seamlessly fuse the edited region with the unchanged parts of the image, we spatially blend noised versions of the input image with the local text-guided diffusion latent at a progression of noise levels. In addition, we show that adding augmentations to the diffusion process mitigates adversarial results. We compare against several baselines and related methods, both qualitatively and quantitatively, and show that our method outperforms these solutions in terms of overall realism, ability to preserve the background and matching the text. Finally, we show several text-driven editing applications, including adding a new object to an image, removing/replacing/altering existing objects, background replacement, and image extrapolation.
Learning Program Representations for Food Images and Cooking Recipes
Mar 30, 2022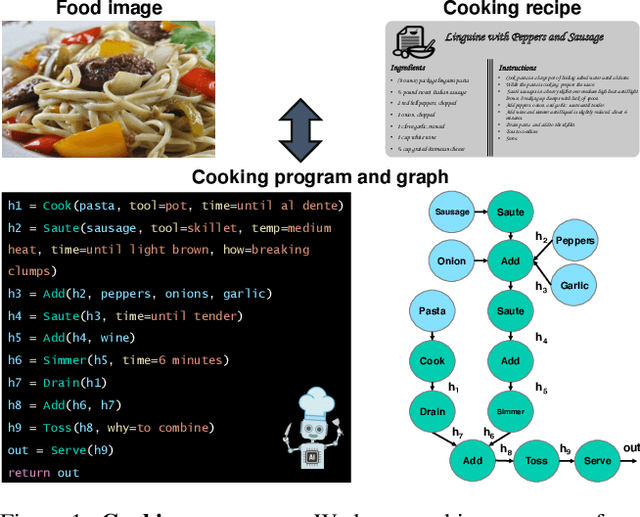
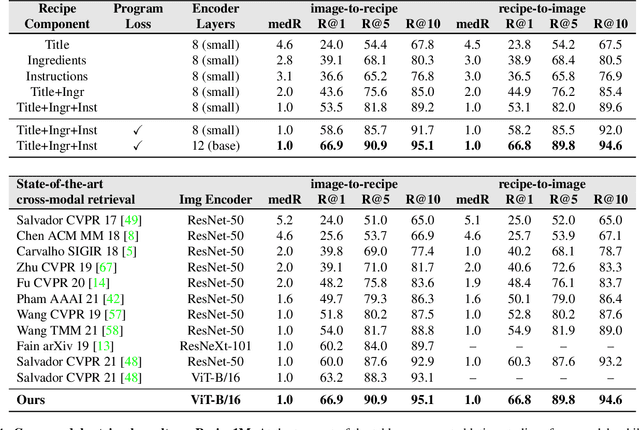
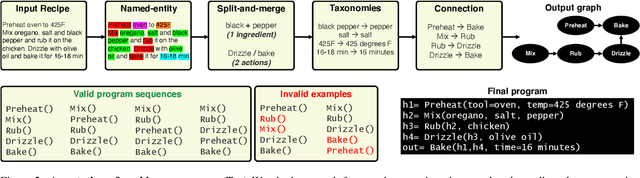
In this paper, we are interested in modeling a how-to instructional procedure, such as a cooking recipe, with a meaningful and rich high-level representation. Specifically, we propose to represent cooking recipes and food images as cooking programs. Programs provide a structured representation of the task, capturing cooking semantics and sequential relationships of actions in the form of a graph. This allows them to be easily manipulated by users and executed by agents. To this end, we build a model that is trained to learn a joint embedding between recipes and food images via self-supervision and jointly generate a program from this embedding as a sequence. To validate our idea, we crowdsource programs for cooking recipes and show that: (a) projecting the image-recipe embeddings into programs leads to better cross-modal retrieval results; (b) generating programs from images leads to better recognition results compared to predicting raw cooking instructions; and (c) we can generate food images by manipulating programs via optimizing the latent code of a GAN. Code, data, and models are available online.
Self-Normalized Density Map (SNDM) for Counting Microbiological Objects
Mar 15, 2022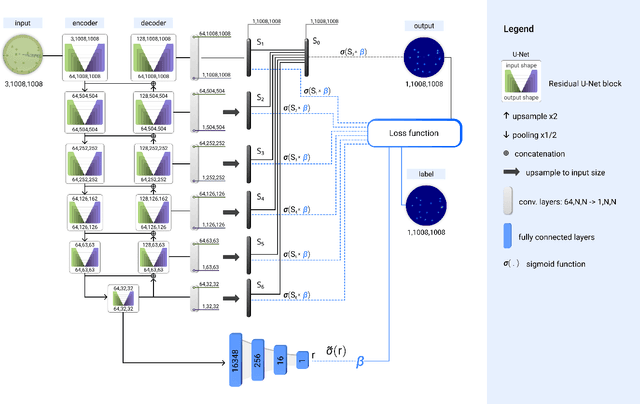
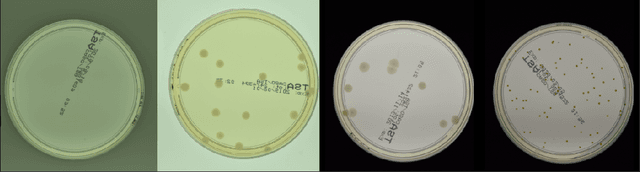
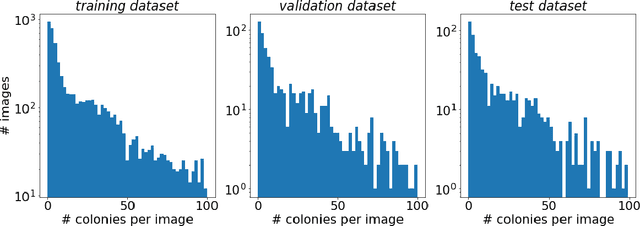
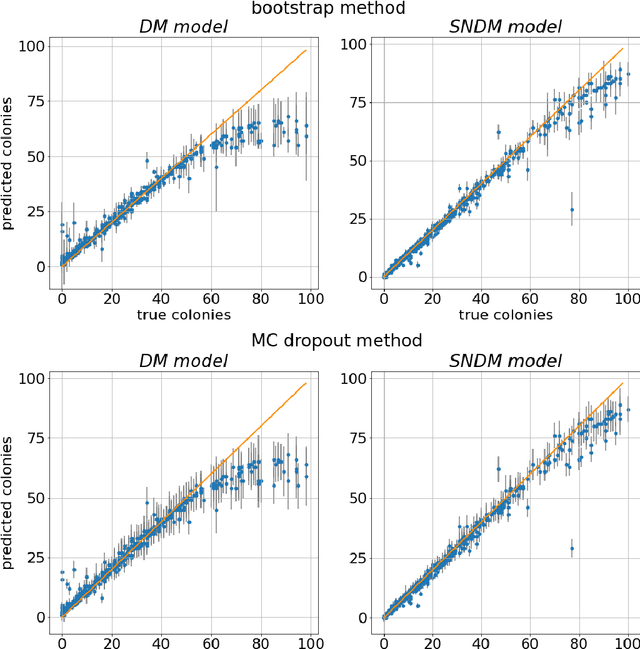
The statistical properties of the density map (DM) approach to counting microbiological objects on images are studied in detail. The DM is given by U$^2$-Net. Two statistical methods for deep neural networks are utilized: the bootstrap and the Monte Carlo (MC) dropout. The detailed analysis of the uncertainties for the DM predictions leads to a deeper understanding of the DM model's deficiencies. Based on our investigation, we propose a self-normalization module in the network. The improved network model, called Self-Normalized Density Map (SNDM), can correct its output density map by itself to accurately predict the total number of objects in the image. The SNDM architecture outperforms the original model. Moreover, both statistical frameworks -- bootstrap and MC dropout -- have consistent statistical results for SNDM, which were not observed in the original model.
SS-3DCapsNet: Self-supervised 3D Capsule Networks for Medical Segmentation on Less Labeled Data
Jan 15, 2022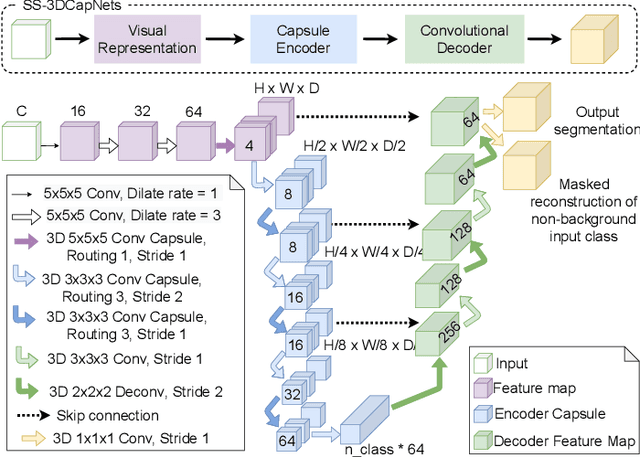
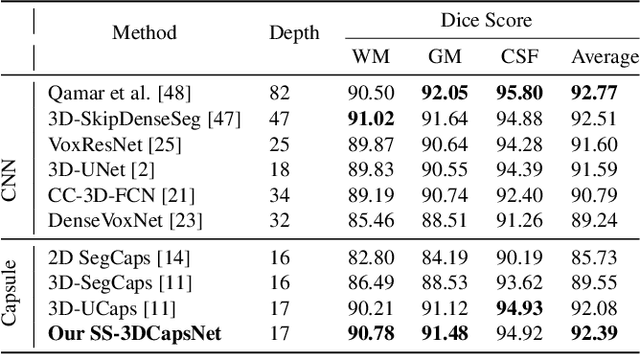
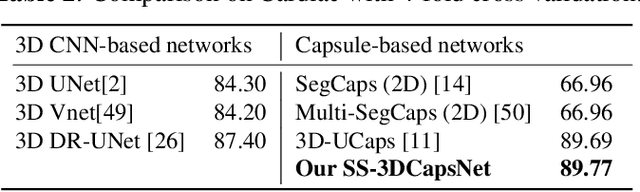
Capsule network is a recent new deep network architecture that has been applied successfully for medical image segmentation tasks. This work extends capsule networks for volumetric medical image segmentation with self-supervised learning. To improve on the problem of weight initialization compared to previous capsule networks, we leverage self-supervised learning for capsule networks pre-training, where our pretext-task is optimized by self-reconstruction. Our capsule network, SS-3DCapsNet, has a UNet-based architecture with a 3D Capsule encoder and 3D CNNs decoder. Our experiments on multiple datasets including iSeg-2017, Hippocampus, and Cardiac demonstrate that our 3D capsule network with self-supervised pre-training considerably outperforms previous capsule networks and 3D-UNets.
Rediscovery of the Effectiveness of Standard Convolution for Lightweight Face Detection
Apr 04, 2022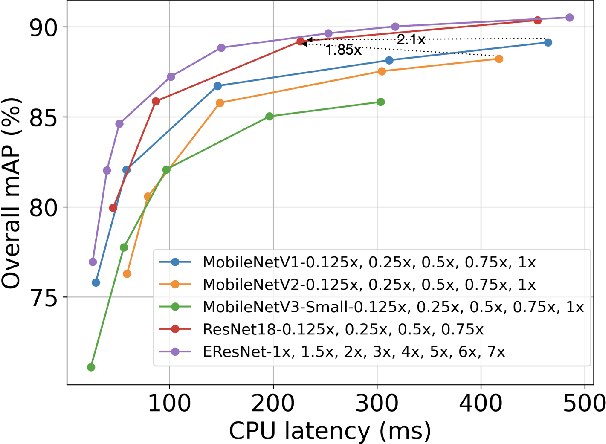
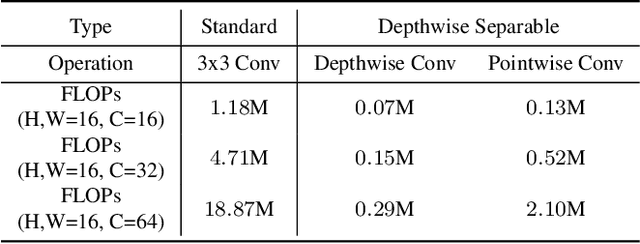
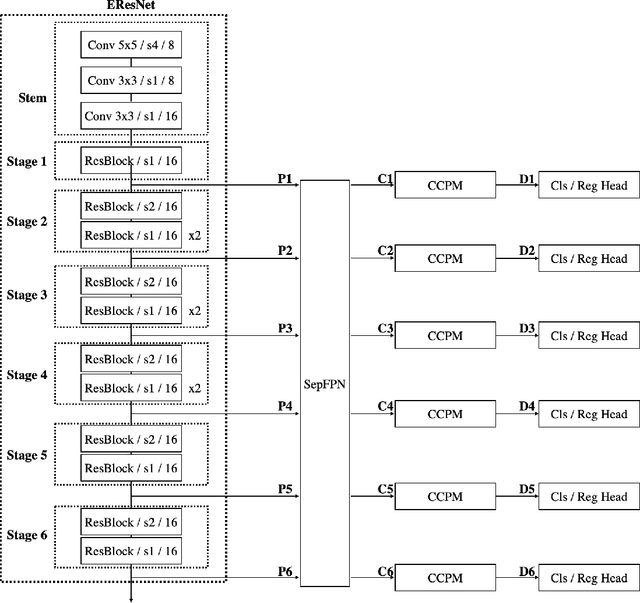
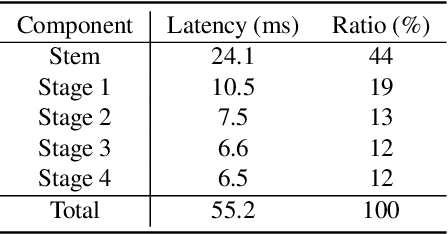
This paper analyses the design choices of face detection architecture that improve efficiency between computation cost and accuracy. Specifically, we re-examine the effectiveness of the standard convolutional block as a lightweight backbone architecture on face detection. Unlike the current tendency of lightweight architecture design, which heavily utilizes depthwise separable convolution layers, we show that heavily channel-pruned standard convolution layer can achieve better accuracy and inference speed when using a similar parameter size. This observation is supported by the analyses concerning the characteristics of the target data domain, face. Based on our observation, we propose to employ ResNet with a highly reduced channel, which surprisingly allows high efficiency compared to other mobile-friendly networks (e.g., MobileNet-V1,-V2,-V3). From the extensive experiments, we show that the proposed backbone can replace that of the state-of-the-art face detector with a faster inference speed. Also, we further propose a new feature aggregation method maximizing the detection performance. Our proposed detector EResFD obtained 80.4% mAP on WIDER FACE Hard subset which only takes 37.7 ms for VGA image inference in on CPU. Code will be available at https://github.com/clovaai/EResFD.
Multi-View Motion Synthesis via Applying Rotated Dual-Pixel Blur Kernels
Nov 15, 2021
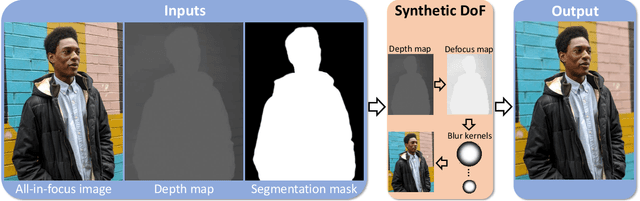
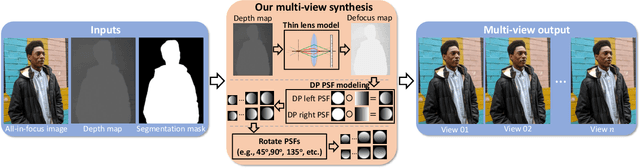
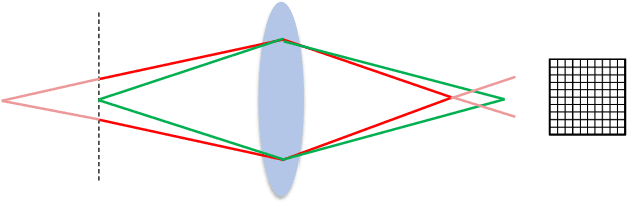
Portrait mode is widely available on smartphone cameras to provide an enhanced photographic experience. One of the primary effects applied to images captured in portrait mode is a synthetic shallow depth of field (DoF). The synthetic DoF (or bokeh effect) selectively blurs regions in the image to emulate the effect of using a large lens with a wide aperture. In addition, many applications now incorporate a new image motion attribute (NIMAT) to emulate background motion, where the motion is correlated with estimated depth at each pixel. In this work, we follow the trend of rendering the NIMAT effect by introducing a modification on the blur synthesis procedure in portrait mode. In particular, our modification enables a high-quality synthesis of multi-view bokeh from a single image by applying rotated blurring kernels. Given the synthesized multiple views, we can generate aesthetically realistic image motion similar to the NIMAT effect. We validate our approach qualitatively compared to the original NIMAT effect and other similar image motions, like Facebook 3D image. Our image motion demonstrates a smooth image view transition with fewer artifacts around the object boundary.
Longer Version for "Deep Context-Encoding Network for Retinal Image Captioning"
May 30, 2021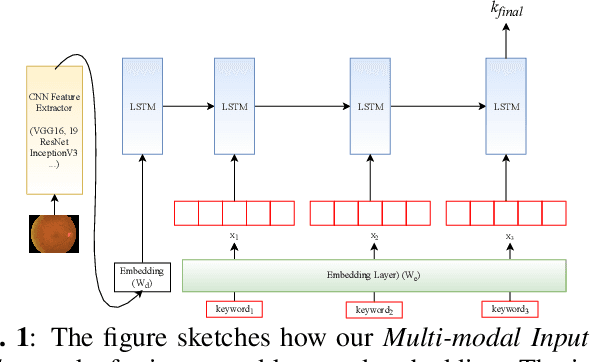
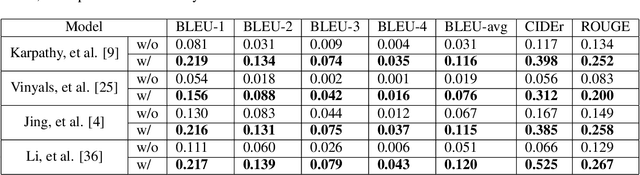
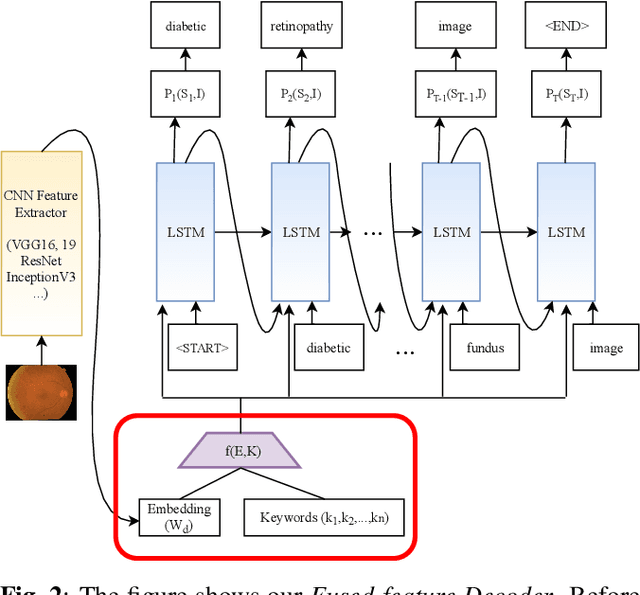

Automatically generating medical reports for retinal images is one of the promising ways to help ophthalmologists reduce their workload and improve work efficiency. In this work, we propose a new context-driven encoding network to automatically generate medical reports for retinal images. The proposed model is mainly composed of a multi-modal input encoder and a fused-feature decoder. Our experimental results show that our proposed method is capable of effectively leveraging the interactive information between the input image and context, i.e., keywords in our case. The proposed method creates more accurate and meaningful reports for retinal images than baseline models and achieves state-of-the-art performance. This performance is shown in several commonly used metrics for the medical report generation task: BLEU-avg (+16%), CIDEr (+10.2%), and ROUGE (+8.6%).
Projected Multi-Agent Consensus Equilibrium for Ptychographic Image Reconstruction
Dec 08, 2021
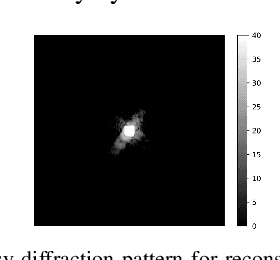
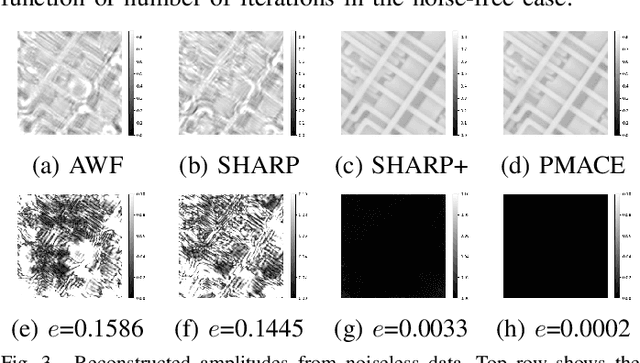

Ptychography is a computational imaging technique using multiple, overlapping, coherently illuminated snapshots to achieve nanometer resolution by solving a nonlinear phase-field recovery problem. Ptychography is vital for imaging of manufactured nanomaterials, but existing algorithms have computational shortcomings that limit large-scale application. In this paper, we present the Projected Multi-Agent Consensus Equilibrium (PMACE) approach for solving the ptychography inversion problem. This approach extends earlier work on MACE, which formulates an inversion problem as an equilibrium among multiple agents, each acting independently to update a full reconstruction. In PMACE, each agent acts on a portion (projection) corresponding to one of the snapshots, and these updates to projections are then combined to give an update to the full reconstruction. The resulting algorithm is easily parallelized, with convergence properties inherited from convergence results associated with MACE. We apply our method on simulated data and demonstrate that it outperforms competing algorithms in both reconstruction quality and convergence speed.
Multimodal Quasi-AutoRegression: Forecasting the visual popularity of new fashion products
Apr 08, 2022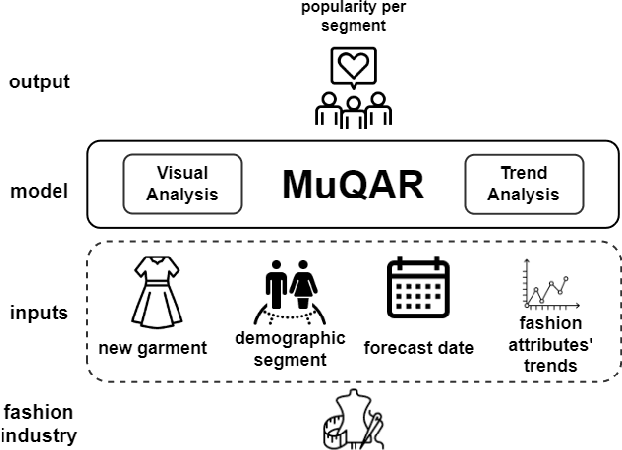
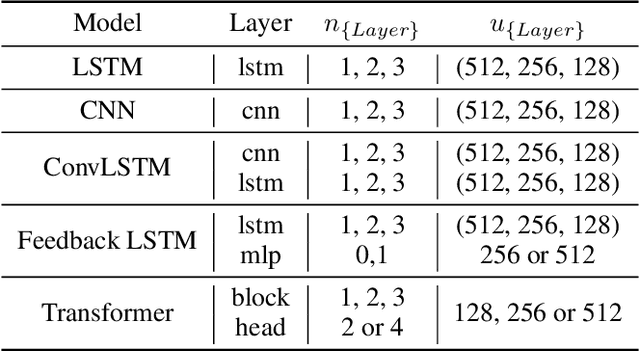
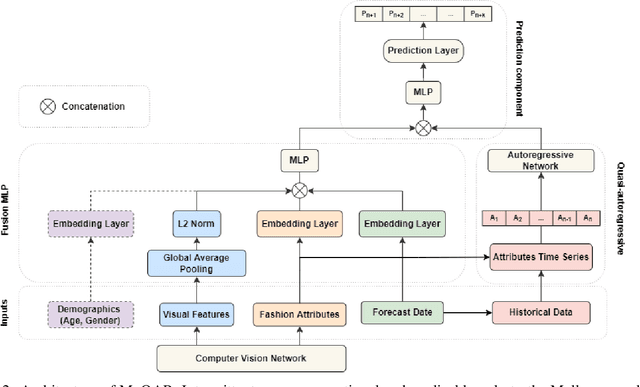
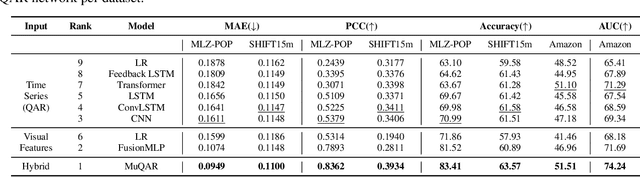
Estimating the preferences of consumers is of utmost importance for the fashion industry as appropriately leveraging this information can be beneficial in terms of profit. Trend detection in fashion is a challenging task due to the fast pace of change in the fashion industry. Moreover, forecasting the visual popularity of new garment designs is even more demanding due to lack of historical data. To this end, we propose MuQAR, a Multimodal Quasi-AutoRegressive deep learning architecture that combines two modules: (1) a multi-modal multi-layer perceptron processing categorical and visual features extracted by computer vision networks and (2) a quasi-autoregressive neural network modelling the time series of the product's attributes, which are used as a proxy of temporal popularity patterns mitigating the lack of historical data. We perform an extensive ablation analysis on two large scale image fashion datasets, Mallzee-popularity and SHIFT15m to assess the adequacy of MuQAR and also use the Amazon Reviews: Home and Kitchen dataset to assess generalisability to other domains. A comparative study on the VISUELLE dataset, shows that MuQAR is capable of competing and surpassing the domain's current state of the art by 2.88% in terms of WAPE and 3.04% in terms of MAE.