 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStory2Board: A Training-Free Approach for Expressive Storyboard Generation
Aug 13, 2025We present Story2Board, a training-free framework for expressive storyboard generation from natural language. Existing methods narrowly focus on subject identity, overlooking key aspects of visual storytelling such as spatial composition, background evolution, and narrative pacing. To address this, we introduce a lightweight consistency framework composed of two components: Latent Panel Anchoring, which preserves a shared character reference across panels, and Reciprocal Attention Value Mixing, which softly blends visual features between token pairs with strong reciprocal attention. Together, these mechanisms enhance coherence without architectural changes or fine-tuning, enabling state-of-the-art diffusion models to generate visually diverse yet consistent storyboards. To structure generation, we use an off-the-shelf language model to convert free-form stories into grounded panel-level prompts. To evaluate, we propose the Rich Storyboard Benchmark, a suite of open-domain narratives designed to assess layout diversity and background-grounded storytelling, in addition to consistency. We also introduce a new Scene Diversity metric that quantifies spatial and pose variation across storyboards. Our qualitative and quantitative results, as well as a user study, show that Story2Board produces more dynamic, coherent, and narratively engaging storyboards than existing baselines.
Stable Flow: Vital Layers for Training-Free Image Editing
Nov 21, 2024



Diffusion models have revolutionized the field of content synthesis and editing. Recent models have replaced the traditional UNet architecture with the Diffusion Transformer (DiT), and employed flow-matching for improved training and sampling. However, they exhibit limited generation diversity. In this work, we leverage this limitation to perform consistent image edits via selective injection of attention features. The main challenge is that, unlike the UNet-based models, DiT lacks a coarse-to-fine synthesis structure, making it unclear in which layers to perform the injection. Therefore, we propose an automatic method to identify "vital layers" within DiT, crucial for image formation, and demonstrate how these layers facilitate a range of controlled stable edits, from non-rigid modifications to object addition, using the same mechanism. Next, to enable real-image editing, we introduce an improved image inversion method for flow models. Finally, we evaluate our approach through qualitative and quantitative comparisons, along with a user study, and demonstrate its effectiveness across multiple applications. The project page is available at https://omriavrahami.com/stable-flow
Click2Mask: Local Editing with Dynamic Mask Generation
Sep 12, 2024



Recent advancements in generative models have revolutionized image generation and editing, making these tasks accessible to non-experts. This paper focuses on local image editing, particularly the task of adding new content to a loosely specified area. Existing methods often require a precise mask or a detailed description of the location, which can be cumbersome and prone to errors. We propose Click2Mask, a novel approach that simplifies the local editing process by requiring only a single point of reference (in addition to the content description). A mask is dynamically grown around this point during a Blended Latent Diffusion (BLD) process, guided by a masked CLIP-based semantic loss. Click2Mask surpasses the limitations of segmentation-based and fine-tuning dependent methods, offering a more user-friendly and contextually accurate solution. Our experiments demonstrate that Click2Mask not only minimizes user effort but also delivers competitive or superior local image manipulation results compared to SoTA methods, according to both human judgement and automatic metrics. Key contributions include the simplification of user input, the ability to freely add objects unconstrained by existing segments, and the integration potential of our dynamic mask approach within other editing methods.
DiffUHaul: A Training-Free Method for Object Dragging in Images
Jun 03, 2024



Text-to-image diffusion models have proven effective for solving many image editing tasks. However, the seemingly straightforward task of seamlessly relocating objects within a scene remains surprisingly challenging. Existing methods addressing this problem often struggle to function reliably in real-world scenarios due to lacking spatial reasoning. In this work, we propose a training-free method, dubbed DiffUHaul, that harnesses the spatial understanding of a localized text-to-image model, for the object dragging task. Blindly manipulating layout inputs of the localized model tends to cause low editing performance due to the intrinsic entanglement of object representation in the model. To this end, we first apply attention masking in each denoising step to make the generation more disentangled across different objects and adopt the self-attention sharing mechanism to preserve the high-level object appearance. Furthermore, we propose a new diffusion anchoring technique: in the early denoising steps, we interpolate the attention features between source and target images to smoothly fuse new layouts with the original appearance; in the later denoising steps, we pass the localized features from the source images to the interpolated images to retain fine-grained object details. To adapt DiffUHaul to real-image editing, we apply a DDPM self-attention bucketing that can better reconstruct real images with the localized model. Finally, we introduce an automated evaluation pipeline for this task and showcase the efficacy of our method. Our results are reinforced through a user preference study.
PALP: Prompt Aligned Personalization of Text-to-Image Models
Jan 11, 2024



Content creators often aim to create personalized images using personal subjects that go beyond the capabilities of conventional text-to-image models. Additionally, they may want the resulting image to encompass a specific location, style, ambiance, and more. Existing personalization methods may compromise personalization ability or the alignment to complex textual prompts. This trade-off can impede the fulfillment of user prompts and subject fidelity. We propose a new approach focusing on personalization methods for a \emph{single} prompt to address this issue. We term our approach prompt-aligned personalization. While this may seem restrictive, our method excels in improving text alignment, enabling the creation of images with complex and intricate prompts, which may pose a challenge for current techniques. In particular, our method keeps the personalized model aligned with a target prompt using an additional score distillation sampling term. We demonstrate the versatility of our method in multi- and single-shot settings and further show that it can compose multiple subjects or use inspiration from reference images, such as artworks. We compare our approach quantitatively and qualitatively with existing baselines and state-of-the-art techniques.
The Chosen One: Consistent Characters in Text-to-Image Diffusion Models
Nov 27, 2023



Recent advances in text-to-image generation models have unlocked vast potential for visual creativity. However, these models struggle with generation of consistent characters, a crucial aspect for numerous real-world applications such as story visualization, game development asset design, advertising, and more. Current methods typically rely on multiple pre-existing images of the target character or involve labor-intensive manual processes. In this work, we propose a fully automated solution for consistent character generation, with the sole input being a text prompt. We introduce an iterative procedure that, at each stage, identifies a coherent set of images sharing a similar identity and extracts a more consistent identity from this set. Our quantitative analysis demonstrates that our method strikes a better balance between prompt alignment and identity consistency compared to the baseline methods, and these findings are reinforced by a user study. To conclude, we showcase several practical applications of our approach. Project page is available at https://omriavrahami.com/the-chosen-one
Blended-NeRF: Zero-Shot Object Generation and Blending in Existing Neural Radiance Fields
Jun 22, 2023



Editing a local region or a specific object in a 3D scene represented by a NeRF is challenging, mainly due to the implicit nature of the scene representation. Consistently blending a new realistic object into the scene adds an additional level of difficulty. We present Blended-NeRF, a robust and flexible framework for editing a specific region of interest in an existing NeRF scene, based on text prompts or image patches, along with a 3D ROI box. Our method leverages a pretrained language-image model to steer the synthesis towards a user-provided text prompt or image patch, along with a 3D MLP model initialized on an existing NeRF scene to generate the object and blend it into a specified region in the original scene. We allow local editing by localizing a 3D ROI box in the input scene, and seamlessly blend the content synthesized inside the ROI with the existing scene using a novel volumetric blending technique. To obtain natural looking and view-consistent results, we leverage existing and new geometric priors and 3D augmentations for improving the visual fidelity of the final result. We test our framework both qualitatively and quantitatively on a variety of real 3D scenes and text prompts, demonstrating realistic multi-view consistent results with much flexibility and diversity compared to the baselines. Finally, we show the applicability of our framework for several 3D editing applications, including adding new objects to a scene, removing/replacing/altering existing objects, and texture conversion.
Break-A-Scene: Extracting Multiple Concepts from a Single Image
May 25, 2023



Text-to-image model personalization aims to introduce a user-provided concept to the model, allowing its synthesis in diverse contexts. However, current methods primarily focus on the case of learning a single concept from multiple images with variations in backgrounds and poses, and struggle when adapted to a different scenario. In this work, we introduce the task of textual scene decomposition: given a single image of a scene that may contain several concepts, we aim to extract a distinct text token for each concept, enabling fine-grained control over the generated scenes. To this end, we propose augmenting the input image with masks that indicate the presence of target concepts. These masks can be provided by the user or generated automatically by a pre-trained segmentation model. We then present a novel two-phase customization process that optimizes a set of dedicated textual embeddings (handles), as well as the model weights, striking a delicate balance between accurately capturing the concepts and avoiding overfitting. We employ a masked diffusion loss to enable handles to generate their assigned concepts, complemented by a novel loss on cross-attention maps to prevent entanglement. We also introduce union-sampling, a training strategy aimed to improve the ability of combining multiple concepts in generated images. We use several automatic metrics to quantitatively compare our method against several baselines, and further affirm the results using a user study. Finally, we showcase several applications of our method. Project page is available at: https://omriavrahami.com/break-a-scene/
SpaText: Spatio-Textual Representation for Controllable Image Generation
Nov 25, 2022Recent text-to-image diffusion models are able to generate convincing results of unprecedented quality. However, it is nearly impossible to control the shapes of different regions/objects or their layout in a fine-grained fashion. Previous attempts to provide such controls were hindered by their reliance on a fixed set of labels. To this end, we present SpaText - a new method for text-to-image generation using open-vocabulary scene control. In addition to a global text prompt that describes the entire scene, the user provides a segmentation map where each region of interest is annotated by a free-form natural language description. Due to lack of large-scale datasets that have a detailed textual description for each region in the image, we choose to leverage the current large-scale text-to-image datasets and base our approach on a novel CLIP-based spatio-textual representation, and show its effectiveness on two state-of-the-art diffusion models: pixel-based and latent-based. In addition, we show how to extend the classifier-free guidance method in diffusion models to the multi-conditional case and present an alternative accelerated inference algorithm. Finally, we offer several automatic evaluation metrics and use them, in addition to FID scores and a user study, to evaluate our method and show that it achieves state-of-the-art results on image generation with free-form textual scene control.
Blended Latent Diffusion
Jun 06, 2022
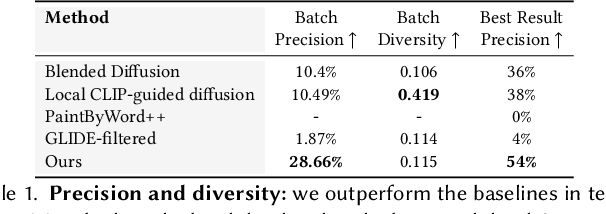

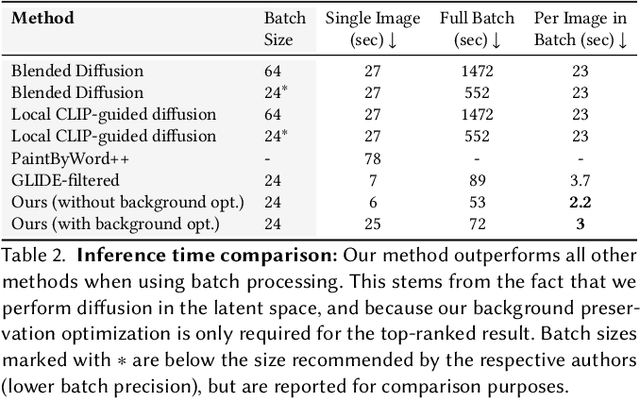
The tremendous progress in neural image generation, coupled with the emergence of seemingly omnipotent vision-language models has finally enabled text-based interfaces for creating and editing images. Handling generic images requires a diverse underlying generative model, hence the latest works utilize diffusion models, which were shown to surpass GANs in terms of diversity. One major drawback of diffusion models, however, is their relatively slow inference time. In this paper, we present an accelerated solution to the task of local text-driven editing of generic images, where the desired edits are confined to a user-provided mask. Our solution leverages a recent text-to-image Latent Diffusion Model (LDM), which speeds up diffusion by operating in a lower-dimensional latent space. We first convert the LDM into a local image editor by incorporating Blended Diffusion into it. Next we propose an optimization-based solution for the inherent inability of this LDM to accurately reconstruct images. Finally, we address the scenario of performing local edits using thin masks. We evaluate our method against the available baselines both qualitatively and quantitatively and demonstrate that in addition to being faster, our method achieves better precision than the baselines while mitigating some of their artifacts. Project page is available at https://omriavrahami.com/blended-latent-diffusion-page/