 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
On the Pitfalls of Using the Residual Error as Anomaly Score
Feb 08, 2022
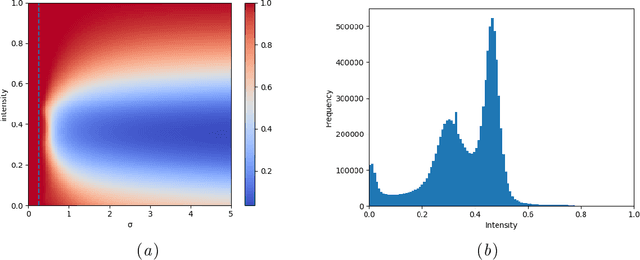
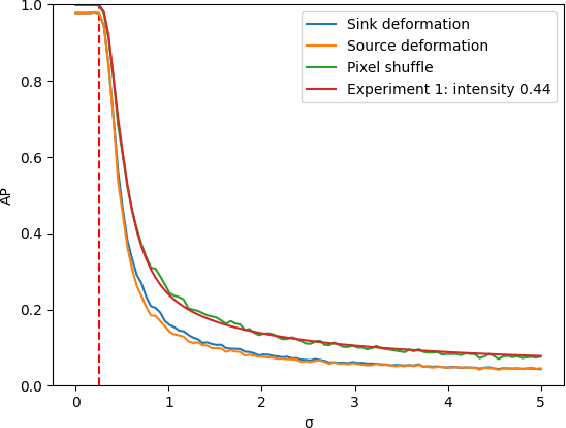
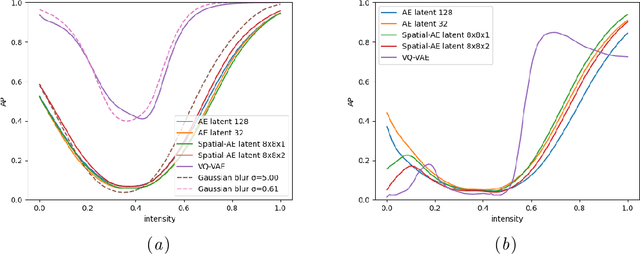
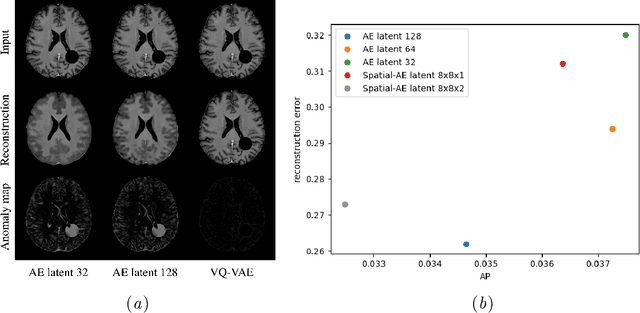
Many current state-of-the-art methods for anomaly localization in medical images rely on calculating a residual image between a potentially anomalous input image and its "healthy" reconstruction. As the reconstruction of the unseen anomalous region should be erroneous, this yields large residuals as a score to detect anomalies in medical images. However, this assumption does not take into account residuals resulting from imperfect reconstructions of the machine learning models used. Such errors can easily overshadow residuals of interest and therefore strongly question the use of residual images as scoring function. Our work explores this fundamental problem of residual images in detail. We theoretically define the problem and thoroughly evaluate the influence of intensity and texture of anomalies against the effect of imperfect reconstructions in a series of experiments. Code and experiments are available under https://github.com/FeliMe/residual-score-pitfalls
Enhanced Magnetic Resonance Image Synthesis with Contrast-Aware Generative Adversarial Networks
Feb 17, 2021
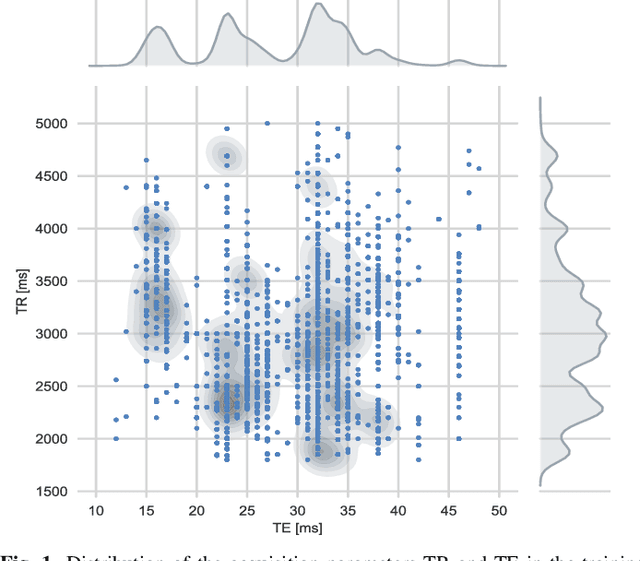
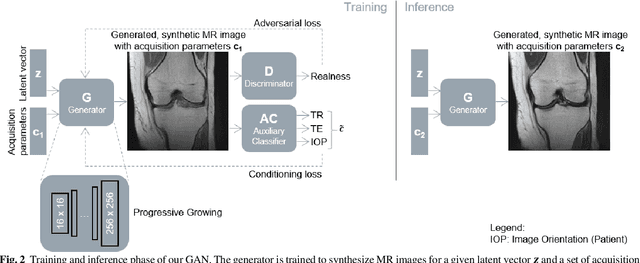
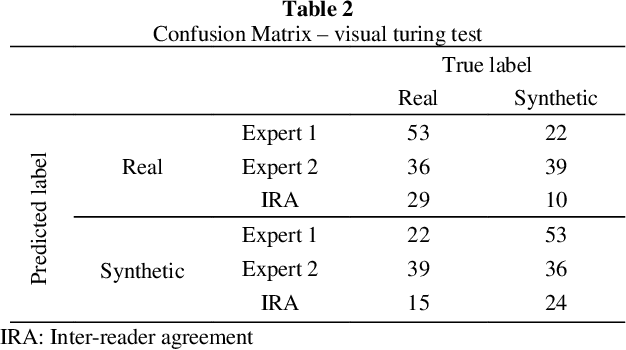
A Magnetic Resonance Imaging (MRI) exam typically consists of the acquisition of multiple MR pulse sequences, which are required for a reliable diagnosis. Each sequence can be parameterized through multiple acquisition parameters affecting MR image contrast, signal-to-noise ratio, resolution, or scan time. With the rise of generative deep learning models, approaches for the synthesis of MR images are developed to either synthesize additional MR contrasts, generate synthetic data, or augment existing data for AI training. However, current generative approaches for the synthesis of MR images are only trained on images with a specific set of acquisition parameter values, limiting the clinical value of these methods as various sets of acquisition parameter settings are used in clinical practice. Therefore, we trained a generative adversarial network (GAN) to generate synthetic MR knee images conditioned on various acquisition parameters (repetition time, echo time, image orientation). This approach enables us to synthesize MR images with adjustable image contrast. In a visual Turing test, two experts mislabeled 40.5% of real and synthetic MR images, demonstrating that the image quality of the generated synthetic and real MR images is comparable. This work can support radiologists and technologists during the parameterization of MR sequences by previewing the yielded MR contrast, can serve as a valuable tool for radiology training, and can be used for customized data generation to support AI training.
How stable are Transferability Metrics evaluations?
Apr 11, 2022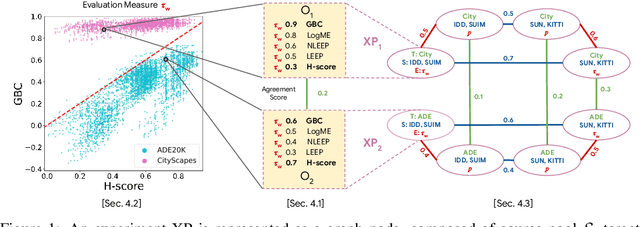
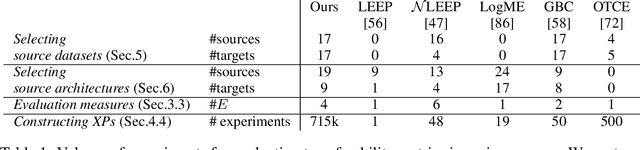
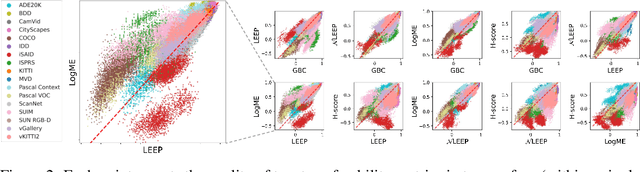
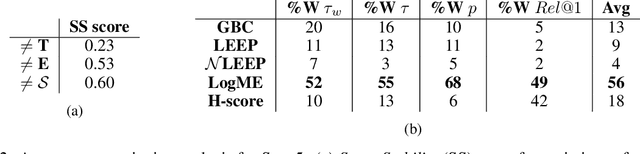
Transferability metrics is a maturing field with increasing interest, which aims at providing heuristics for selecting the most suitable source models to transfer to a given target dataset, without fine-tuning them all. However, existing works rely on custom experimental setups which differ across papers, leading to inconsistent conclusions about which transferability metrics work best. In this paper we conduct a large-scale study by systematically constructing a broad range of 715k experimental setup variations. We discover that even small variations to an experimental setup lead to different conclusions about the superiority of a transferability metric over another. Then we propose better evaluations by aggregating across many experiments, enabling to reach more stable conclusions. As a result, we reveal the superiority of LogME at selecting good source datasets to transfer from in a semantic segmentation scenario, NLEEP at selecting good source architectures in an image classification scenario, and GBC at determining which target task benefits most from a given source model. Yet, no single transferability metric works best in all scenarios.
Omni-frequency Channel-selection Representations for Unsupervised Anomaly Detection
Mar 01, 2022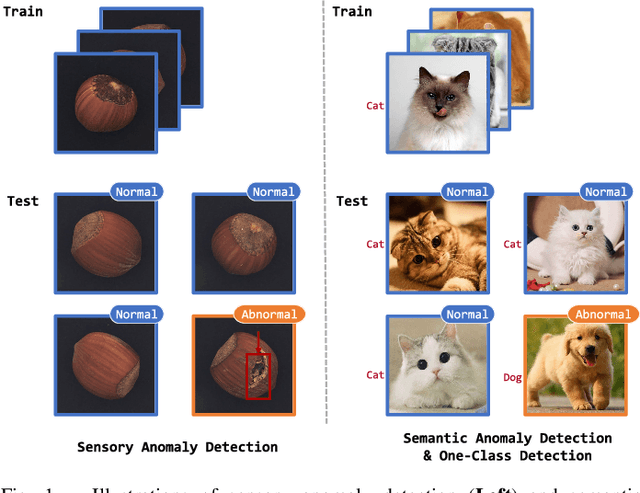
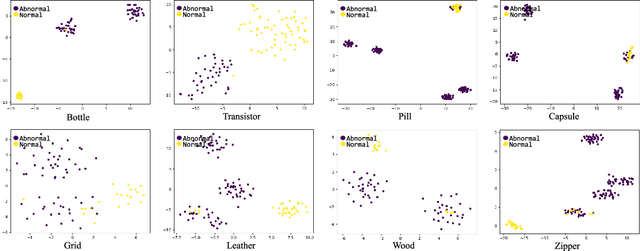

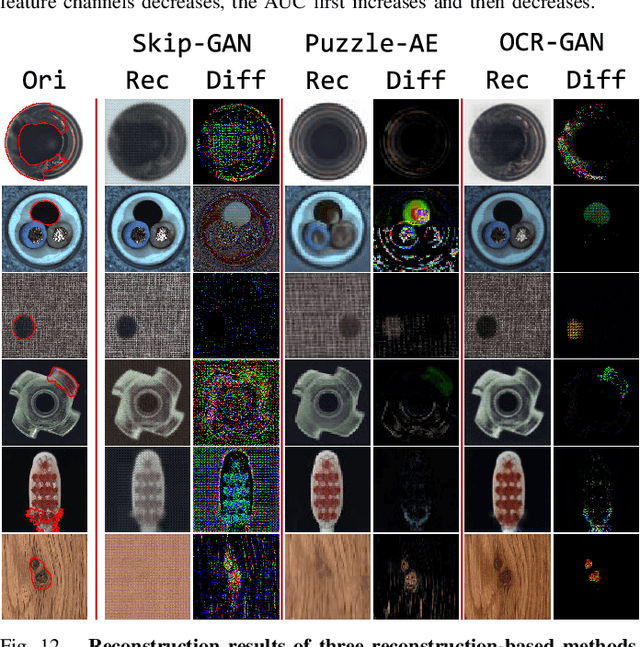
Density-based and classification-based methods have ruled unsupervised anomaly detection in recent years, while reconstruction-based methods are rarely mentioned for the poor reconstruction ability and low performance. However, the latter requires no costly extra training samples for the unsupervised training that is more practical, so this paper focuses on improving this kind of method and proposes a novel Omni-frequency Channel-selection Reconstruction (OCR-GAN) network to handle anomaly detection task in a perspective of frequency. Concretely, we propose a Frequency Decoupling (FD) module to decouple the input image into different frequency components and model the reconstruction process as a combination of parallel omni-frequency image restorations, as we observe a significant difference in the frequency distribution of normal and abnormal images. Given the correlation among multiple frequencies, we further propose a Channel Selection (CS) module that performs frequency interaction among different encoders by adaptively selecting different channels. Abundant experiments demonstrate the effectiveness and superiority of our approach over different kinds of methods, e.g., achieving a new state-of-the-art 98.3 detection AUC on the MVTec AD dataset without extra training data that markedly surpasses the reconstruction-based baseline by +38.1 and the current SOTA method by +0.3. Source code will be available at https://github.com/zhangzjn/OCR-GAN.
Commonality in Natural Images Rescues GANs: Pretraining GANs with Generic and Privacy-free Synthetic Data
Apr 11, 2022
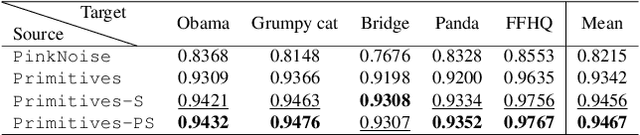
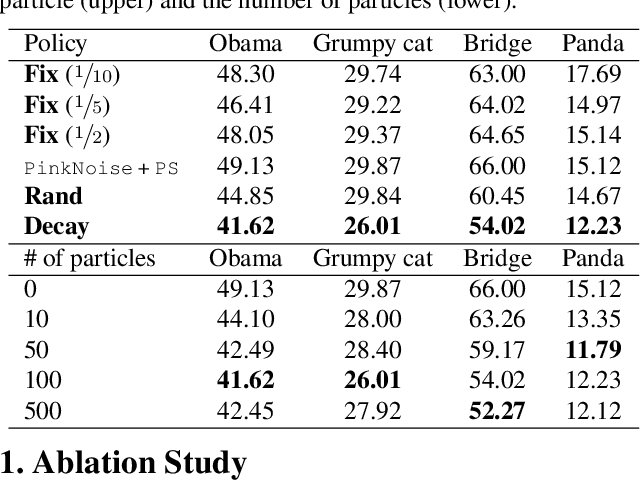
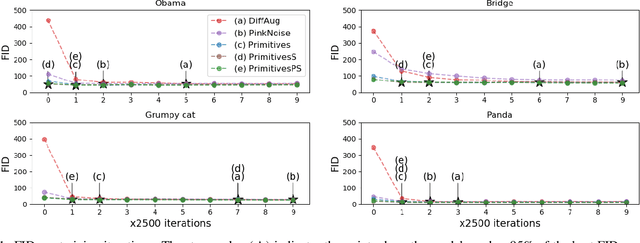
Transfer learning for GANs successfully improves generation performance under low-shot regimes. However, existing studies show that the pretrained model using a single benchmark dataset is not generalized to various target datasets. More importantly, the pretrained model can be vulnerable to copyright or privacy risks as membership inference attack advances. To resolve both issues, we propose an effective and unbiased data synthesizer, namely Primitives-PS, inspired by the generic characteristics of natural images. Specifically, we utilize 1) the generic statistics on the frequency magnitude spectrum, 2) the elementary shape (i.e., image composition via elementary shapes) for representing the structure information, and 3) the existence of saliency as prior. Since our synthesizer only considers the generic properties of natural images, the single model pretrained on our dataset can be consistently transferred to various target datasets, and even outperforms the previous methods pretrained with the natural images in terms of Fr'echet inception distance. Extensive analysis, ablation study, and evaluations demonstrate that each component of our data synthesizer is effective, and provide insights on the desirable nature of the pretrained model for the transferability of GANs.
A Novel Upsampling and Context Convolution for Image Semantic Segmentation
Mar 20, 2021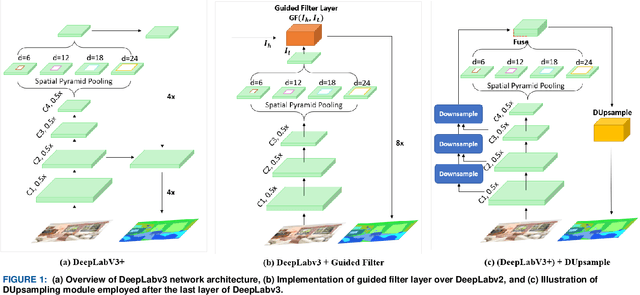
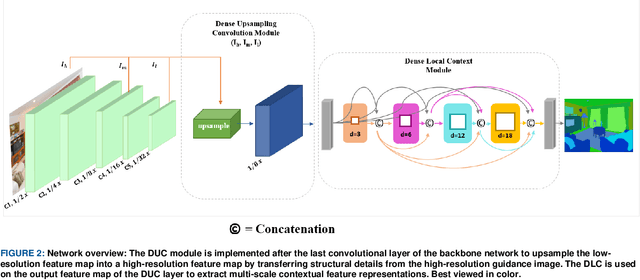
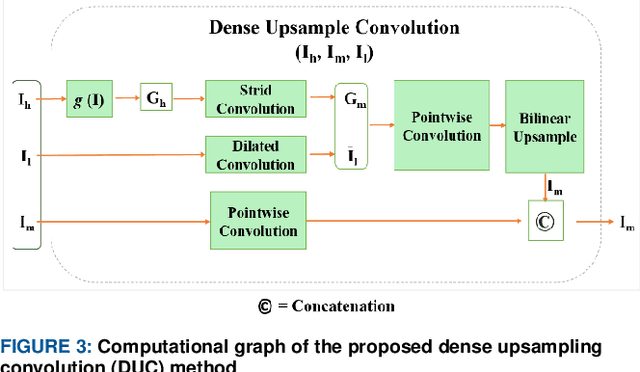
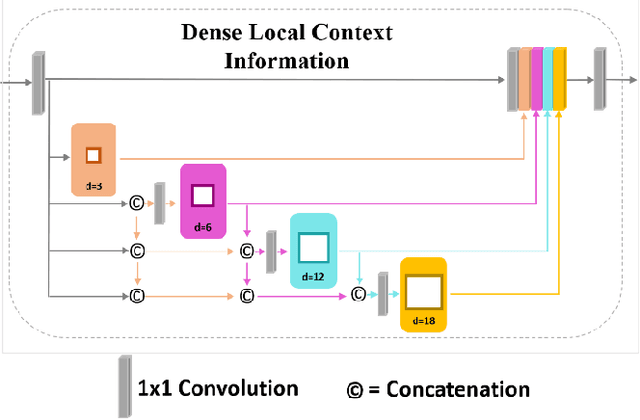
Semantic segmentation, which refers to pixel-wise classification of an image, is a fundamental topic in computer vision owing to its growing importance in robot vision and autonomous driving industries. It provides rich information about objects in the scene such as object boundary, category, and location. Recent methods for semantic segmentation often employ an encoder-decoder structure using deep convolutional neural networks. The encoder part extracts feature of the image using several filters and pooling operations, whereas the decoder part gradually recovers the low-resolution feature maps of the encoder into a full input resolution feature map for pixel-wise prediction. However, the encoder-decoder variants for semantic segmentation suffer from severe spatial information loss, caused by pooling operations or convolutions with stride, and does not consider the context in the scene. In this paper, we propose a dense upsampling convolution method based on guided filtering to effectively preserve the spatial information of the image in the network. We further propose a novel local context convolution method that not only covers larger-scale objects in the scene but covers them densely for precise object boundary delineation. Theoretical analyses and experimental results on several benchmark datasets verify the effectiveness of our method. Qualitatively, our approach delineates object boundaries at a level of accuracy that is beyond the current excellent methods. Quantitatively, we report a new record of 82.86% and 81.62% of pixel accuracy on ADE20K and Pascal-Context benchmark datasets, respectively. In comparison with the state-of-the-art methods, the proposed method offers promising improvements.
* 11 pages, published in sensors journal
C2N: Practical Generative Noise Modeling for Real-World Denoising
Feb 19, 2022
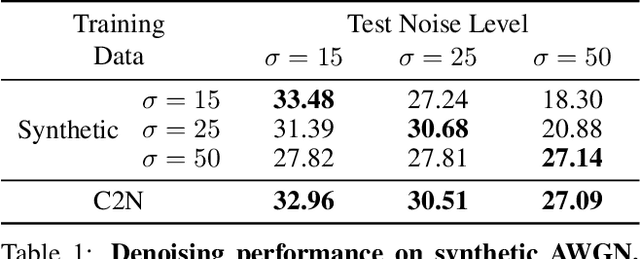
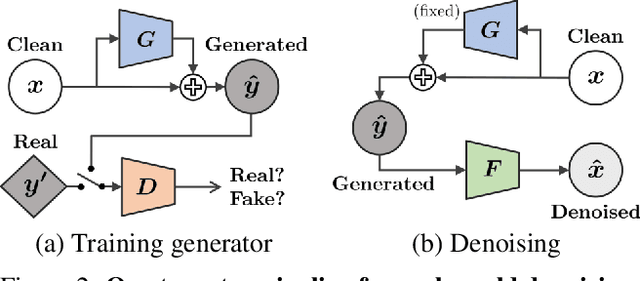

Learning-based image denoising methods have been bounded to situations where well-aligned noisy and clean images are given, or samples are synthesized from predetermined noise models, e.g., Gaussian. While recent generative noise modeling methods aim to simulate the unknown distribution of real-world noise, several limitations still exist. In a practical scenario, a noise generator should learn to simulate the general and complex noise distribution without using paired noisy and clean images. However, since existing methods are constructed on the unrealistic assumption of real-world noise, they tend to generate implausible patterns and cannot express complicated noise maps. Therefore, we introduce a Clean-to-Noisy image generation framework, namely C2N, to imitate complex real-world noise without using any paired examples. We construct the noise generator in C2N accordingly with each component of real-world noise characteristics to express a wide range of noise accurately. Combined with our C2N, conventional denoising CNNs can be trained to outperform existing unsupervised methods on challenging real-world benchmarks by a large margin.
Acceleration Strategies for MR-STAT: Achieving High-Resolution Reconstructions on a Desktop PC within 3 minutes
May 04, 2022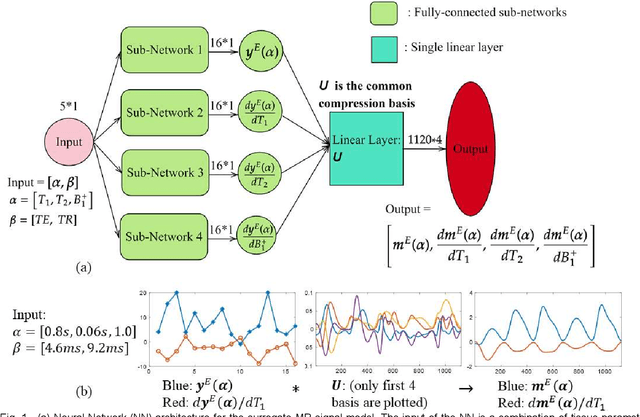
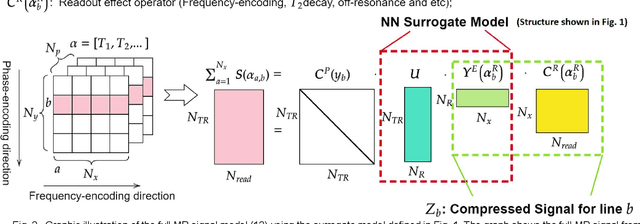
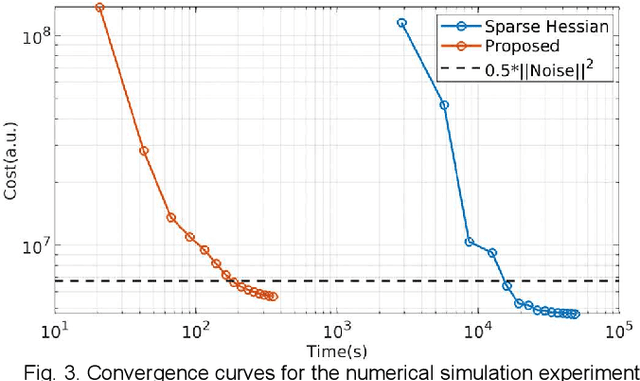

MR-STAT is an emerging quantitative magnetic resonance imaging technique which aims at obtaining multi-parametric tissue parameter maps from single short scans. It describes the relationship between the spatial-domain tissue parameters and the time-domain measured signal by using a comprehensive, volumetric forward model. The MR-STAT reconstruction solves a large-scale nonlinear problem, thus is very computationally challenging. In previous work, MR-STAT reconstruction using Cartesian readout data was accelerated by approximating the Hessian matrix with sparse, banded blocks, and can be done on high performance CPU clusters with tens of minutes. In the current work, we propose an accelerated Cartesian MR-STAT algorithm incorporating two different strategies: firstly, a neural network is trained as a fast surrogate to learn the magnetization signal not only in the full time-domain but also in the compressed lowrank domain; secondly, based on the surrogate model, the Cartesian MR-STAT problem is re-formulated and split into smaller sub-problems by the alternating direction method of multipliers. The proposed method substantially reduces the computational requirements for runtime and memory. Simulated and in-vivo balanced MR-STAT experiments show similar reconstruction results using the proposed algorithm compared to the previous sparse Hessian method, and the reconstruction times are at least 40 times shorter. Incorporating sensitivity encoding and regularization terms is straightforward, and allows for better image quality with a negligible increase in reconstruction time. The proposed algorithm could reconstruct both balanced and gradient-spoiled in-vivo data within 3 minutes on a desktop PC, and could thereby facilitate the translation of MR-STAT in clinical settings.
An Attention Score Based Attacker for Black-box NLP Classifier
Jan 01, 2022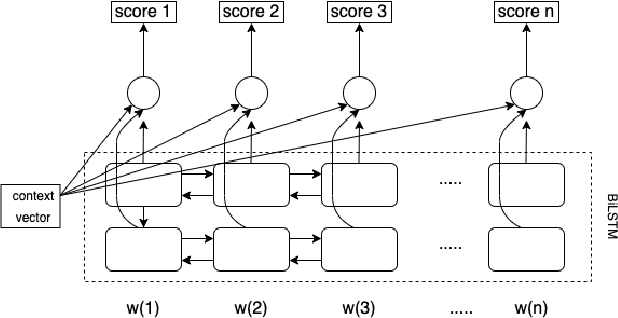
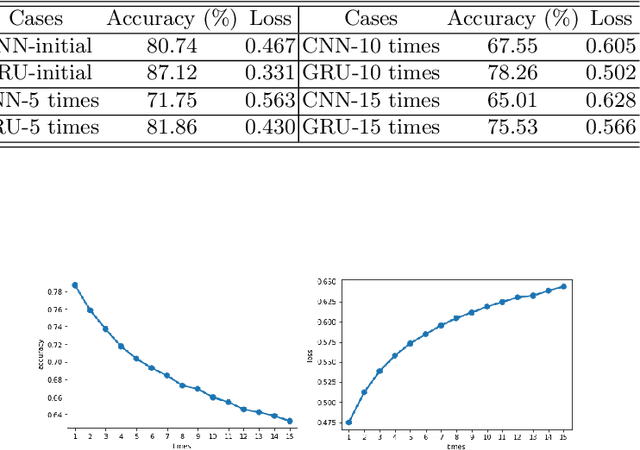
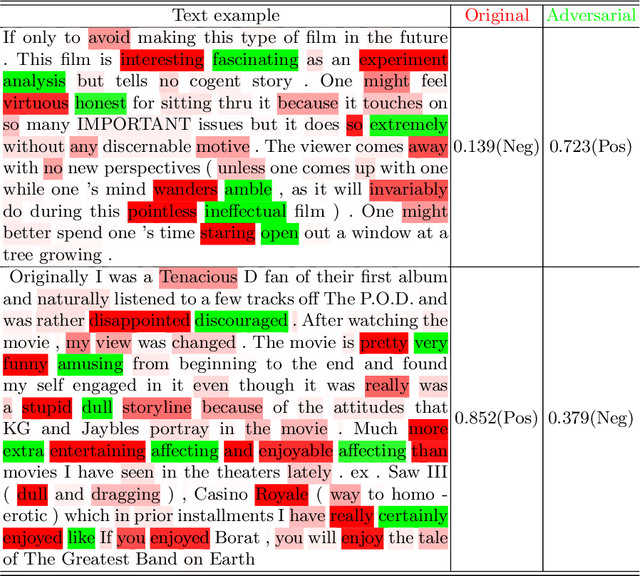
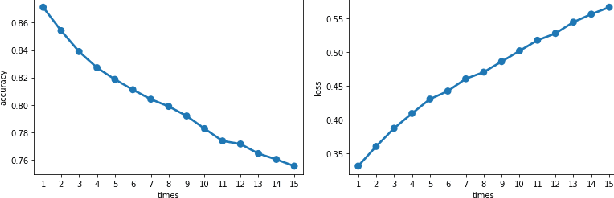
Deep neural networks have a wide range of applications in solving various real-world tasks and have achieved satisfactory results, in domains such as computer vision, image classification, and natural language processing. Meanwhile, the security and robustness of neural networks have become imperative, as diverse researches have shown the vulnerable aspects of neural networks. Case in point, in Natural language processing tasks, the neural network may be fooled by an attentively modified text, which has a high similarity to the original one. As per previous research, most of the studies are focused on the image domain; Different from image adversarial attacks, the text is represented in a discrete sequence, traditional image attack methods are not applicable in the NLP field. In this paper, we propose a word-level NLP sentiment classifier attack model, which includes a self-attention mechanism-based word selection method and a greedy search algorithm for word substitution. We experiment with our attack model by attacking GRU and 1D-CNN victim models on IMDB datasets. Experimental results demonstrate that our model achieves a higher attack success rate and more efficient than previous methods due to the efficient word selection algorithms are employed and minimized the word substitute number. Also, our model is transferable, which can be used in the image domain with several modifications.
A Radiomics-Boosted Deep-Learning Model for COVID-19 and Non-COVID-19 Pneumonia Detection Using Chest X-ray Image
Jul 19, 2021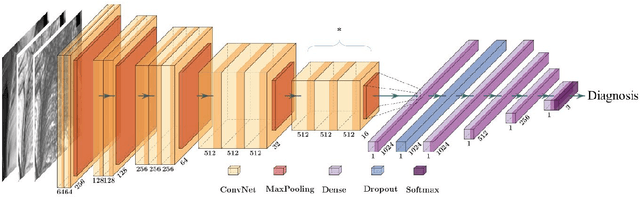
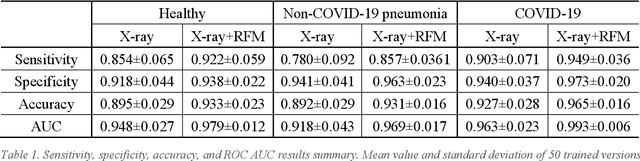
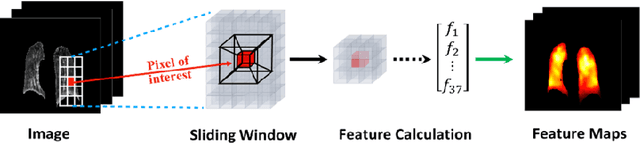
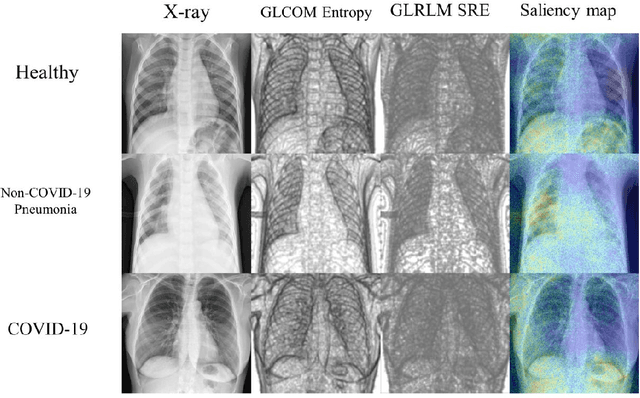
To develop a deep-learning model that integrates radiomics analysis for enhanced performance of COVID-19 and Non-COVID-19 pneumonia detection using chest X-ray image, two deep-learning models were trained based on a pre-trained VGG-16 architecture: in the 1st model, X-ray image was the sole input; in the 2nd model, X-ray image and 2 radiomic feature maps (RFM) selected by the saliency map analysis of the 1st model were stacked as the input. Both models were developed using 812 chest X-ray images with 262/288/262 COVID-19/Non-COVID-19 pneumonia/healthy cases, and 649/163 cases were assigned as training-validation/independent test sets. In 1st model using X-ray as the sole input, the 1) sensitivity, 2) specificity, 3) accuracy, and 4) ROC Area-Under-the-Curve of COVID-19 vs Non-COVID-19 pneumonia detection were 1) 0.90$\pm$0.07 vs 0.78$\pm$0.09, 2) 0.94$\pm$0.04 vs 0.94$\pm$0.04, 3) 0.93$\pm$0.03 vs 0.89$\pm$0.03, and 4) 0.96$\pm$0.02 vs 0.92$\pm$0.04. In the 2nd model, two RFMs, Entropy and Short-Run-Emphasize, were selected with their highest cross-correlations with the saliency maps of the 1st model. The corresponding results demonstrated significant improvements (p<0.05) of COVID-19 vs Non-COVID-19 pneumonia detection: 1) 0.95$\pm$0.04 vs 0.85$\pm$0.04, 2) 0.97$\pm$0.02 vs 0.96$\pm$0.02, 3) 0.97$\pm$0.02 vs 0.93$\pm$0.02, and 4) 0.99$\pm$0.01 vs 0.97$\pm$0.02. The reduced variations suggested a superior robustness of 2nd model design.