 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
On the semantics of big Earth observation data for land classification
Apr 23, 2022
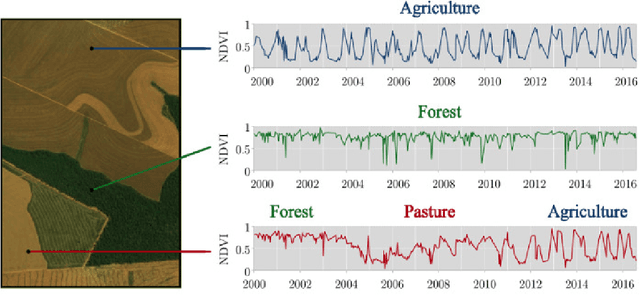
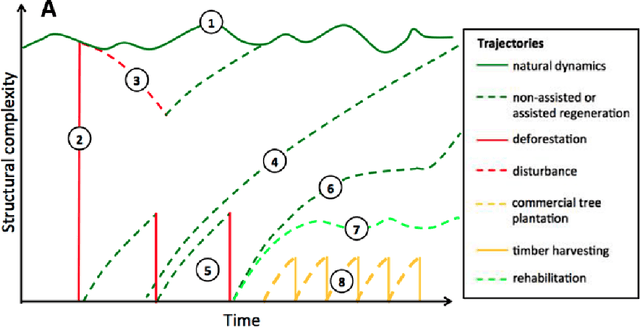
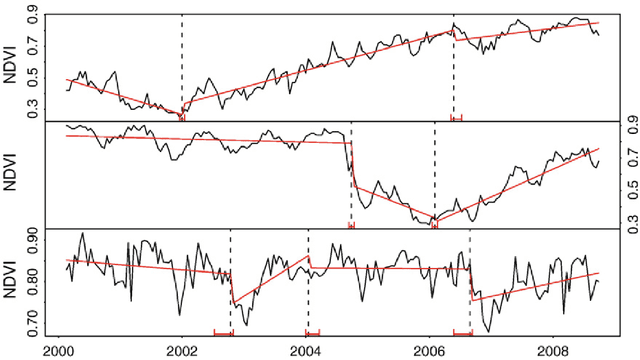
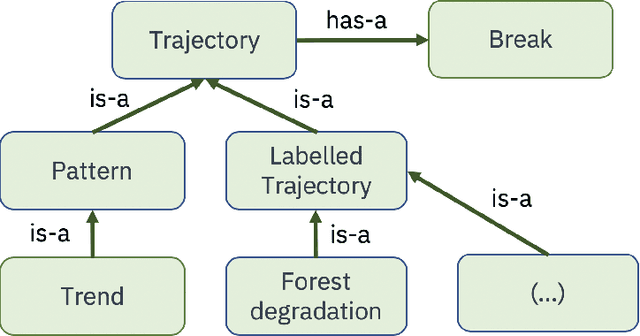
This paper discusses the challenges of using big Earth observation data for land classification. The approach taken is to consider pure data-driven methods to be insufficient to represent continuous change. We argue for sound theories when working with big data. After revising existing classification schemes such as FAO's Land Cover Classification System (LCCS), we conclude that LCCS and similar proposals cannot capture the complexity of landscape dynamics. We then investigate concepts that are being used for analyzing satellite image time series; we show these concepts to be instances of events. Therefore, for continuous monitoring of land change, event recognition needs to replace object identification as the prevailing paradigm. The paper concludes by showing how event semantics can improve data-driven methods to fulfil the potential of big data.
Deep Learning-Assisted Co-registration of Full-Spectral Autofluorescence Lifetime Microscopic Images with H&E-Stained Histology Images
Feb 15, 2022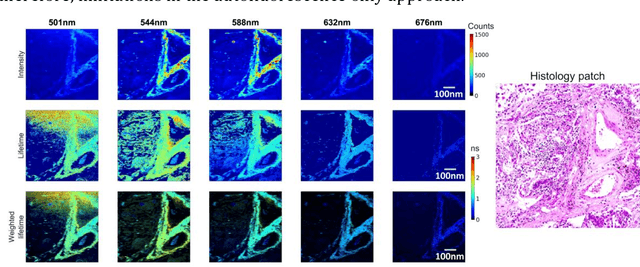
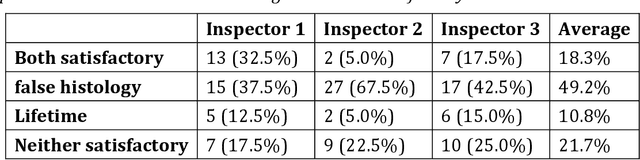
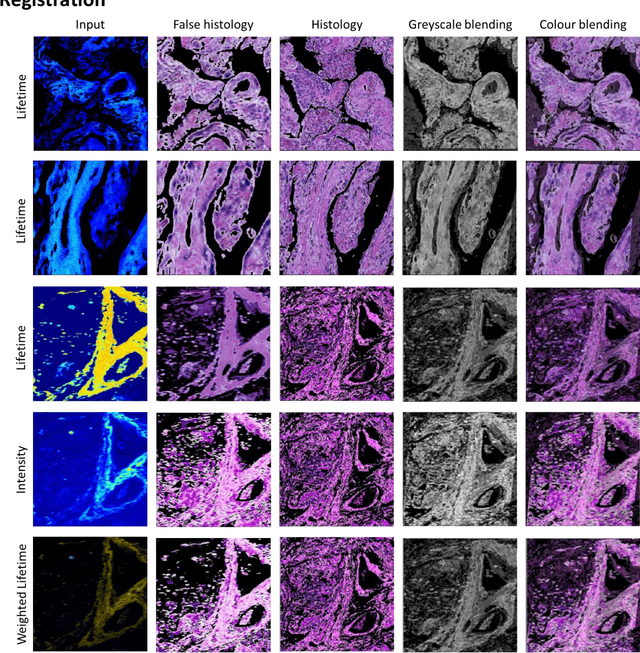
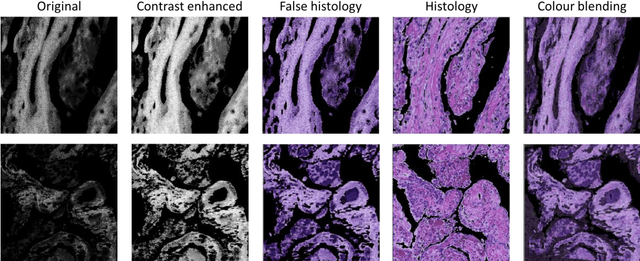
Autofluorescence lifetime images reveal unique characteristics of endogenous fluorescence in biological samples. Comprehensive understanding and clinical diagnosis rely on co-registration with the gold standard, histology images, which is extremely challenging due to the difference of both images. Here, we show an unsupervised image-to-image translation network that significantly improves the success of the co-registration using a conventional optimisation-based regression network, applicable to autofluorescence lifetime images at different emission wavelengths. A preliminary blind comparison by experienced researchers shows the superiority of our method on co-registration. The results also indicate that the approach is applicable to various image formats, like fluorescence intensity images. With the registration, stitching outcomes illustrate the distinct differences of the spectral lifetime across an unstained tissue, enabling macro-level rapid visual identification of lung cancer and cellular-level characterisation of cell variants and common types. The approach could be effortlessly extended to lifetime images beyond this range and other staining technologies.
A globally convergent fast iterative shrinkage-thresholding algorithm with a new momentum factor for single and multi-objective convex optimization
May 11, 2022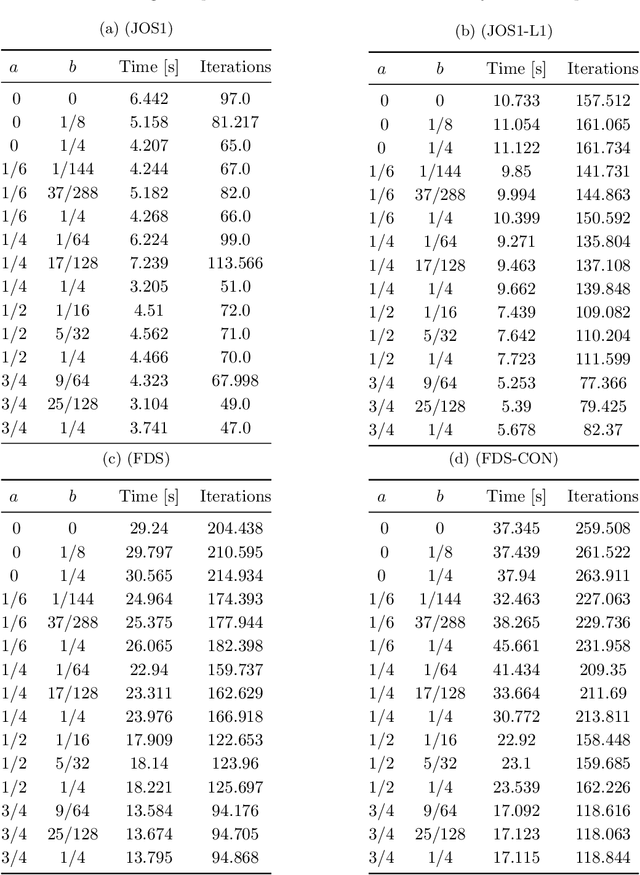
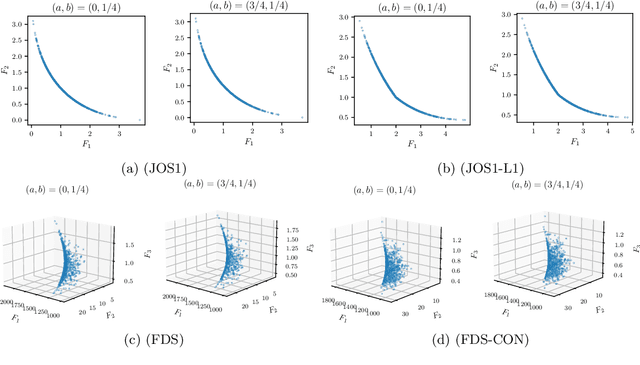

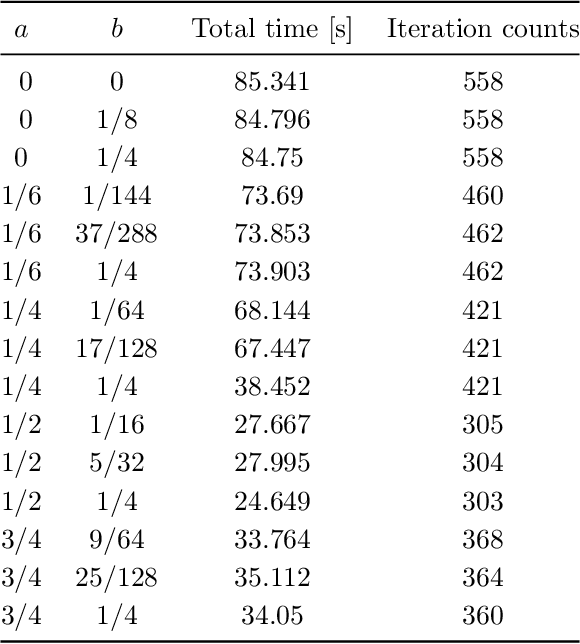
Convex-composite optimization, which minimizes an objective function represented by the sum of a differentiable function and a convex one, is widely used in machine learning and signal/image processing. Fast Iterative Shrinkage Thresholding Algorithm (FISTA) is a typical method for solving this problem and has a global convergence rate of $O(1 / k^2)$. Recently, this has been extended to multi-objective optimization, together with the proof of the $O(1 / k^2)$ global convergence rate. However, its momentum factor is classical, and the convergence of its iterates has not been proven. In this work, introducing some additional hyperparameters $(a, b)$, we propose another accelerated proximal gradient method with a general momentum factor, which is new even for the single-objective cases. We show that our proposed method also has a global convergence rate of $O(1/k^2)$ for any $(a,b)$, and further that the generated sequence of iterates converges to a weak Pareto solution when $a$ is positive, an essential property for the finite-time manifold identification. Moreover, we report numerical results with various $(a,b)$, showing that some of these choices give better results than the classical momentum factors.
HyperTransformer: A Textural and Spectral Feature Fusion Transformer for Pansharpening
Mar 28, 2022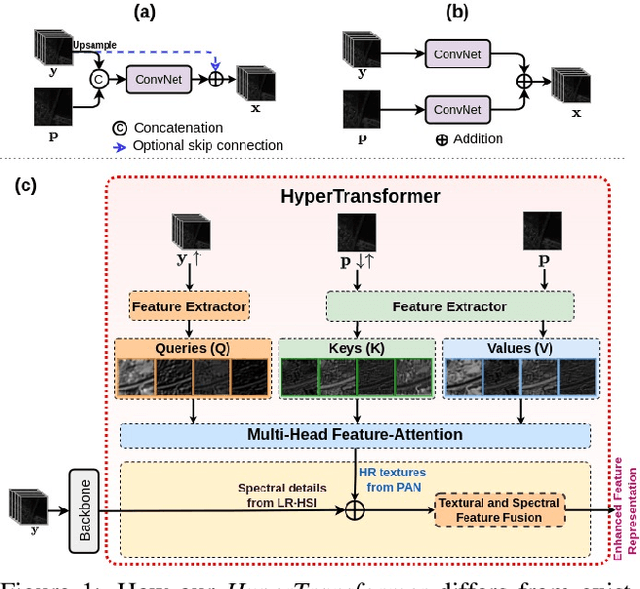
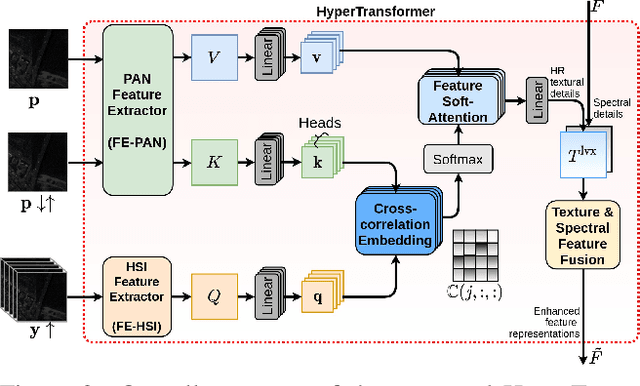
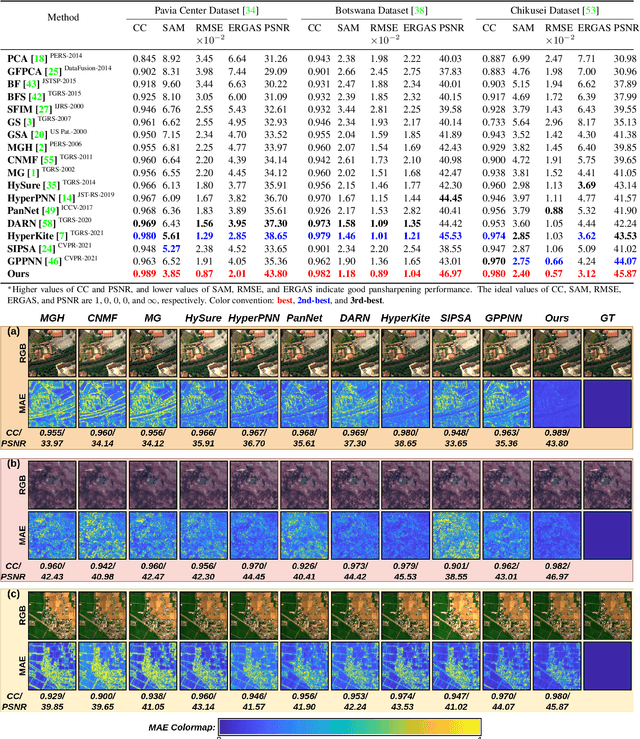
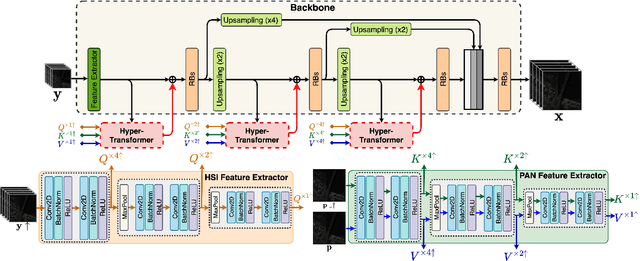
Pansharpening aims to fuse a registered high-resolution panchromatic image (PAN) with a low-resolution hyperspectral image (LR-HSI) to generate an enhanced HSI with high spectral and spatial resolution. Existing pansharpening approaches neglect using an attention mechanism to transfer HR texture features from PAN to LR-HSI features, resulting in spatial and spectral distortions. In this paper, we present a novel attention mechanism for pansharpening called HyperTransformer, in which features of LR-HSI and PAN are formulated as queries and keys in a transformer, respectively. HyperTransformer consists of three main modules, namely two separate feature extractors for PAN and HSI, a multi-head feature soft attention module, and a spatial-spectral feature fusion module. Such a network improves both spatial and spectral quality measures of the pansharpened HSI by learning cross-feature space dependencies and long-range details of PAN and LR-HSI. Furthermore, HyperTransformer can be utilized across multiple spatial scales at the backbone for obtaining improved performance. Extensive experiments conducted on three widely used datasets demonstrate that HyperTransformer achieves significant improvement over the state-of-the-art methods on both spatial and spectral quality measures. Implementation code and pre-trained weights can be accessed at https://github.com/wgcban/HyperTransformer.
Exploiting the relationship between visual and textual features in social networks for image classification with zero-shot deep learning
Jul 08, 2021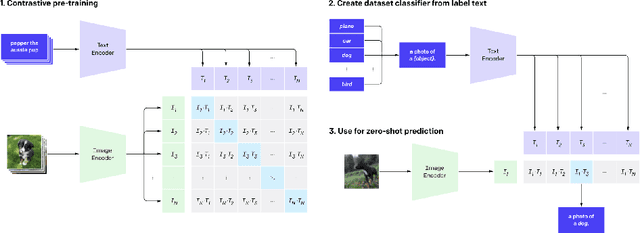


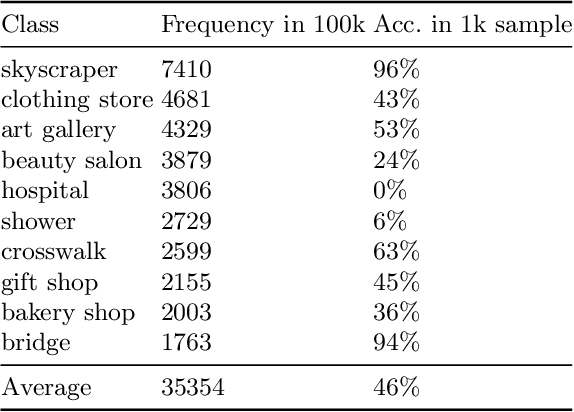
One of the main issues related to unsupervised machine learning is the cost of processing and extracting useful information from large datasets. In this work, we propose a classifier ensemble based on the transferable learning capabilities of the CLIP neural network architecture in multimodal environments (image and text) from social media. For this purpose, we used the InstaNY100K dataset and proposed a validation approach based on sampling techniques. Our experiments, based on image classification tasks according to the labels of the Places dataset, are performed by first considering only the visual part, and then adding the associated texts as support. The results obtained demonstrated that trained neural networks such as CLIP can be successfully applied to image classification with little fine-tuning, and considering the associated texts to the images can help to improve the accuracy depending on the goal. The results demonstrated what seems to be a promising research direction.
AIM 2020 Challenge on Image Extreme Inpainting
Oct 02, 2020
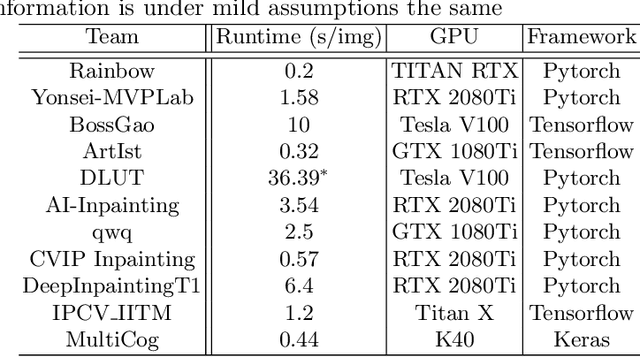
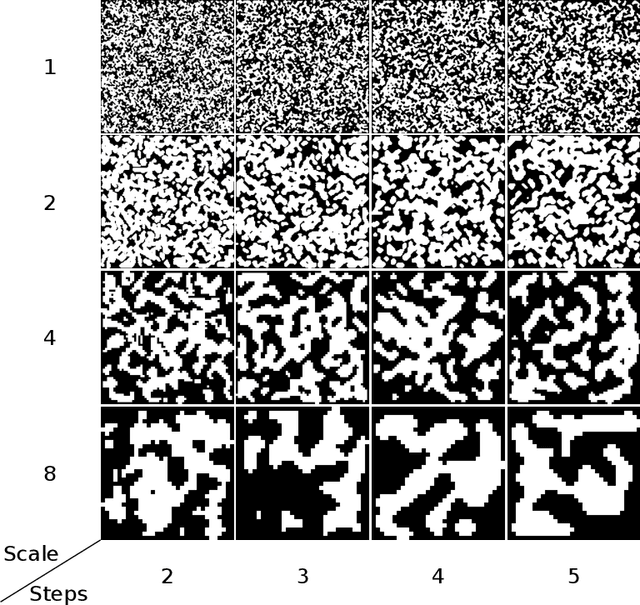
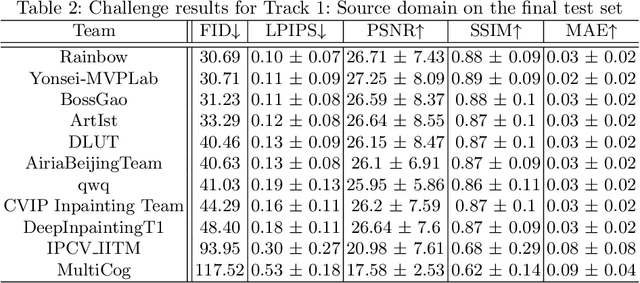
This paper reviews the AIM 2020 challenge on extreme image inpainting. This report focuses on proposed solutions and results for two different tracks on extreme image inpainting: classical image inpainting and semantically guided image inpainting. The goal of track 1 is to inpaint considerably large part of the image using no supervision but the context. Similarly, the goal of track 2 is to inpaint the image by having access to the entire semantic segmentation map of the image to inpaint. The challenge had 88 and 74 participants, respectively. 11 and 6 teams competed in the final phase of the challenge, respectively. This report gauges current solutions and set a benchmark for future extreme image inpainting methods.
FHIST: A Benchmark for Few-shot Classification of Histological Images
May 31, 2022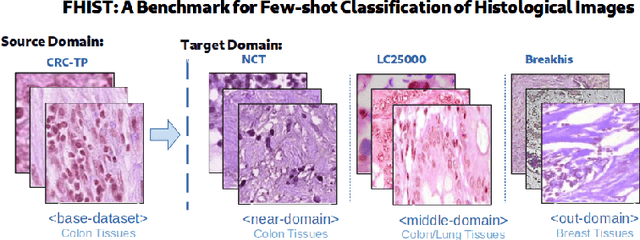
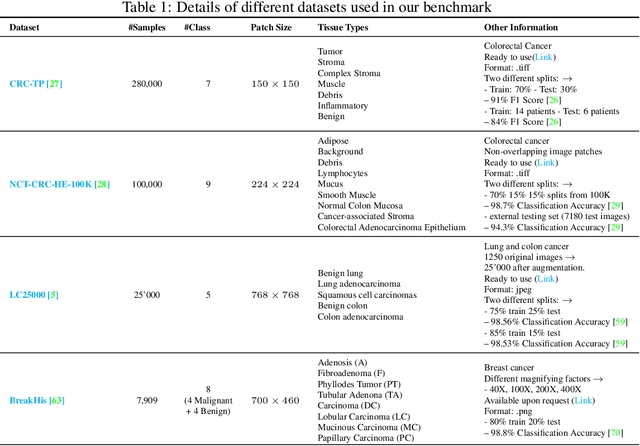
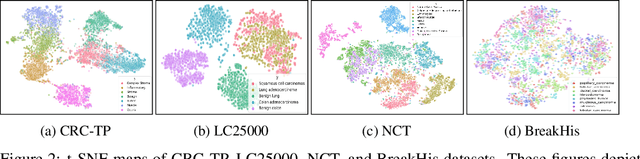
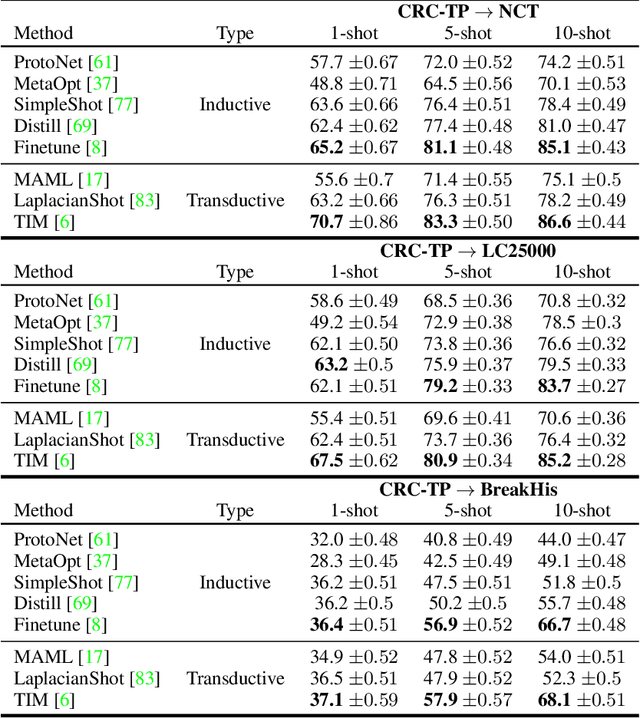
Few-shot learning has recently attracted wide interest in image classification, but almost all the current public benchmarks are focused on natural images. The few-shot paradigm is highly relevant in medical-imaging applications due to the scarcity of labeled data, as annotations are expensive and require specialized expertise. However, in medical imaging, few-shot learning research is sparse, limited to private data sets and is at its early stage. In particular, the few-shot setting is of high interest in histology due to the diversity and fine granularity of cancer related tissue classification tasks, and the variety of data-preparation techniques. This paper introduces a highly diversified public benchmark, gathered from various public datasets, for few-shot histology data classification. We build few-shot tasks and base-training data with various tissue types, different levels of domain shifts stemming from various cancer sites, and different class-granularity levels, thereby reflecting realistic scenarios. We evaluate the performances of state-of-the-art few-shot learning methods on our benchmark, and observe that simple fine-tuning and regularization methods achieve better results than the popular meta-learning and episodic-training paradigm. Furthermore, we introduce three scenarios based on the domain shifts between the source and target histology data: near-domain, middle-domain and out-domain. Our experiments display the potential of few-shot learning in histology classification, with state-of-art few shot learning methods approaching the supervised-learning baselines in the near-domain setting. In our out-domain setting, for 5-way 5-shot, the best performing method reaches 60% accuracy. We believe that our work could help in building realistic evaluations and fair comparisons of few-shot learning methods and will further encourage research in the few-shot paradigm.
Unsupervised Simultaneous Learning for Camera Re-Localization and Depth Estimation from Video
Mar 24, 2022
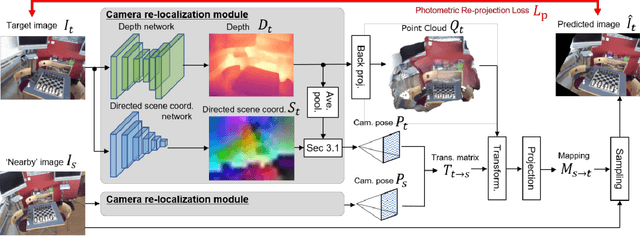


We present an unsupervised simultaneous learning framework for the task of monocular camera re-localization and depth estimation from unlabeled video sequences. Monocular camera re-localization refers to the task of estimating the absolute camera pose from an instance image in a known environment, which has been intensively studied for alternative localization in GPS-denied environments. In recent works, camera re-localization methods are trained via supervised learning from pairs of camera images and camera poses. In contrast to previous works, we propose a completely unsupervised learning framework for camera re-localization and depth estimation, requiring only monocular video sequences for training. In our framework, we train two networks that estimate the scene coordinates using directions and the depth map from each image which are then combined to estimate the camera pose. The networks can be trained through the minimization of loss functions based on our loop closed view synthesis. In experiments with the 7-scenes dataset, the proposed method outperformed the re-localization of the state-of-the-art visual SLAM, ORB-SLAM3. Our method also outperforms state-of-the-art monocular depth estimation in a trained environment.
Noise-based Enhancement for Foveated Rendering
Apr 09, 2022
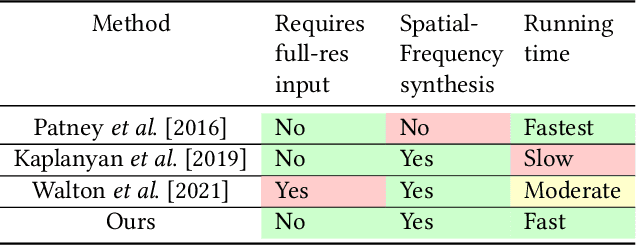
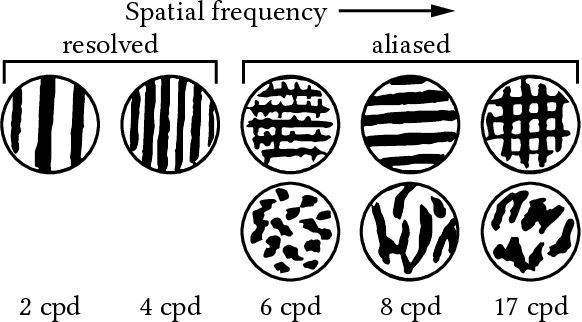
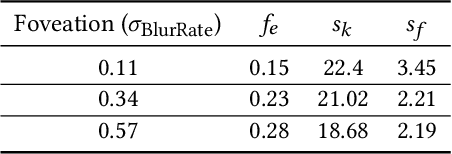
Human visual sensitivity to spatial details declines towards the periphery. Novel image synthesis techniques, so-called foveated rendering, exploit this observation and reduce the spatial resolution of synthesized images for the periphery, avoiding the synthesis of high-spatial-frequency details that are costly to generate but not perceived by a viewer. However, contemporary techniques do not make a clear distinction between the range of spatial frequencies that must be reproduced and those that can be omitted. For a given eccentricity, there is a range of frequencies that are detectable but not resolvable. While the accurate reproduction of these frequencies is not required, an observer can detect their absence if completely omitted. We use this observation to improve the performance of existing foveated rendering techniques. We demonstrate that this specific range of frequencies can be efficiently replaced with procedural noise whose parameters are carefully tuned to image content and human perception. Consequently, these frequencies do not have to be synthesized during rendering, allowing more aggressive foveation, and they can be replaced by noise generated in a less expensive post-processing step, leading to improved performance of the rendering system. Our main contribution is a perceptually-inspired technique for deriving the parameters of the noise required for the enhancement and its calibration. The method operates on rendering output and runs at rates exceeding 200FPS at 4K resolution, making it suitable for integration with real-time foveated rendering systems for VR and AR devices. We validate our results and compare them to the existing contrast enhancement technique in user experiments.
RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition
May 05, 2021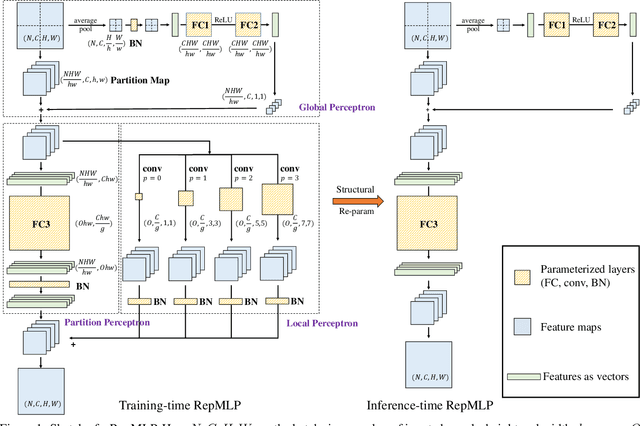
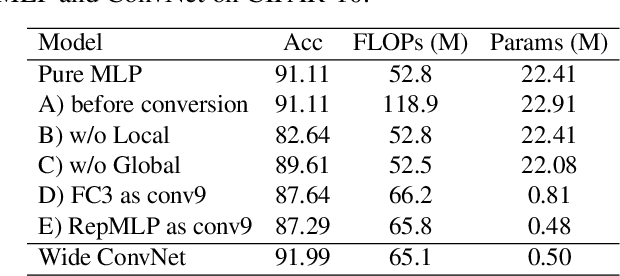
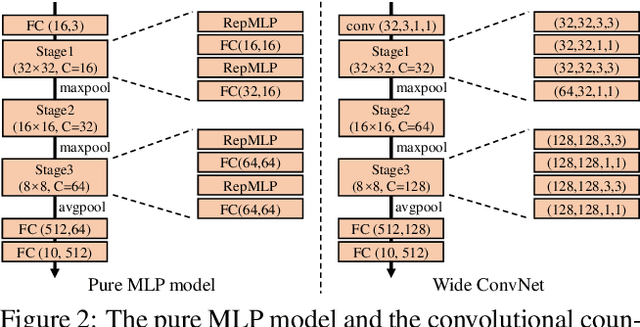
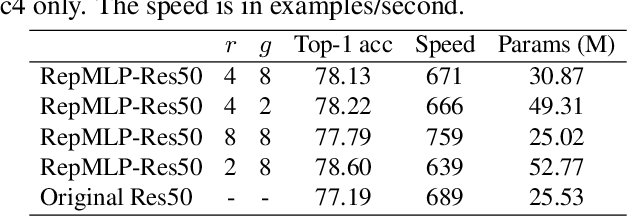
We propose RepMLP, a multi-layer-perceptron-style neural network building block for image recognition, which is composed of a series of fully-connected (FC) layers. Compared to convolutional layers, FC layers are more efficient, better at modeling the long-range dependencies and positional patterns, but worse at capturing the local structures, hence usually less favored for image recognition. We propose a structural re-parameterization technique that adds local prior into an FC to make it powerful for image recognition. Specifically, we construct convolutional layers inside a RepMLP during training and merge them into the FC for inference. On CIFAR, a simple pure-MLP model shows performance very close to CNN. By inserting RepMLP in traditional CNN, we improve ResNets by 1.8% accuracy on ImageNet, 2.9% for face recognition, and 2.3% mIoU on Cityscapes with lower FLOPs. Our intriguing findings highlight that combining the global representational capacity and positional perception of FC with the local prior of convolution can improve the performance of neural network with faster speed on both the tasks with translation invariance (e.g., semantic segmentation) and those with aligned images and positional patterns (e.g., face recognition). The code and models are available at https://github.com/DingXiaoH/RepMLP.