 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Blind Face Restoration: Benchmark Datasets and a Baseline Model
Jun 08, 2022
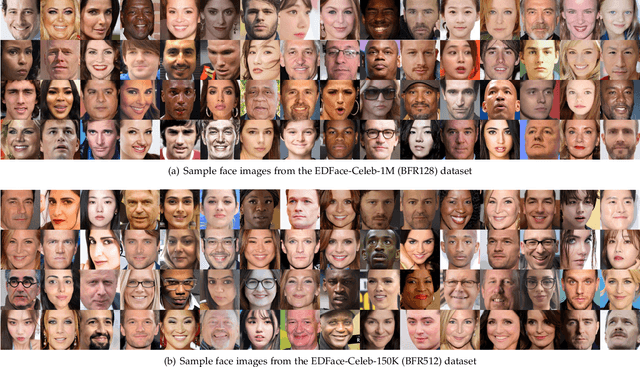
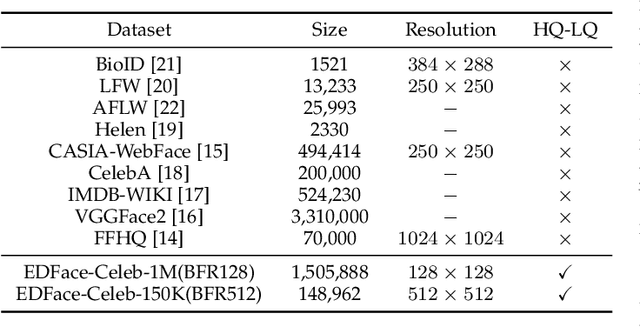


Blind Face Restoration (BFR) aims to construct a high-quality (HQ) face image from its corresponding low-quality (LQ) input. Recently, many BFR methods have been proposed and they have achieved remarkable success. However, these methods are trained or evaluated on privately synthesized datasets, which makes it infeasible for the subsequent approaches to fairly compare with them. To address this problem, we first synthesize two blind face restoration benchmark datasets called EDFace-Celeb-1M (BFR128) and EDFace-Celeb-150K (BFR512). State-of-the-art methods are benchmarked on them under five settings including blur, noise, low resolution, JPEG compression artifacts, and the combination of them (full degradation). To make the comparison more comprehensive, five widely-used quantitative metrics and two task-driven metrics including Average Face Landmark Distance (AFLD) and Average Face ID Cosine Similarity (AFICS) are applied. Furthermore, we develop an effective baseline model called Swin Transformer U-Net (STUNet). The STUNet with U-net architecture applies an attention mechanism and a shifted windowing scheme to capture long-range pixel interactions and focus more on significant features while still being trained efficiently. Experimental results show that the proposed baseline method performs favourably against the SOTA methods on various BFR tasks.
OUR-GAN: One-shot Ultra-high-Resolution Generative Adversarial Networks
Feb 28, 2022

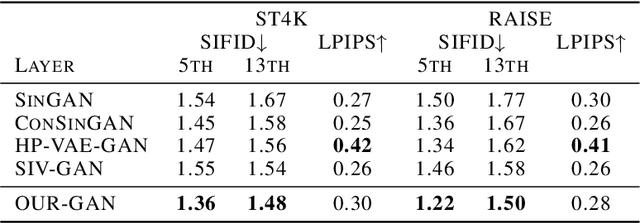
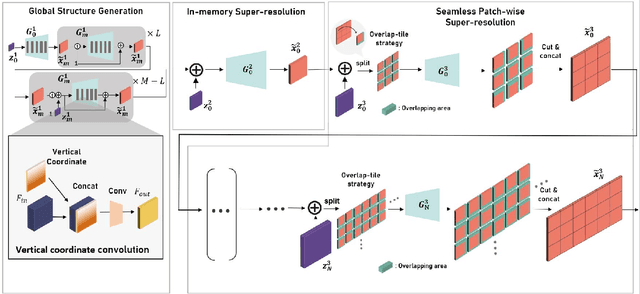
We propose OUR-GAN, the first one-shot ultra-high-resolution (UHR) image synthesis framework that generates non-repetitive images with 4K or higher resolution from a single training image. OUR-GAN generates a visually coherent image at low resolution and then gradually increases the resolution by super-resolution. Since OUR-GAN learns from a real UHR image, it can synthesize large-scale shapes with fine details while maintaining long-range coherence, which is difficult with conventional generative models that generate large images based on the patch distribution learned from relatively small images. OUR-GAN applies seamless subregion-wise super-resolution that synthesizes 4k or higher UHR images with limited memory, preventing discontinuity at the boundary. Additionally, OUR-GAN improves visual coherence maintaining diversity by adding vertical positional embeddings to the feature maps. In experiments on the ST4K and RAISE datasets, OUR-GAN exhibited improved fidelity, visual coherency, and diversity compared with existing methods. The synthesized images are presented at https://anonymous-62348.github.io.
Image Classification on Small Datasets via Masked Feature Mixing
Feb 23, 2022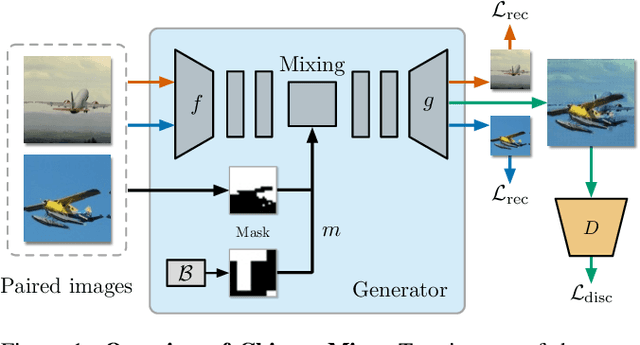
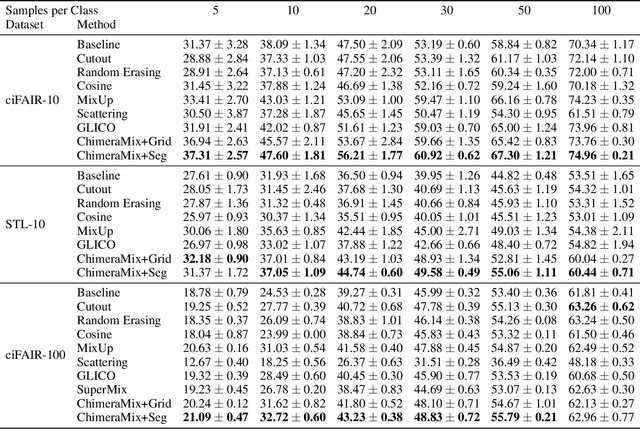

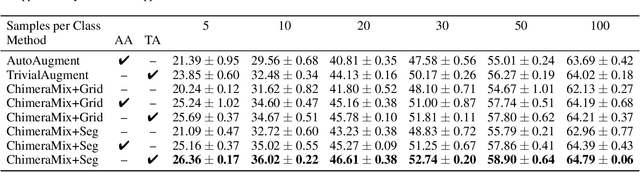
Deep convolutional neural networks require large amounts of labeled data samples. For many real-world applications, this is a major limitation which is commonly treated by augmentation methods. In this work, we address the problem of learning deep neural networks on small datasets. Our proposed architecture called ChimeraMix learns a data augmentation by generating compositions of instances. The generative model encodes images in pairs, combines the features guided by a mask, and creates new samples. For evaluation, all methods are trained from scratch without any additional data. Several experiments on benchmark datasets, e.g. ciFAIR-10, STL-10, and ciFAIR-100, demonstrate the superior performance of ChimeraMix compared to current state-of-the-art methods for classification on small datasets.
Few-Shot Diffusion Models
May 30, 2022

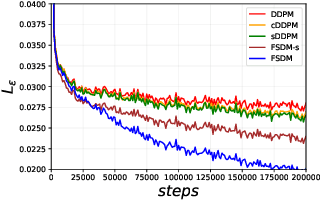
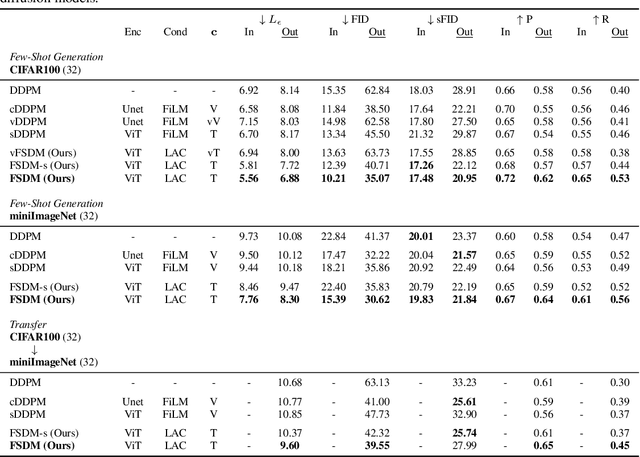
Denoising diffusion probabilistic models (DDPM) are powerful hierarchical latent variable models with remarkable sample generation quality and training stability. These properties can be attributed to parameter sharing in the generative hierarchy, as well as a parameter-free diffusion-based inference procedure. In this paper, we present Few-Shot Diffusion Models (FSDM), a framework for few-shot generation leveraging conditional DDPMs. FSDMs are trained to adapt the generative process conditioned on a small set of images from a given class by aggregating image patch information using a set-based Vision Transformer (ViT). At test time, the model is able to generate samples from previously unseen classes conditioned on as few as 5 samples from that class. We empirically show that FSDM can perform few-shot generation and transfer to new datasets. We benchmark variants of our method on complex vision datasets for few-shot learning and compare to unconditional and conditional DDPM baselines. Additionally, we show how conditioning the model on patch-based input set information improves training convergence.
Neural Basis Models for Interpretability
Jun 08, 2022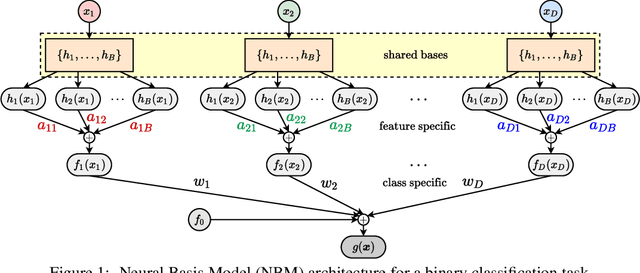
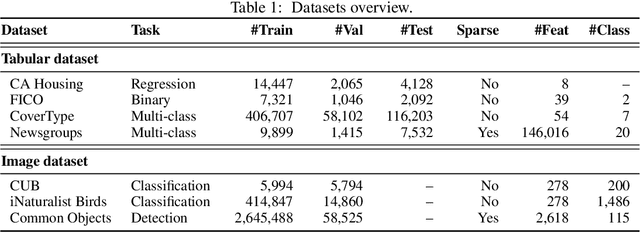
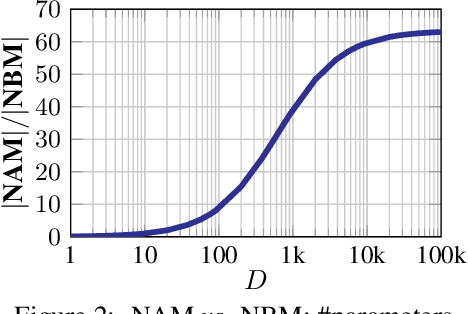
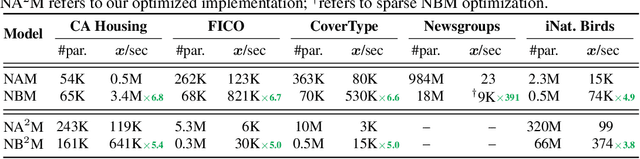
Due to the widespread use of complex machine learning models in real-world applications, it is becoming critical to explain model predictions. However, these models are typically black-box deep neural networks, explained post-hoc via methods with known faithfulness limitations. Generalized Additive Models (GAMs) are an inherently interpretable class of models that address this limitation by learning a non-linear shape function for each feature separately, followed by a linear model on top. However, these models are typically difficult to train, require numerous parameters, and are difficult to scale. We propose an entirely new subfamily of GAMs that utilizes basis decomposition of shape functions. A small number of basis functions are shared among all features, and are learned jointly for a given task, thus making our model scale much better to large-scale data with high-dimensional features, especially when features are sparse. We propose an architecture denoted as the Neural Basis Model (NBM) which uses a single neural network to learn these bases. On a variety of tabular and image datasets, we demonstrate that for interpretable machine learning, NBMs are the state-of-the-art in accuracy, model size, and, throughput and can easily model all higher-order feature interactions. Source code is available at https://github.com/facebookresearch/nbm-spam.
Human Perception Modeling for Automatic Natural Image Matting
Mar 31, 2021
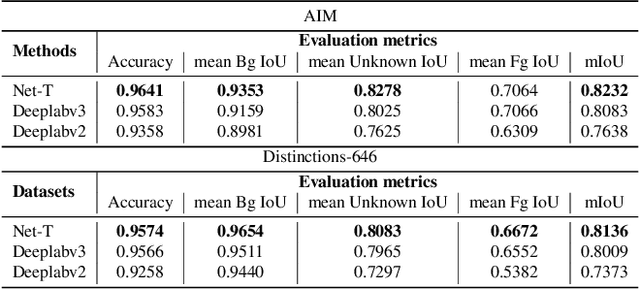
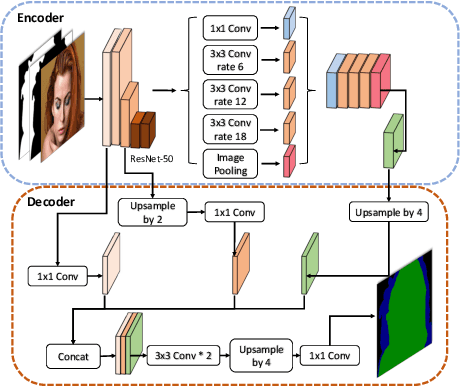

Natural image matting aims to precisely separate foreground objects from background using alpha matte. Fully automatic natural image matting without external annotation is quite challenging. Well-performed matting methods usually require accurate handcrafted trimap as extra input, which is labor-intensive and time-consuming, while the performance of automatic trimap generation method of dilating foreground segmentation fluctuates with segmentation quality. In this paper, we argue that how to handle trade-off of additional information input is a major issue in automatic matting, which we decompose into two subtasks: trimap and alpha estimation. By leveraging easily-accessible coarse annotations and modeling alpha matte handmade process of capturing rough foreground/background/transition boundary and carving delicate details in transition region, we propose an intuitively-designed trimap-free two-stage matting approach without additional annotations, e.g. trimap and background image. Specifically, given an image and its coarse foreground segmentation, Trimap Generation Network estimates probabilities of foreground, unknown, and background regions to guide alpha feature flow of our proposed Non-Local Matting network, which is equipped with trimap-guided global aggregation attention block. Experimental results show that our matting algorithm has competitive performance with current state-of-the-art methods in both trimap-free and trimap-needed aspects.
DrawingInStyles: Portrait Image Generation and Editing with Spatially Conditioned StyleGAN
Mar 05, 2022

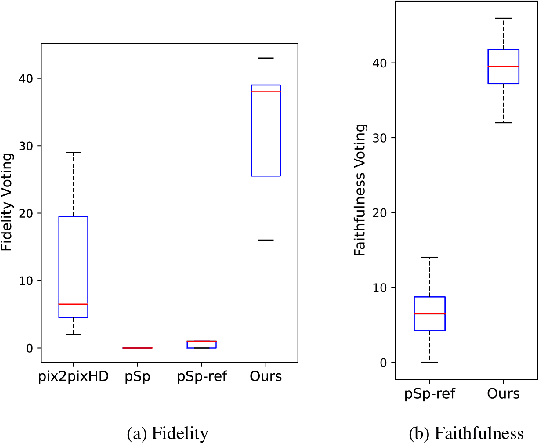
The research topic of sketch-to-portrait generation has witnessed a boost of progress with deep learning techniques. The recently proposed StyleGAN architectures achieve state-of-the-art generation ability but the original StyleGAN is not friendly for sketch-based creation due to its unconditional generation nature. To address this issue, we propose a direct conditioning strategy to better preserve the spatial information under the StyleGAN framework. Specifically, we introduce Spatially Conditioned StyleGAN (SC-StyleGAN for short), which explicitly injects spatial constraints to the original StyleGAN generation process. We explore two input modalities, sketches and semantic maps, which together allow users to express desired generation results more precisely and easily. Based on SC-StyleGAN, we present DrawingInStyles, a novel drawing interface for non-professional users to easily produce high-quality, photo-realistic face images with precise control, either from scratch or editing existing ones. Qualitative and quantitative evaluations show the superior generation ability of our method to existing and alternative solutions. The usability and expressiveness of our system are confirmed by a user study.
Quarter Laplacian Filter for Edge Aware Image Processing
Jan 20, 2021
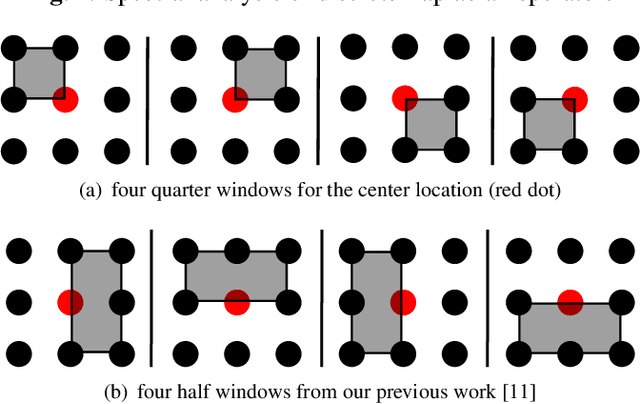

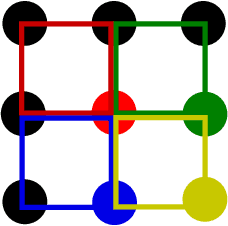
This paper presents a quarter Laplacian filter that can preserve corners and edges during image smoothing. Its support region is $2\times2$, which is smaller than the $3\times3$ support region of Laplacian filter. Thus, it is more local. Moreover, this filter can be implemented via the classical box filter, leading to high performance for real time applications. Finally, we show its edge preserving property in several image processing tasks, including image smoothing, texture enhancement, and low-light image enhancement. The proposed filter can be adopted in a wide range of image processing applications.
Learning to segment with limited annotations: Self-supervised pretraining with regression and contrastive loss in MRI
May 26, 2022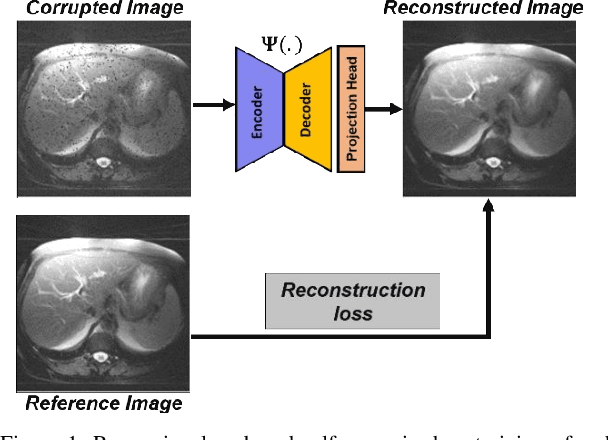
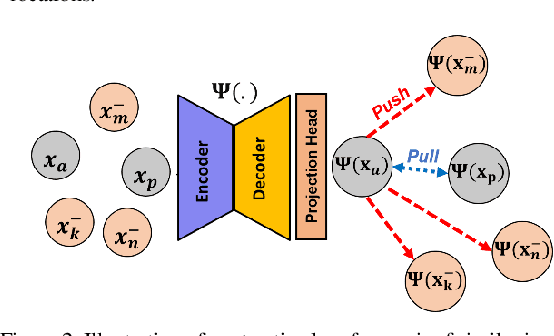
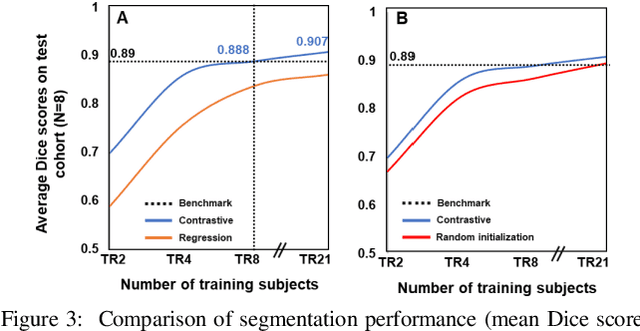
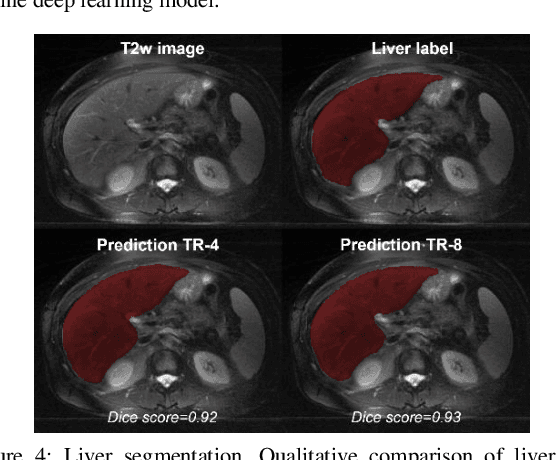
Obtaining manual annotations for large datasets for supervised training of deep learning (DL) models is challenging. The availability of large unlabeled datasets compared to labeled ones motivate the use of self-supervised pretraining to initialize DL models for subsequent segmentation tasks. In this work, we consider two pre-training approaches for driving a DL model to learn different representations using: a) regression loss that exploits spatial dependencies within an image and b) contrastive loss that exploits semantic similarity between pairs of images. The effect of pretraining techniques is evaluated in two downstream segmentation applications using Magnetic Resonance (MR) images: a) liver segmentation in abdominal T2-weighted MR images and b) prostate segmentation in T2-weighted MR images of the prostate. We observed that DL models pretrained using self-supervision can be finetuned for comparable performance with fewer labeled datasets. Additionally, we also observed that initializing the DL model using contrastive loss based pretraining performed better than the regression loss.
Towards Fine-grained Image Classification with Generative Adversarial Networks and Facial Landmark Detection
Aug 28, 2021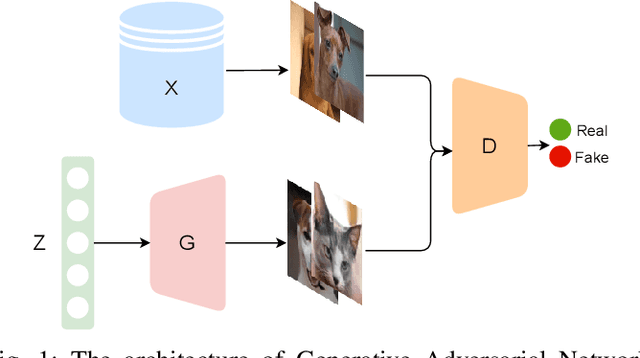
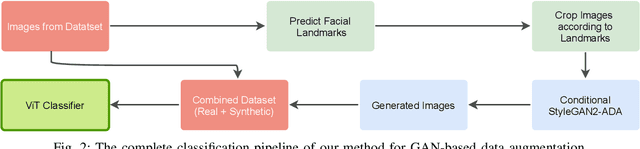


Fine-grained classification remains a challenging task because distinguishing categories needs learning complex and local differences. Diversity in the pose, scale, and position of objects in an image makes the problem even more difficult. Although the recent Vision Transformer models achieve high performance, they need an extensive volume of input data. To encounter this problem, we made the best use of GAN-based data augmentation to generate extra dataset instances. Oxford-IIIT Pets was our dataset of choice for this experiment. It consists of 37 breeds of cats and dogs with variations in scale, poses, and lighting, which intensifies the difficulty of the classification task. Furthermore, we enhanced the performance of the recent Generative Adversarial Network (GAN), StyleGAN2-ADA model to generate more realistic images while preventing overfitting to the training set. We did this by training a customized version of MobileNetV2 to predict animal facial landmarks; then, we cropped images accordingly. Lastly, we combined the synthetic images with the original dataset and compared our proposed method with standard GANs augmentation and no augmentation with different subsets of training data. We validated our work by evaluating the accuracy of fine-grained image classification on the recent Vision Transformer (ViT) Model.