 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SG2Caps: Revisiting Scene Graphs for Image Captioning
Feb 09, 2021
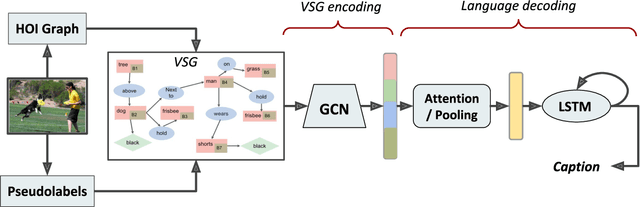
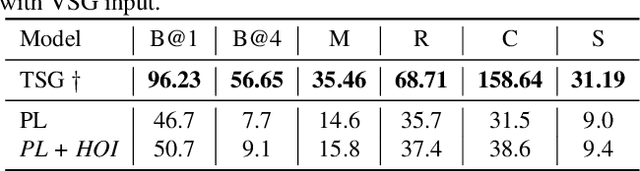
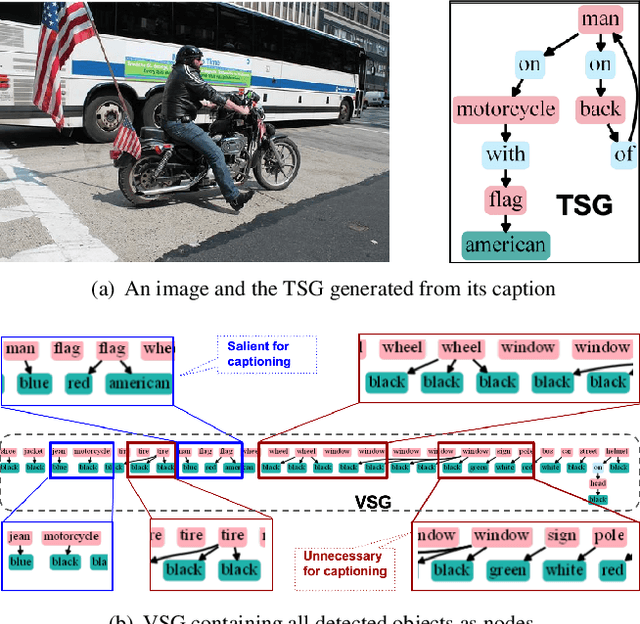
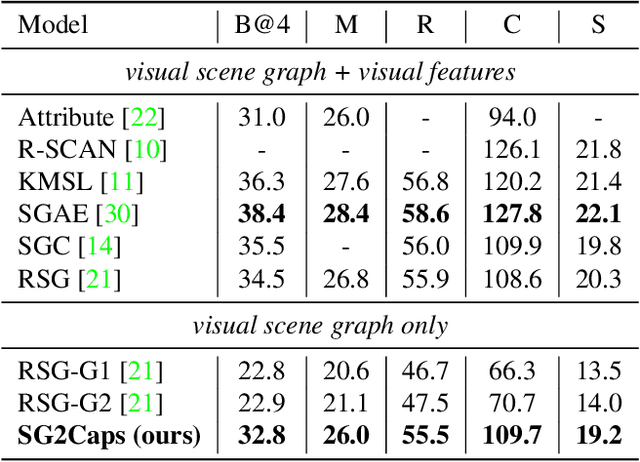
The mainstream image captioning models rely on Convolutional Neural Network (CNN) image features with an additional attention to salient regions and objects to generate captions via recurrent models. Recently, scene graph representations of images have been used to augment captioning models so as to leverage their structural semantics, such as object entities, relationships and attributes. Several studies have noted that naive use of scene graphs from a black-box scene graph generator harms image caption-ing performance, and scene graph-based captioning mod-els have to incur the overhead of explicit use of image features to generate decent captions. Addressing these challenges, we propose a framework, SG2Caps, that utilizes only the scene graph labels for competitive image caption-ing performance. The basic idea is to close the semantic gap between two scene graphs - one derived from the input image and the other one from its caption. In order to achieve this, we leverage the spatial location of objects and the Human-Object-Interaction (HOI) labels as an additional HOI graph. Our framework outperforms existing scene graph-only captioning models by a large margin (CIDEr score of 110 vs 71) indicating scene graphs as a promising representation for image captioning. Direct utilization of the scene graph labels avoids expensive graph convolutions over high-dimensional CNN features resulting in 49%fewer trainable parameters.
Convolutional Neural Network Based Partial Face Detection
Jun 29, 2022

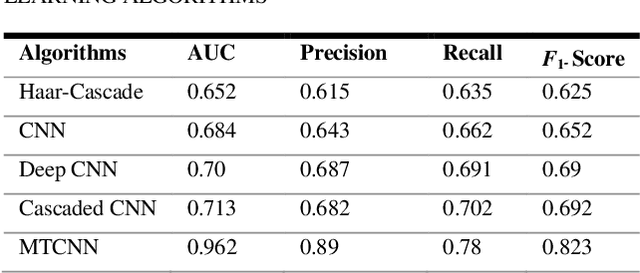

Due to the massive explanation of artificial intelligence, machine learning technology is being used in various areas of our day-to-day life. In the world, there are a lot of scenarios where a simple crime can be prevented before it may even happen or find the person responsible for it. A face is one distinctive feature that we have and can differentiate easily among many other species. But not just different species, it also plays a significant role in determining someone from the same species as us, humans. Regarding this critical feature, a single problem occurs most often nowadays. When the camera is pointed, it cannot detect a person's face, and it becomes a poor image. On the other hand, where there was a robbery and a security camera installed, the robber's identity is almost indistinguishable due to the low-quality camera. But just making an excellent algorithm to work and detecting a face reduces the cost of hardware, and it doesn't cost that much to focus on that area. Facial recognition, widget control, and such can be done by detecting the face correctly. This study aims to create and enhance a machine learning model that correctly recognizes faces. Total 627 Data have been collected from different Bangladeshi people's faces on four angels. In this work, CNN, Harr Cascade, Cascaded CNN, Deep CNN & MTCNN are these five machine learning approaches implemented to get the best accuracy of our dataset. After creating and running the model, Multi-Task Convolutional Neural Network (MTCNN) achieved 96.2% best model accuracy with training data rather than other machine learning models.
Semantically Self-Aligned Network for Text-to-Image Part-aware Person Re-identification
Jul 27, 2021
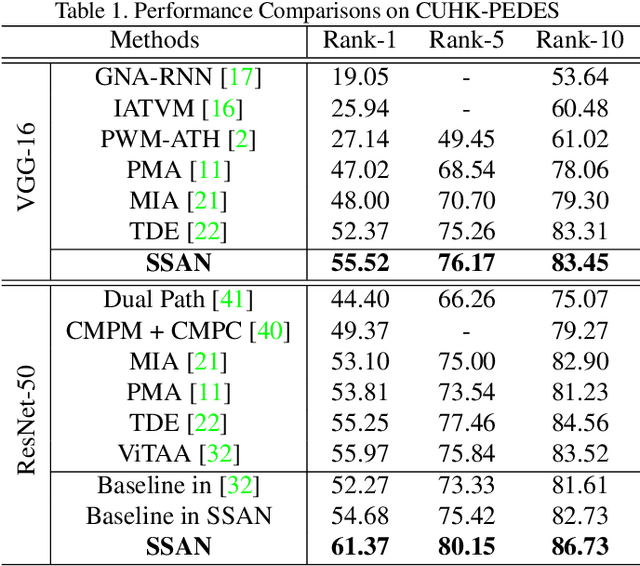
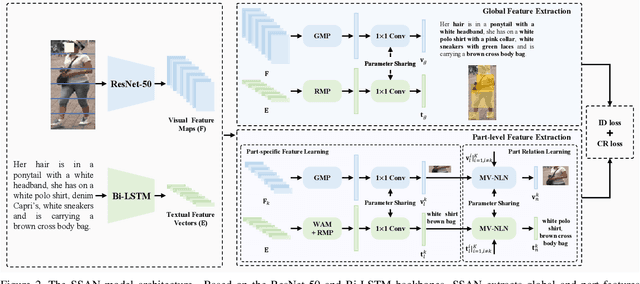
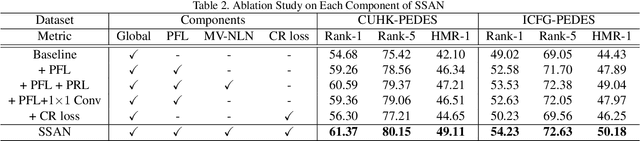
Text-to-image person re-identification (ReID) aims to search for images containing a person of interest using textual descriptions. However, due to the significant modality gap and the large intra-class variance in textual descriptions, text-to-image ReID remains a challenging problem. Accordingly, in this paper, we propose a Semantically Self-Aligned Network (SSAN) to handle the above problems. First, we propose a novel method that automatically extracts semantically aligned part-level features from the two modalities. Second, we design a multi-view non-local network that captures the relationships between body parts, thereby establishing better correspondences between body parts and noun phrases. Third, we introduce a Compound Ranking (CR) loss that makes use of textual descriptions for other images of the same identity to provide extra supervision, thereby effectively reducing the intra-class variance in textual features. Finally, to expedite future research in text-to-image ReID, we build a new database named ICFG-PEDES. Extensive experiments demonstrate that SSAN outperforms state-of-the-art approaches by significant margins. Both the new ICFG-PEDES database and the SSAN code are available at https://github.com/zifyloo/SSAN.
Stabilized Medical Image Attacks
Mar 09, 2021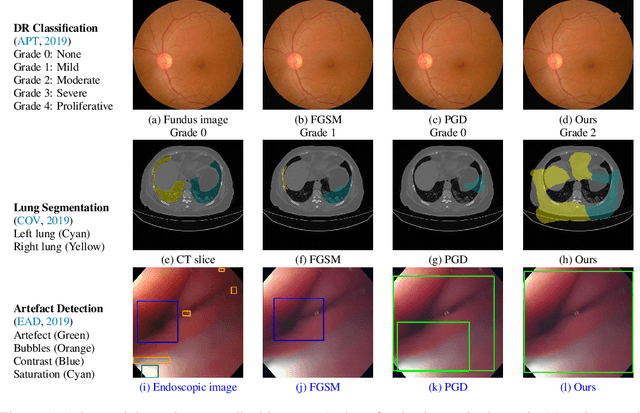

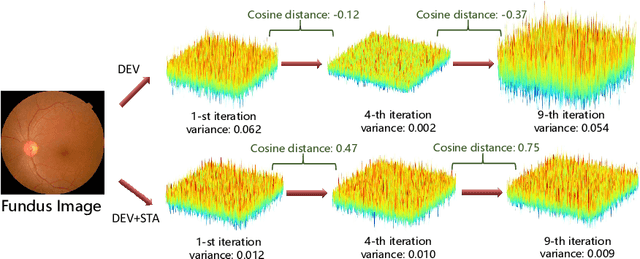
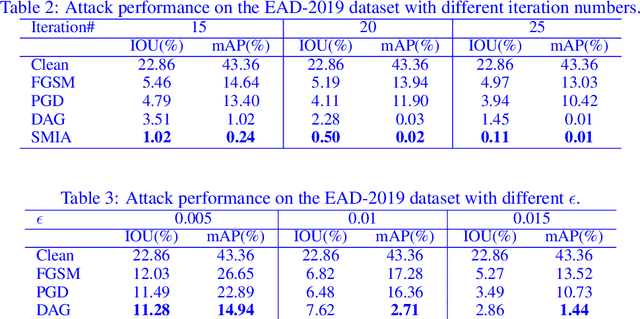
Convolutional Neural Networks (CNNs) have advanced existing medical systems for automatic disease diagnosis. However, a threat to these systems arises that adversarial attacks make CNNs vulnerable. Inaccurate diagnosis results make a negative influence on human healthcare. There is a need to investigate potential adversarial attacks to robustify deep medical diagnosis systems. On the other side, there are several modalities of medical images (e.g., CT, fundus, and endoscopic image) of which each type is significantly different from others. It is more challenging to generate adversarial perturbations for different types of medical images. In this paper, we propose an image-based medical adversarial attack method to consistently produce adversarial perturbations on medical images. The objective function of our method consists of a loss deviation term and a loss stabilization term. The loss deviation term increases the divergence between the CNN prediction of an adversarial example and its ground truth label. Meanwhile, the loss stabilization term ensures similar CNN predictions of this example and its smoothed input. From the perspective of the whole iterations for perturbation generation, the proposed loss stabilization term exhaustively searches the perturbation space to smooth the single spot for local optimum escape. We further analyze the KL-divergence of the proposed loss function and find that the loss stabilization term makes the perturbations updated towards a fixed objective spot while deviating from the ground truth. This stabilization ensures the proposed medical attack effective for different types of medical images while producing perturbations in small variance. Experiments on several medical image analysis benchmarks including the recent COVID-19 dataset show the stability of the proposed method.
Learning to Predict RNA Sequence Expressions from Whole Slide Images with Applications for Search and Classification
Mar 26, 2022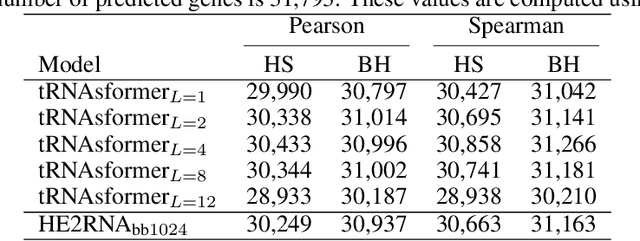
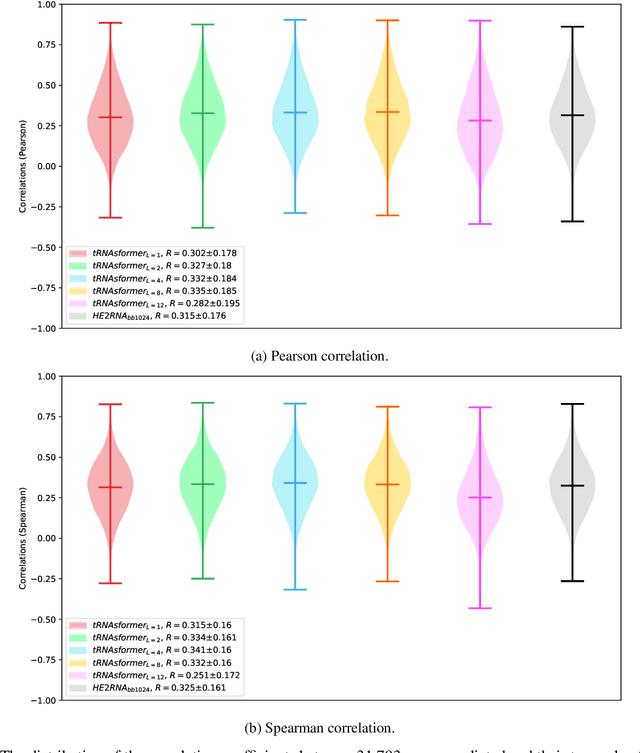
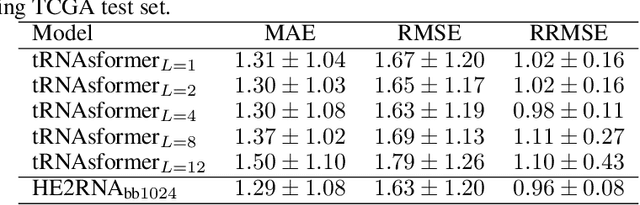
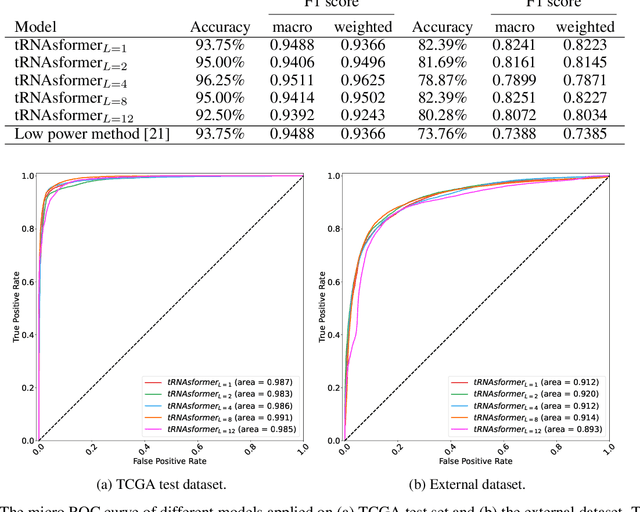
Deep learning methods are widely applied in digital pathology to address clinical challenges such as prognosis and diagnosis. As one of the most recent applications, deep models have also been used to extract molecular features from whole slide images. Although molecular tests carry rich information, they are often expensive, time-consuming, and require additional tissue to sample. In this paper, we propose tRNAsfomer, an attention-based topology that can learn both to predict the bulk RNA-seq from an image and represent the whole slide image of a glass slide simultaneously. The tRNAsfomer uses multiple instance learning to solve a weakly supervised problem while the pixel-level annotation is not available for an image. We conducted several experiments and achieved better performance and faster convergence in comparison to the state-of-the-art algorithms. The proposed tRNAsfomer can assist as a computational pathology tool to facilitate a new generation of search and classification methods by combining the tissue morphology and the molecular fingerprint of the biopsy samples.
Continual Learning for Image-Based Camera Localization
Aug 20, 2021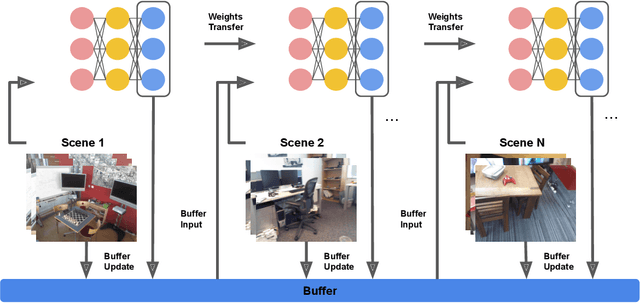
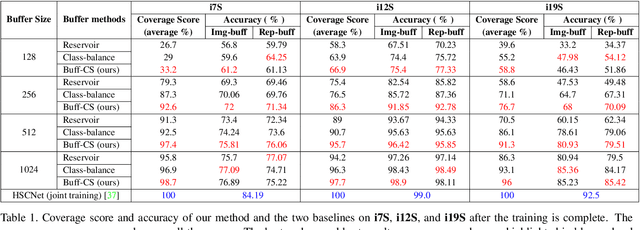
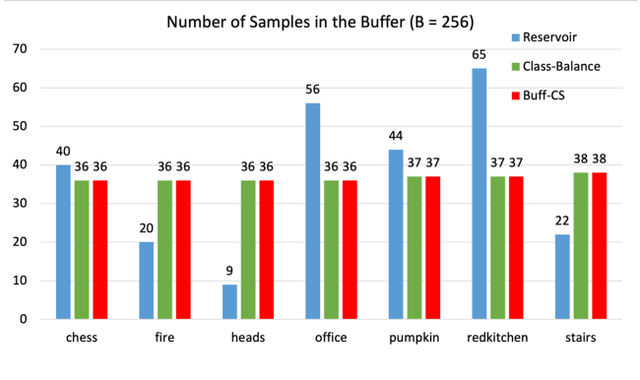

For several emerging technologies such as augmented reality, autonomous driving and robotics, visual localization is a critical component. Directly regressing camera pose/3D scene coordinates from the input image using deep neural networks has shown great potential. However, such methods assume a stationary data distribution with all scenes simultaneously available during training. In this paper, we approach the problem of visual localization in a continual learning setup -- whereby the model is trained on scenes in an incremental manner. Our results show that similar to the classification domain, non-stationary data induces catastrophic forgetting in deep networks for visual localization. To address this issue, a strong baseline based on storing and replaying images from a fixed buffer is proposed. Furthermore, we propose a new sampling method based on coverage score (Buff-CS) that adapts the existing sampling strategies in the buffering process to the problem of visual localization. Results demonstrate consistent improvements over standard buffering methods on two challenging datasets -- 7Scenes, 12Scenes, and also 19Scenes by combining the former scenes.
Text to Image Generation with Semantic-Spatial Aware GAN
Apr 01, 2021
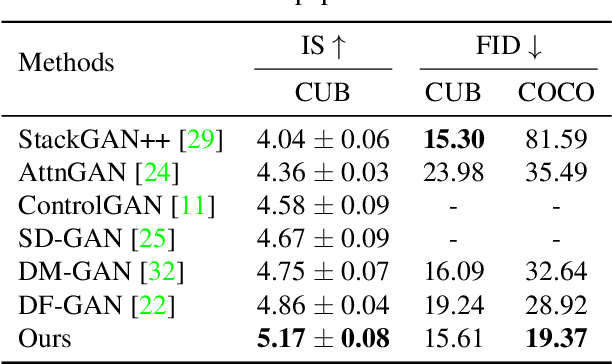


A text to image generation (T2I) model aims to generate photo-realistic images which are semantically consistent with the text descriptions. Built upon the recent advances in generative adversarial networks (GANs), existing T2I models have made great progress. However, a close inspection of their generated images reveals two major limitations: (1) The condition batch normalization methods are applied on the whole image feature maps equally, ignoring the local semantics; (2) The text encoder is fixed during training, which should be trained with the image generator jointly to learn better text representations for image generation. To address these limitations, we propose a novel framework Semantic-Spatial Aware GAN, which is trained in an end-to-end fashion so that the text encoder can exploit better text information. Concretely, we introduce a novel Semantic-Spatial Aware Convolution Network, which (1) learns semantic-adaptive transformation conditioned on text to effectively fuse text features and image features, and (2) learns a mask map in a weakly-supervised way that depends on the current text-image fusion process in order to guide the transformation spatially. Experiments on the challenging COCO and CUB bird datasets demonstrate the advantage of our method over the recent state-of-the-art approaches, regarding both visual fidelity and alignment with input text description.
Enhancing Medical Image Registration via Appearance Adjustment Networks
Mar 09, 2021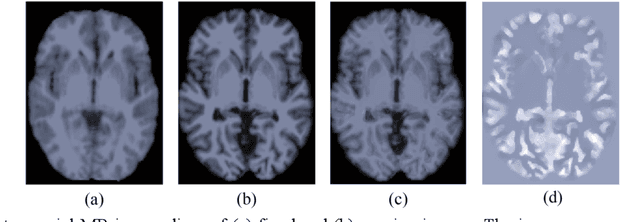
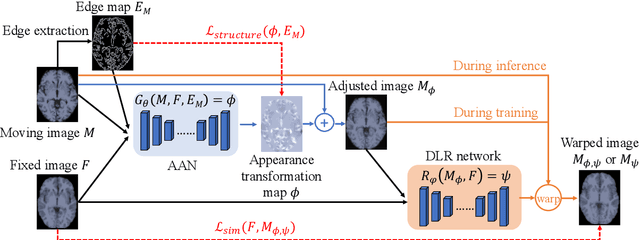
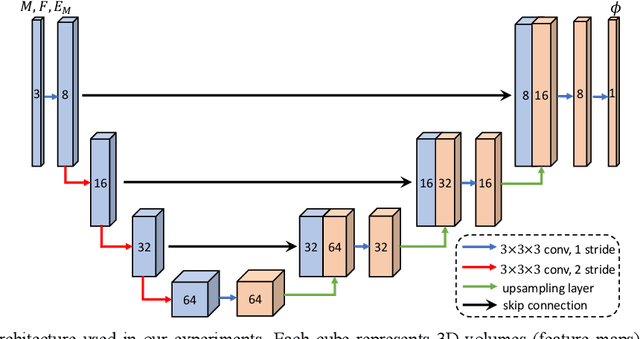
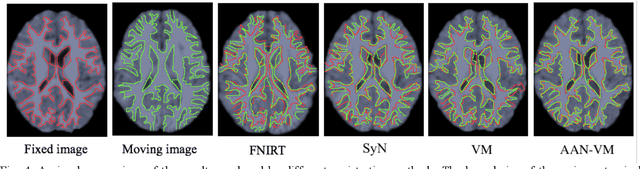
Deformable image registration is fundamental for many medical image analyses. A key obstacle for accurate image registration is the variations in image appearance. Recently, deep learning-based registration methods (DLRs), using deep neural networks, have computational efficiency that is several orders of magnitude greater than traditional optimization-based registration methods (ORs). A major drawback, however, of DLRs is a disregard for the target-pair-specific optimization that is inherent in ORs and instead they rely on a globally optimized network that is trained with a set of training samples to achieve faster registration. Thus, DLRs inherently have degraded ability to adapt to appearance variations and perform poorly, compared to ORs, when image pairs (fixed/moving images) have large differences in appearance. Hence, we propose an Appearance Adjustment Network (AAN) where we leverage anatomy edges, through an anatomy-constrained loss function, to generate an anatomy-preserving appearance transformation. We designed the AAN so that it can be readily inserted into a wide range of DLRs, to reduce the appearance differences between the fixed and moving images. Our AAN and DLR's network can be trained cooperatively in an unsupervised and end-to-end manner. We evaluated our AAN with two widely used DLRs - Voxelmorph (VM) and FAst IMage registration (FAIM) - on three public 3D brain magnetic resonance (MR) image datasets - IBSR18, Mindboggle101, and LPBA40. The results show that DLRs, using the AAN, improved performance and achieved higher results than state-of-the-art ORs.
A Multi-Scale A Contrario method for Unsupervised Image Anomaly Detection
Oct 05, 2021
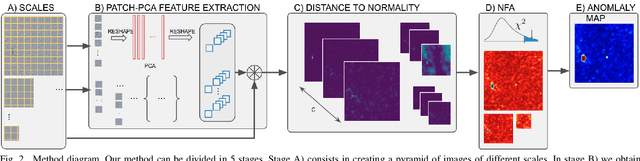
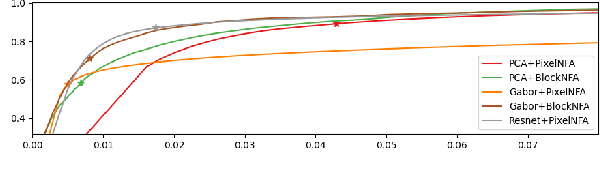
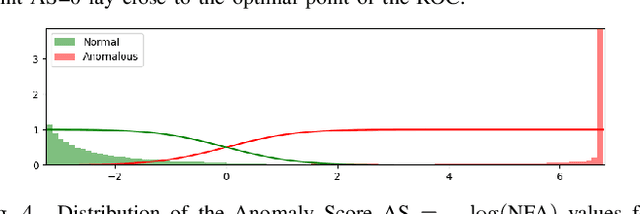
Anomalies can be defined as any non-random structure which deviates from normality. Anomaly detection methods reported in the literature are numerous and diverse, as what is considered anomalous usually varies depending on particular scenarios and applications. In this work we propose an a contrario framework to detect anomalies in images applying statistical analysis to feature maps obtained via convolutions. We evaluate filters learned from the image under analysis via patch PCA, Gabor filters and the feature maps obtained from a pre-trained deep neural network (Resnet). The proposed method is multi-scale and fully unsupervised and is able to detect anomalies in a wide variety of scenarios. While the end goal of this work is the detection of subtle defects in leather samples for the automotive industry, we show that the same algorithm achieves state of the art results in public anomalies datasets.
On the duality between contrastive and non-contrastive self-supervised learning
Jun 03, 2022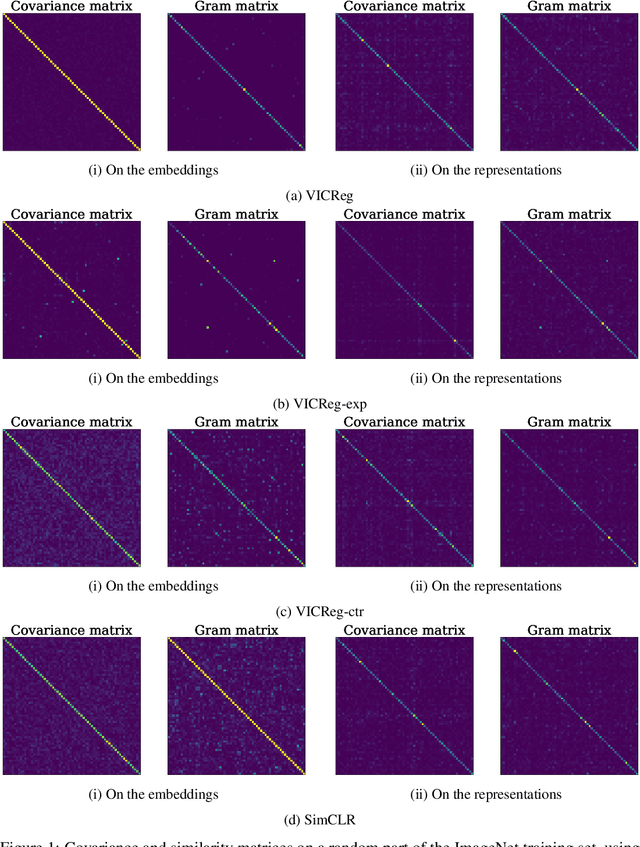
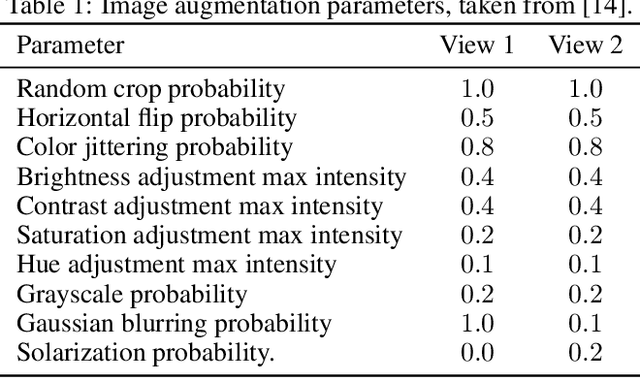
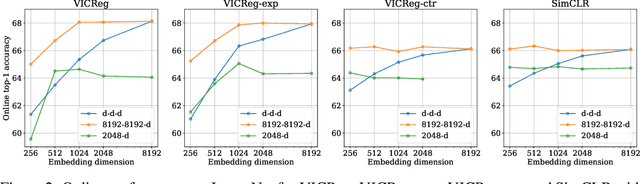

Recent approaches in self-supervised learning of image representations can be categorized into different families of methods and, in particular, can be divided into contrastive and non-contrastive approaches. While differences between the two families have been thoroughly discussed to motivate new approaches, we focus more on the theoretical similarities between them. By designing contrastive and non-contrastive criteria that can be related algebraically and shown to be equivalent under limited assumptions, we show how close those families can be. We further study popular methods and introduce variations of them, allowing us to relate this theoretical result to current practices and show how design choices in the criterion can influence the optimization process and downstream performance. We also challenge the popular assumptions that contrastive and non-contrastive methods, respectively, need large batch sizes and output dimensions. Our theoretical and quantitative results suggest that the numerical gaps between contrastive and noncontrastive methods in certain regimes can be significantly reduced given better network design choice and hyperparameter tuning.