 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMP-SSL: Towards Self-Supervised Learning in One Training Epoch
Apr 08, 2023



Recently, self-supervised learning (SSL) has achieved tremendous success in learning image representation. Despite the empirical success, most self-supervised learning methods are rather "inefficient" learners, typically taking hundreds of training epochs to fully converge. In this work, we show that the key towards efficient self-supervised learning is to increase the number of crops from each image instance. Leveraging one of the state-of-the-art SSL method, we introduce a simplistic form of self-supervised learning method called Extreme-Multi-Patch Self-Supervised-Learning (EMP-SSL) that does not rely on many heuristic techniques for SSL such as weight sharing between the branches, feature-wise normalization, output quantization, and stop gradient, etc, and reduces the training epochs by two orders of magnitude. We show that the proposed method is able to converge to 85.1% on CIFAR-10, 58.5% on CIFAR-100, 38.1% on Tiny ImageNet and 58.5% on ImageNet-100 in just one epoch. Furthermore, the proposed method achieves 91.5% on CIFAR-10, 70.1% on CIFAR-100, 51.5% on Tiny ImageNet and 78.9% on ImageNet-100 with linear probing in less than ten training epochs. In addition, we show that EMP-SSL shows significantly better transferability to out-of-domain datasets compared to baseline SSL methods. We will release the code in https://github.com/tsb0601/EMP-SSL.
Active Self-Supervised Learning: A Few Low-Cost Relationships Are All You Need
Mar 27, 2023



Self-Supervised Learning (SSL) has emerged as the solution of choice to learn transferable representations from unlabeled data. However, SSL requires to build samples that are known to be semantically akin, i.e. positive views. Requiring such knowledge is the main limitation of SSL and is often tackled by ad-hoc strategies e.g. applying known data-augmentations to the same input. In this work, we generalize and formalize this principle through Positive Active Learning (PAL) where an oracle queries semantic relationships between samples. PAL achieves three main objectives. First, it unveils a theoretically grounded learning framework beyond SSL, that can be extended to tackle supervised and semi-supervised learning depending on the employed oracle. Second, it provides a consistent algorithm to embed a priori knowledge, e.g. some observed labels, into any SSL losses without any change in the training pipeline. Third, it provides a proper active learning framework yielding low-cost solutions to annotate datasets, arguably bringing the gap between theory and practice of active learning that is based on simple-to-answer-by-non-experts queries of semantic relationships between inputs.
Self-supervised learning of Split Invariant Equivariant representations
Feb 14, 2023



Recent progress has been made towards learning invariant or equivariant representations with self-supervised learning. While invariant methods are evaluated on large scale datasets, equivariant ones are evaluated in smaller, more controlled, settings. We aim at bridging the gap between the two in order to learn more diverse representations that are suitable for a wide range of tasks. We start by introducing a dataset called 3DIEBench, consisting of renderings from 3D models over 55 classes and more than 2.5 million images where we have full control on the transformations applied to the objects. We further introduce a predictor architecture based on hypernetworks to learn equivariant representations with no possible collapse to invariance. We introduce SIE (Split Invariant-Equivariant) which combines the hypernetwork-based predictor with representations split in two parts, one invariant, the other equivariant, to learn richer representations. We demonstrate significant performance gains over existing methods on equivariance related tasks from both a qualitative and quantitative point of view. We further analyze our introduced predictor and show how it steers the learned latent space. We hope that both our introduced dataset and approach will enable learning richer representations without supervision in more complex scenarios.
RankMe: Assessing the downstream performance of pretrained self-supervised representations by their rank
Oct 05, 2022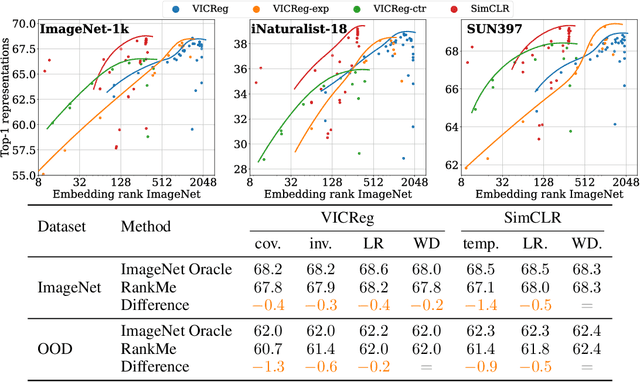
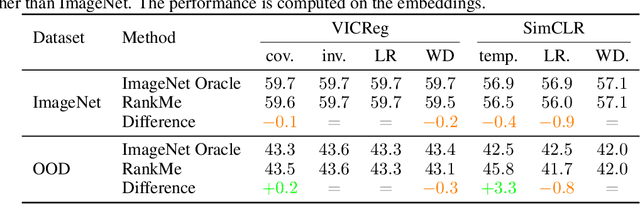
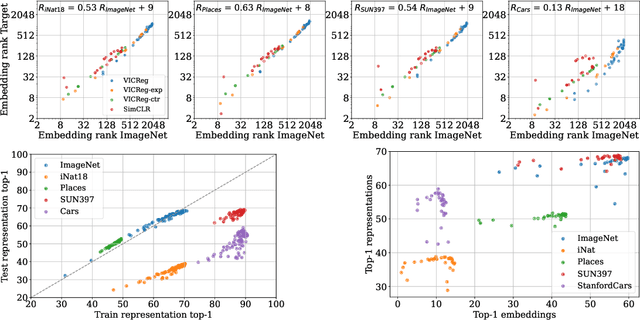
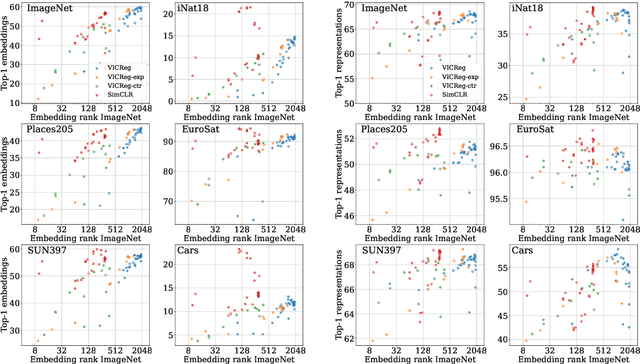
Joint-Embedding Self Supervised Learning (JE-SSL) has seen a rapid development, with the emergence of many method variations and few principled guidelines that would help practitioners to successfully deploy those methods. The main reason for that pitfall actually comes from JE-SSL's core principle of not employing any input reconstruction. Without any visual clue, it becomes extremely cryptic to judge the quality of a learned representation without having access to a labelled dataset. We hope to correct those limitations by providing a single -- theoretically motivated -- criterion that reflects the quality of learned JE-SSL representations: their effective rank. Albeit simple and computationally friendly, this method -- coined RankMe -- allows one to assess the performance of JE-SSL representations, even on different downstream datasets, without requiring any labels, training or parameters to tune. Through thorough empirical experiments involving hundreds of repeated training episodes, we demonstrate how RankMe can be used for hyperparameter selection with nearly no loss in final performance compared to the current selection method that involve dataset labels. We hope that RankMe will facilitate the use of JE-SSL in domains with little or no labeled data.
On the duality between contrastive and non-contrastive self-supervised learning
Jun 03, 2022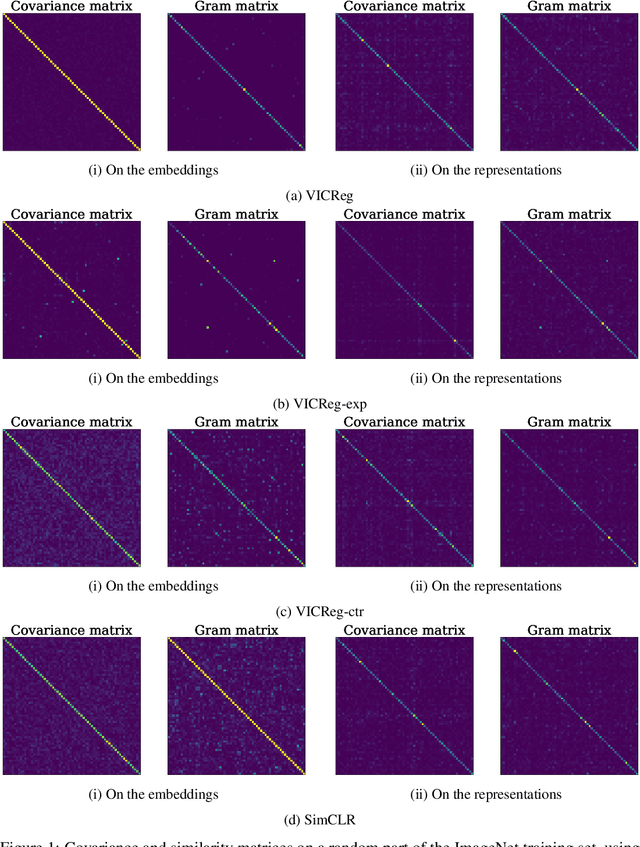
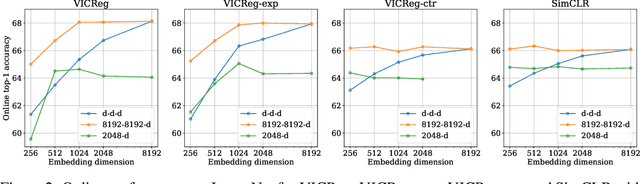

Recent approaches in self-supervised learning of image representations can be categorized into different families of methods and, in particular, can be divided into contrastive and non-contrastive approaches. While differences between the two families have been thoroughly discussed to motivate new approaches, we focus more on the theoretical similarities between them. By designing contrastive and non-contrastive criteria that can be related algebraically and shown to be equivalent under limited assumptions, we show how close those families can be. We further study popular methods and introduce variations of them, allowing us to relate this theoretical result to current practices and show how design choices in the criterion can influence the optimization process and downstream performance. We also challenge the popular assumptions that contrastive and non-contrastive methods, respectively, need large batch sizes and output dimensions. Our theoretical and quantitative results suggest that the numerical gaps between contrastive and noncontrastive methods in certain regimes can be significantly reduced given better network design choice and hyperparameter tuning.
projUNN: efficient method for training deep networks with unitary matrices
Mar 11, 2022
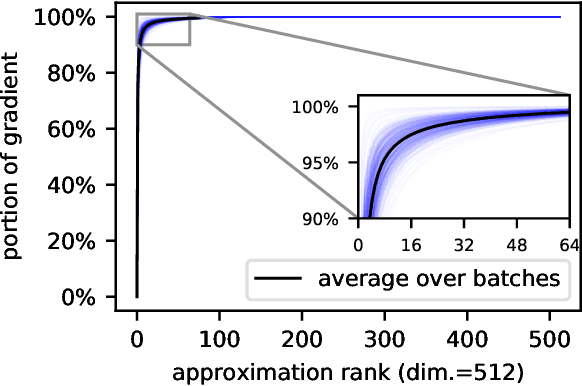
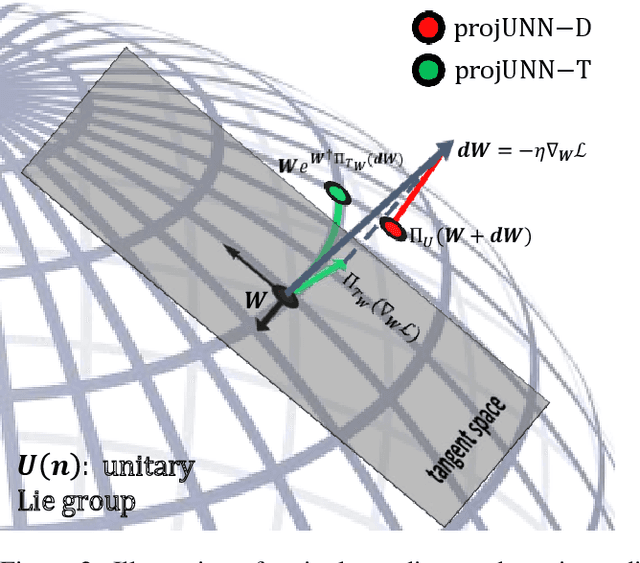

In learning with recurrent or very deep feed-forward networks, employing unitary matrices in each layer can be very effective at maintaining long-range stability. However, restricting network parameters to be unitary typically comes at the cost of expensive parameterizations or increased training runtime. We propose instead an efficient method based on rank-$k$ updates -- or their rank-$k$ approximation -- that maintains performance at a nearly optimal training runtime. We introduce two variants of this method, named Direct (projUNN-D) and Tangent (projUNN-T) projected Unitary Neural Networks, that can parameterize full $N$-dimensional unitary or orthogonal matrices with a training runtime scaling as $O(kN^2)$. Our method either projects low-rank gradients onto the closest unitary matrix (projUNN-T) or transports unitary matrices in the direction of the low-rank gradient (projUNN-D). Even in the fastest setting ($k=1$), projUNN is able to train a model's unitary parameters to reach comparable performances against baseline implementations. By integrating our projUNN algorithm into both recurrent and convolutional neural networks, our models can closely match or exceed benchmarked results from state-of-the-art algorithms.
Very Deep Convolutional Networks for Text Classification
Jan 27, 2017
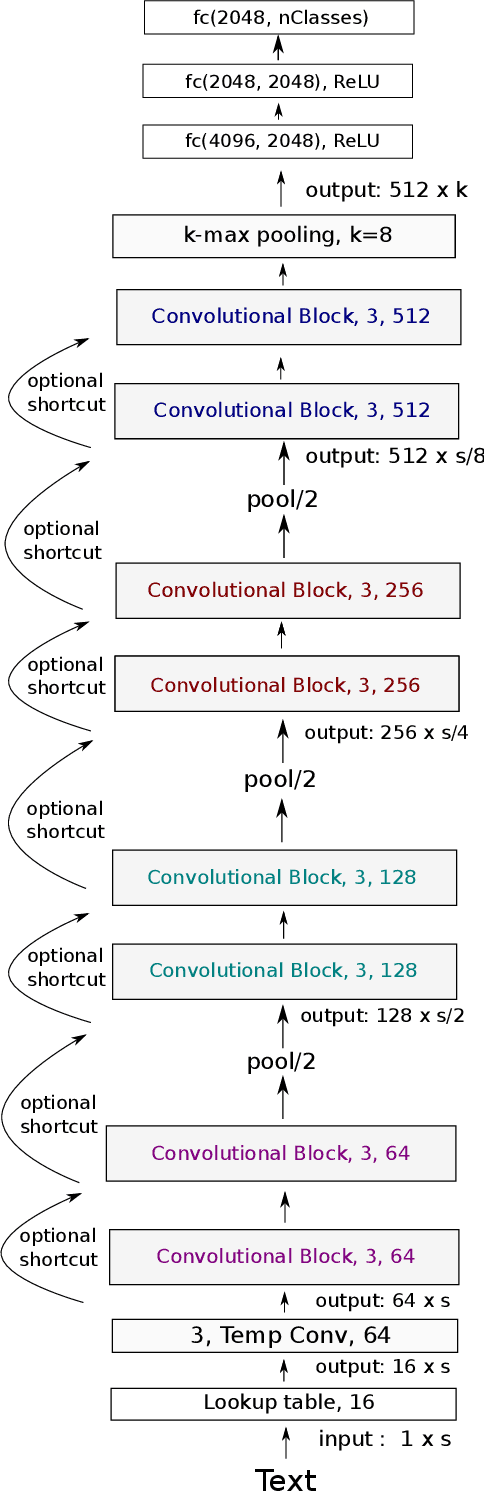
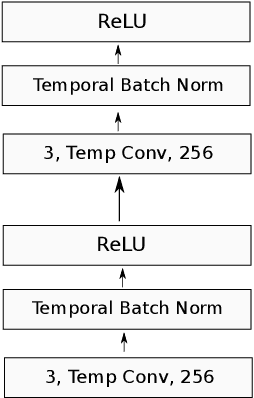

The dominant approach for many NLP tasks are recurrent neural networks, in particular LSTMs, and convolutional neural networks. However, these architectures are rather shallow in comparison to the deep convolutional networks which have pushed the state-of-the-art in computer vision. We present a new architecture (VDCNN) for text processing which operates directly at the character level and uses only small convolutions and pooling operations. We are able to show that the performance of this model increases with depth: using up to 29 convolutional layers, we report improvements over the state-of-the-art on several public text classification tasks. To the best of our knowledge, this is the first time that very deep convolutional nets have been applied to text processing.