 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSG2Caps: Revisiting Scene Graphs for Image Captioning
Paper and Code
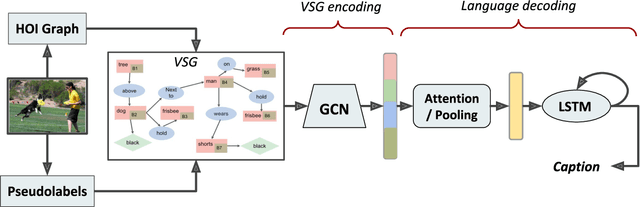
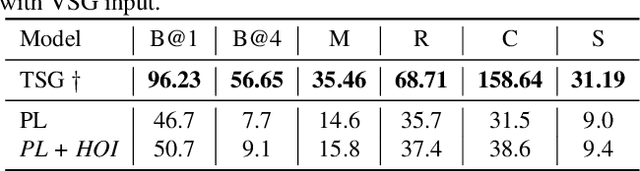
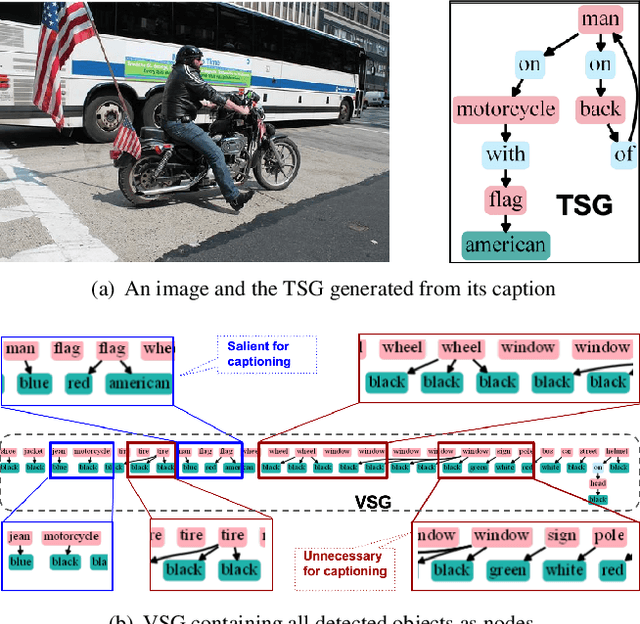
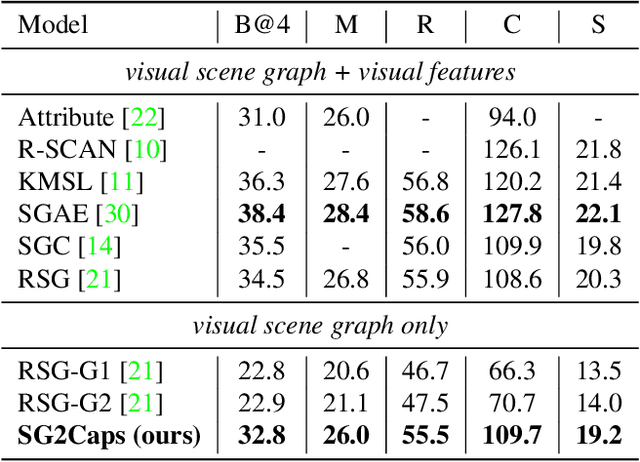
The mainstream image captioning models rely on Convolutional Neural Network (CNN) image features with an additional attention to salient regions and objects to generate captions via recurrent models. Recently, scene graph representations of images have been used to augment captioning models so as to leverage their structural semantics, such as object entities, relationships and attributes. Several studies have noted that naive use of scene graphs from a black-box scene graph generator harms image caption-ing performance, and scene graph-based captioning mod-els have to incur the overhead of explicit use of image features to generate decent captions. Addressing these challenges, we propose a framework, SG2Caps, that utilizes only the scene graph labels for competitive image caption-ing performance. The basic idea is to close the semantic gap between two scene graphs - one derived from the input image and the other one from its caption. In order to achieve this, we leverage the spatial location of objects and the Human-Object-Interaction (HOI) labels as an additional HOI graph. Our framework outperforms existing scene graph-only captioning models by a large margin (CIDEr score of 110 vs 71) indicating scene graphs as a promising representation for image captioning. Direct utilization of the scene graph labels avoids expensive graph convolutions over high-dimensional CNN features resulting in 49%fewer trainable parameters.