 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A robust and lightweight deep attention multiple instance learning algorithm for predicting genetic alterations
May 31, 2022
Deep-learning models based on whole-slide digital pathology images (WSIs) become increasingly popular for predicting molecular biomarkers. Instance-based models has been the mainstream strategy for predicting genetic alterations using WSIs although bag-based models along with self-attention mechanism-based algorithms have been proposed for other digital pathology applications. In this paper, we proposed a novel Attention-based Multiple Instance Mutation Learning (AMIML) model for predicting gene mutations. AMIML was comprised of successive 1-D convolutional layers, a decoder, and a residual weight connection to facilitate further integration of a lightweight attention mechanism to detect the most predictive image patches. Using data for 24 clinically relevant genes from four cancer cohorts in The Cancer Genome Atlas (TCGA) studies (UCEC, BRCA, GBM and KIRC), we compared AMIML with one popular instance-based model and four recently published bag-based models (e.g., CHOWDER, HE2RNA, etc.). AMIML demonstrated excellent robustness, not only outperforming all the five baseline algorithms in the vast majority of the tested genes (17 out of 24), but also providing near-best-performance for the other seven genes. Conversely, the performance of the baseline published algorithms varied across different cancers/genes. In addition, compared to the published models for genetic alterations, AMIML provided a significant improvement for predicting a wide range of genes (e.g., KMT2C, TP53, and SETD2 for KIRC; ERBB2, BRCA1, and BRCA2 for BRCA; JAK1, POLE, and MTOR for UCEC) as well as produced outstanding predictive models for other clinically relevant gene mutations, which have not been reported in the current literature. Furthermore, with the flexible and interpretable attention-based MIL pooling mechanism, AMIML could further zero-in and detect predictive image patches.
Domain Adaptive 3D Pose Augmentation for In-the-wild Human Mesh Recovery
Jun 21, 2022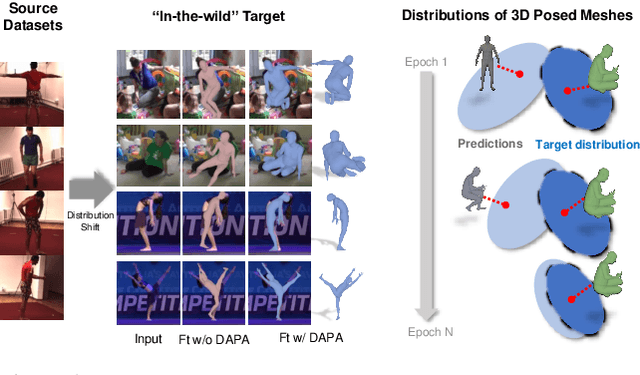
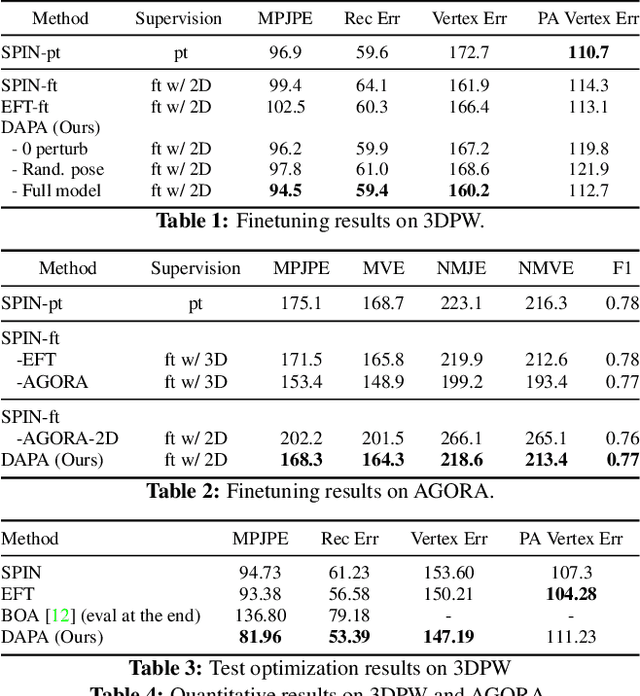
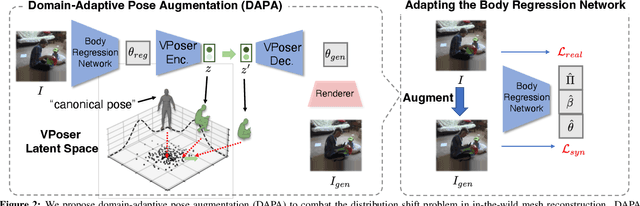

The ability to perceive 3D human bodies from a single image has a multitude of applications ranging from entertainment and robotics to neuroscience and healthcare. A fundamental challenge in human mesh recovery is in collecting the ground truth 3D mesh targets required for training, which requires burdensome motion capturing systems and is often limited to indoor laboratories. As a result, while progress is made on benchmark datasets collected in these restrictive settings, models fail to generalize to real-world ``in-the-wild'' scenarios due to distribution shifts. We propose Domain Adaptive 3D Pose Augmentation (DAPA), a data augmentation method that enhances the model's generalization ability in in-the-wild scenarios. DAPA combines the strength of methods based on synthetic datasets by getting direct supervision from the synthesized meshes, and domain adaptation methods by using ground truth 2D keypoints from the target dataset. We show quantitatively that finetuning with DAPA effectively improves results on benchmarks 3DPW and AGORA. We further demonstrate the utility of DAPA on a challenging dataset curated from videos of real-world parent-child interaction.
Large-Margin Representation Learning for Texture Classification
Jun 17, 2022

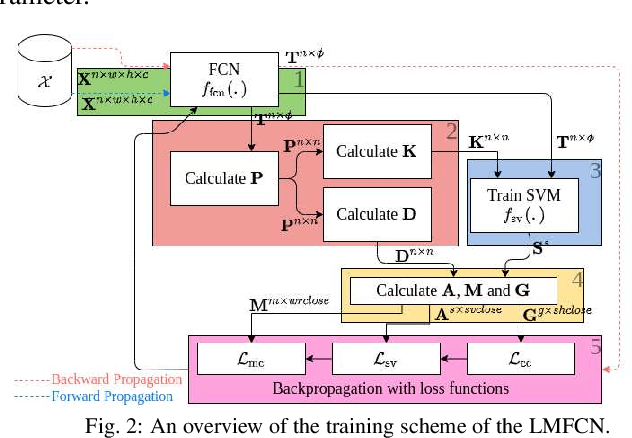
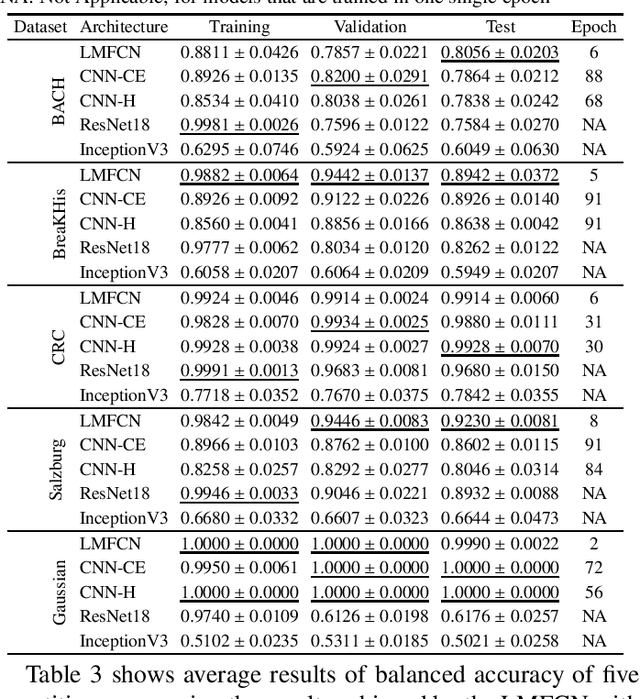
This paper presents a novel approach combining convolutional layers (CLs) and large-margin metric learning for training supervised models on small datasets for texture classification. The core of such an approach is a loss function that computes the distances between instances of interest and support vectors. The objective is to update the weights of CLs iteratively to learn a representation with a large margin between classes. Each iteration results in a large-margin discriminant model represented by support vectors based on such a representation. The advantage of the proposed approach w.r.t. convolutional neural networks (CNNs) is two-fold. First, it allows representation learning with a small amount of data due to the reduced number of parameters compared to an equivalent CNN. Second, it has a low training cost since the backpropagation considers only support vectors. The experimental results on texture and histopathologic image datasets have shown that the proposed approach achieves competitive accuracy with lower computational cost and faster convergence when compared to equivalent CNNs.
Memory Efficient Invertible Neural Networks for 3D Photoacoustic Imaging
Apr 24, 2022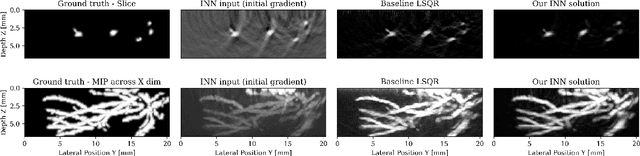
Photoacoustic imaging (PAI) can image high-resolution structures of clinical interest such as vascularity in cancerous tumor monitoring. When imaging human subjects, geometric restrictions force limited-view data retrieval causing imaging artifacts. Iterative physical model based approaches reduce artifacts but require prohibitively time consuming PDE solves. Machine learning (ML) has accelerated PAI by combining physical models and learned networks. However, the depth and overall power of ML methods is limited by memory intensive training. We propose using invertible neural networks (INNs) to alleviate memory pressure. We demonstrate INNs can image 3D photoacoustic volumes in the setting of limited-view, noisy, and subsampled data. The frugal constant memory usage of INNs enables us to train an arbitrary depth of learned layers on a consumer GPU with 16GB RAM.
8-bit Numerical Formats for Deep Neural Networks
Jun 06, 2022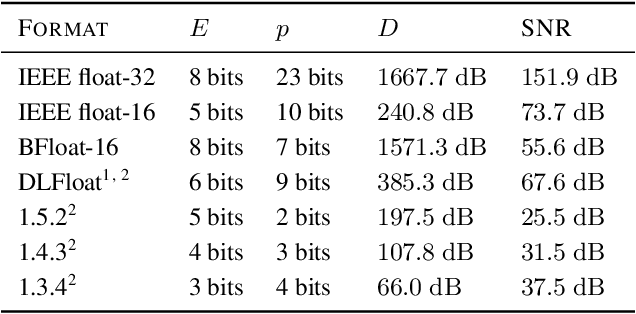
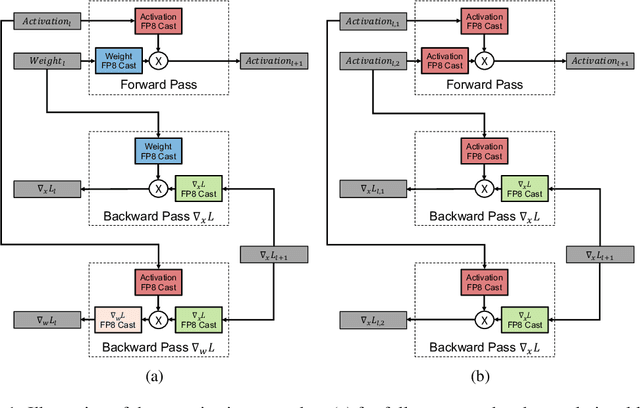
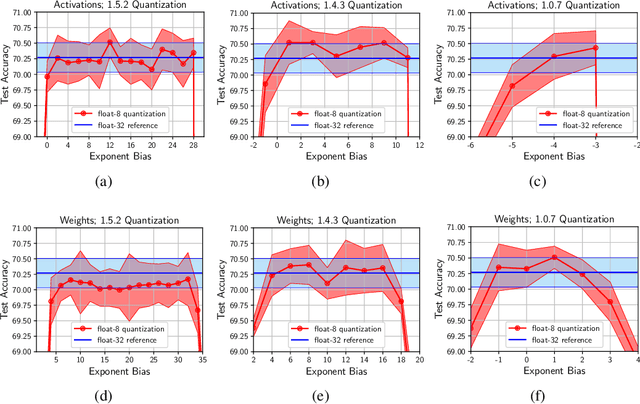
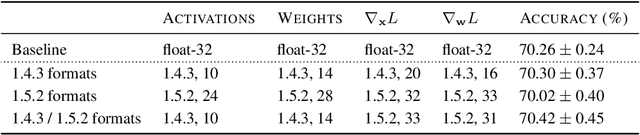
Given the current trend of increasing size and complexity of machine learning architectures, it has become of critical importance to identify new approaches to improve the computational efficiency of model training. In this context, we address the advantages of floating-point over fixed-point representation, and present an in-depth study on the use of 8-bit floating-point number formats for activations, weights, and gradients for both training and inference. We explore the effect of different bit-widths for exponents and significands and different exponent biases. The experimental results demonstrate that a suitable choice of these low-precision formats enables faster training and reduced power consumption without any degradation in accuracy for a range of deep learning models for image classification and language processing.
Image Classification with CondenseNeXt for ARM-Based Computing Platforms
Jun 26, 2021
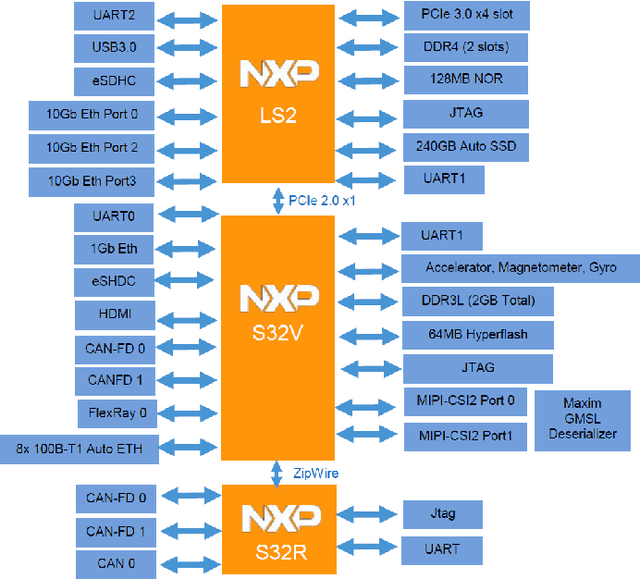
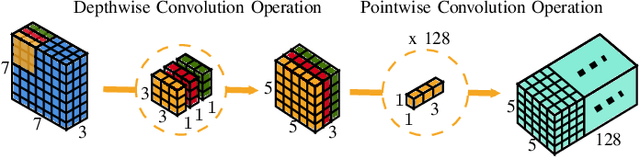
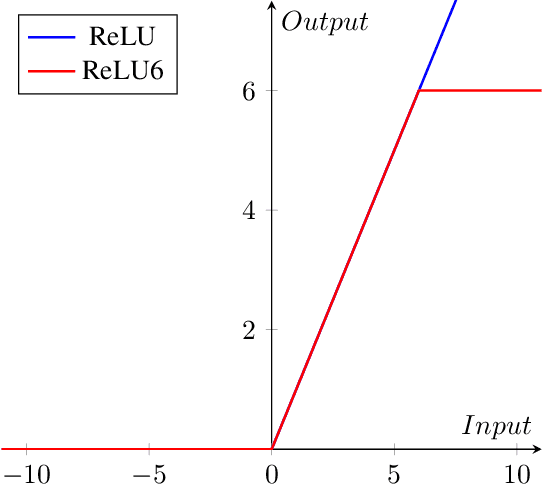
In this paper, we demonstrate the implementation of our ultra-efficient deep convolutional neural network architecture: CondenseNeXt on NXP BlueBox, an autonomous driving development platform developed for self-driving vehicles. We show that CondenseNeXt is remarkably efficient in terms of FLOPs, designed for ARM-based embedded computing platforms with limited computational resources and can perform image classification without the need of a CUDA enabled GPU. CondenseNeXt utilizes the state-of-the-art depthwise separable convolution and model compression techniques to achieve a remarkable computational efficiency. Extensive analyses are conducted on CIFAR-10, CIFAR-100 and ImageNet datasets to verify the performance of CondenseNeXt Convolutional Neural Network (CNN) architecture. It achieves state-of-the-art image classification performance on three benchmark datasets including CIFAR-10 (4.79% top-1 error), CIFAR-100 (21.98% top-1 error) and ImageNet (7.91% single model, single crop top-5 error). CondenseNeXt achieves final trained model size improvement of 2.9+ MB and up to 59.98% reduction in forward FLOPs compared to CondenseNet and can perform image classification on ARM-Based computing platforms without needing a CUDA enabled GPU support, with outstanding efficiency.
Effective Solid State LiDAR Odometry Using Continuous-time Filter Registration
Jun 17, 2022

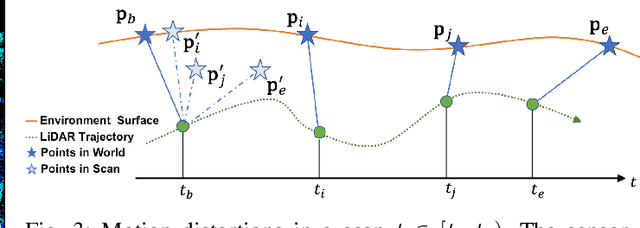
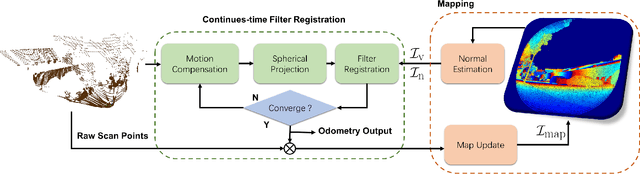
Solid-state LiDARs are more compact and cheaper than the conventional mechanical multi-line spinning LiDARs, which have become increasingly popular in autonomous driving recently. However, there are several challenges for these new LiDAR sensors, including severe motion distortions, small field of view and sparse point cloud, which hinder them from being widely used in LiDAR odometry. To tackle these problems, we present an effective continuous-time LiDAR odometry (ECTLO) method for the Risley prism-based LiDARs with non-repetitive scanning patterns. To account for the noisy data, a filter-based point-to-plane Gaussian Mixture Model is used for robust registration. Moreover, a LiDAR-only continuous-time motion model is employed to relieve the inevitable distortions. To facilitate the implicit data association in parallel, we maintain all map points within a single range image. Extensive experiments have been conducted on various testbeds using the solid-state LiDARs with different scanning patterns, whose promising results demonstrate the efficacy of our proposed approach.
GM-MLIC: Graph Matching based Multi-Label Image Classification
Apr 30, 2021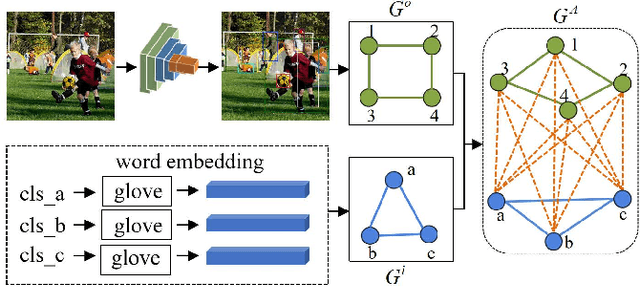
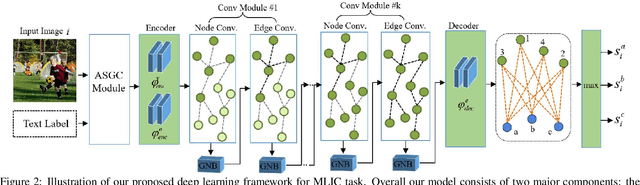
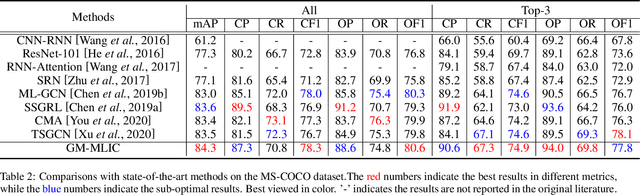
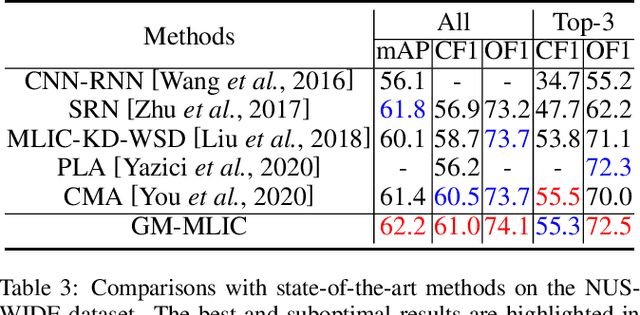
Multi-Label Image Classification (MLIC) aims to predict a set of labels that present in an image. The key to deal with such problem is to mine the associations between image contents and labels, and further obtain the correct assignments between images and their labels. In this paper, we treat each image as a bag of instances, and reformulate the task of MLIC as an instance-label matching selection problem. To model such problem, we propose a novel deep learning framework named Graph Matching based Multi-Label Image Classification (GM-MLIC), where Graph Matching (GM) scheme is introduced owing to its excellent capability of excavating the instance and label relationship. Specifically, we first construct an instance spatial graph and a label semantic graph respectively, and then incorporate them into a constructed assignment graph by connecting each instance to all labels. Subsequently, the graph network block is adopted to aggregate and update all nodes and edges state on the assignment graph to form structured representations for each instance and label. Our network finally derives a prediction score for each instance-label correspondence and optimizes such correspondence with a weighted cross-entropy loss. Extensive experiments conducted on various image datasets demonstrate the superiority of our proposed method.
FundusQ-Net: a Regression Quality Assessment Deep Learning Algorithm for Fundus Images Quality Grading
May 02, 2022
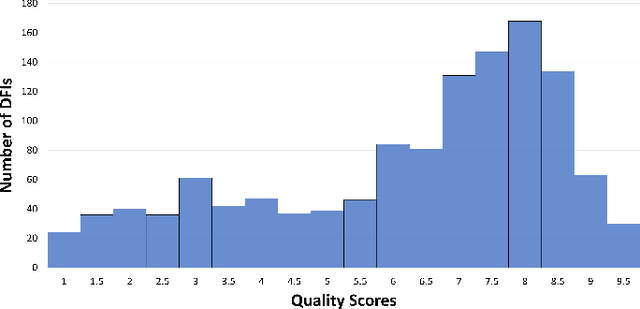
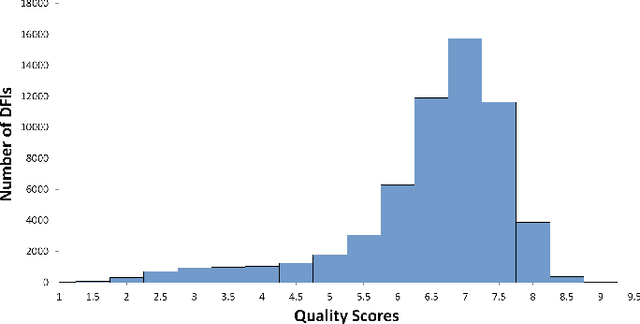
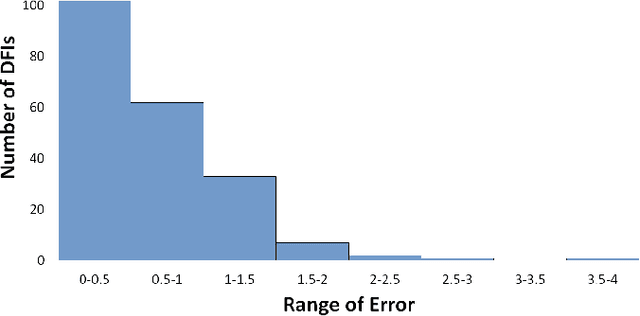
Objective: Ophthalmological pathologies such as glaucoma, diabetic retinopathy and age-related macular degeneration are major causes of blindness and vision impairment. There is a need for novel decision support tools that can simplify and speed up the diagnosis of these pathologies. A key step in this process is to automatically estimate the quality of the fundus images to make sure these are interpretable by a human operator or a machine learning model. We present a novel fundus image quality scale and deep learning (DL) model that can estimate fundus image quality relative to this new scale. Methods: A total of 1,245 images were graded for quality by two ophthalmologists within the range 1-10, with a resolution of 0.5. A DL regression model was trained for fundus image quality assessment. The architecture used was Inception-V3. The model was developed using a total of 89,947 images from 6 databases, of which 1,245 were labeled by the specialists and the remaining 88,702 images were used for pre-training and semi-supervised learning. The final DL model was evaluated on an internal test set (n=209) as well as an external test set (n=194). Results: The final DL model, denoted FundusQ-Net, achieved a mean absolute error of 0.61 (0.54-0.68) on the internal test set. When evaluated as a binary classification model on the public DRIMDB database as an external test set the model obtained an accuracy of 99%. Significance: the proposed algorithm provides a new robust tool for automated quality grading of fundus images.
CLIP-Art: Contrastive Pre-training for Fine-Grained Art Classification
Apr 29, 2022
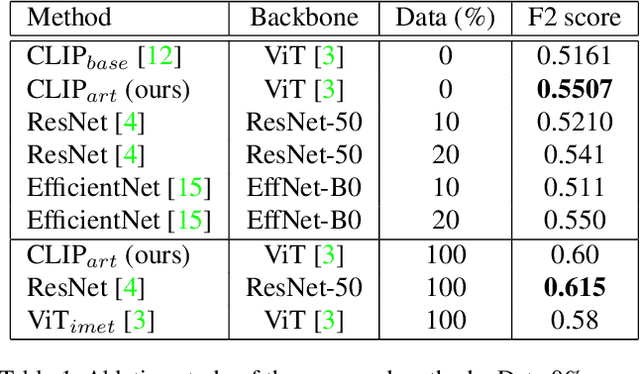

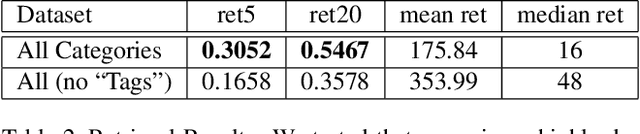
Existing computer vision research in artwork struggles with artwork's fine-grained attributes recognition and lack of curated annotated datasets due to their costly creation. To the best of our knowledge, we are one of the first methods to use CLIP (Contrastive Language-Image Pre-Training) to train a neural network on a variety of artwork images and text descriptions pairs. CLIP is able to learn directly from free-form art descriptions, or, if available, curated fine-grained labels. Model's zero-shot capability allows predicting accurate natural language description for a given image, without directly optimizing for the task. Our approach aims to solve 2 challenges: instance retrieval and fine-grained artwork attribute recognition. We use the iMet Dataset, which we consider the largest annotated artwork dataset. In this benchmark we achieved competitive results using only self-supervision.
* CVPR CVFAD Workshop 2021