 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning Dual-Pixel Alignment for Defocus Deblurring
Apr 26, 2022




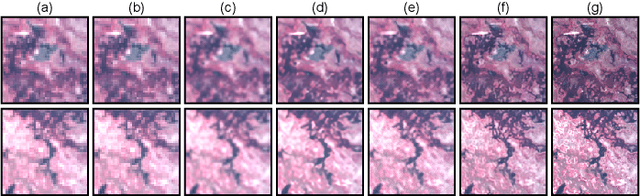
It is a challenging task to recover all-in-focus image from a single defocus blurry image in real-world applications. On many modern cameras, dual-pixel (DP) sensors create two-image views, based on which stereo information can be exploited to benefit defocus deblurring. Despite existing DP defocus deblurring methods achieving impressive results, they directly take naive concatenation of DP views as input, while neglecting the disparity between left and right views in the regions out of camera's depth of field (DoF). In this work, we propose a Dual-Pixel Alignment Network (DPANet) for defocus deblurring. Generally, DPANet is an encoder-decoder with skip-connections, where two branches with shared parameters in the encoder are employed to extract and align deep features from left and right views, and one decoder is adopted to fuse aligned features for predicting the all-in-focus image. Due to that DP views suffer from different blur amounts, it is not trivial to align left and right views. To this end, we propose novel encoder alignment module (EAM) and decoder alignment module (DAM). In particular, a correlation layer is suggested in EAM to measure the disparity between DP views, whose deep features can then be accordingly aligned using deformable convolutions. And DAM can further enhance the alignment of skip-connected features from encoder and deep features in decoder. By introducing several EAMs and DAMs, DP views in DPANet can be well aligned for better predicting latent all-in-focus image. Experimental results on real-world datasets show that our DPANet is notably superior to state-of-the-art deblurring methods in reducing defocus blur while recovering visually plausible sharp structures and textures.
Contextualized Keyword Representations for Multi-modal Retinal Image Captioning
Apr 26, 2021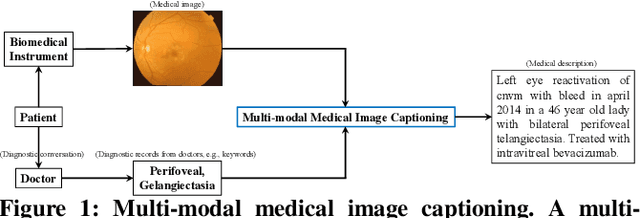

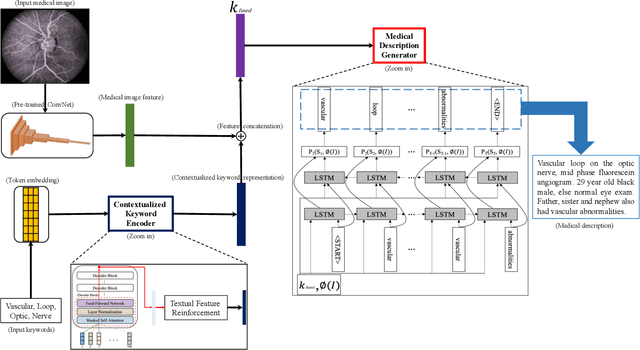
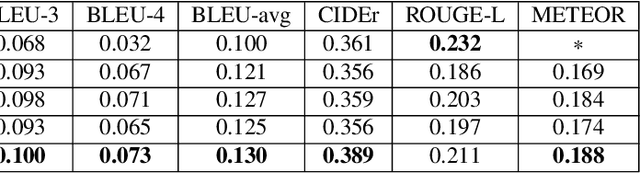
Medical image captioning automatically generates a medical description to describe the content of a given medical image. A traditional medical image captioning model creates a medical description only based on a single medical image input. Hence, an abstract medical description or concept is hard to be generated based on the traditional approach. Such a method limits the effectiveness of medical image captioning. Multi-modal medical image captioning is one of the approaches utilized to address this problem. In multi-modal medical image captioning, textual input, e.g., expert-defined keywords, is considered as one of the main drivers of medical description generation. Thus, encoding the textual input and the medical image effectively are both important for the task of multi-modal medical image captioning. In this work, a new end-to-end deep multi-modal medical image captioning model is proposed. Contextualized keyword representations, textual feature reinforcement, and masked self-attention are used to develop the proposed approach. Based on the evaluation of the existing multi-modal medical image captioning dataset, experimental results show that the proposed model is effective with the increase of +53.2% in BLEU-avg and +18.6% in CIDEr, compared with the state-of-the-art method.
Hyperspectral Pansharpening Based on Improved Deep Image Prior and Residual Reconstruction
Jul 06, 2021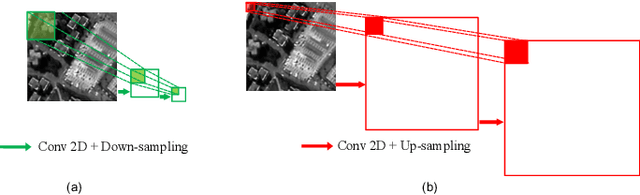


Hyperspectral pansharpening aims to synthesize a low-resolution hyperspectral image (LR-HSI) with a registered panchromatic image (PAN) to generate an enhanced HSI with high spectral and spatial resolution. Recently proposed HS pansharpening methods have obtained remarkable results using deep convolutional networks (ConvNets), which typically consist of three steps: (1) up-sampling the LR-HSI, (2) predicting the residual image via a ConvNet, and (3) obtaining the final fused HSI by adding the outputs from first and second steps. Recent methods have leveraged Deep Image Prior (DIP) to up-sample the LR-HSI due to its excellent ability to preserve both spatial and spectral information, without learning from large data sets. However, we observed that the quality of up-sampled HSIs can be further improved by introducing an additional spatial-domain constraint to the conventional spectral-domain energy function. We define our spatial-domain constraint as the $L_1$ distance between the predicted PAN image and the actual PAN image. To estimate the PAN image of the up-sampled HSI, we also propose a learnable spectral response function (SRF). Moreover, we noticed that the residual image between the up-sampled HSI and the reference HSI mainly consists of edge information and very fine structures. In order to accurately estimate fine information, we propose a novel over-complete network, called HyperKite, which focuses on learning high-level features by constraining the receptive from increasing in the deep layers. We perform experiments on three HSI datasets to demonstrate the superiority of our DIP-HyperKite over the state-of-the-art pansharpening methods. The deployment codes, pre-trained models, and final fusion outputs of our DIP-HyperKite and the methods used for the comparisons will be publicly made available at https://github.com/wgcban/DIP-HyperKite.git.
Simultaneous Multiple-Prompt Guided Generation Using Differentiable Optimal Transport
Apr 18, 2022


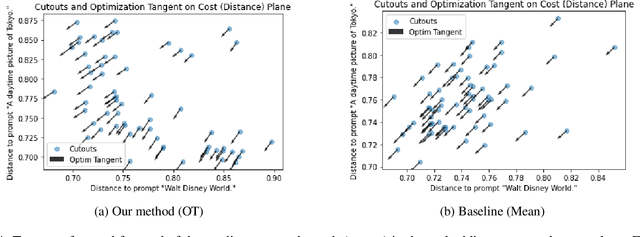
Recent advances in deep learning, such as powerful generative models and joint text-image embeddings, have provided the computational creativity community with new tools, opening new perspectives for artistic pursuits. Text-to-image synthesis approaches that operate by generating images from text cues provide a case in point. These images are generated with a latent vector that is progressively refined to agree with text cues. To do so, patches are sampled within the generated image, and compared with the text prompts in the common text-image embedding space; The latent vector is then updated, using gradient descent, to reduce the mean (average) distance between these patches and text cues. While this approach provides artists with ample freedom to customize the overall appearance of images, through their choice in generative models, the reliance on a simple criterion (mean of distances) often causes mode collapse: The entire image is drawn to the average of all text cues, thereby losing their diversity. To address this issue, we propose using matching techniques found in the optimal transport (OT) literature, resulting in images that are able to reflect faithfully a wide diversity of prompts. We provide numerous illustrations showing that OT avoids some of the pitfalls arising from estimating vectors with mean distances, and demonstrate the capacity of our proposed method to perform better in experiments, qualitatively and quantitatively.
Ray-Space Motion Compensation for Lenslet Plenoptic Video Coding
Jul 01, 2022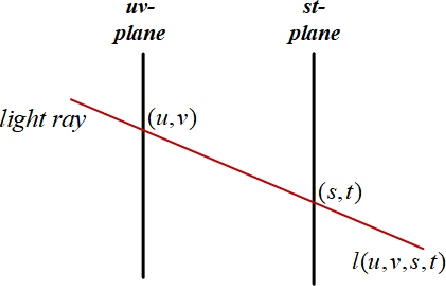
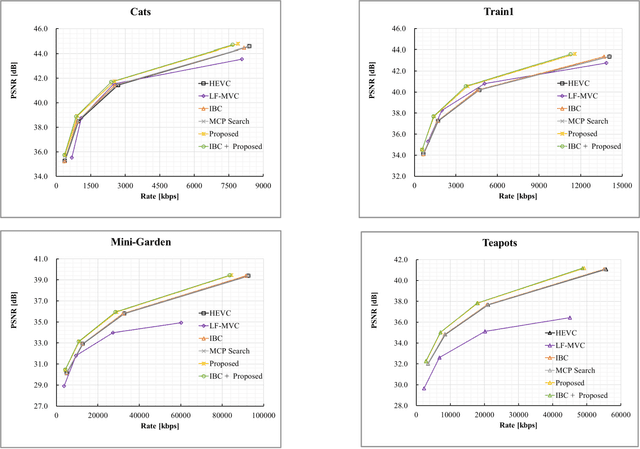
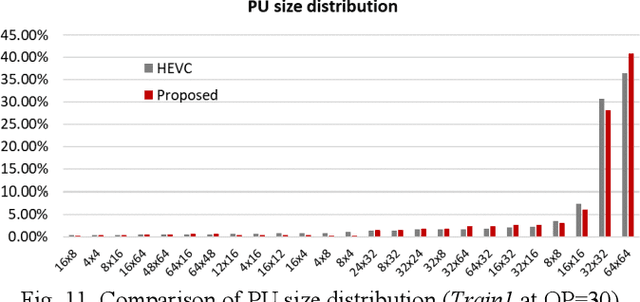
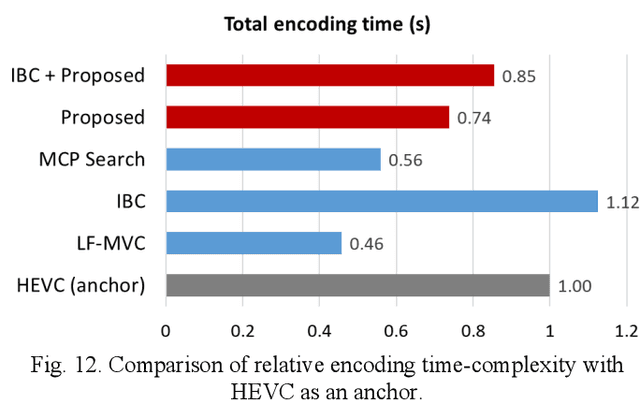
Plenoptic images and videos bearing rich information demand a tremendous amount of data storage and high transmission cost. While there has been much study on plenoptic image coding, investigations into plenoptic video coding have been very limited. We investigate the motion compensation for plenoptic video coding from a slightly different perspective by looking at the problem in the ray-space domain instead of in the conventional pixel domain. Here, we develop a novel motion compensation scheme for lenslet video under two sub-cases of ray-space motion, that is, integer ray-space motion and fractional ray-space motion. The proposed new scheme of light field motion-compensated prediction is designed such that it can be easily integrated into well-known video coding techniques such as HEVC. Experimental results compared to relevant existing methods have shown remarkable compression efficiency with an average gain of 19.63% and a peak gain of 29.1%.
The State of the Art when using GPUs in Devising Image Generation Methods Using Deep Learning
Sep 13, 2021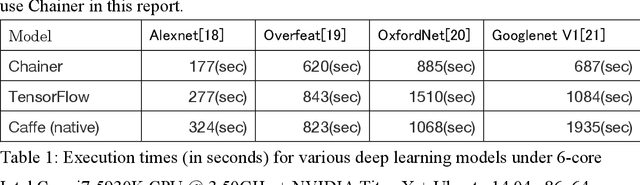
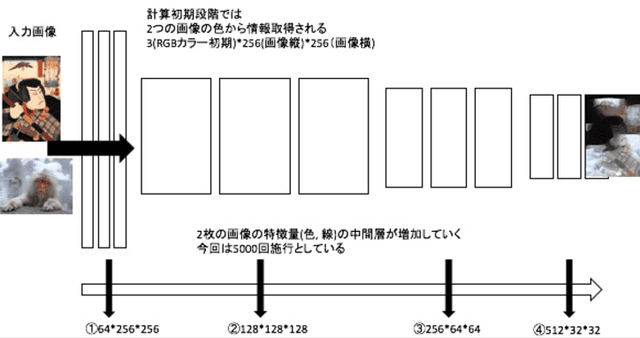


Deep learning is a technique for machine learning using multi-layer neural networks. It has been used for image synthesis and image recognition, but in recent years, it has also been used for various social detection and social labeling. In this analysis, we compared (1) the number of Iterations per minute between the GPU and CPU when using the VGG model and the NIN model, and (2) the number of Iterations per minute by the number of pixels when using the VGG model, using an image with 128 pixels. When the number of pixels was 64 or 128, the processing time was almost the same when using the GPU, but when the number of pixels was changed to 256, the number of iterations per minute decreased and the processing time increased by about three times. In this case study, since the number of pixels becomes core dumping when the number of pixels is 512 or more, we can consider that we should consider improvement in the vector calculation part. If we aim to achieve 8K highly saturated computer graphics using neural networks, we will need to consider an environment that allows computation even when the size of the image becomes even more highly saturated and massive, and parallel computation when performing image recognition and tuning.
* 13 pages
Let there be a clock on the beach: Reducing Object Hallucination in Image Captioning
Oct 04, 2021
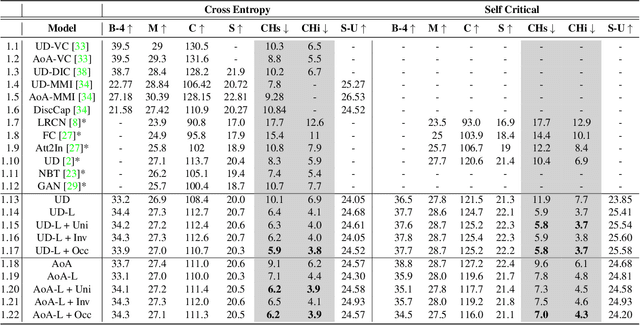
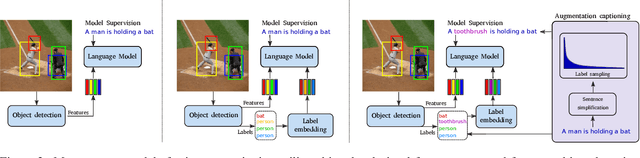

Explaining an image with missing or non-existent objects is known as object bias (hallucination) in image captioning. This behaviour is quite common in the state-of-the-art captioning models which is not desirable by humans. To decrease the object hallucination in captioning, we propose three simple yet efficient training augmentation method for sentences which requires no new training data or increase in the model size. By extensive analysis, we show that the proposed methods can significantly diminish our models' object bias on hallucination metrics. Moreover, we experimentally demonstrate that our methods decrease the dependency on the visual features. All of our code, configuration files and model weights will be made public.
Two Souls in an Adversarial Image: Towards Universal Adversarial Example Detection using Multi-view Inconsistency
Sep 25, 2021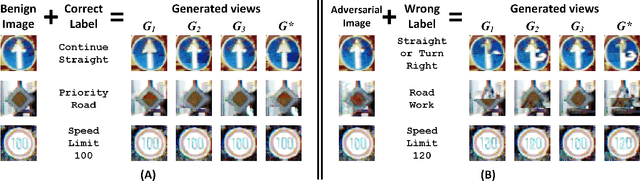
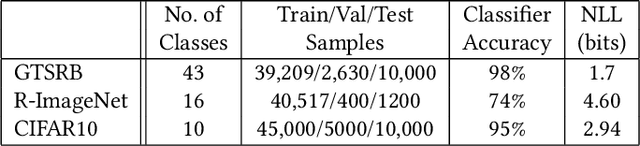
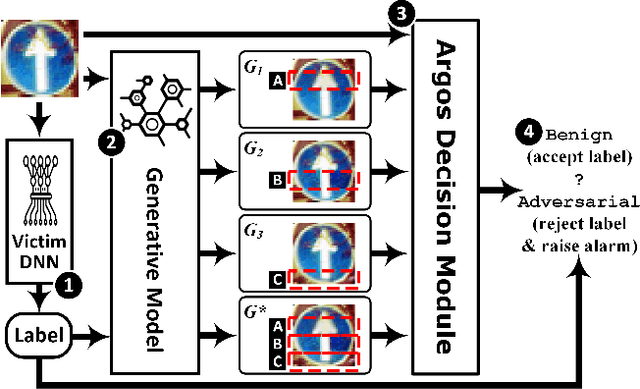
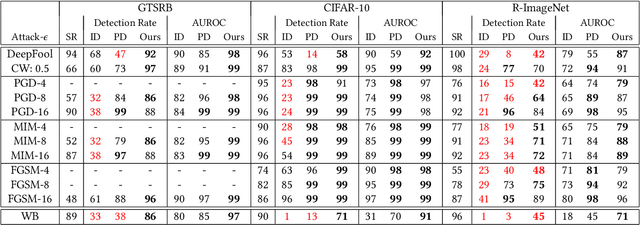
In the evasion attacks against deep neural networks (DNN), the attacker generates adversarial instances that are visually indistinguishable from benign samples and sends them to the target DNN to trigger misclassifications. In this paper, we propose a novel multi-view adversarial image detector, namely Argos, based on a novel observation. That is, there exist two "souls" in an adversarial instance, i.e., the visually unchanged content, which corresponds to the true label, and the added invisible perturbation, which corresponds to the misclassified label. Such inconsistencies could be further amplified through an autoregressive generative approach that generates images with seed pixels selected from the original image, a selected label, and pixel distributions learned from the training data. The generated images (i.e., the "views") will deviate significantly from the original one if the label is adversarial, demonstrating inconsistencies that Argos expects to detect. To this end, Argos first amplifies the discrepancies between the visual content of an image and its misclassified label induced by the attack using a set of regeneration mechanisms and then identifies an image as adversarial if the reproduced views deviate to a preset degree. Our experimental results show that Argos significantly outperforms two representative adversarial detectors in both detection accuracy and robustness against six well-known adversarial attacks. Code is available at: https://github.com/sohaib730/Argos-Adversarial_Detection
Exploring the solution space of linear inverse problems with GAN latent geometry
Jul 01, 2022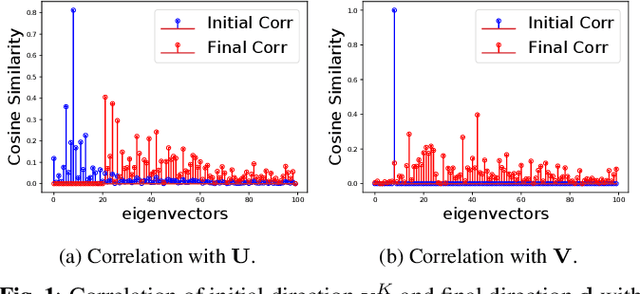



Inverse problems consist in reconstructing signals from incomplete sets of measurements and their performance is highly dependent on the quality of the prior knowledge encoded via regularization. While traditional approaches focus on obtaining a unique solution, an emerging trend considers exploring multiple feasibile solutions. In this paper, we propose a method to generate multiple reconstructions that fit both the measurements and a data-driven prior learned by a generative adversarial network. In particular, we show that, starting from an initial solution, it is possible to find directions in the latent space of the generative model that are null to the forward operator, and thus keep consistency with the measurements, while inducing significant perceptual change. Our exploration approach allows to generate multiple solutions to the inverse problem an order of magnitude faster than existing approaches; we show results on image super-resolution and inpainting problems.
Learning Weighting Map for Bit-Depth Expansion within a Rational Range
Apr 26, 2022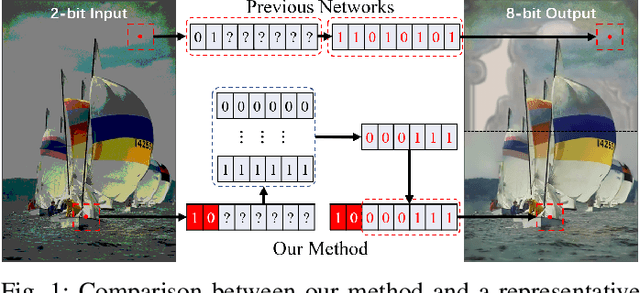


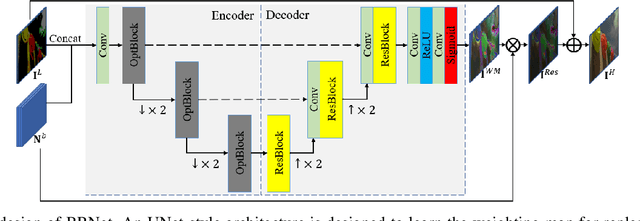
Bit-depth expansion (BDE) is one of the emerging technologies to display high bit-depth (HBD) image from low bit-depth (LBD) source. Existing BDE methods have no unified solution for various BDE situations, and directly learn a mapping for each pixel from LBD image to the desired value in HBD image, which may change the given high-order bits and lead to a huge deviation from the ground truth. In this paper, we design a bit restoration network (BRNet) to learn a weight for each pixel, which indicates the ratio of the replenished value within a rational range, invoking an accurate solution without modifying the given high-order bit information. To make the network adaptive for any bit-depth degradation, we investigate the issue in an optimization perspective and train the network under progressive training strategy for better performance. Moreover, we employ Wasserstein distance as a visual quality indicator to evaluate the difference of color distribution between restored image and the ground truth. Experimental results show our method can restore colorful images with fewer artifacts and false contours, and outperforms state-of-the-art methods with higher PSNR/SSIM results and lower Wasserstein distance. The source code will be made available at https://github.com/yuqing-liu-dut/bit-depth-expansion