 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Data Augmentation Pipeline to Generate Synthetic Labeled Datasets of 3D Echocardiography Images using a GAN
Mar 08, 2024
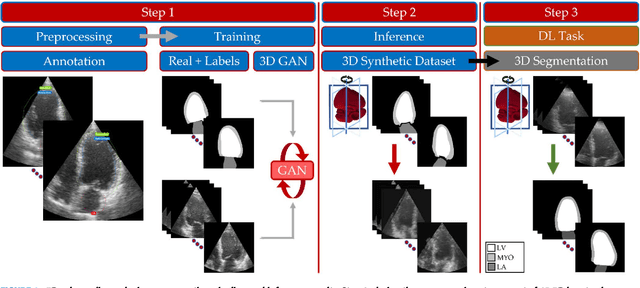
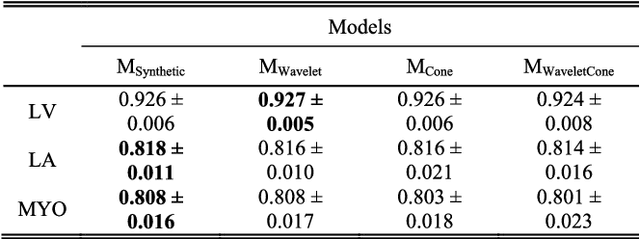
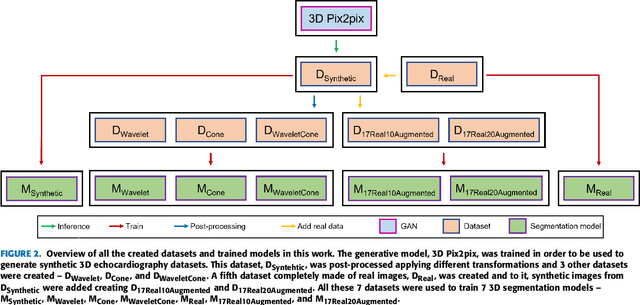
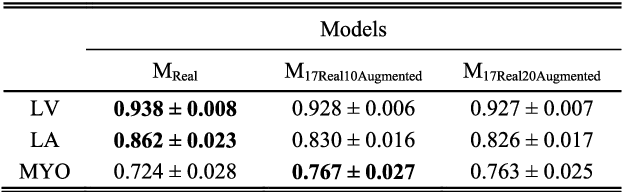
Due to privacy issues and limited amount of publicly available labeled datasets in the domain of medical imaging, we propose an image generation pipeline to synthesize 3D echocardiographic images with corresponding ground truth labels, to alleviate the need for data collection and for laborious and error-prone human labeling of images for subsequent Deep Learning (DL) tasks. The proposed method utilizes detailed anatomical segmentations of the heart as ground truth label sources. This initial dataset is combined with a second dataset made up of real 3D echocardiographic images to train a Generative Adversarial Network (GAN) to synthesize realistic 3D cardiovascular Ultrasound images paired with ground truth labels. To generate the synthetic 3D dataset, the trained GAN uses high resolution anatomical models from Computed Tomography (CT) as input. A qualitative analysis of the synthesized images showed that the main structures of the heart are well delineated and closely follow the labels obtained from the anatomical models. To assess the usability of these synthetic images for DL tasks, segmentation algorithms were trained to delineate the left ventricle, left atrium, and myocardium. A quantitative analysis of the 3D segmentations given by the models trained with the synthetic images indicated the potential use of this GAN approach to generate 3D synthetic data, use the data to train DL models for different clinical tasks, and therefore tackle the problem of scarcity of 3D labeled echocardiography datasets.
Contrastive Region Guidance: Improving Grounding in Vision-Language Models without Training
Mar 04, 2024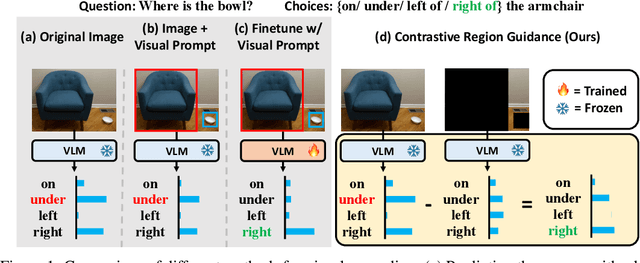
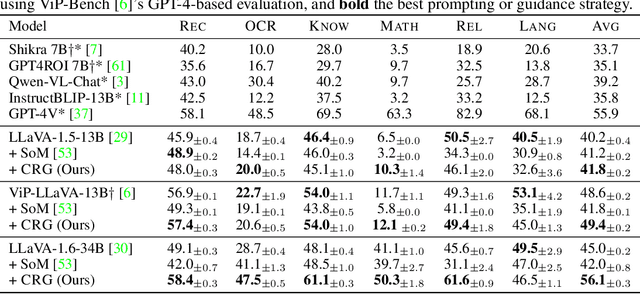
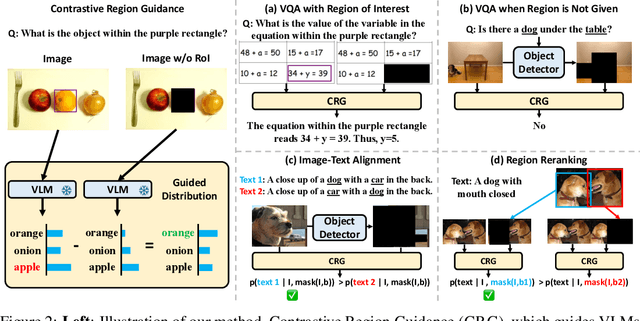
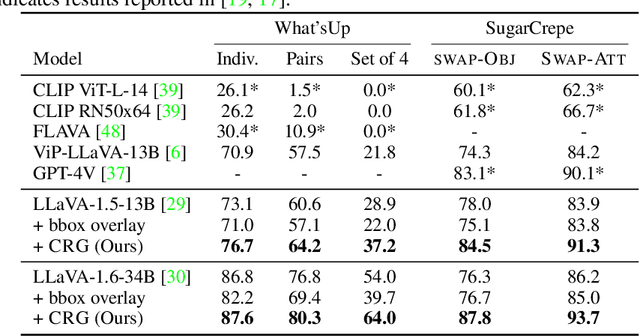
Highlighting particularly relevant regions of an image can improve the performance of vision-language models (VLMs) on various vision-language (VL) tasks by guiding the model to attend more closely to these regions of interest. For example, VLMs can be given a "visual prompt", where visual markers such as bounding boxes delineate key image regions. However, current VLMs that can incorporate visual guidance are either proprietary and expensive or require costly training on curated data that includes visual prompts. We introduce Contrastive Region Guidance (CRG), a training-free guidance method that enables open-source VLMs to respond to visual prompts. CRG contrasts model outputs produced with and without visual prompts, factoring out biases revealed by the model when answering without the information required to produce a correct answer (i.e., the model's prior). CRG achieves substantial improvements in a wide variety of VL tasks: When region annotations are provided, CRG increases absolute accuracy by up to 11.1% on ViP-Bench, a collection of six diverse region-based tasks such as recognition, math, and object relationship reasoning. We also show CRG's applicability to spatial reasoning, with 10% improvement on What'sUp, as well as to compositional generalization -- improving accuracy by 11.5% and 7.5% on two challenging splits from SugarCrepe -- and to image-text alignment for generated images, where we improve by up to 8.4 AUROC and 6.8 F1 points on SeeTRUE. When reference regions are absent, CRG allows us to re-rank proposed regions in referring expression comprehension and phrase grounding benchmarks like RefCOCO/+/g and Flickr30K Entities, with an average gain of 3.2% in accuracy. Our analysis explores alternative masking strategies for CRG, quantifies CRG's probability shift, and evaluates the role of region guidance strength, empirically validating CRG's design choices.
Hyperspectral Image Analysis in Single-Modal and Multimodal setting using Deep Learning Techniques
Mar 03, 2024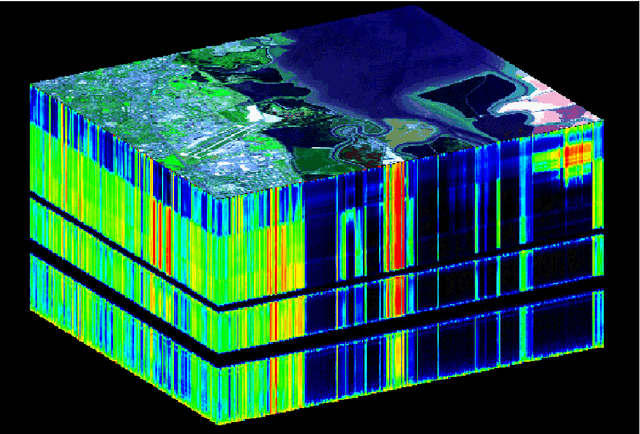

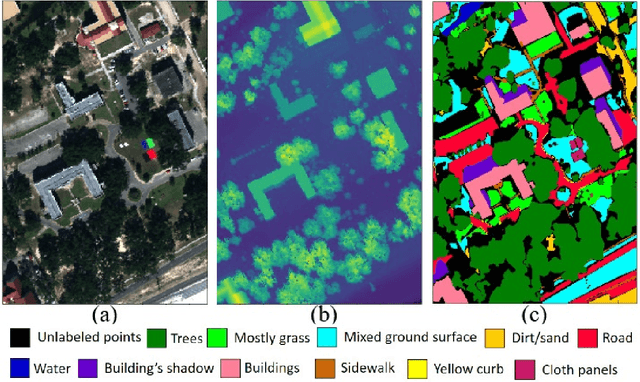
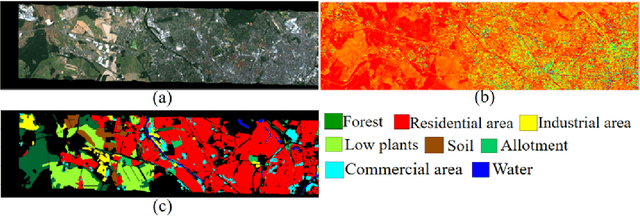
Hyperspectral imaging provides precise classification for land use and cover due to its exceptional spectral resolution. However, the challenges of high dimensionality and limited spatial resolution hinder its effectiveness. This study addresses these challenges by employing deep learning techniques to efficiently process, extract features, and classify data in an integrated manner. To enhance spatial resolution, we integrate information from complementary modalities such as LiDAR and SAR data through multimodal learning. Moreover, adversarial learning and knowledge distillation are utilized to overcome issues stemming from domain disparities and missing modalities. We also tailor deep learning architectures to suit the unique characteristics of HSI data, utilizing 1D convolutional and recurrent neural networks to handle its continuous spectral dimension. Techniques like visual attention and feedback connections within the architecture bolster the robustness of feature extraction. Additionally, we tackle the issue of limited training samples through self-supervised learning methods, employing autoencoders for dimensionality reduction and exploring semi-supervised learning techniques that leverage unlabeled data. Our proposed approaches are evaluated across various HSI datasets, consistently outperforming existing state-of-the-art techniques.
Structure-Guided Adversarial Training of Diffusion Models
Mar 04, 2024Diffusion models have demonstrated exceptional efficacy in various generative applications. While existing models focus on minimizing a weighted sum of denoising score matching losses for data distribution modeling, their training primarily emphasizes instance-level optimization, overlooking valuable structural information within each mini-batch, indicative of pair-wise relationships among samples. To address this limitation, we introduce Structure-guided Adversarial training of Diffusion Models (SADM). In this pioneering approach, we compel the model to learn manifold structures between samples in each training batch. To ensure the model captures authentic manifold structures in the data distribution, we advocate adversarial training of the diffusion generator against a novel structure discriminator in a minimax game, distinguishing real manifold structures from the generated ones. SADM substantially improves existing diffusion transformers (DiT) and outperforms existing methods in image generation and cross-domain fine-tuning tasks across 12 datasets, establishing a new state-of-the-art FID of 1.58 and 2.11 on ImageNet for class-conditional image generation at resolutions of 256x256 and 512x512, respectively.
FreeA: Human-object Interaction Detection using Free Annotation Labels
Mar 04, 2024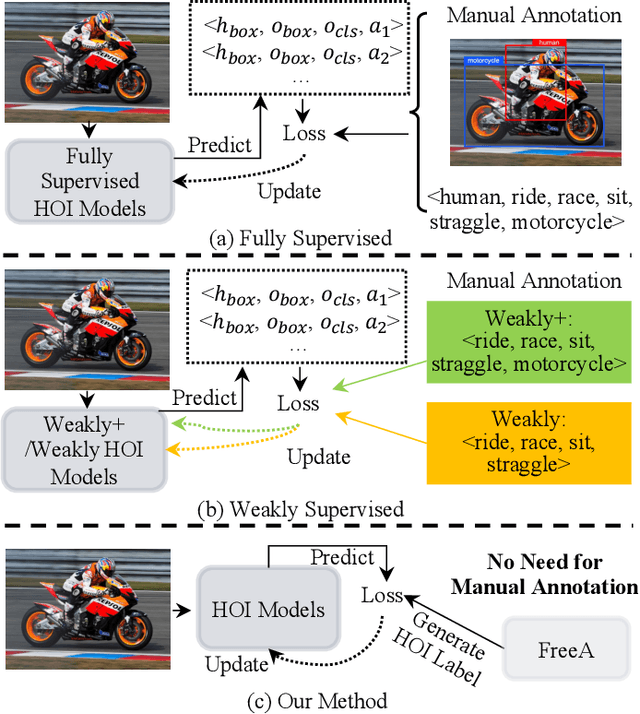
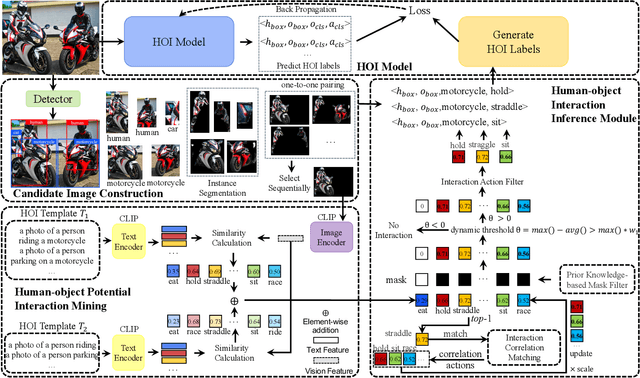
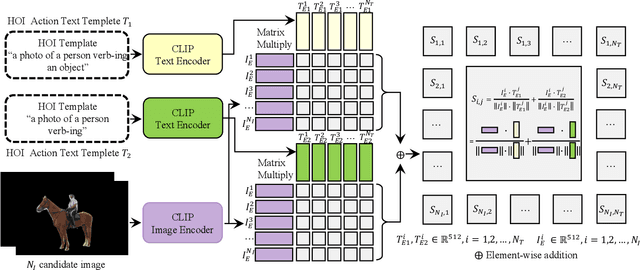
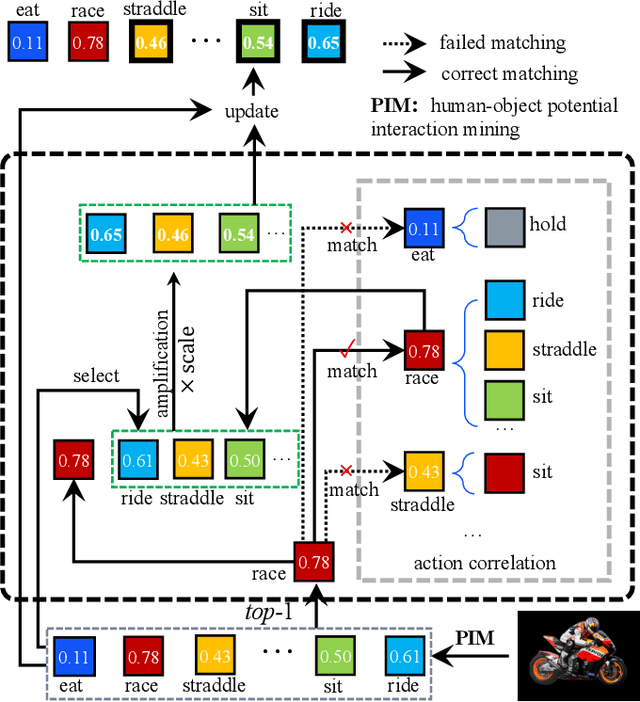
Recent human-object interaction (HOI) detection approaches rely on high cost of manpower and require comprehensive annotated image datasets. In this paper, we propose a novel self-adaption language-driven HOI detection method, termed as FreeA, without labeling by leveraging the adaptability of CLIP to generate latent HOI labels. To be specific, FreeA matches image features of human-object pairs with HOI text templates, and a priori knowledge-based mask method is developed to suppress improbable interactions. In addition, FreeA utilizes the proposed interaction correlation matching method to enhance the likelihood of actions related to a specified action, further refine the generated HOI labels. Experiments on two benchmark datasets show that FreeA achieves state-of-the-art performance among weakly supervised HOI models. Our approach is +8.58 mean Average Precision (mAP) on HICO-DET and +1.23 mAP on V-COCO more accurate in localizing and classifying the interactive actions than the newest weakly model, and +1.68 mAP and +7.28 mAP than the latest weakly+ model, respectively. Code will be available at https://drliuqi.github.io/.
Multi-modal Deep Learning
Mar 06, 2024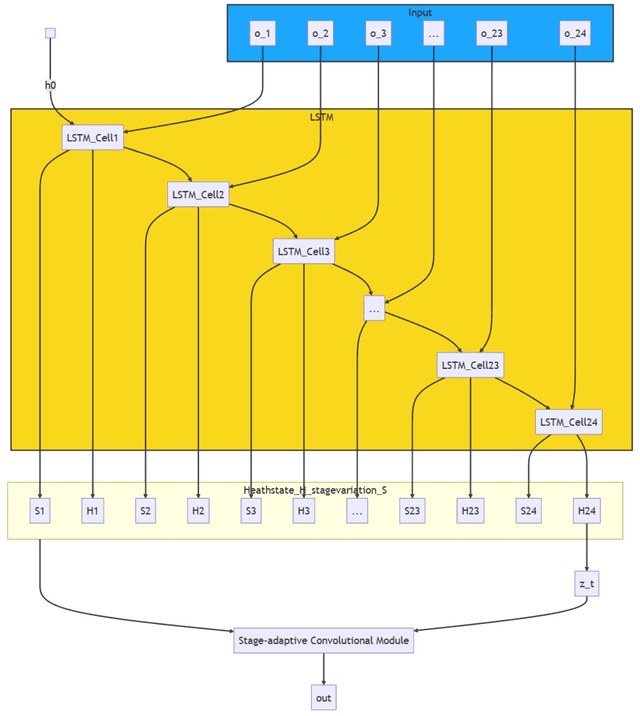
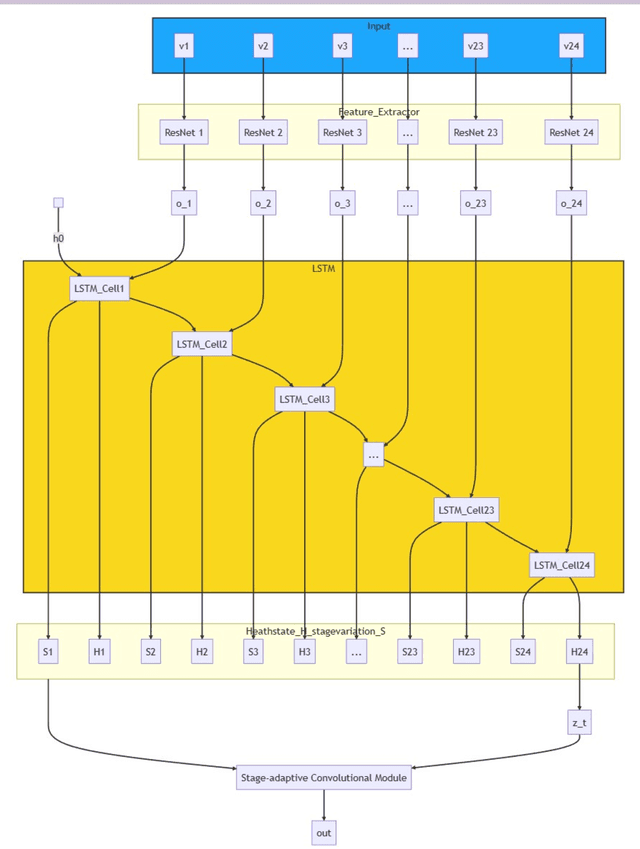
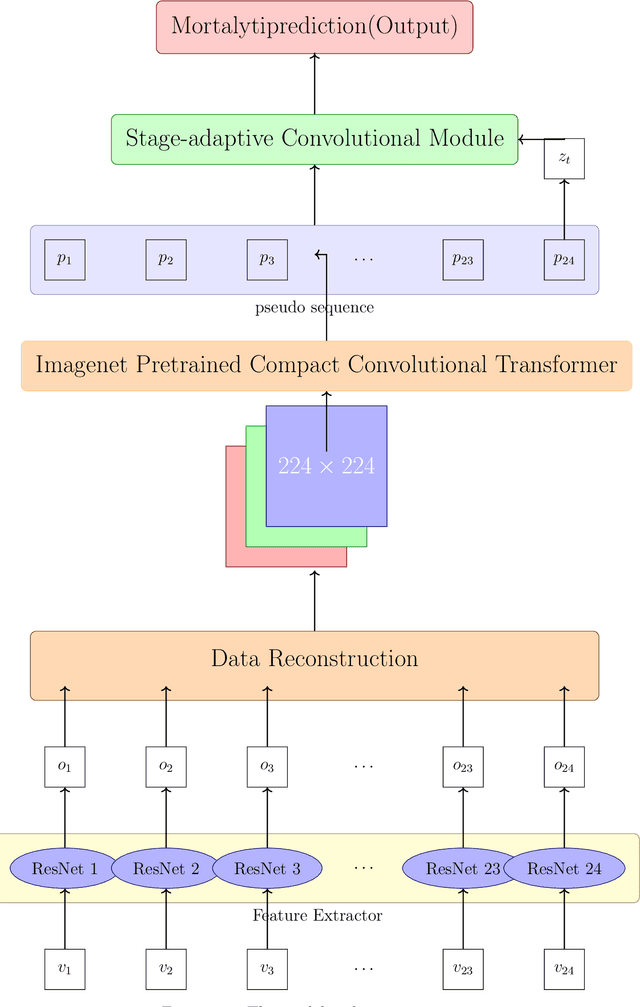
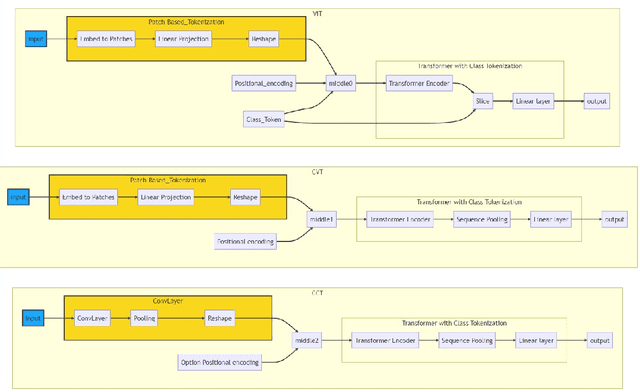
This article investigates deep learning methodologies for single-modality clinical data analysis, as a crucial precursor to multi-modal medical research. Building on Guo JingYuan's work, the study refines clinical data processing through Compact Convolutional Transformer (CCT), Patch Up, and the innovative CamCenterLoss technique, establishing a foundation for future multimodal investigations. The proposed methodology demonstrates improved prediction accuracy and at tentiveness to critically ill patients compared to Guo JingYuan's ResNet and StageNet approaches. Novelty that using image-pretrained vision transformer backbone to perform transfer learning time-series clinical data.The study highlights the potential of CCT, Patch Up, and novel CamCenterLoss in processing single modality clinical data within deep learning frameworks, paving the way for future multimodal medical research and promoting precision and personalized healthcare
UniCtrl: Improving the Spatiotemporal Consistency of Text-to-Video Diffusion Models via Training-Free Unified Attention Control
Mar 06, 2024


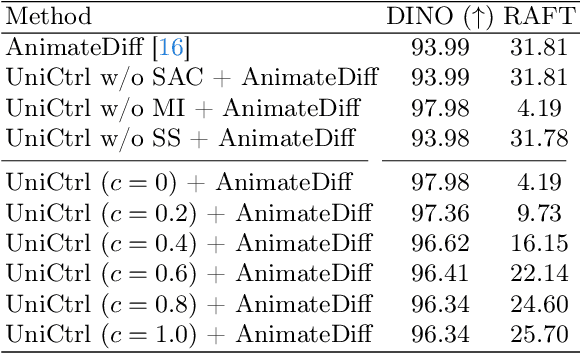
Video Diffusion Models have been developed for video generation, usually integrating text and image conditioning to enhance control over the generated content. Despite the progress, ensuring consistency across frames remains a challenge, particularly when using text prompts as control conditions. To address this problem, we introduce UniCtrl, a novel, plug-and-play method that is universally applicable to improve the spatiotemporal consistency and motion diversity of videos generated by text-to-video models without additional training. UniCtrl ensures semantic consistency across different frames through cross-frame self-attention control, and meanwhile, enhances the motion quality and spatiotemporal consistency through motion injection and spatiotemporal synchronization. Our experimental results demonstrate UniCtrl's efficacy in enhancing various text-to-video models, confirming its effectiveness and universality.
On Trojan Signatures in Large Language Models of Code
Mar 07, 2024Trojan signatures, as described by Fields et al. (2021), are noticeable differences in the distribution of the trojaned class parameters (weights) and the non-trojaned class parameters of the trojaned model, that can be used to detect the trojaned model. Fields et al. (2021) found trojan signatures in computer vision classification tasks with image models, such as, Resnet, WideResnet, Densenet, and VGG. In this paper, we investigate such signatures in the classifier layer parameters of large language models of source code. Our results suggest that trojan signatures could not generalize to LLMs of code. We found that trojaned code models are stubborn, even when the models were poisoned under more explicit settings (finetuned with pre-trained weights frozen). We analyzed nine trojaned models for two binary classification tasks: clone and defect detection. To the best of our knowledge, this is the first work to examine weight-based trojan signature revelation techniques for large-language models of code and furthermore to demonstrate that detecting trojans only from the weights in such models is a hard problem.
DLP-GAN: learning to draw modern Chinese landscape photos with generative adversarial network
Mar 07, 2024Chinese landscape painting has a unique and artistic style, and its drawing technique is highly abstract in both the use of color and the realistic representation of objects. Previous methods focus on transferring from modern photos to ancient ink paintings. However, little attention has been paid to translating landscape paintings into modern photos. To solve such problems, in this paper, we (1) propose DLP-GAN (Draw Modern Chinese Landscape Photos with Generative Adversarial Network), an unsupervised cross-domain image translation framework with a novel asymmetric cycle mapping, and (2) introduce a generator based on a dense-fusion module to match different translation directions. Moreover, a dual-consistency loss is proposed to balance the realism and abstraction of model painting. In this way, our model can draw landscape photos and sketches in the modern sense. Finally, based on our collection of modern landscape and sketch datasets, we compare the images generated by our model with other benchmarks. Extensive experiments including user studies show that our model outperforms state-of-the-art methods.
* Corrected typos
CMDA: Cross-Modal and Domain Adversarial Adaptation for LiDAR-Based 3D Object Detection
Mar 07, 2024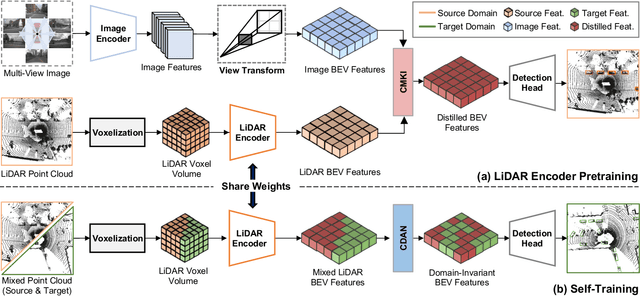
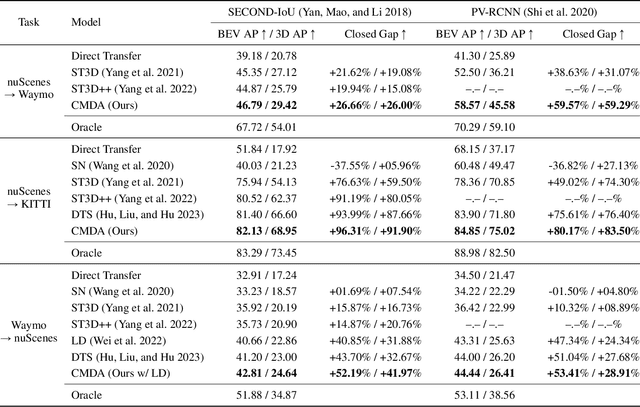
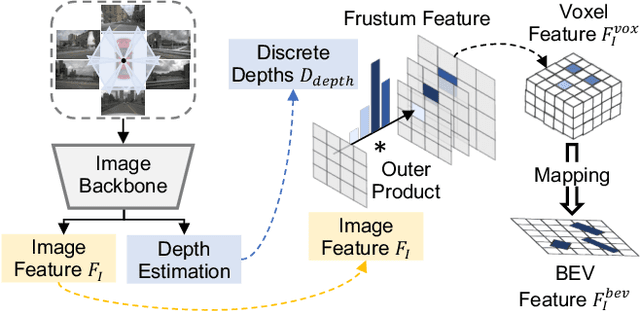
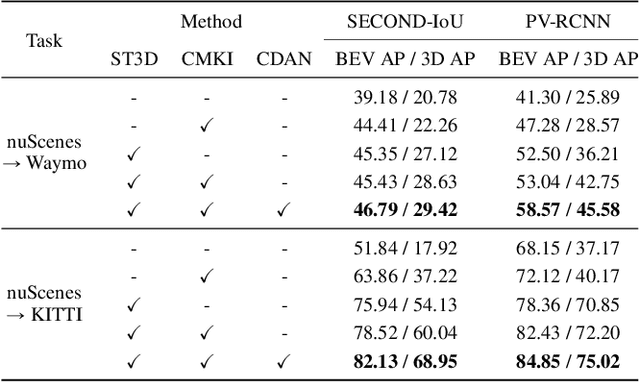
Recent LiDAR-based 3D Object Detection (3DOD) methods show promising results, but they often do not generalize well to target domains outside the source (or training) data distribution. To reduce such domain gaps and thus to make 3DOD models more generalizable, we introduce a novel unsupervised domain adaptation (UDA) method, called CMDA, which (i) leverages visual semantic cues from an image modality (i.e., camera images) as an effective semantic bridge to close the domain gap in the cross-modal Bird's Eye View (BEV) representations. Further, (ii) we also introduce a self-training-based learning strategy, wherein a model is adversarially trained to generate domain-invariant features, which disrupt the discrimination of whether a feature instance comes from a source or an unseen target domain. Overall, our CMDA framework guides the 3DOD model to generate highly informative and domain-adaptive features for novel data distributions. In our extensive experiments with large-scale benchmarks, such as nuScenes, Waymo, and KITTI, those mentioned above provide significant performance gains for UDA tasks, achieving state-of-the-art performance.