 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Ghost-free High Dynamic Range Imaging with Context-aware Transformer
Aug 10, 2022

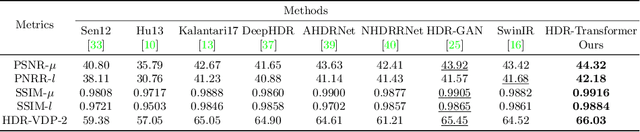
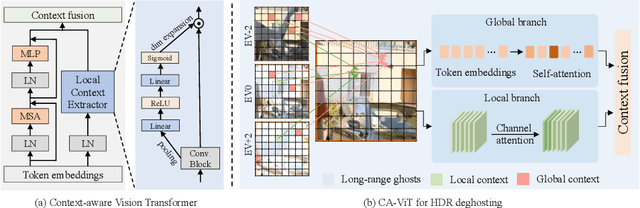

High dynamic range (HDR) deghosting algorithms aim to generate ghost-free HDR images with realistic details. Restricted by the locality of the receptive field, existing CNN-based methods are typically prone to producing ghosting artifacts and intensity distortions in the presence of large motion and severe saturation. In this paper, we propose a novel Context-Aware Vision Transformer (CA-ViT) for ghost-free high dynamic range imaging. The CA-ViT is designed as a dual-branch architecture, which can jointly capture both global and local dependencies. Specifically, the global branch employs a window-based Transformer encoder to model long-range object movements and intensity variations to solve ghosting. For the local branch, we design a local context extractor (LCE) to capture short-range image features and use the channel attention mechanism to select informative local details across the extracted features to complement the global branch. By incorporating the CA-ViT as basic components, we further build the HDR-Transformer, a hierarchical network to reconstruct high-quality ghost-free HDR images. Extensive experiments on three benchmark datasets show that our approach outperforms state-of-the-art methods qualitatively and quantitatively with considerably reduced computational budgets. Codes are available at https://github.com/megvii-research/HDR-Transformer
What Image Features Boost Housing Market Predictions?
Jul 15, 2021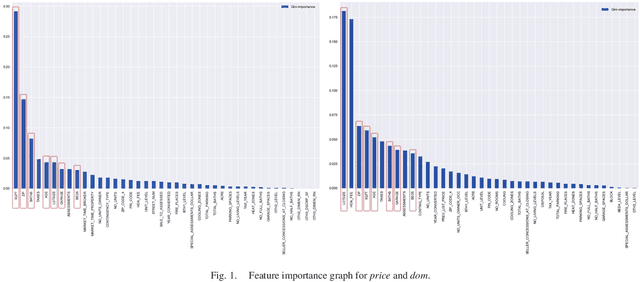

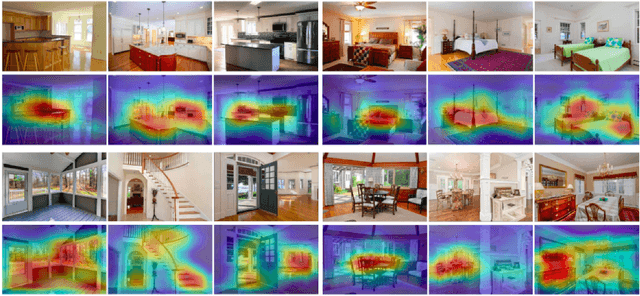

The attractiveness of a property is one of the most interesting, yet challenging, categories to model. Image characteristics are used to describe certain attributes, and to examine the influence of visual factors on the price or timeframe of the listing. In this paper, we propose a set of techniques for the extraction of visual features for efficient numerical inclusion in modern-day predictive algorithms. We discuss techniques such as Shannon's entropy, calculating the center of gravity, employing image segmentation, and using Convolutional Neural Networks. After comparing these techniques as applied to a set of property-related images (indoor, outdoor, and satellite), we conclude the following: (i) the entropy is the most efficient single-digit visual measure for housing price prediction; (ii) image segmentation is the most important visual feature for the prediction of housing lifespan; and (iii) deep image features can be used to quantify interior characteristics and contribute to captivation modeling. The set of 40 image features selected here carries a significant amount of predictive power and outperforms some of the strongest metadata predictors. Without any need to replace a human expert in a real-estate appraisal process, we conclude that the techniques presented in this paper can efficiently describe visible characteristics, thus introducing perceived attractiveness as a quantitative measure into the predictive modeling of housing.
Correlation between image quality metrics of magnetic resonance images and the neural network segmentation accuracy
Nov 01, 2021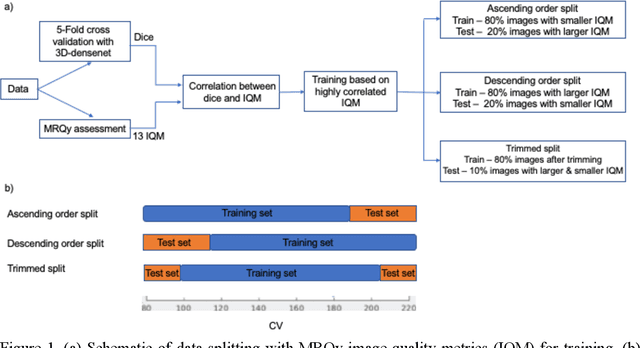
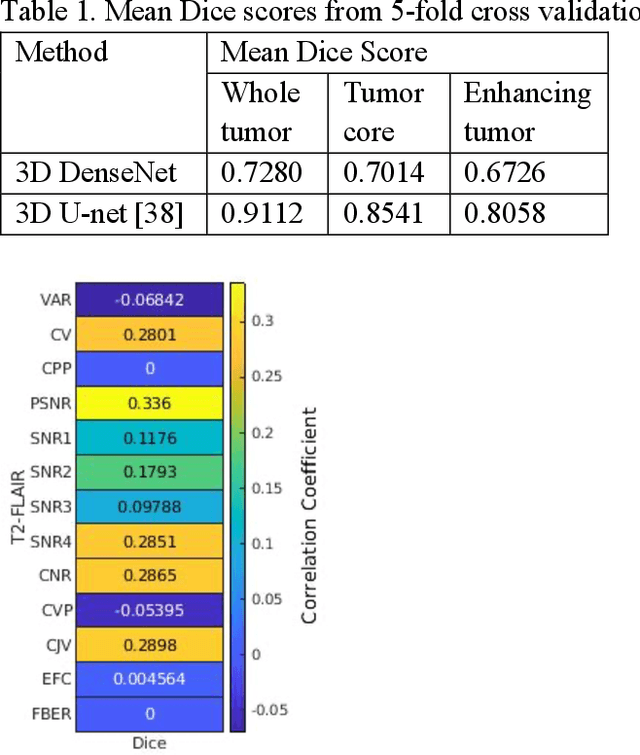
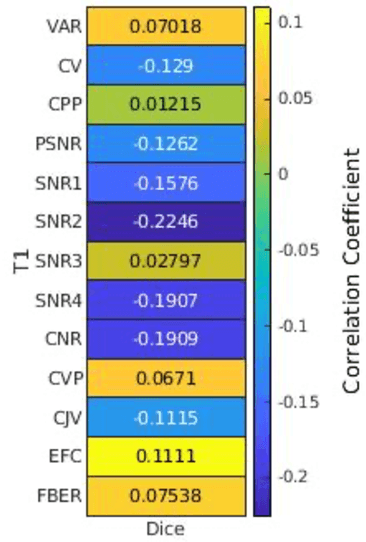
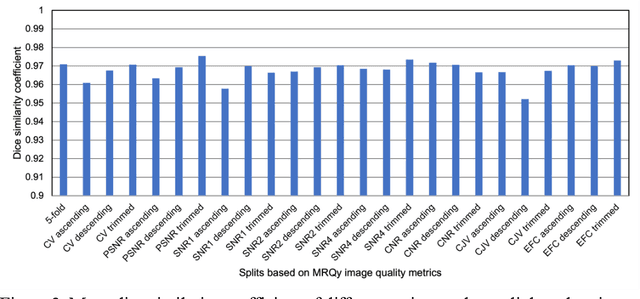
Deep neural networks with multilevel connections process input data in complex ways to learn the information.A networks learning efficiency depends not only on the complex neural network architecture but also on the input training images.Medical image segmentation with deep neural networks for skull stripping or tumor segmentation from magnetic resonance images enables learning both global and local features of the images.Though medical images are collected in a controlled environment,there may be artifacts or equipment based variance that cause inherent bias in the input set.In this study, we investigated the correlation between the image quality metrics of MR images with the neural network segmentation accuracy.For that we have used the 3D DenseNet architecture and let the network trained on the same input but applying different methodologies to select the training data set based on the IQM values.The difference in the segmentation accuracy between models based on the random training inputs with IQM based training inputs shed light on the role of image quality metrics on segmentation accuracy.By running the image quality metrics to choose the training inputs,further we may tune the learning efficiency of the network and the segmentation accuracy.
ULISSE: A Tool for One-shot Sky Exploration and its Application to Active Galactic Nuclei Detection
Aug 23, 2022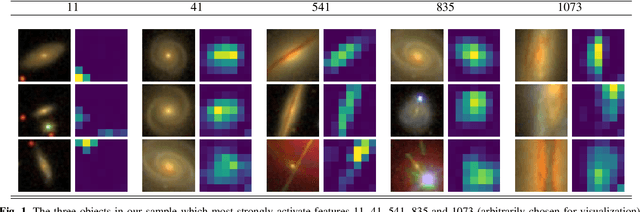
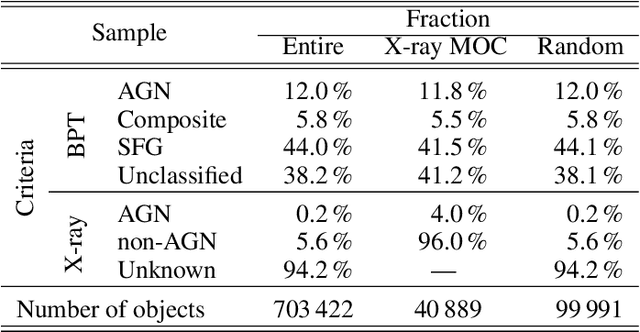
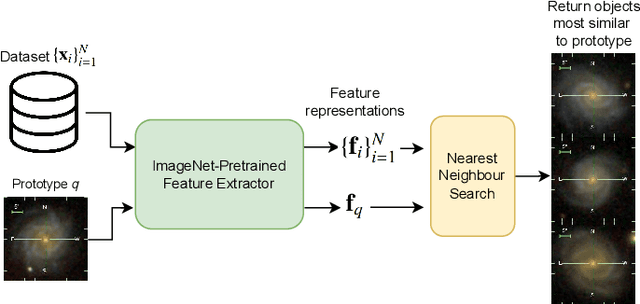
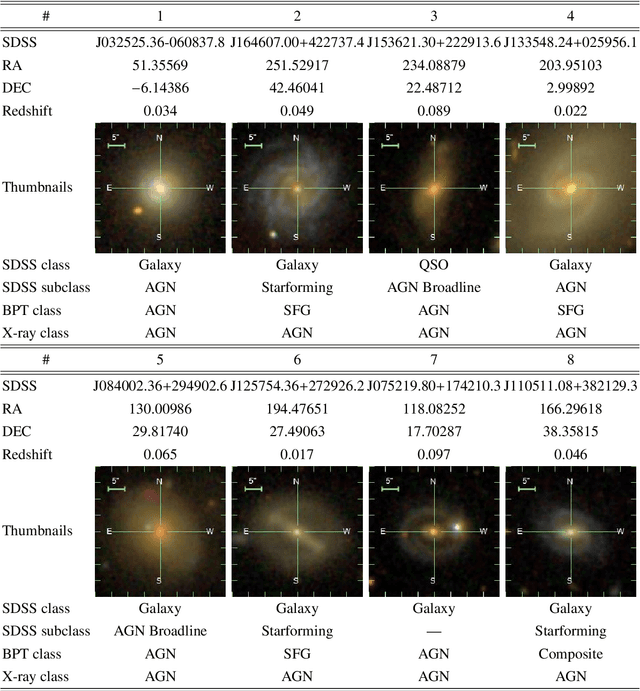
Modern sky surveys are producing ever larger amounts of observational data, which makes the application of classical approaches for the classification and analysis of objects challenging and time-consuming. However, this issue may be significantly mitigated by the application of automatic machine and deep learning methods. We propose ULISSE, a new deep learning tool that, starting from a single prototype object, is capable of identifying objects sharing the same morphological and photometric properties, and hence of creating a list of candidate sosia. In this work, we focus on applying our method to the detection of AGN candidates in a Sloan Digital Sky Survey galaxy sample, since the identification and classification of Active Galactic Nuclei (AGN) in the optical band still remains a challenging task in extragalactic astronomy. Intended for the initial exploration of large sky surveys, ULISSE directly uses features extracted from the ImageNet dataset to perform a similarity search. The method is capable of rapidly identifying a list of candidates, starting from only a single image of a given prototype, without the need for any time-consuming neural network training. Our experiments show ULISSE is able to identify AGN candidates based on a combination of host galaxy morphology, color and the presence of a central nuclear source, with a retrieval efficiency ranging from 21% to 65% (including composite sources) depending on the prototype, where the random guess baseline is 12%. We find ULISSE to be most effective in retrieving AGN in early-type host galaxies, as opposed to prototypes with spiral- or late-type properties. Based on the results described in this work, ULISSE can be a promising tool for selecting different types of astrophysical objects in current and future wide-field surveys (e.g. Euclid, LSST etc.) that target millions of sources every single night.
Disease-oriented image embedding with pseudo-scanner standardization for content-based image retrieval on 3D brain MRI
Aug 14, 2021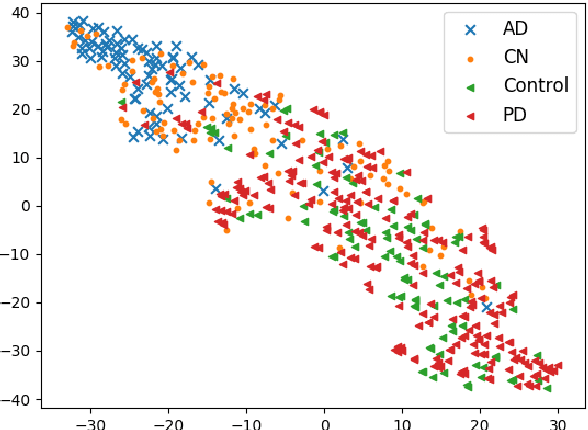
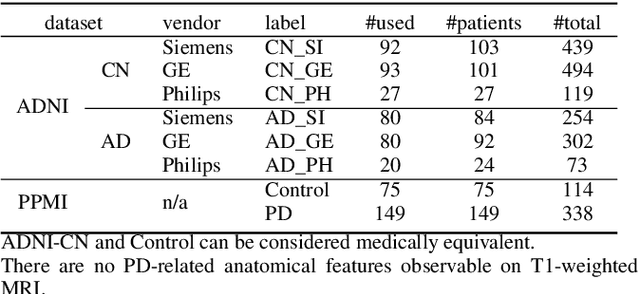
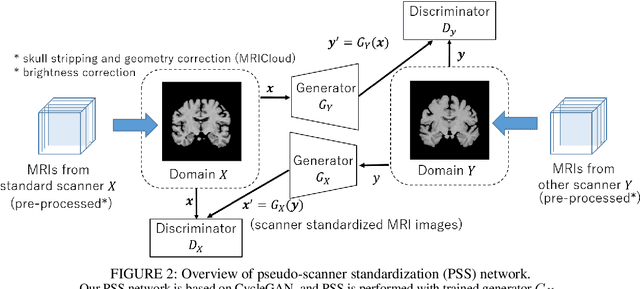
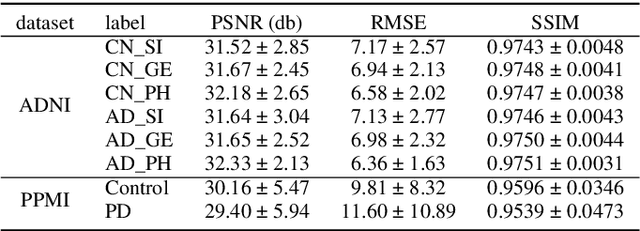
To build a robust and practical content-based image retrieval (CBIR) system that is applicable to a clinical brain MRI database, we propose a new framework -- Disease-oriented image embedding with pseudo-scanner standardization (DI-PSS) -- that consists of two core techniques, data harmonization and a dimension reduction algorithm. Our DI-PSS uses skull stripping and CycleGAN-based image transformations that map to a standard brain followed by transformation into a brain image taken with a given reference scanner. Then, our 3D convolutioinal autoencoders (3D-CAE) with deep metric learning acquires a low-dimensional embedding that better reflects the characteristics of the disease. The effectiveness of our proposed framework was tested on the T1-weighted MRIs selected from the Alzheimer's Disease Neuroimaging Initiative and the Parkinson's Progression Markers Initiative. We confirmed that our PSS greatly reduced the variability of low-dimensional embeddings caused by different scanner and datasets. Compared with the baseline condition, our PSS reduced the variability in the distance from Alzheimer's disease (AD) to clinically normal (CN) and Parkinson disease (PD) cases by 15.8-22.6% and 18.0-29.9%, respectively. These properties allow DI-PSS to generate lower dimensional representations that are more amenable to disease classification. In AD and CN classification experiments based on spectral clustering, PSS improved the average accuracy and macro-F1 by 6.2% and 10.7%, respectively. Given the potential of the DI-PSS for harmonizing images scanned by MRI scanners that were not used to scan the training data, we expect that the DI-PSS is suitable for application to a large number of legacy MRIs scanned in heterogeneous environments.
A Comprehensive Study of Real-Time Object Detection Networks Across Multiple Domains: A Survey
Aug 23, 2022
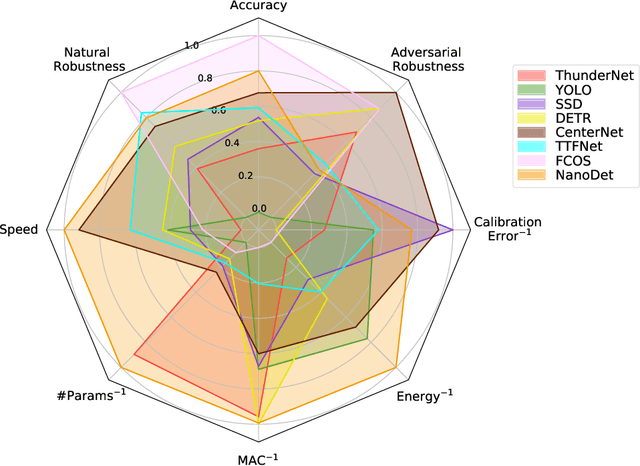
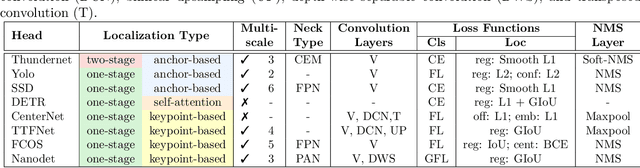
Deep neural network based object detectors are continuously evolving and are used in a multitude of applications, each having its own set of requirements. While safety-critical applications need high accuracy and reliability, low-latency tasks need resource and energy-efficient networks. Real-time detectors, which are a necessity in high-impact real-world applications, are continuously proposed, but they overemphasize the improvements in accuracy and speed while other capabilities such as versatility, robustness, resource and energy efficiency are omitted. A reference benchmark for existing networks does not exist, nor does a standard evaluation guideline for designing new networks, which results in ambiguous and inconsistent comparisons. We, thus, conduct a comprehensive study on multiple real-time detectors (anchor-, keypoint-, and transformer-based) on a wide range of datasets and report results on an extensive set of metrics. We also study the impact of variables such as image size, anchor dimensions, confidence thresholds, and architecture layers on the overall performance. We analyze the robustness of detection networks against distribution shifts, natural corruptions, and adversarial attacks. Also, we provide a calibration analysis to gauge the reliability of the predictions. Finally, to highlight the real-world impact, we conduct two unique case studies, on autonomous driving and healthcare applications. To further gauge the capability of networks in critical real-time applications, we report the performance after deploying the detection networks on edge devices. Our extensive empirical study can act as a guideline for the industrial community to make an informed choice on the existing networks. We also hope to inspire the research community towards a new direction in the design and evaluation of networks that focuses on a bigger and holistic overview for a far-reaching impact.
* Published in Transactions on Machine Learning Research (TMLR) with Survey Certification
An Image-based Generator Architecture for Synthetic Image Refinement
Aug 10, 2021
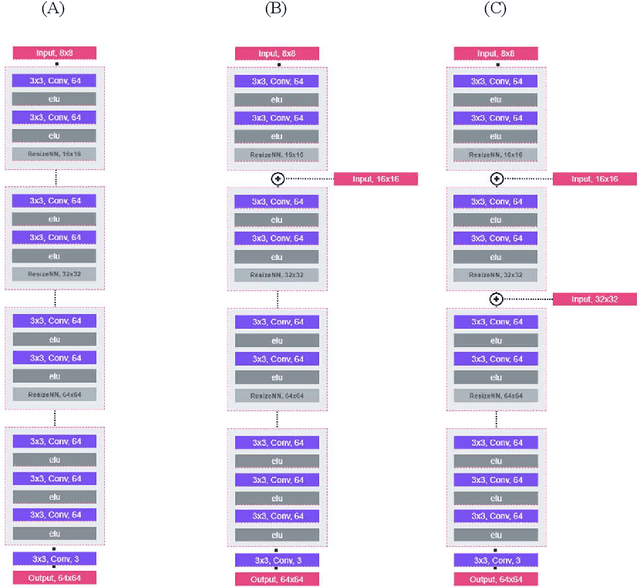

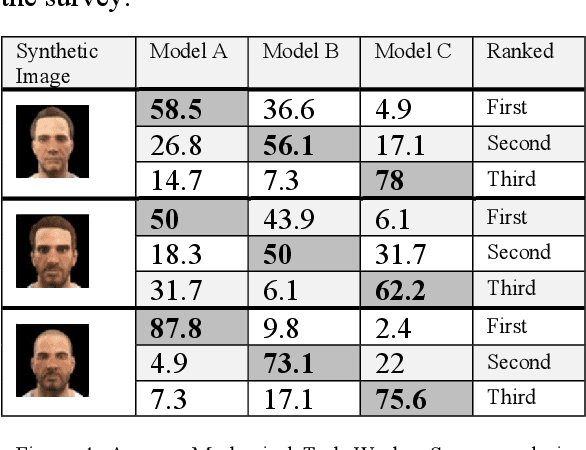
Proposed are alternative generator architectures for Boundary Equilibrium Generative Adversarial Networks, motivated by Learning from Simulated and Unsupervised Images through Adversarial Training. It disentangles the need for a noise-based latent space. The generator will operate mainly as a refiner network to gain a photo-realistic presentation of the given synthetic images. It also attempts to resolve the latent space's poorly understood properties by eliminating the need for noise injection and replacing it with an image-based concept. The new flexible and simple generator architecture will also give the power to control the trade-off between restrictive refinement and expressiveness ability. Contrary to other available methods, this architecture will not require a paired or unpaired dataset of real and synthetic images for the training phase. Only a relatively small set of real images would suffice.
HLIC: Harmonizing Optimization Metrics in Learned Image Compression by Reinforcement Learning
Sep 30, 2021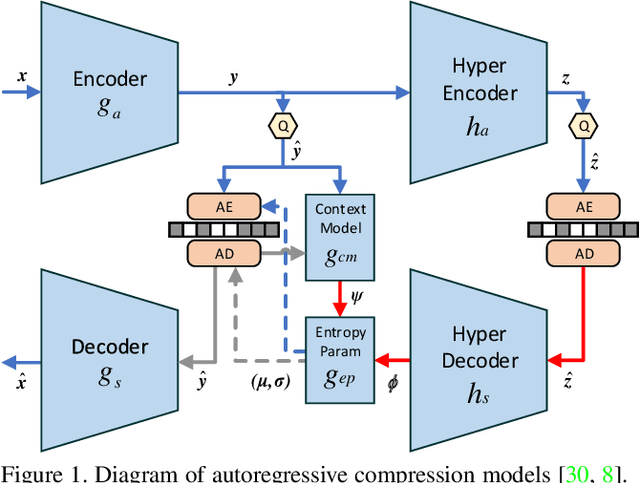
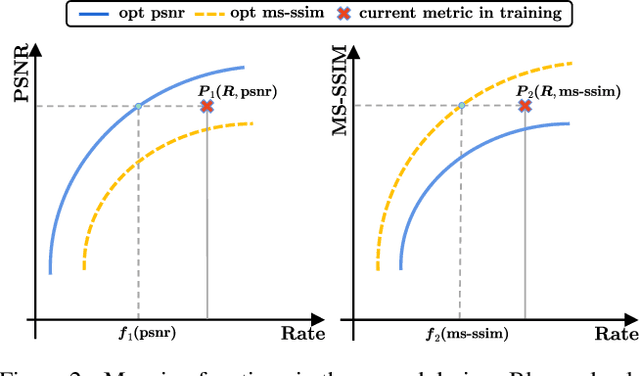
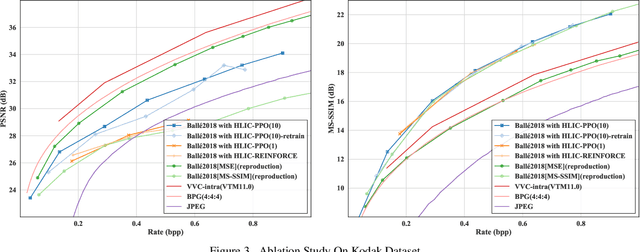
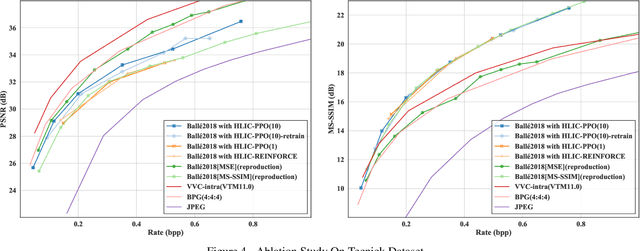
Learned image compression is making good progress in recent years. Peak signal-to-noise ratio (PSNR) and multi-scale structural similarity (MS-SSIM) are the two most popular evaluation metrics. As different metrics only reflect certain aspects of human perception, works in this field normally optimize two models using PSNR and MS-SSIM as loss function separately, which is suboptimal and makes it difficult to select the model with best visual quality or overall performance. Towards solving this problem, we propose to Harmonize optimization metrics in Learned Image Compression (HLIC) using online loss function adaptation by reinforcement learning. By doing so, we are able to leverage the advantages of both PSNR and MS-SSIM, achieving better visual quality and higher VMAF score. To our knowledge, our work is the first to explore automatic loss function adaptation for harmonizing optimization metrics in low level vision tasks like learned image compression.
An Image Classifier Can Suffice For Video Understanding
Jun 30, 2021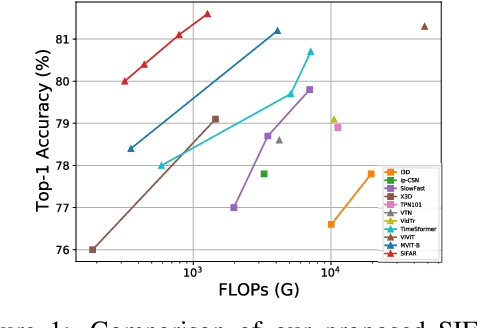
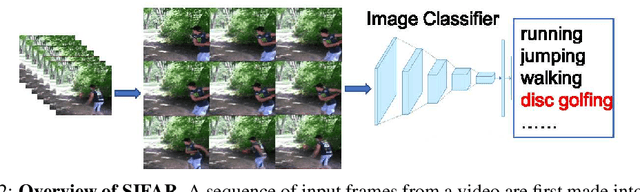
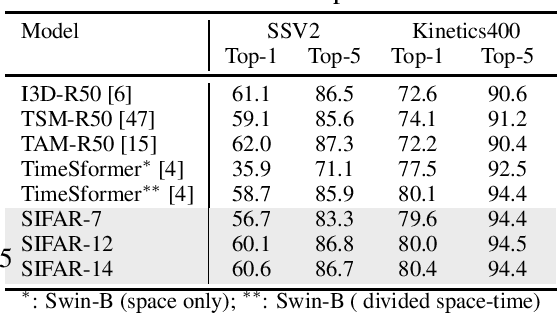
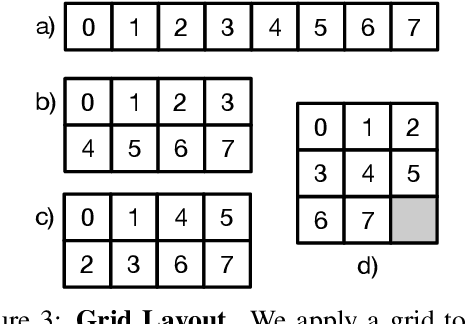
We propose a new perspective on video understanding by casting the video recognition problem as an image recognition task. We show that an image classifier alone can suffice for video understanding without temporal modeling. Our approach is simple and universal. It composes input frames into a super image to train an image classifier to fulfill the task of action recognition, in exactly the same way as classifying an image. We prove the viability of such an idea by demonstrating strong and promising performance on four public datasets including Kinetics400, Something-to-something (V2), MiT and Jester, using a recently developed vision transformer. We also experiment with the prevalent ResNet image classifiers in computer vision to further validate our idea. The results on Kinetics400 are comparable to some of the best-performed CNN approaches based on spatio-temporal modeling. our code and models will be made available at https://github.com/IBM/sifar-pytorch.
Localization supervision of chest x-ray classifiers using label-specific eye-tracking annotation
Jul 20, 2022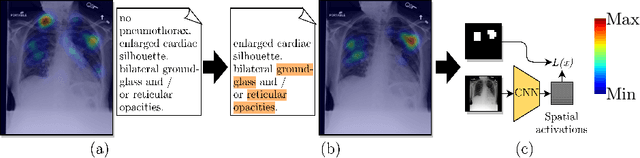
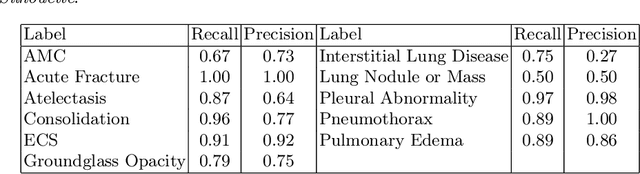
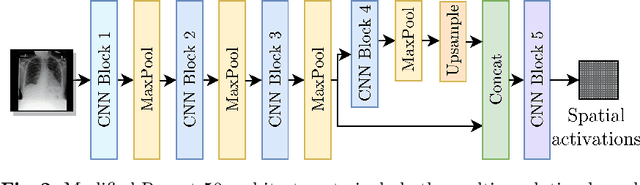
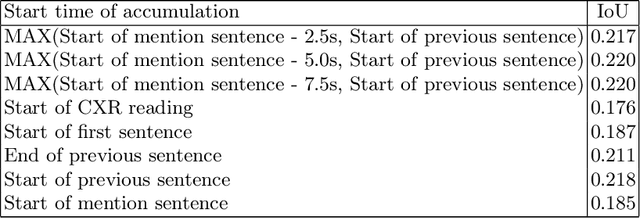
Convolutional neural networks (CNNs) have been successfully applied to chest x-ray (CXR) images. Moreover, annotated bounding boxes have been shown to improve the interpretability of a CNN in terms of localizing abnormalities. However, only a few relatively small CXR datasets containing bounding boxes are available, and collecting them is very costly. Opportunely, eye-tracking (ET) data can be collected in a non-intrusive way during the clinical workflow of a radiologist. We use ET data recorded from radiologists while dictating CXR reports to train CNNs. We extract snippets from the ET data by associating them with the dictation of keywords and use them to supervise the localization of abnormalities. We show that this method improves a model's interpretability without impacting its image-level classification.