 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CrAM: A Compression-Aware Minimizer
Jul 28, 2022
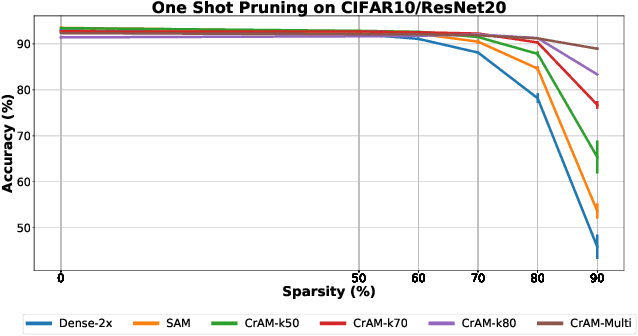

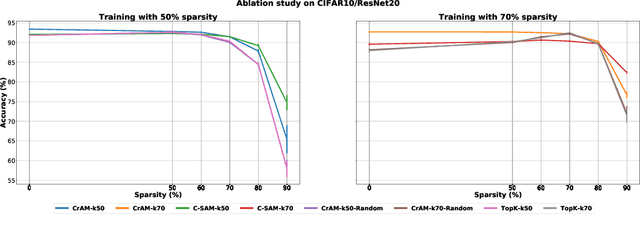
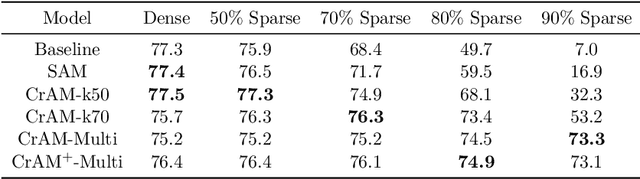
We examine the question of whether SGD-based optimization of deep neural networks (DNNs) can be adapted to produce models which are both highly-accurate and easily-compressible. We propose a new compression-aware minimizer dubbed CrAM, which modifies the SGD training iteration in a principled way, in order to produce models whose local loss behavior is stable under compression operations such as weight pruning or quantization. Experimental results on standard image classification tasks show that CrAM produces dense models that can be more accurate than standard SGD-type baselines, but which are surprisingly stable under weight pruning: for instance, for ResNet50 on ImageNet, CrAM-trained models can lose up to 70% of their weights in one shot with only minor accuracy loss.
Generation of Artificial CT Images using Patch-based Conditional Generative Adversarial Networks
May 19, 2022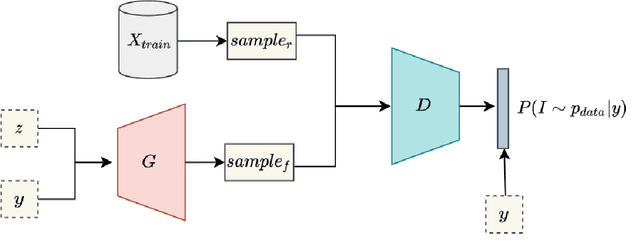
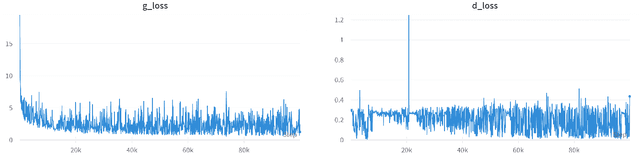
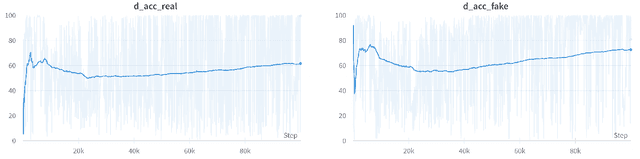
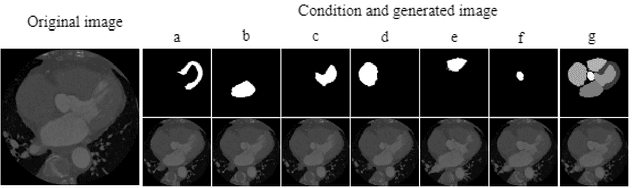
Deep learning has a great potential to alleviate diagnosis and prognosis for various clinical procedures. However, the lack of a sufficient number of medical images is the most common obstacle in conducting image-based analysis using deep learning. Due to the annotations scarcity, semi-supervised techniques in the automatic medical analysis are getting high attention. Artificial data augmentation and generation techniques such as generative adversarial networks (GANs) may help overcome this obstacle. In this work, we present an image generation approach that uses generative adversarial networks with a conditional discriminator where segmentation masks are used as conditions for image generation. We validate the feasibility of GAN-enhanced medical image generation on whole heart computed tomography (CT) images and its seven substructures, namely: left ventricle, right ventricle, left atrium, right atrium, myocardium, pulmonary arteries, and aorta. Obtained results demonstrate the suitability of the proposed adversarial approach for the accurate generation of high-quality CT images. The presented method shows great potential to facilitate further research in the domain of artificial medical image generation.
Sparse Nonnegative Tucker Decomposition and Completion under Noisy Observations
Aug 17, 2022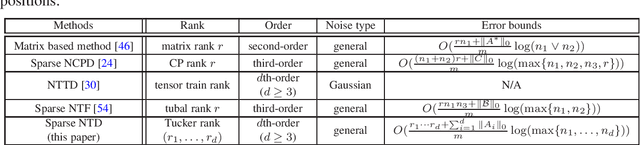
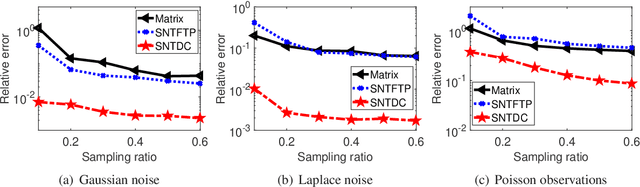
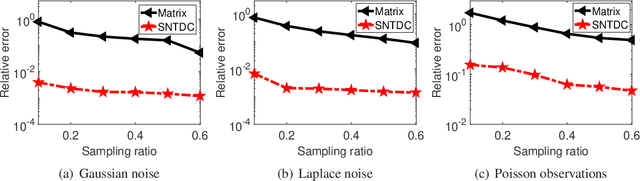
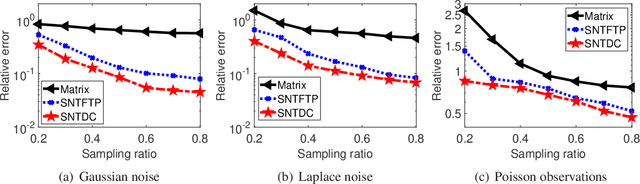
Tensor decomposition is a powerful tool for extracting physically meaningful latent factors from multi-dimensional nonnegative data, and has been an increasing interest in a variety of fields such as image processing, machine learning, and computer vision. In this paper, we propose a sparse nonnegative Tucker decomposition and completion method for the recovery of underlying nonnegative data under noisy observations. Here the underlying nonnegative data tensor is decomposed into a core tensor and several factor matrices with all entries being nonnegative and the factor matrices being sparse. The loss function is derived by the maximum likelihood estimation of the noisy observations, and the $\ell_0$ norm is employed to enhance the sparsity of the factor matrices. We establish the error bound of the estimator of the proposed model under generic noise scenarios, which is then specified to the observations with additive Gaussian noise, additive Laplace noise, and Poisson observations, respectively. Our theoretical results are better than those by existing tensor-based or matrix-based methods. Moreover, the minimax lower bounds are shown to be matched with the derived upper bounds up to logarithmic factors. Numerical examples on both synthetic and real-world data sets demonstrate the superiority of the proposed method for nonnegative tensor data completion.
Grassmannian learning mutual subspace method for image set recognition
Nov 08, 2021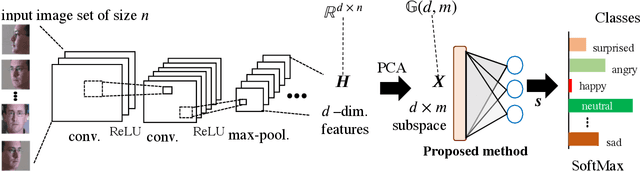
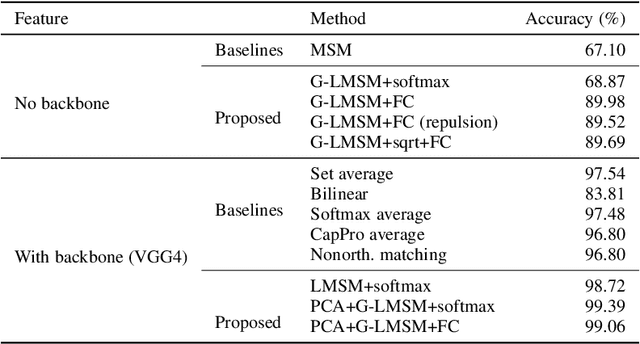
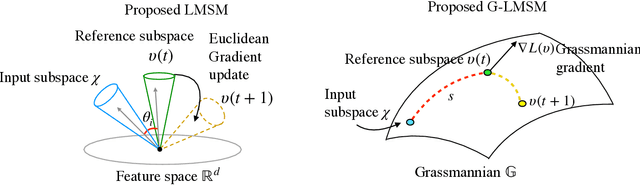
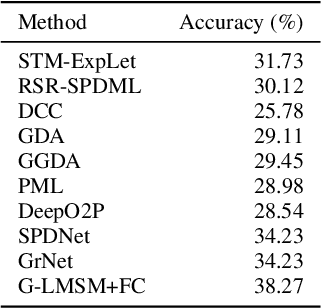
This paper addresses the problem of object recognition given a set of images as input (e.g., multiple camera sources and video frames). Convolutional neural network (CNN)-based frameworks do not exploit these sets effectively, processing a pattern as observed, not capturing the underlying feature distribution as it does not consider the variance of images in the set. To address this issue, we propose the Grassmannian learning mutual subspace method (G-LMSM), a NN layer embedded on top of CNNs as a classifier, that can process image sets more effectively and can be trained in an end-to-end manner. The image set is represented by a low-dimensional input subspace; and this input subspace is matched with reference subspaces by a similarity of their canonical angles, an interpretable and easy to compute metric. The key idea of G-LMSM is that the reference subspaces are learned as points on the Grassmann manifold, optimized with Riemannian stochastic gradient descent. This learning is stable, efficient and theoretically well-grounded. We demonstrate the effectiveness of our proposed method on hand shape recognition, face identification, and facial emotion recognition.
Two-Stage Architectural Fine-Tuning with Neural Architecture Search using Early-Stopping in Image Classification
Feb 17, 2022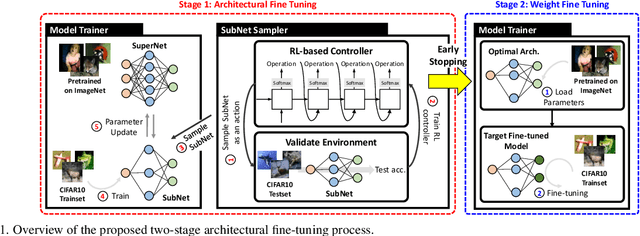

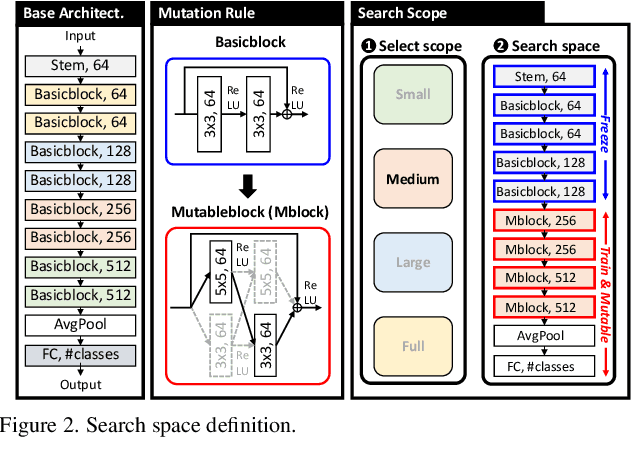
Deep neural networks (NN) perform well in various tasks (e.g., computer vision) because of the convolutional neural networks (CNN). However, the difficulty of gathering quality data in the industry field hinders the practical use of NN. To cope with this issue, the concept of transfer learning (TL) has emerged, which leverages the fine-tuning of NNs trained on large-scale datasets in data-scarce situations. Therefore, this paper suggests a two-stage architectural fine-tuning method for image classification, inspired by the concept of neural architecture search (NAS). One of the main ideas of our proposed method is a mutation with base architectures, which reduces the search cost by using given architectural information. Moreover, an early-stopping is also considered which directly reduces NAS costs. Experimental results verify that our proposed method reduces computational and searching costs by up to 28.2% and 22.3%, compared to existing methods.
Deep Learning-enabled Spatial Phase Unwrapping for 3D Measurement
Aug 06, 2022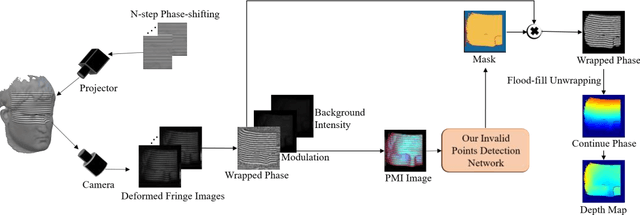
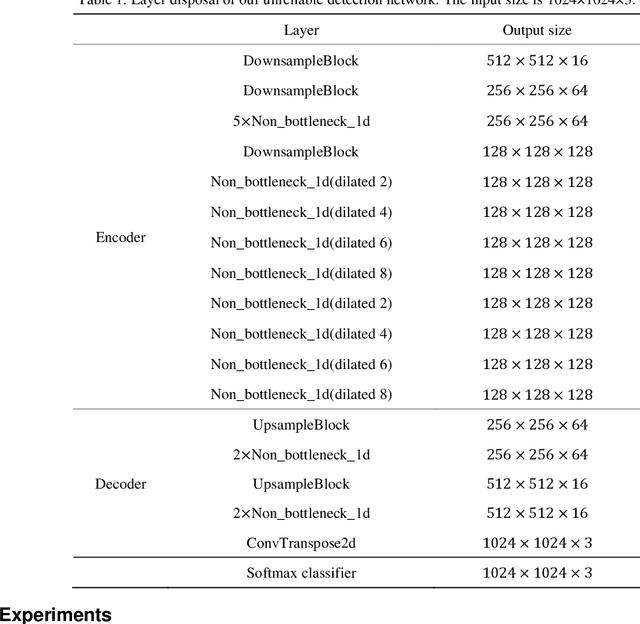
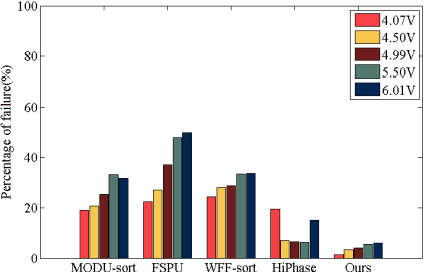
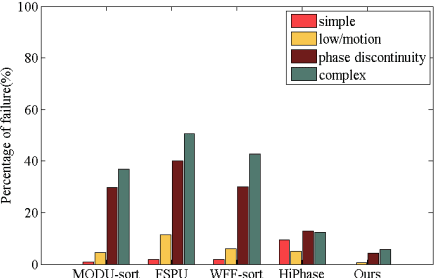
In terms of 3D imaging speed and system cost, the single-camera system projecting single-frequency patterns is the ideal option among all proposed Fringe Projection Profilometry (FPP) systems. This system necessitates a robust spatial phase unwrapping (SPU) algorithm. However, robust SPU remains a challenge in complex scenes. Quality-guided SPU algorithms need more efficient ways to identify the unreliable points in phase maps before unwrapping. End-to-end deep learning SPU methods face generality and interpretability problems. This paper proposes a hybrid method combining deep learning and traditional path-following for robust SPU in FPP. This hybrid SPU scheme demonstrates better robustness than traditional quality-guided SPU methods, better interpretability than end-to-end deep learning scheme, and generality on unseen data. Experiments on the real dataset of multiple illumination conditions and multiple FPP systems differing in image resolution, the number of fringes, fringe direction, and optics wavelength verify the effectiveness of the proposed method.
Paddy Leaf diseases identification on Infrared Images based on Convolutional Neural Networks
Aug 06, 2022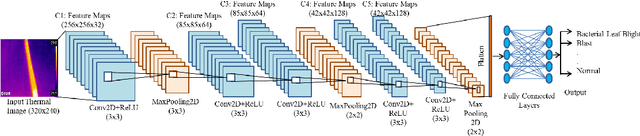
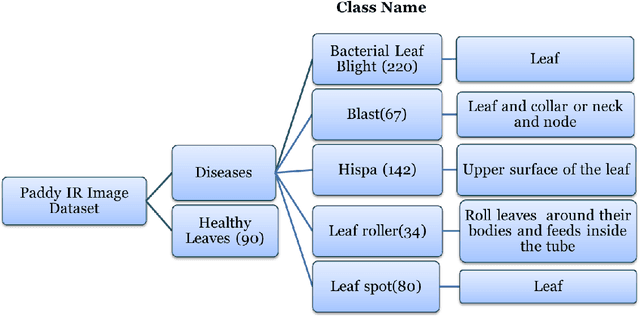
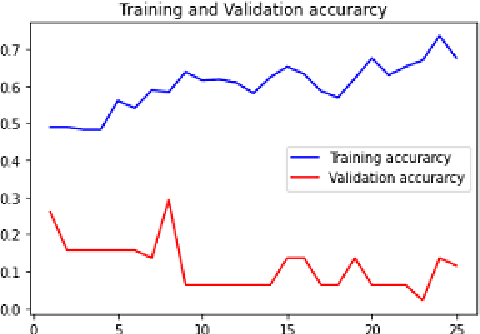
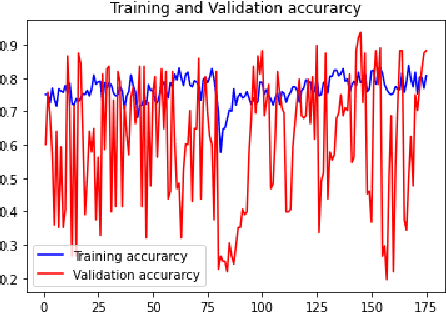
Agriculture is the mainstay of human society because it is an essential need for every organism. Paddy cultivation is very significant so far as humans are concerned, largely in the Asian continent, and it is one of the staple foods. However, plant diseases in agriculture lead to depletion in productivity. Plant diseases are generally caused by pests, insects, and pathogens that decrease productivity to a large scale if not controlled within a particular time. Eventually, one cannot see an increase in paddy yield. Accurate and timely identification of plant diseases can help farmers mitigate losses due to pests and diseases. Recently, deep learning techniques have been used to identify paddy diseases and overcome these problems. This paper implements a convolutional neural network (CNN) based on a model and tests a public dataset consisting of 636 infrared image samples with five paddy disease classes and one healthy class. The proposed model proficiently identified and classified paddy diseases of five different types and achieved an accuracy of 88.28%
HaloAE: An HaloNet based Local Transformer Auto-Encoder for Anomaly Detection and Localization
Aug 06, 2022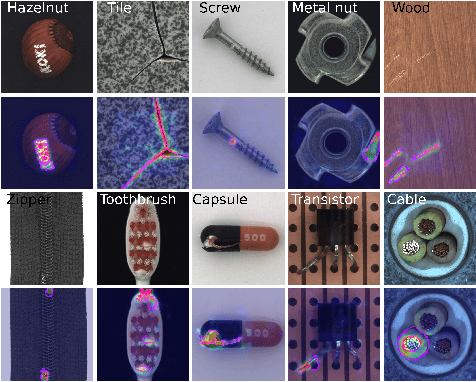

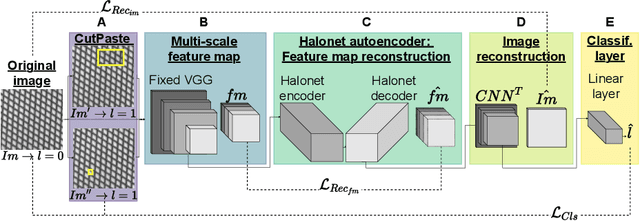
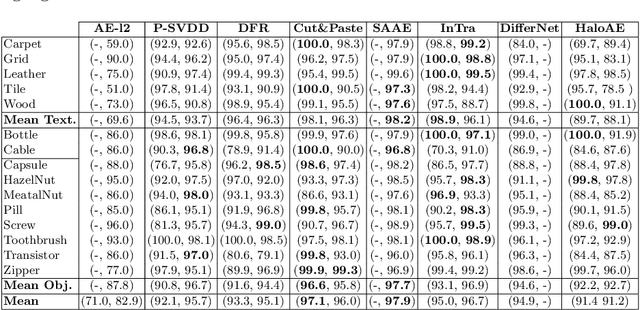
Unsupervised anomaly detection and localization is a crucial task as it is impossible to collect and label all possible anomalies. Many studies have emphasized the importance of integrating local and global information to achieve accurate segmentation of anomalies. To this end, there has been a growing interest in Transformer, which allows modeling long-range content interactions. However, global interactions through self attention are generally too expensive for most image scales. In this study, we introduce HaloAE, the first auto-encoder based on a local 2D version of Transformer with HaloNet. With HaloAE, we have created a hybrid model that combines convolution and local 2D block-wise self-attention layers and jointly performs anomaly detection and segmentation through a single model. We achieved competitive results on the MVTec dataset, suggesting that vision models incorporating Transformer could benefit from a local computation of the self-attention operation, and pave the way for other applications.
Towards Real-World Video Deblurring by Exploring Blur Formation Process
Aug 28, 2022

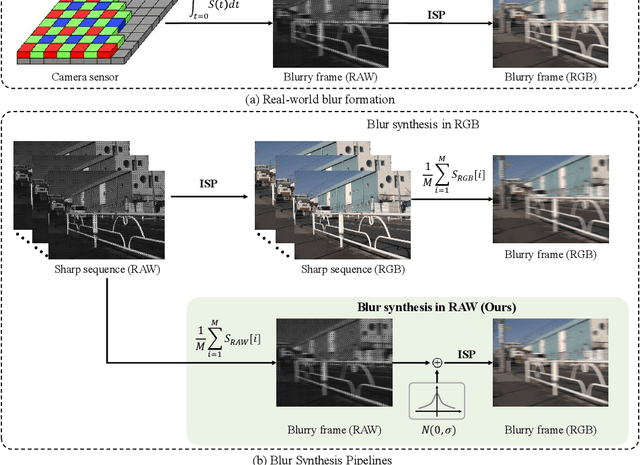
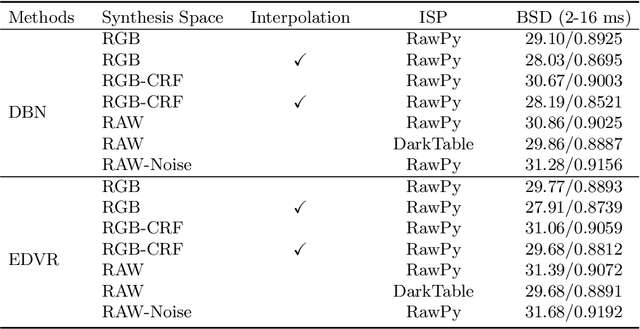
This paper aims at exploring how to synthesize close-to-real blurs that existing video deblurring models trained on them can generalize well to real-world blurry videos. In recent years, deep learning-based approaches have achieved promising success on video deblurring task. However, the models trained on existing synthetic datasets still suffer from generalization problems over real-world blurry scenarios with undesired artifacts. The factors accounting for the failure remain unknown. Therefore, we revisit the classical blur synthesis pipeline and figure out the possible reasons, including shooting parameters, blur formation space, and image signal processor~(ISP). To analyze the effects of these potential factors, we first collect an ultra-high frame-rate (940 FPS) RAW video dataset as the data basis to synthesize various kinds of blurs. Then we propose a novel realistic blur synthesis pipeline termed as RAW-Blur by leveraging blur formation cues. Through numerous experiments, we demonstrate that synthesizing blurs in the RAW space and adopting the same ISP as the real-world testing data can effectively eliminate the negative effects of synthetic data. Furthermore, the shooting parameters of the synthesized blurry video, e.g., exposure time and frame-rate play significant roles in improving the performance of deblurring models. Impressively, the models trained on the blurry data synthesized by the proposed RAW-Blur pipeline can obtain more than 5dB PSNR gain against those trained on the existing synthetic blur datasets. We believe the novel realistic synthesis pipeline and the corresponding RAW video dataset can help the community to easily construct customized blur datasets to improve real-world video deblurring performance largely, instead of laboriously collecting real data pairs.
DLCFT: Deep Linear Continual Fine-Tuning for General Incremental Learning
Aug 17, 2022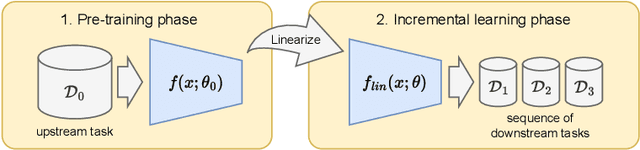
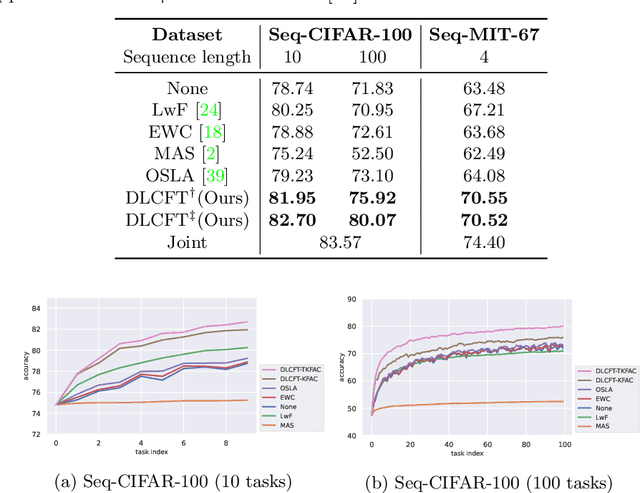
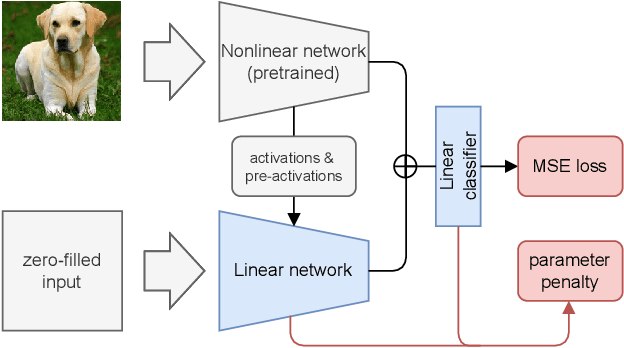
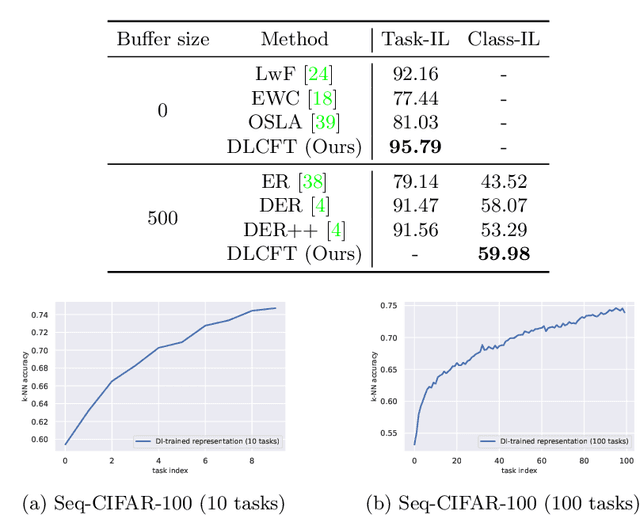
Pre-trained representation is one of the key elements in the success of modern deep learning. However, existing works on continual learning methods have mostly focused on learning models incrementally from scratch. In this paper, we explore an alternative framework to incremental learning where we continually fine-tune the model from a pre-trained representation. Our method takes advantage of linearization technique of a pre-trained neural network for simple and effective continual learning. We show that this allows us to design a linear model where quadratic parameter regularization method is placed as the optimal continual learning policy, and at the same time enjoying the high performance of neural networks. We also show that the proposed algorithm enables parameter regularization methods to be applied to class-incremental problems. Additionally, we provide a theoretical reason why the existing parameter-space regularization algorithms such as EWC underperform on neural networks trained with cross-entropy loss. We show that the proposed method can prevent forgetting while achieving high continual fine-tuning performance on image classification tasks. To show that our method can be applied to general continual learning settings, we evaluate our method in data-incremental, task-incremental, and class-incremental learning problems.