 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A 915-1220 TOPS/W Hybrid In-Memory Computing based Image Restoration and Region Proposal Integrated Circuit for Neuromorphic Vision Sensors in 65nm CMOS
Mar 09, 2022
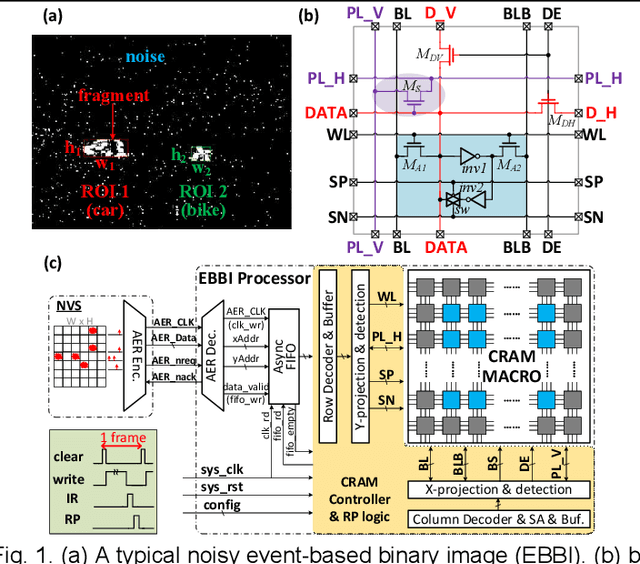
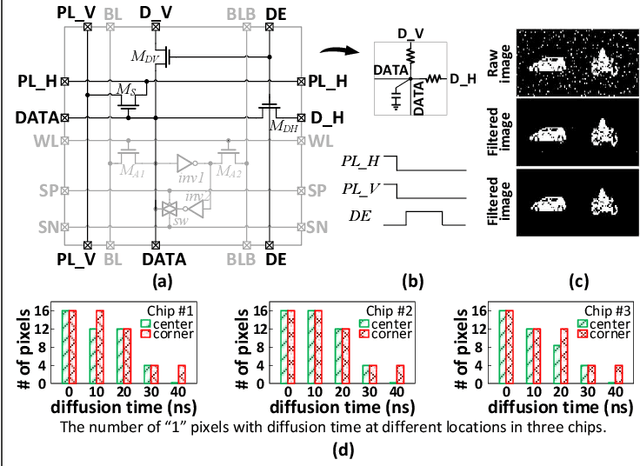
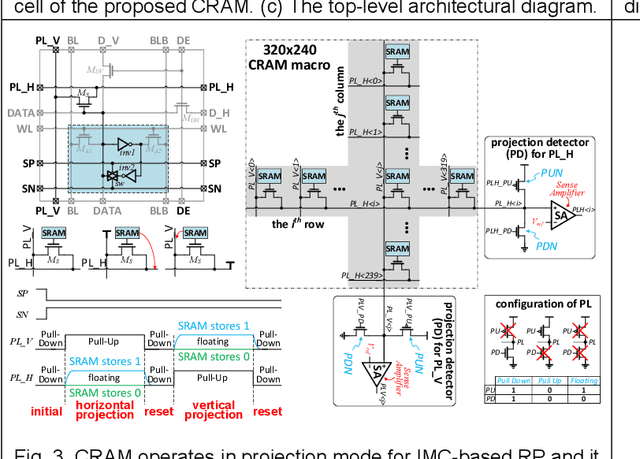
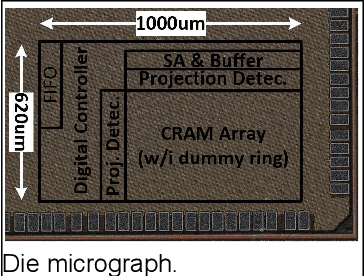
In this work, we present a hybrid memory bit cell - collocated SRAM and DRAM (CRAM) consisting of 11 transistors for in-memory computing (IMC) based image restoration (IR) and region proposal (RP). A robust RP updated algorithm is proposed to improve the performance. This work demonstrates IMC based global parallel diffusion and column/row-wise projection to achieve a maximal energy efficiency of 1220 TOPS/W for image restoration and 915 TOPS/W when combined with region proposal.
A real-time dynamic obstacle tracking and mapping system for UAV navigation and collision avoidance with an RGB-D camera
Sep 17, 2022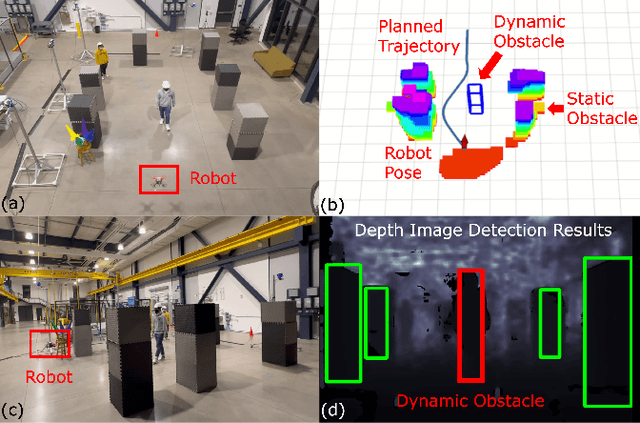
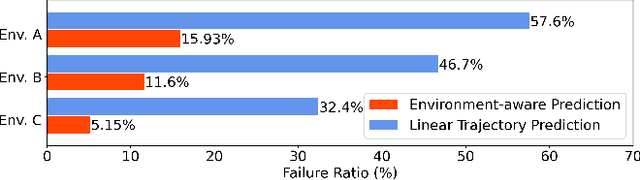
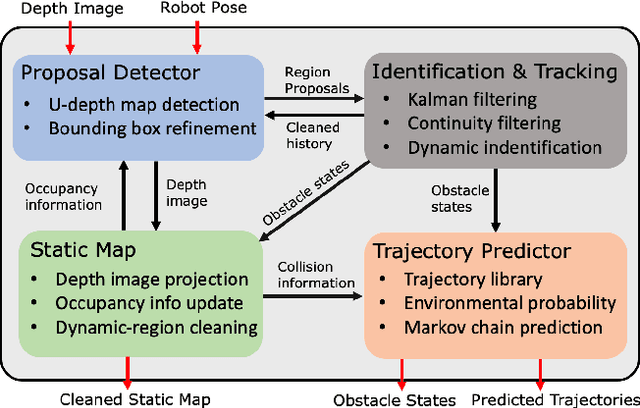
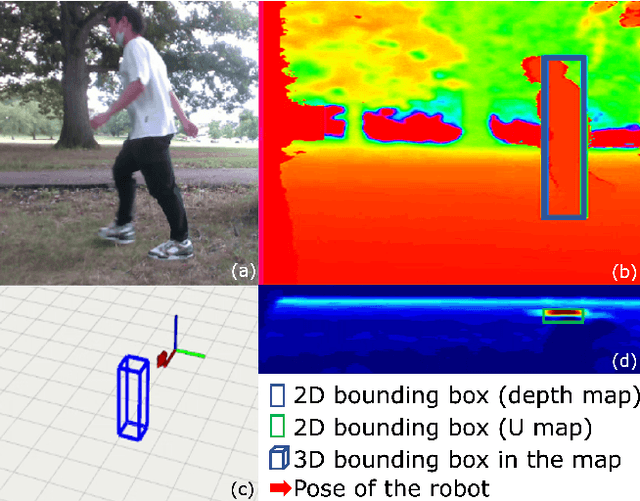
The real-time dynamic environment perception has become vital for autonomous robots in crowded spaces. Although the popular voxel-based mapping methods can efficiently represent 3D obstacles with arbitrarily complex shapes, they can hardly distinguish between static and dynamic obstacles, leading to the limited performance of obstacle avoidance. While plenty of sophisticated learning-based dynamic obstacle detection algorithms exist in autonomous driving, the quadcopter's limited computation resources cannot achieve real-time performance using those approaches. To address these issues, we propose a real-time dynamic obstacle tracking and mapping system for quadcopter obstacle avoidance using an RGB-D camera. The proposed system first utilizes a depth image with an occupancy voxel map to generate potential dynamic obstacle regions as proposals. With the obstacle region proposals, the Kalman filter and our continuity filter are applied to track each dynamic obstacle. Finally, the environment-aware trajectory prediction method is proposed based on the Markov chain using the states of tracked dynamic obstacles. We implemented the proposed system with our custom quadcopter and navigation planner. The simulation and physical experiments show that our methods can successfully track and represent obstacles in dynamic environments in real-time and safely avoid obstacles.
Community Detection in Medical Image Datasets: Using Wavelets and Spectral Methods
Dec 22, 2021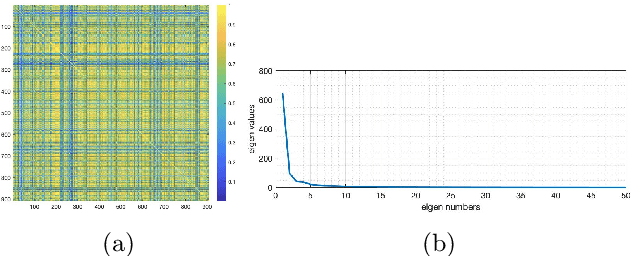
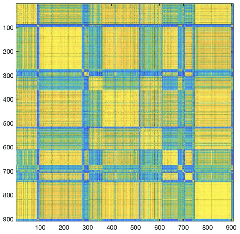
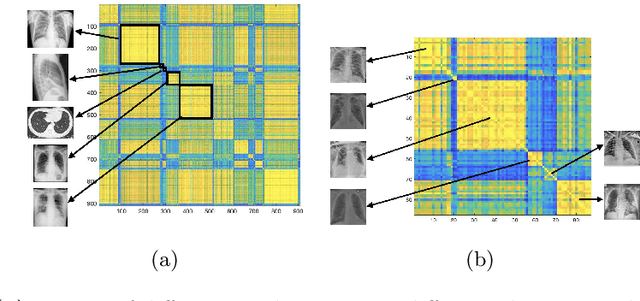
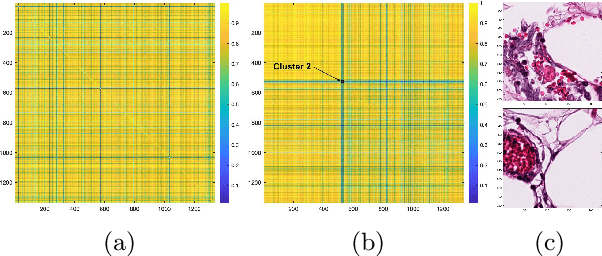
Medical image datasets can have large number of images representing patients with different health conditions and various disease severity. When dealing with raw unlabeled image datasets, the large number of samples often makes it hard for experts and non-experts to understand the variety of images present in a dataset. Supervised learning methods rely on labeled images which requires a considerable effort by medical experts to first understand the communities of images present in the data and then labeling the images. Here, we propose an algorithm to facilitate the automatic identification of communities in medical image datasets. We further explain that such analysis can also be insightful in a supervised setting, when the images are already labeled. Such insights are useful because in reality, health and disease severity can be considered a continuous spectrum, and within each class, there usually are finer communities worthy of investigation, especially when they have similarities to communities in other classes. In our approach, we use wavelet decomposition of images in tandem with spectral methods. We show that the eigenvalues of a graph Laplacian can reveal the number of notable communities in an image dataset. In our experiments, we use a dataset of images labeled with different conditions for COVID patients. We detect 25 communities in the dataset and then observe that only 6 of those communities contain patients with pneumonia. We also investigate the contents of a colorectal cancer histopathology dataset.
Towards Multimodal Vision-Language Models Generating Non-Generic Text
Jul 09, 2022
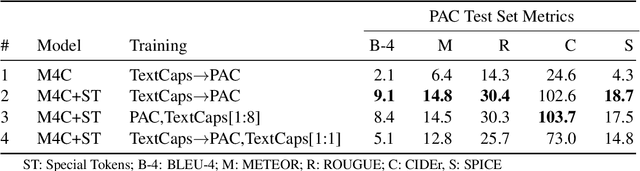
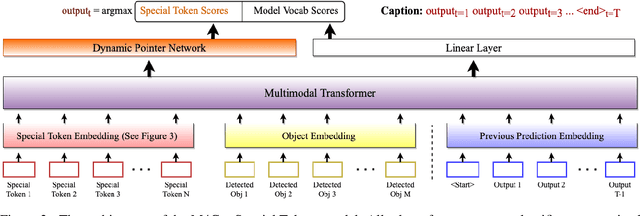

Vision-language models can assess visual context in an image and generate descriptive text. While the generated text may be accurate and syntactically correct, it is often overly general. To address this, recent work has used optical character recognition to supplement visual information with text extracted from an image. In this work, we contend that vision-language models can benefit from additional information that can be extracted from an image, but are not used by current models. We modify previous multimodal frameworks to accept relevant information from any number of auxiliary classifiers. In particular, we focus on person names as an additional set of tokens and create a novel image-caption dataset to facilitate captioning with person names. The dataset, Politicians and Athletes in Captions (PAC), consists of captioned images of well-known people in context. By fine-tuning pretrained models with this dataset, we demonstrate a model that can naturally integrate facial recognition tokens into generated text by training on limited data. For the PAC dataset, we provide a discussion on collection and baseline benchmark scores.
Vision Transformer Hashing for Image Retrieval
Sep 26, 2021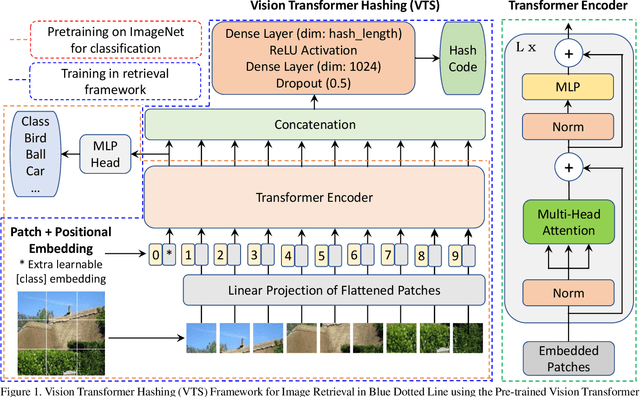
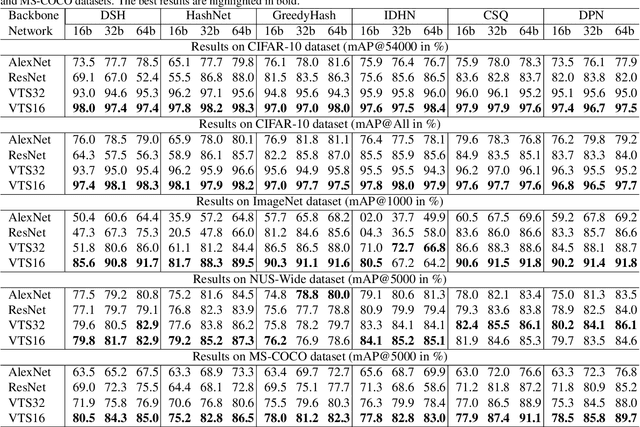
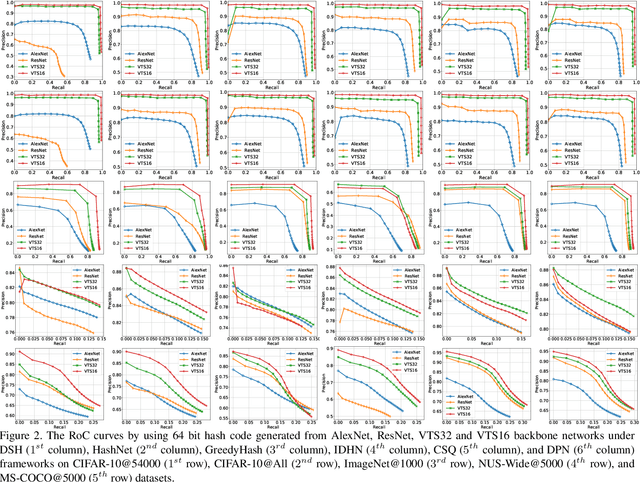
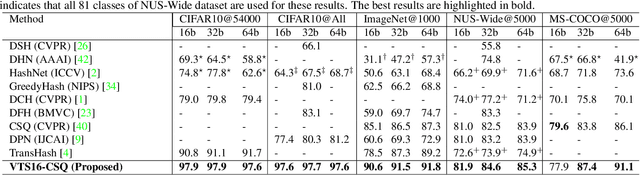
Deep learning has shown a tremendous growth in hashing techniques for image retrieval. Recently, Transformer has emerged as a new architecture by utilizing self-attention without convolution. Transformer is also extended to Vision Transformer (ViT) for the visual recognition with a promising performance on ImageNet. In this paper, we propose a Vision Transformer based Hashing (VTS) for image retrieval. We utilize the pre-trained ViT on ImageNet as the backbone network and add the hashing head. The proposed VTS model is fine tuned for hashing under six different image retrieval frameworks, including Deep Supervised Hashing (DSH), HashNet, GreedyHash, Improved Deep Hashing Network (IDHN), Deep Polarized Network (DPN) and Central Similarity Quantization (CSQ) with their objective functions. We perform the extensive experiments on CIFAR10, ImageNet, NUS-Wide, and COCO datasets. The proposed VTS based image retrieval outperforms the recent state-of-the-art hashing techniques with a great margin. We also find the proposed VTS model as the backbone network is better than the existing networks, such as AlexNet and ResNet.
Integrative Feature and Cost Aggregation with Transformers for Dense Correspondence
Sep 20, 2022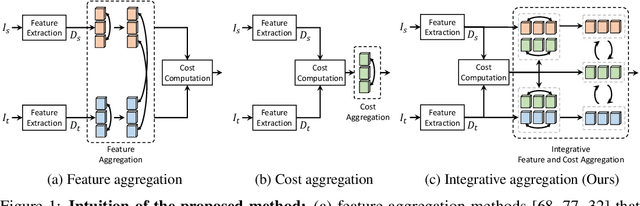
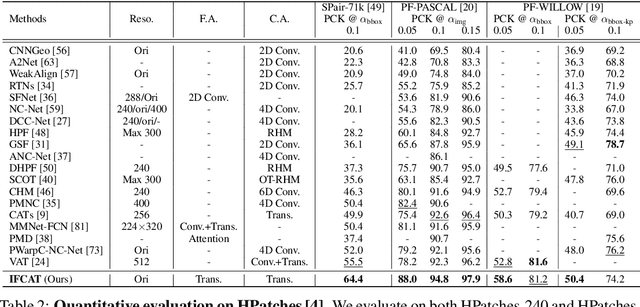

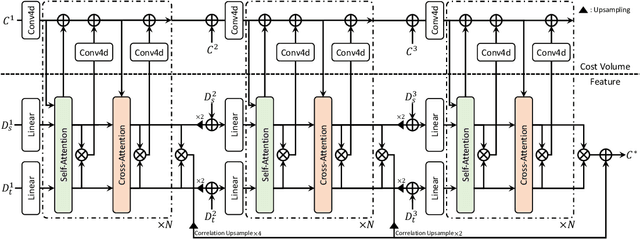
We present a novel architecture for dense correspondence. The current state-of-the-art are Transformer-based approaches that focus on either feature descriptors or cost volume aggregation. However, they generally aggregate one or the other but not both, though joint aggregation would boost each other by providing information that one has but other lacks, i.e., structural or semantic information of an image, or pixel-wise matching similarity. In this work, we propose a novel Transformer-based network that interleaves both forms of aggregations in a way that exploits their complementary information. Specifically, we design a self-attention layer that leverages the descriptor to disambiguate the noisy cost volume and that also utilizes the cost volume to aggregate features in a manner that promotes accurate matching. A subsequent cross-attention layer performs further aggregation conditioned on the descriptors of both images and aided by the aggregated outputs of earlier layers. We further boost the performance with hierarchical processing, in which coarser level aggregations guide those at finer levels. We evaluate the effectiveness of the proposed method on dense matching tasks and achieve state-of-the-art performance on all the major benchmarks. Extensive ablation studies are also provided to validate our design choices.
Expansion and Shrinkage of Localization for Weakly-Supervised Semantic Segmentation
Sep 20, 2022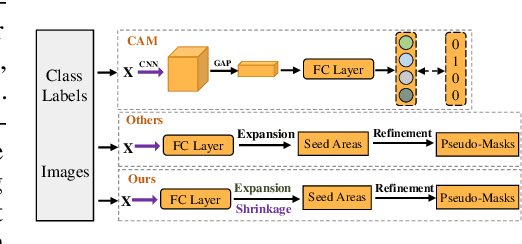
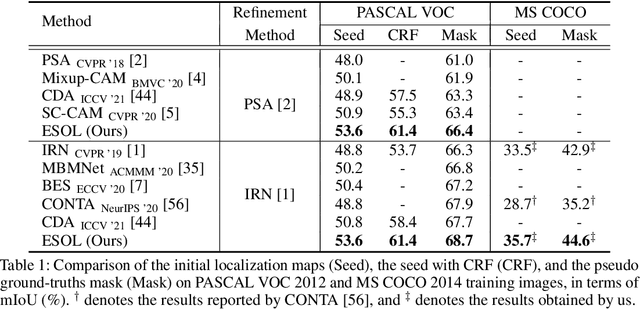
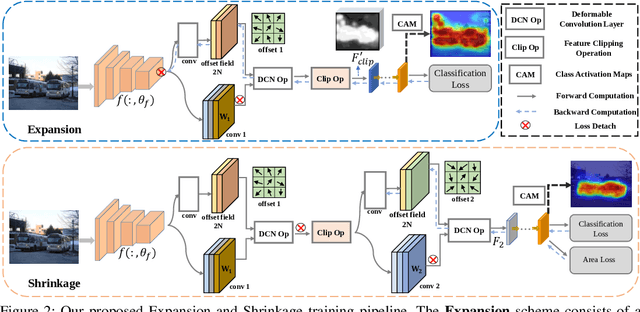

Generating precise class-aware pseudo ground-truths, a.k.a, class activation maps (CAMs), is essential for weakly-supervised semantic segmentation. The original CAM method usually produces incomplete and inaccurate localization maps. To tackle with this issue, this paper proposes an Expansion and Shrinkage scheme based on the offset learning in the deformable convolution, to sequentially improve the recall and precision of the located object in the two respective stages. In the Expansion stage, an offset learning branch in a deformable convolution layer, referred as "expansion sampler" seeks for sampling increasingly less discriminative object regions, driven by an inverse supervision signal that maximizes image-level classification loss. The located more complete object in the Expansion stage is then gradually narrowed down to the final object region during the Shrinkage stage. In the Shrinkage stage, the offset learning branch of another deformable convolution layer, referred as "shrinkage sampler", is introduced to exclude the false positive background regions attended in the Expansion stage to improve the precision of the localization maps. We conduct various experiments on PASCAL VOC 2012 and MS COCO 2014 to well demonstrate the superiority of our method over other state-of-the-art methods for weakly-supervised semantic segmentation. Code will be made publicly available here https://github.com/TyroneLi/ESOL_WSSS.
TIPS: Text-Induced Pose Synthesis
Jul 24, 2022
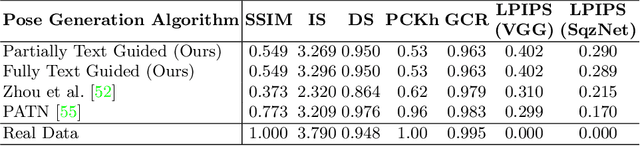
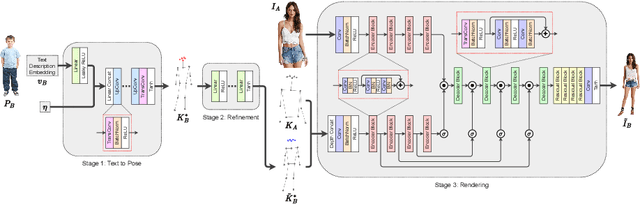
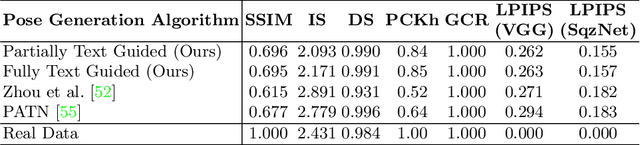
In computer vision, human pose synthesis and transfer deal with probabilistic image generation of a person in a previously unseen pose from an already available observation of that person. Though researchers have recently proposed several methods to achieve this task, most of these techniques derive the target pose directly from the desired target image on a specific dataset, making the underlying process challenging to apply in real-world scenarios as the generation of the target image is the actual aim. In this paper, we first present the shortcomings of current pose transfer algorithms and then propose a novel text-based pose transfer technique to address those issues. We divide the problem into three independent stages: (a) text to pose representation, (b) pose refinement, and (c) pose rendering. To the best of our knowledge, this is one of the first attempts to develop a text-based pose transfer framework where we also introduce a new dataset DF-PASS, by adding descriptive pose annotations for the images of the DeepFashion dataset. The proposed method generates promising results with significant qualitative and quantitative scores in our experiments.
Cross-Attention Transformer for Video Interpolation
Jul 08, 2022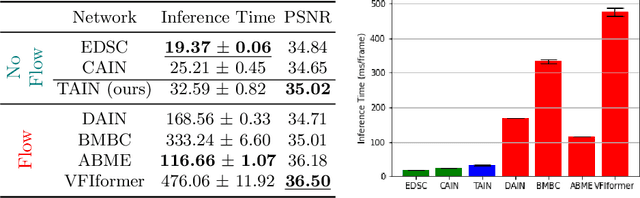
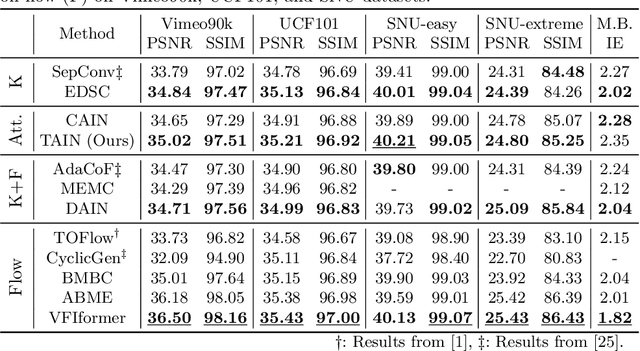
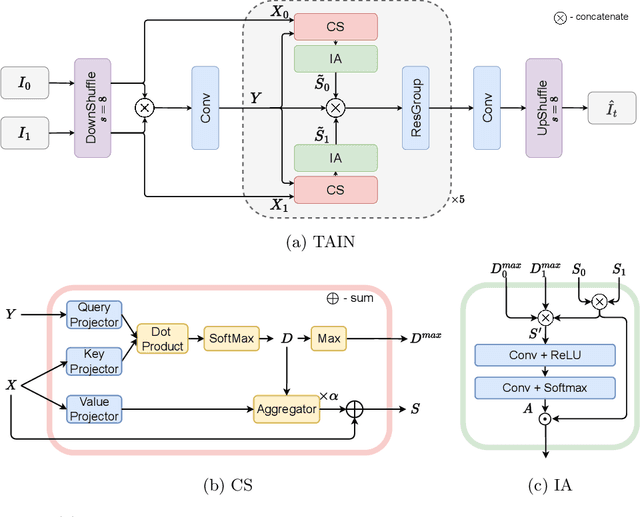
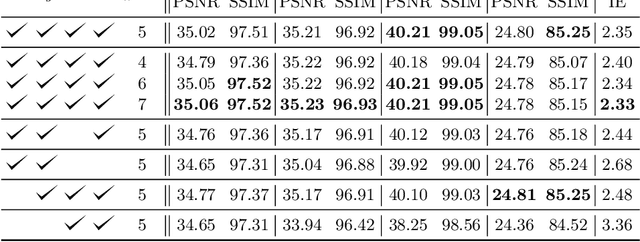
We propose TAIN (Transformers and Attention for video INterpolation), a residual neural network for video interpolation, which aims to interpolate an intermediate frame given two consecutive image frames around it. We first present a novel visual transformer module, named Cross-Similarity (CS), to globally aggregate input image features with similar appearance as those of the predicted interpolated frame. These CS features are then used to refine the interpolated prediction. To account for occlusions in the CS features, we propose an Image Attention (IA) module to allow the network to focus on CS features from one frame over those of the other. Additionally, we augment our training dataset with an occluder patch that moves across frames to improve the network's robustness to occlusions and large motion. Because existing methods yield smooth predictions especially near MBs, we use an additional training loss based on image gradient to yield sharper predictions. TAIN outperforms existing methods that do not require flow estimation and performs comparably to flow-based methods while being computationally efficient in terms of inference time on Vimeo90k, UCF101, and SNU-FILM benchmarks.
Poisson Flow Generative Models
Sep 22, 2022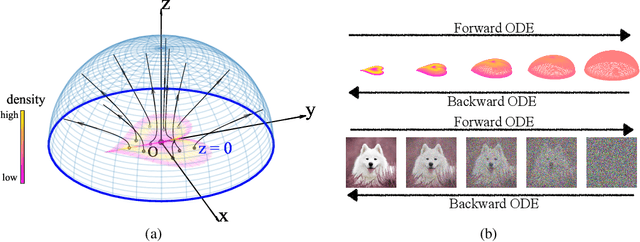
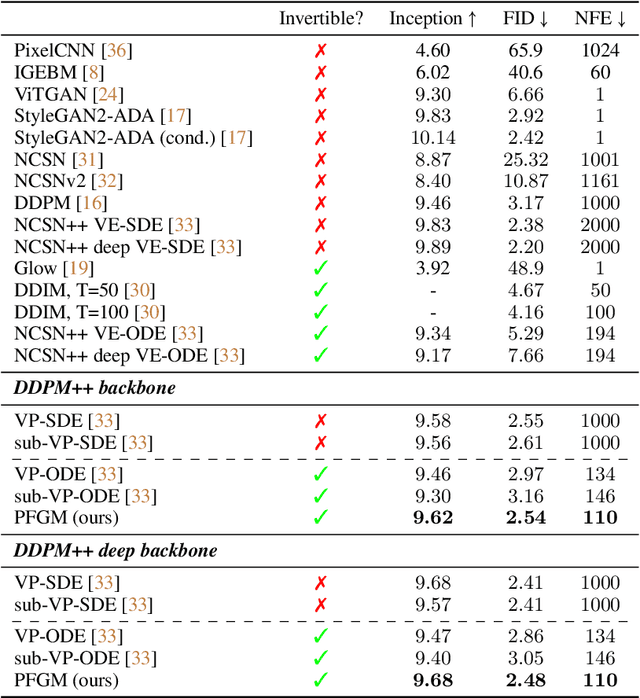
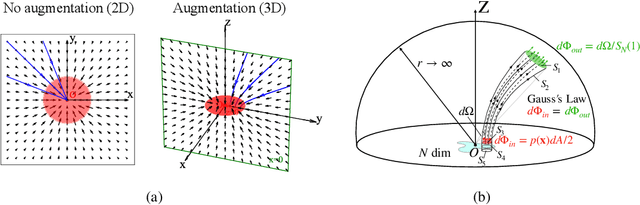

We propose a new "Poisson flow" generative model (PFGM) that maps a uniform distribution on a high-dimensional hemisphere into any data distribution. We interpret the data points as electrical charges on the $z=0$ hyperplane in a space augmented with an additional dimension $z$, generating a high-dimensional electric field (the gradient of the solution to Poisson equation). We prove that if these charges flow upward along electric field lines, their initial distribution in the $z=0$ plane transforms into a distribution on the hemisphere of radius $r$ that becomes uniform in the $r \to\infty$ limit. To learn the bijective transformation, we estimate the normalized field in the augmented space. For sampling, we devise a backward ODE that is anchored by the physically meaningful additional dimension: the samples hit the unaugmented data manifold when the $z$ reaches zero. Experimentally, PFGM achieves current state-of-the-art performance among the normalizing flow models on CIFAR-10, with an Inception score of $9.68$ and a FID score of $2.48$. It also performs on par with the state-of-the-art SDE approaches while offering $10\times $ to $20 \times$ acceleration on image generation tasks. Additionally, PFGM appears more tolerant of estimation errors on a weaker network architecture and robust to the step size in the Euler method. The code is available at https://github.com/Newbeeer/poisson_flow .