 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Object-Attentional Untargeted Adversarial Attack
Oct 16, 2022


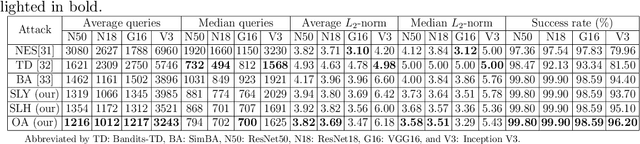
Deep neural networks are facing severe threats from adversarial attacks. Most existing black-box attacks fool target model by generating either global perturbations or local patches. However, both global perturbations and local patches easily cause annoying visual artifacts in adversarial example. Compared with some smooth regions of an image, the object region generally has more edges and a more complex texture. Thus small perturbations on it will be more imperceptible. On the other hand, the object region is undoubtfully the decisive part of an image to classification tasks. Motivated by these two facts, we propose an object-attentional adversarial attack method for untargeted attack. Specifically, we first generate an object region by intersecting the object detection region from YOLOv4 with the salient object detection (SOD) region from HVPNet. Furthermore, we design an activation strategy to avoid the reaction caused by the incomplete SOD. Then, we perform an adversarial attack only on the detected object region by leveraging Simple Black-box Adversarial Attack (SimBA). To verify the proposed method, we create a unique dataset by extracting all the images containing the object defined by COCO from ImageNet-1K, named COCO-Reduced-ImageNet in this paper. Experimental results on ImageNet-1K and COCO-Reduced-ImageNet show that under various system settings, our method yields the adversarial example with better perceptual quality meanwhile saving the query budget up to 24.16\% compared to the state-of-the-art approaches including SimBA.
A novel GAN-based paradigm for weakly supervised brain tumor segmentation of MR images
Nov 10, 2022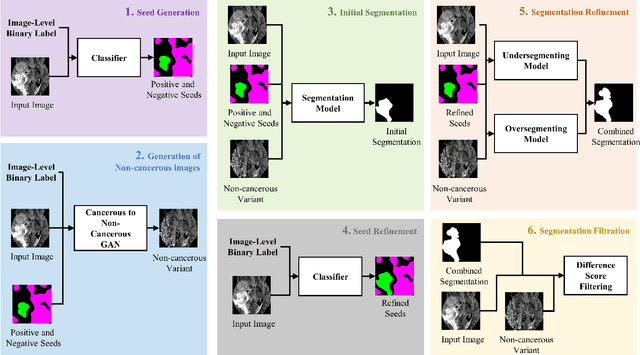
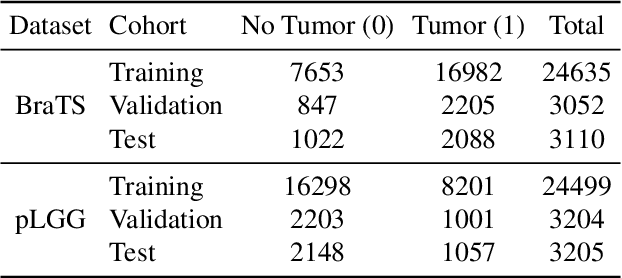
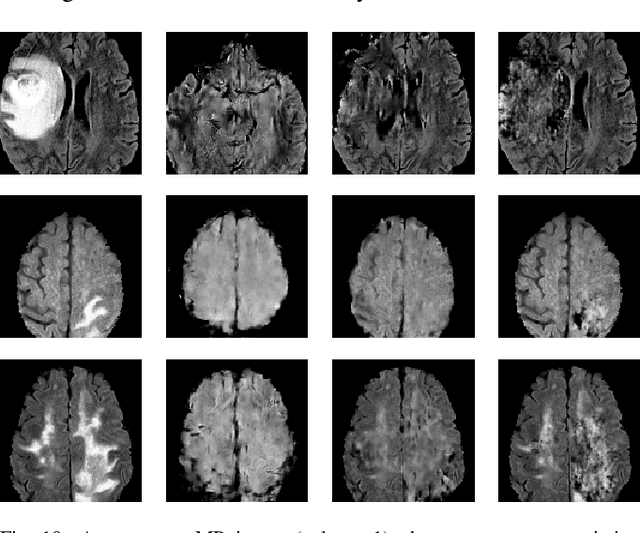
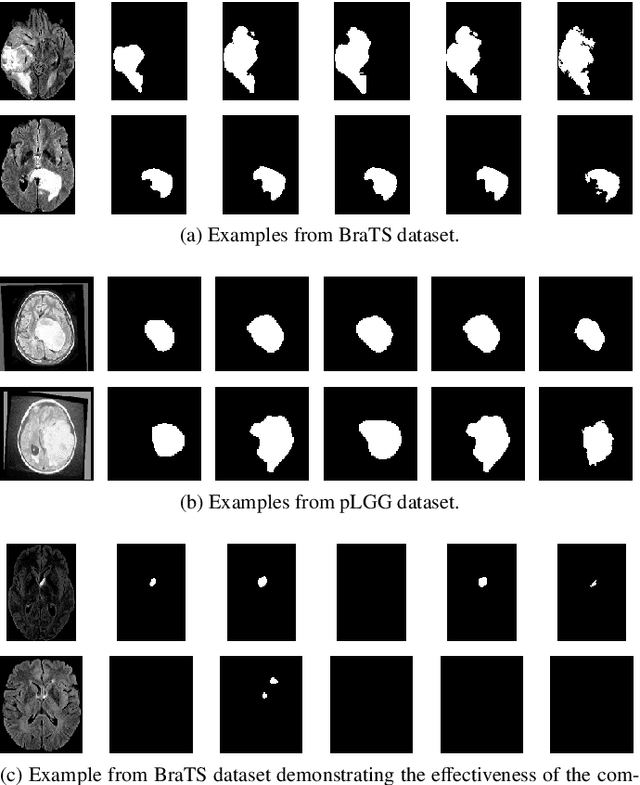
Segmentation of regions of interest (ROIs) for identifying abnormalities is a leading problem in medical imaging. Using Machine Learning (ML) for this problem generally requires manually annotated ground-truth segmentations, demanding extensive time and resources from radiologists. This work presents a novel weakly supervised approach that utilizes binary image-level labels, which are much simpler to acquire, to effectively segment anomalies in medical Magnetic Resonance (MR) images without ground truth annotations. We train a binary classifier using these labels and use it to derive seeds indicating regions likely and unlikely to contain tumors. These seeds are used to train a generative adversarial network (GAN) that converts cancerous images to healthy variants, which are then used in conjunction with the seeds to train a ML model that generates effective segmentations. This method produces segmentations that achieve Dice coefficients of 0.7903, 0.7868, and 0.7712 on the MICCAI Brain Tumor Segmentation (BraTS) 2020 dataset for the training, validation, and test cohorts respectively. We also propose a weakly supervised means of filtering the segmentations, removing a small subset of poorer segmentations to acquire a large subset of high quality segmentations. The proposed filtering further improves the Dice coefficients to up to 0.8374, 0.8232, and 0.8136 for training, validation, and test, respectively.
Near-infrared and visible-light periocular recognition with Gabor features using frequency-adaptive automatic eye detection
Nov 10, 2022
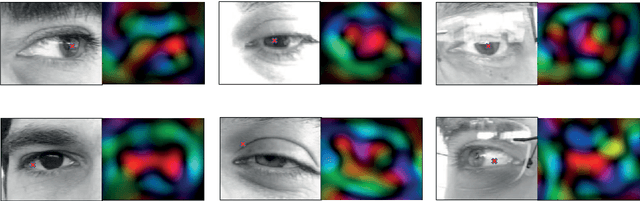

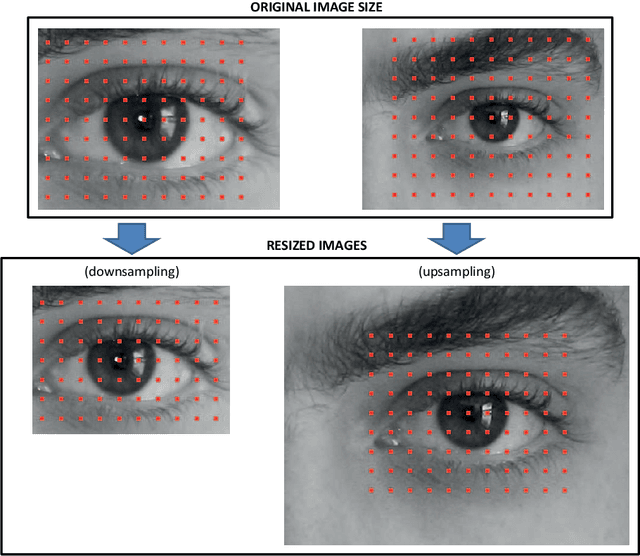
Periocular recognition has gained attention recently due to demands of increased robustness of face or iris in less controlled scenarios. We present a new system for eye detection based on complex symmetry filters, which has the advantage of not needing training. Also, separability of the filters allows faster detection via one-dimensional convolutions. This system is used as input to a periocular algorithm based on retinotopic sampling grids and Gabor spectrum decomposition. The evaluation framework is composed of six databases acquired both with near-infrared and visible sensors. The experimental setup is complemented with four iris matchers, used for fusion experiments. The eye detection system presented shows very high accuracy with near-infrared data, and a reasonable good accuracy with one visible database. Regarding the periocular system, it exhibits great robustness to small errors in locating the eye centre, as well as to scale changes of the input image. The density of the sampling grid can also be reduced without sacrificing accuracy. Lastly, despite the poorer performance of the iris matchers with visible data, fusion with the periocular system can provide an improvement of more than 20%. The six databases used have been manually annotated, with the annotation made publicly available.
Zero-Reference Image Restoration for Under-Display Camera of UAV
Feb 13, 2022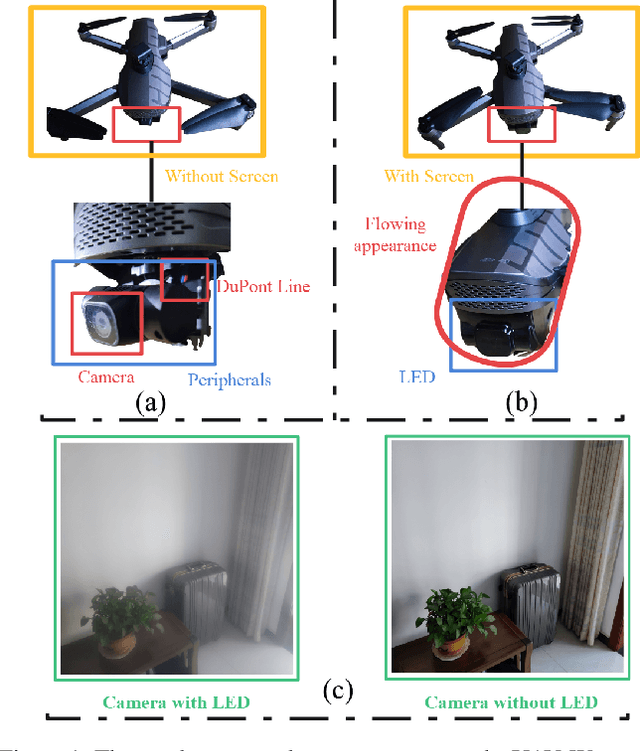
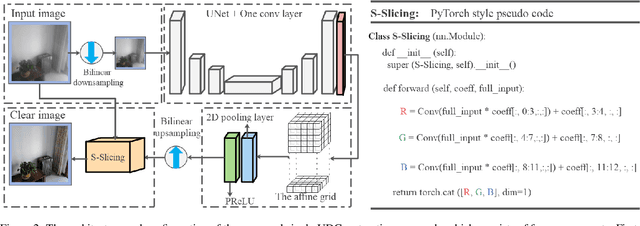


The exposed cameras of UAV can shake, shift, or even malfunction under the influence of harsh weather, while the add-on devices (Dupont lines) are very vulnerable to damage. We can place a low-cost T-OLED overlay around the camera to protect it, but this would also introduce image degradation issues. In particular, the temperature variations in the atmosphere can create mist that adsorbs to the T-OLED, which can cause secondary disasters (i.e., more severe image degradation) during the UAV's filming process. To solve the image degradation problem caused by overlaying T-OLEDs, in this paper we propose a new method to enhance the visual experience by enhancing the texture and color of images. Specifically, our method trains a lightweight network to estimate a low-rank affine grid on the input image, and then utilizes the grid to enhance the input image at block granularity. The advantages of our method are that no reference image is required and the loss function is developed from visual experience. In addition, our model can perform high-quality recovery of images of arbitrary resolution in real time. In the end, the limitations of our model and the collected datasets (including the daytime and nighttime scenes) are discussed.
Deep Learning based Automatic Quantification of Urethral Plate Quality using the Plate Objective Scoring Tool (POST)
Sep 28, 2022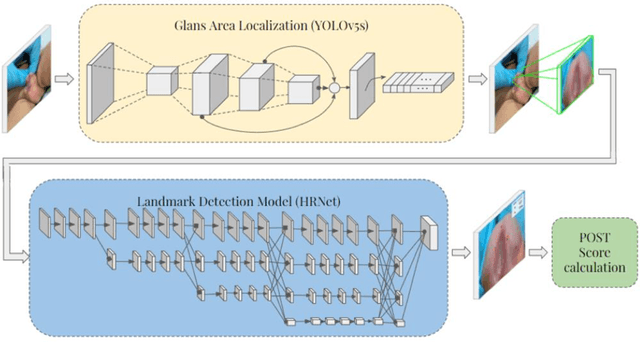
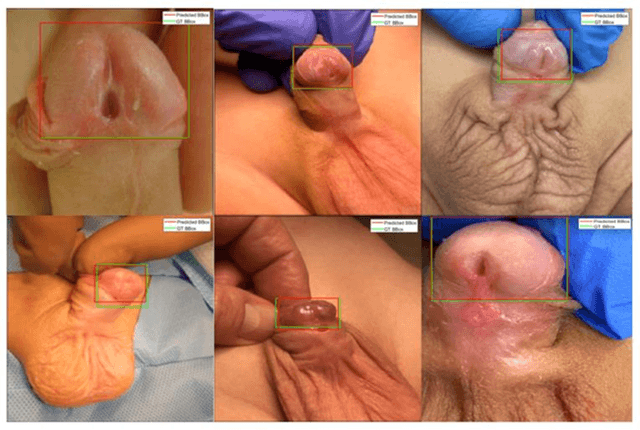
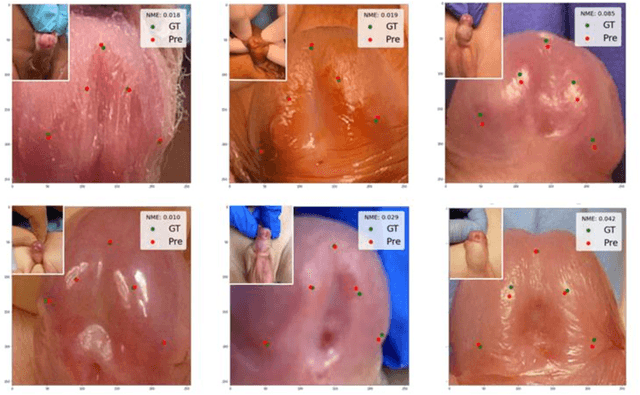
Objectives: To explore the capacity of deep learning algorithm to further streamline and optimize urethral plate (UP) quality appraisal on 2D images using the plate objective scoring tool (POST), aiming to increase the objectivity and reproducibility of UP appraisal in hypospadias repair. Methods: The five key POST landmarks were marked by specialists in a 691-image dataset of prepubertal boys undergoing primary hypospadias repair. This dataset was then used to develop and validate a deep learning-based landmark detection model. The proposed framework begins with glans localization and detection, where the input image is cropped using the predicted bounding box. Next, a deep convolutional neural network (CNN) architecture is used to predict the coordinates of the five POST landmarks. These predicted landmarks are then used to assess UP quality in distal hypospadias. Results: The proposed model accurately localized the glans area, with a mean average precision (mAP) of 99.5% and an overall sensitivity of 99.1%. A normalized mean error (NME) of 0.07152 was achieved in predicting the coordinates of the landmarks, with a mean squared error (MSE) of 0.001 and a 20.2% failure rate at a threshold of 0.1 NME. Conclusions: This deep learning application shows robustness and high precision in using POST to appraise UP quality. Further assessment using international multi-centre image-based databases is ongoing. External validation could benefit deep learning algorithms and lead to better assessments, decision-making and predictions for surgical outcomes.
Leveraging Local Patch Differences in Multi-Object Scenes for Generative Adversarial Attacks
Sep 20, 2022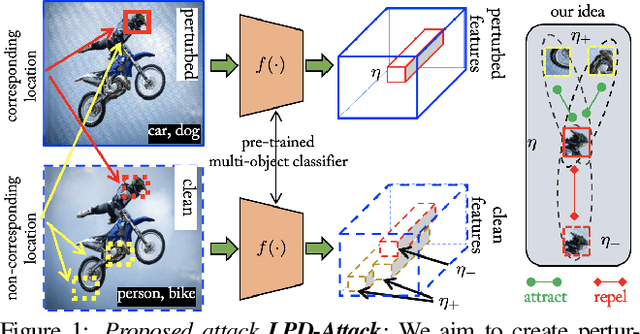

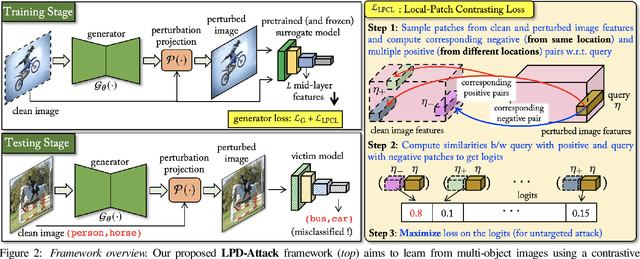
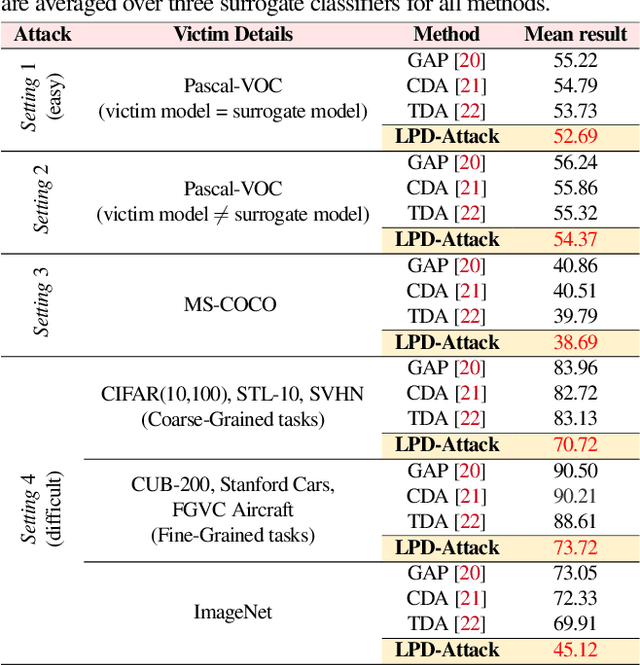
State-of-the-art generative model-based attacks against image classifiers overwhelmingly focus on single-object (i.e., single dominant object) images. Different from such settings, we tackle a more practical problem of generating adversarial perturbations using multi-object (i.e., multiple dominant objects) images as they are representative of most real-world scenes. Our goal is to design an attack strategy that can learn from such natural scenes by leveraging the local patch differences that occur inherently in such images (e.g. difference between the local patch on the object `person' and the object `bike' in a traffic scene). Our key idea is: to misclassify an adversarial multi-object image, each local patch in the image should confuse the victim classifier. Based on this, we propose a novel generative attack (called Local Patch Difference or LPD-Attack) where a novel contrastive loss function uses the aforesaid local differences in feature space of multi-object scenes to optimize the perturbation generator. Through various experiments across diverse victim convolutional neural networks, we show that our approach outperforms baseline generative attacks with highly transferable perturbations when evaluated under different white-box and black-box settings.
Modular Degradation Simulation and Restoration for Under-Display Camera
Sep 23, 2022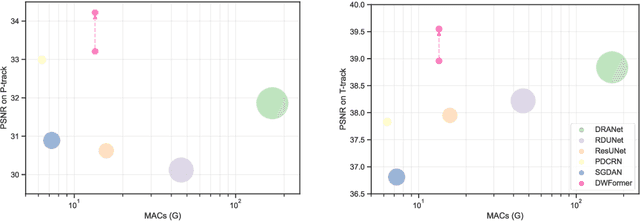
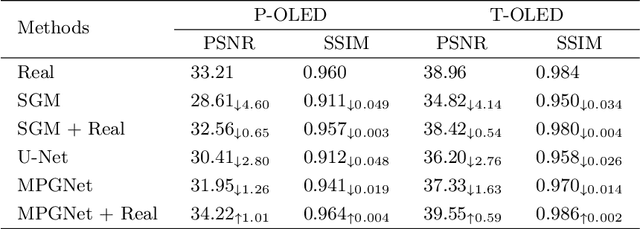
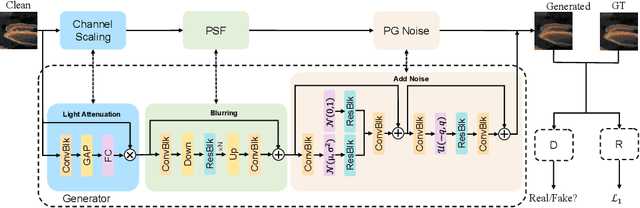
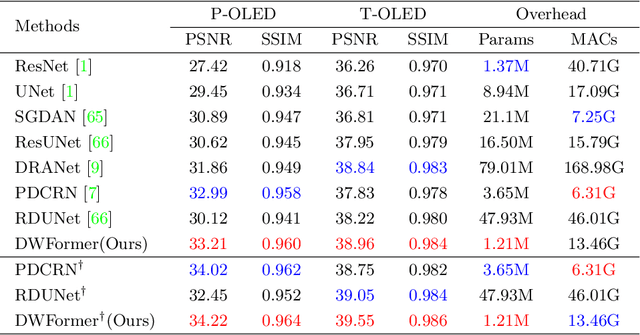
Under-display camera (UDC) provides an elegant solution for full-screen smartphones. However, UDC captured images suffer from severe degradation since sensors lie under the display. Although this issue can be tackled by image restoration networks, these networks require large-scale image pairs for training. To this end, we propose a modular network dubbed MPGNet trained using the generative adversarial network (GAN) framework for simulating UDC imaging. Specifically, we note that the UDC imaging degradation process contains brightness attenuation, blurring, and noise corruption. Thus we model each degradation with a characteristic-related modular network, and all modular networks are cascaded to form the generator. Together with a pixel-wise discriminator and supervised loss, we can train the generator to simulate the UDC imaging degradation process. Furthermore, we present a Transformer-style network named DWFormer for UDC image restoration. For practical purposes, we use depth-wise convolution instead of the multi-head self-attention to aggregate local spatial information. Moreover, we propose a novel channel attention module to aggregate global information, which is critical for brightness recovery. We conduct evaluations on the UDC benchmark, and our method surpasses the previous state-of-the-art models by 1.23 dB on the P-OLED track and 0.71 dB on the T-OLED track, respectively.
Stereo Unstructured Magnification: Multiple Homography Image for View Synthesis
Apr 01, 2022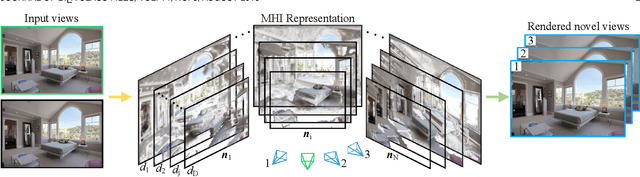
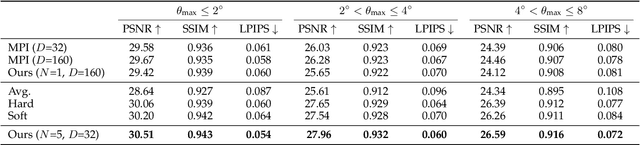
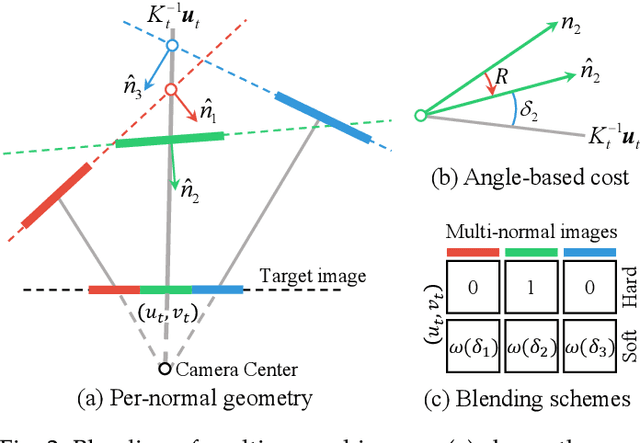
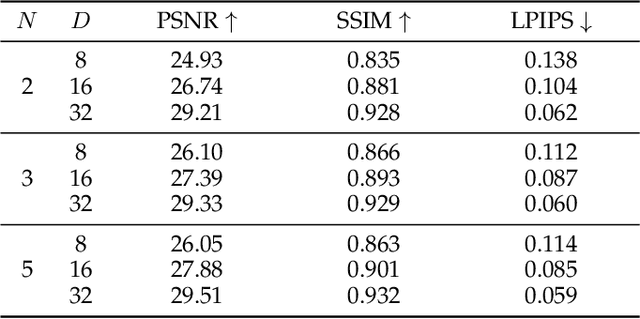
This paper studies the problem of view synthesis with certain amount of rotations from a pair of images, what we called stereo unstructured magnification. While the multi-plane image representation is well suited for view synthesis with depth invariant, how to generalize it to unstructured views remains a significant challenge. This is primarily due to the depth-dependency caused by camera frontal parallel representation. Here we propose a novel multiple homography image (MHI) representation, comprising of a set of scene planes with fixed normals and distances. A two-stage network is developed for novel view synthesis. Stage-1 is an MHI reconstruction module that predicts the MHIs and composites layered multi-normal images along the normal direction. Stage-2 is a normal-blending module to find blending weights. We also derive an angle-based cost to guide the blending of multi-normal images by exploiting per-normal geometry. Compared with the state-of-the-art methods, our method achieves superior performance for view synthesis qualitatively and quantitatively, especially for cases when the cameras undergo rotations.
Can neural networks extrapolate? Discussion of a theorem by Pedro Domingos
Nov 07, 2022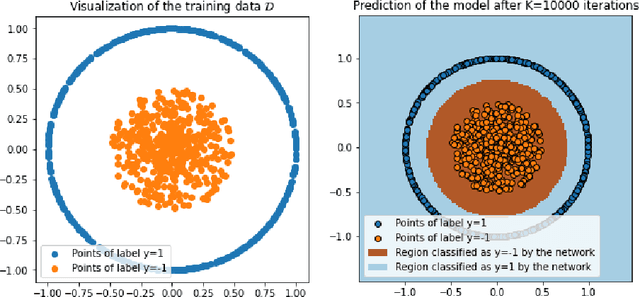
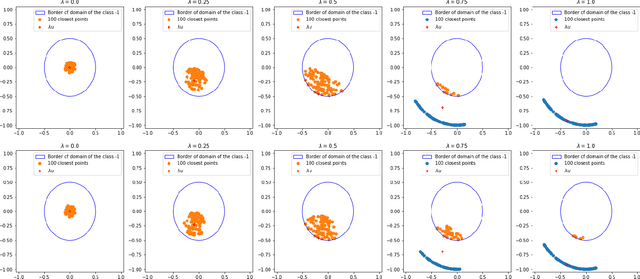
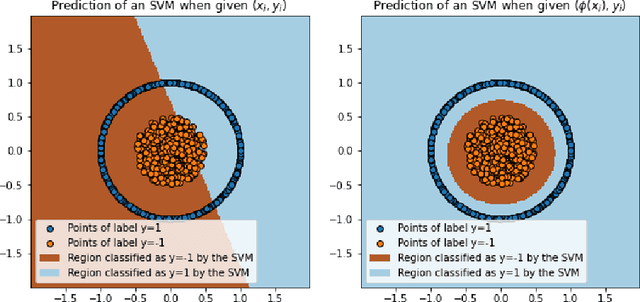
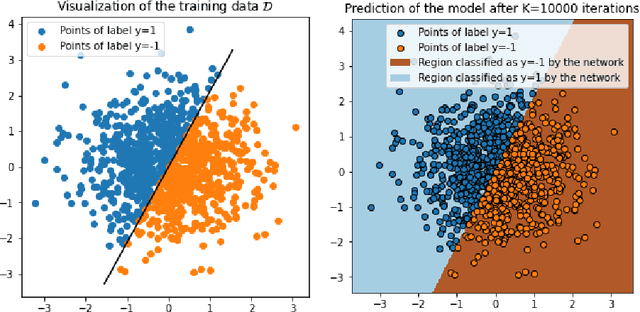
Neural networks trained on large datasets by minimizing a loss have become the state-of-the-art approach for resolving data science problems, particularly in computer vision, image processing and natural language processing. In spite of their striking results, our theoretical understanding about how neural networks operate is limited. In particular, what are the interpolation capabilities of trained neural networks? In this paper we discuss a theorem of Domingos stating that "every machine learned by continuous gradient descent is approximately a kernel machine". According to Domingos, this fact leads to conclude that all machines trained on data are mere kernel machines. We first extend Domingo's result in the discrete case and to networks with vector-valued output. We then study its relevance and significance on simple examples. We find that in simple cases, the "neural tangent kernel" arising in Domingos' theorem does provide understanding of the networks' predictions. Furthermore, when the task given to the network grows in complexity, the interpolation capability of the network can be effectively explained by Domingos' theorem, and therefore is limited. We illustrate this fact on a classic perception theory problem: recovering a shape from its boundary.
3D Harmonic Loss: Towards Task-consistent and Time-friendly 3D Object Detection on Edge for Intelligent Transportation System
Nov 07, 2022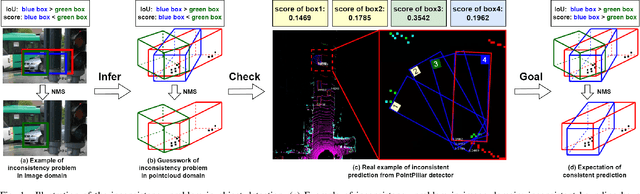

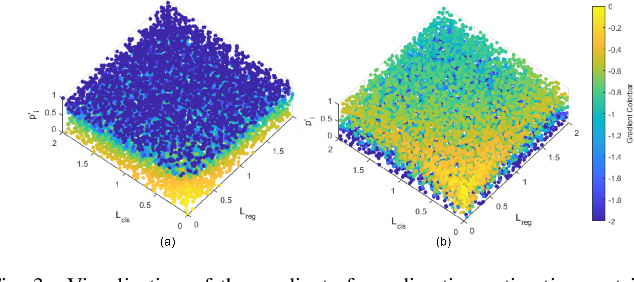
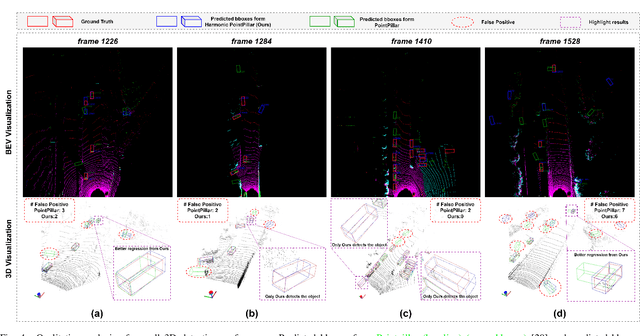
Edge computing-based 3D perception has received attention in intelligent transportation systems (ITS) because real-time monitoring of traffic candidates potentially strengthens Vehicle-to-Everything (V2X) orchestration. Thanks to the capability of precisely measuring the depth information on surroundings from LiDAR, the increasing studies focus on lidar-based 3D detection, which significantly promotes the development of 3D perception. Few methods met the real-time requirement of edge deployment because of high computation-intensive operations. Moreover, an inconsistency problem of object detection remains uncovered in the pointcloud domain due to large sparsity. This paper thoroughly analyses this problem, comprehensively roused by recent works on determining inconsistency problems in the image specialisation. Therefore, we proposed a 3D harmonic loss function to relieve the pointcloud based inconsistent predictions. Moreover, the feasibility of 3D harmonic loss is demonstrated from a mathematical optimization perspective. The KITTI dataset and DAIR-V2X-I dataset are used for simulations, and our proposed method considerably improves the performance than benchmark models. Further, the simulative deployment on an edge device (Jetson Xavier TX) validates our proposed model's efficiency. Our code is open-source and publicly available.