 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Discriminative Kernel Convolution Network for Multi-Label Ophthalmic Disease Detection on Imbalanced Fundus Image Dataset
Jul 16, 2022
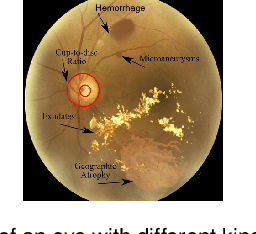
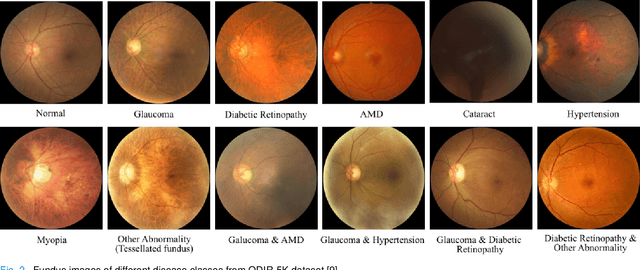

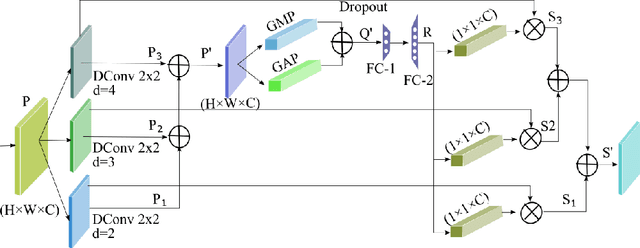
It is feasible to recognize the presence and seriousness of eye disease by investigating the progressions in retinal biological structure. Fundus examination is a diagnostic procedure to examine the biological structure and anomaly of the eye. Ophthalmic diseases like glaucoma, diabetic retinopathy, and cataract are the main reason for visual impairment around the world. Ocular Disease Intelligent Recognition (ODIR-5K) is a benchmark structured fundus image dataset utilized by researchers for multi-label multi-disease classification of fundus images. This work presents a discriminative kernel convolution network (DKCNet), which explores discriminative region-wise features without adding extra computational cost. DKCNet is composed of an attention block followed by a squeeze and excitation (SE) block. The attention block takes features from the backbone network and generates discriminative feature attention maps. The SE block takes the discriminative feature maps and improves channel interdependencies. Better performance of DKCNet is observed with InceptionResnet backbone network for multi-label classification of ODIR-5K fundus images with 96.08 AUC, 94.28 F1-score and 0.81 kappa score. The proposed method splits the common target label for an eye pair based on the diagnostic keyword. Based on these labels oversampling and undersampling is done to resolve class imbalance. To check the biasness of proposed model towards training data, the model trained on ODIR dataset is tested on three publicly available benchmark datasets. It is found to give good performance on completely unseen fundus images also.
A Guide to Image and Video based Small Object Detection using Deep Learning : Case Study of Maritime Surveillance
Jul 26, 2022
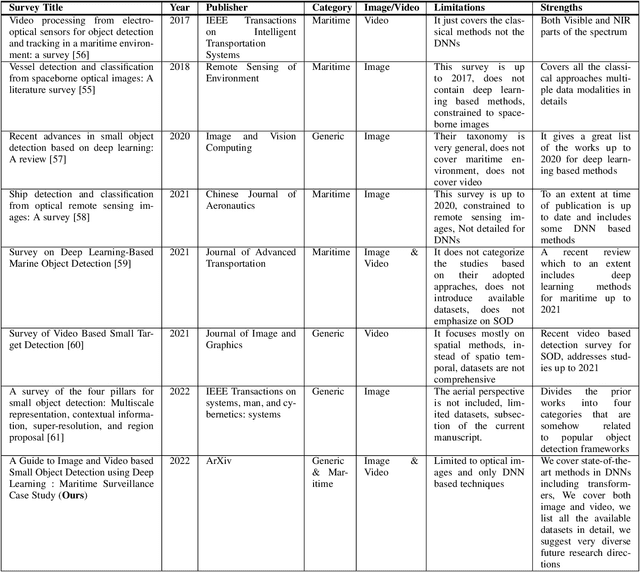
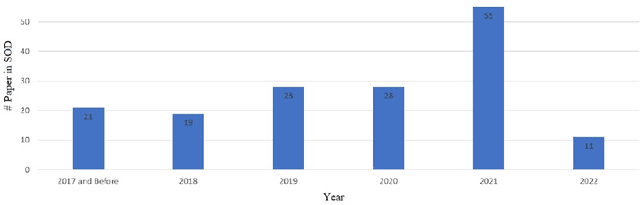
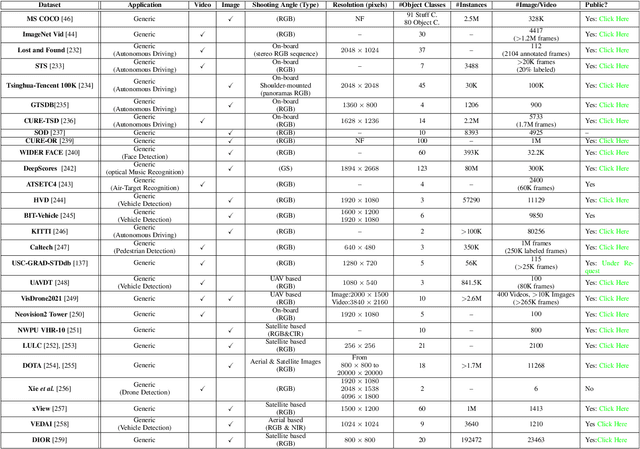
Small object detection (SOD) in optical images and videos is a challenging problem that even state-of-the-art generic object detection methods fail to accurately localize and identify such objects. Typically, small objects appear in real-world due to large camera-object distance. Because small objects occupy only a small area in the input image (e.g., less than 10%), the information extracted from such a small area is not always rich enough to support decision making. Multidisciplinary strategies are being developed by researchers working at the interface of deep learning and computer vision to enhance the performance of SOD deep learning based methods. In this paper, we provide a comprehensive review of over 160 research papers published between 2017 and 2022 in order to survey this growing subject. This paper summarizes the existing literature and provide a taxonomy that illustrates the broad picture of current research. We investigate how to improve the performance of small object detection in maritime environments, where increasing performance is critical. By establishing a connection between generic and maritime SOD research, future directions have been identified. In addition, the popular datasets that have been used for SOD for generic and maritime applications are discussed, and also well-known evaluation metrics for the state-of-the-art methods on some of the datasets are provided.
A Self-Supervised Descriptor for Image Copy Detection
Feb 21, 2022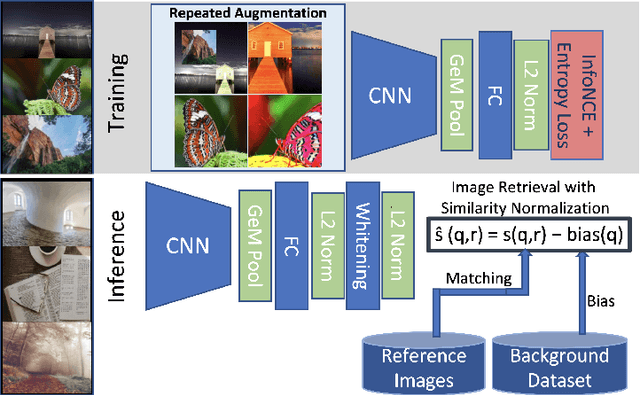


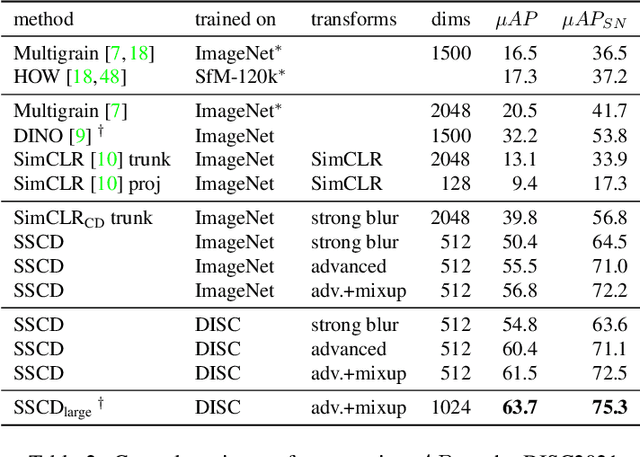
Image copy detection is an important task for content moderation. We introduce SSCD, a model that builds on a recent self-supervised contrastive training objective. We adapt this method to the copy detection task by changing the architecture and training objective, including a pooling operator from the instance matching literature, and adapting contrastive learning to augmentations that combine images. Our approach relies on an entropy regularization term, promoting consistent separation between descriptor vectors, and we demonstrate that this significantly improves copy detection accuracy. Our method produces a compact descriptor vector, suitable for real-world web scale applications. Statistical information from a background image distribution can be incorporated into the descriptor. On the recent DISC2021 benchmark, SSCD is shown to outperform both baseline copy detection models and self-supervised architectures designed for image classification by huge margins, in all settings. For example, SSCD out-performs SimCLR descriptors by 48% absolute.
Unsupervised Spatial-spectral Hyperspectral Image Reconstruction and Clustering with Diffusion Geometry
Apr 28, 2022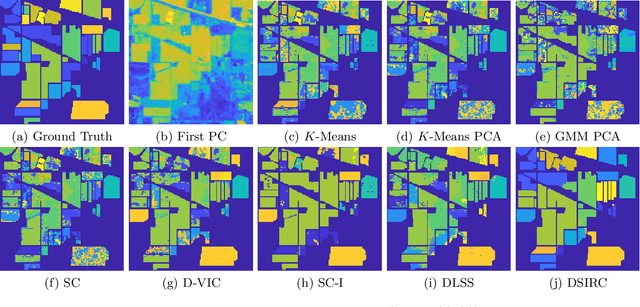
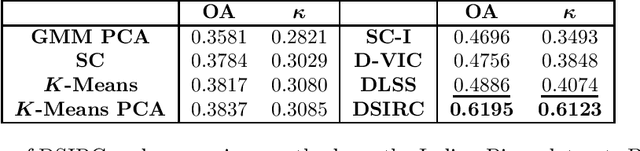
Hyperspectral images, which store a hundred or more spectral bands of reflectance, have become an important data source in natural and social sciences. Hyperspectral images are often generated in large quantities at a relatively coarse spatial resolution. As such, unsupervised machine learning algorithms incorporating known structure in hyperspectral imagery are needed to analyze these images automatically. This work introduces the Spatial-Spectral Image Reconstruction and Clustering with Diffusion Geometry (DSIRC) algorithm for partitioning highly mixed hyperspectral images. DSIRC reduces measurement noise through a shape-adaptive reconstruction procedure. In particular, for each pixel, DSIRC locates spectrally correlated pixels within a data-adaptive spatial neighborhood and reconstructs that pixel's spectral signature using those of its neighbors. DSIRC then locates high-density, high-purity pixels far in diffusion distance (a data-dependent distance metric) from other high-density, high-purity pixels and treats these as cluster exemplars, giving each a unique label. Non-modal pixels are assigned the label of their diffusion distance-nearest neighbor of higher density and purity that is already labeled. Strong numerical results indicate that incorporating spatial information through image reconstruction substantially improves the performance of pixel-wise clustering.
Generation of Anonymous Chest Radiographs Using Latent Diffusion Models for Training Thoracic Abnormality Classification Systems
Nov 04, 2022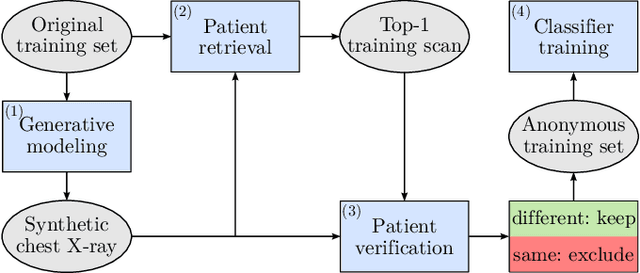
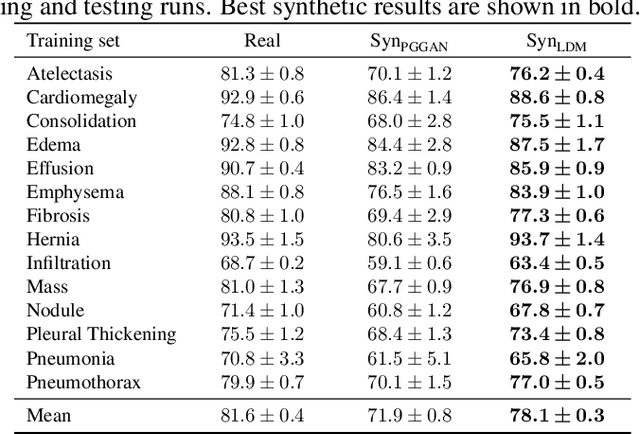
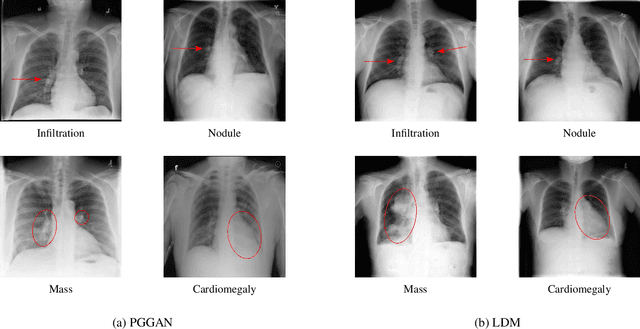
The availability of large-scale chest X-ray datasets is a requirement for developing well-performing deep learning-based algorithms in thoracic abnormality detection and classification. However, biometric identifiers in chest radiographs hinder the public sharing of such data for research purposes due to the risk of patient re-identification. To counteract this issue, synthetic data generation offers a solution for anonymizing medical images. This work employs a latent diffusion model to synthesize an anonymous chest X-ray dataset of high-quality class-conditional images. We propose a privacy-enhancing sampling strategy to ensure the non-transference of biometric information during the image generation process. The quality of the generated images and the feasibility of serving as exclusive training data are evaluated on a thoracic abnormality classification task. Compared to a real classifier, we achieve competitive results with a performance gap of only 3.5% in the area under the receiver operating characteristic curve.
Masked Reconstruction Contrastive Learning with Information Bottleneck Principle
Nov 15, 2022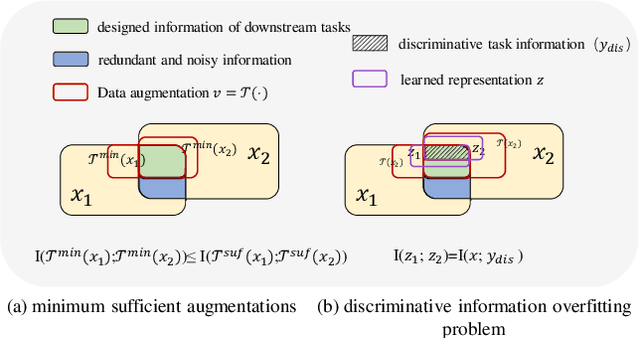
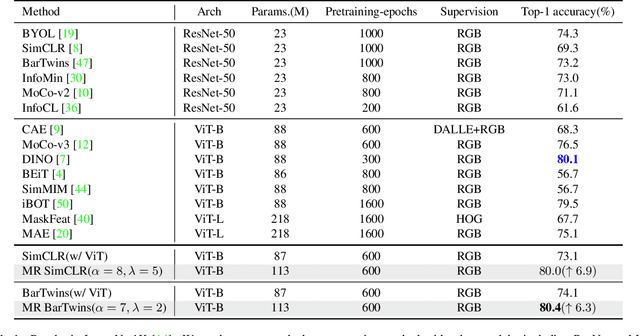
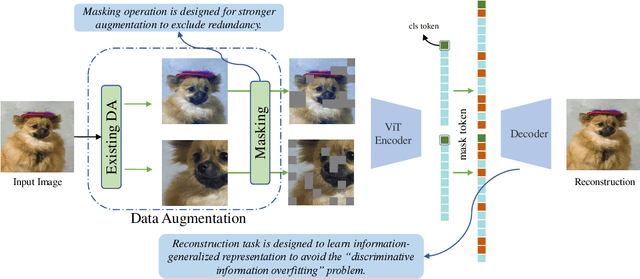
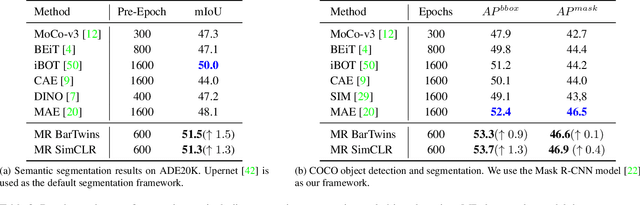
Contrastive learning (CL) has shown great power in self-supervised learning due to its ability to capture insight correlations among large-scale data. Current CL models are biased to learn only the ability to discriminate positive and negative pairs due to the discriminative task setting. However, this bias would lead to ignoring its sufficiency for other downstream tasks, which we call the discriminative information overfitting problem. In this paper, we propose to tackle the above problems from the aspect of the Information Bottleneck (IB) principle, further pushing forward the frontier of CL. Specifically, we present a new perspective that CL is an instantiation of the IB principle, including information compression and expression. We theoretically analyze the optimal information situation and demonstrate that minimum sufficient augmentation and information-generalized representation are the optimal requirements for achieving maximum compression and generalizability to downstream tasks. Therefore, we propose the Masked Reconstruction Contrastive Learning~(MRCL) model to improve CL models. For implementation in practice, MRCL utilizes the masking operation for stronger augmentation, further eliminating redundant and noisy information. In order to alleviate the discriminative information overfitting problem effectively, we employ the reconstruction task to regularize the discriminative task. We conduct comprehensive experiments and show the superiority of the proposed model on multiple tasks, including image classification, semantic segmentation and objective detection.
A Wavelet-based Dual-stream Network for Underwater Image Enhancement
Feb 17, 2022

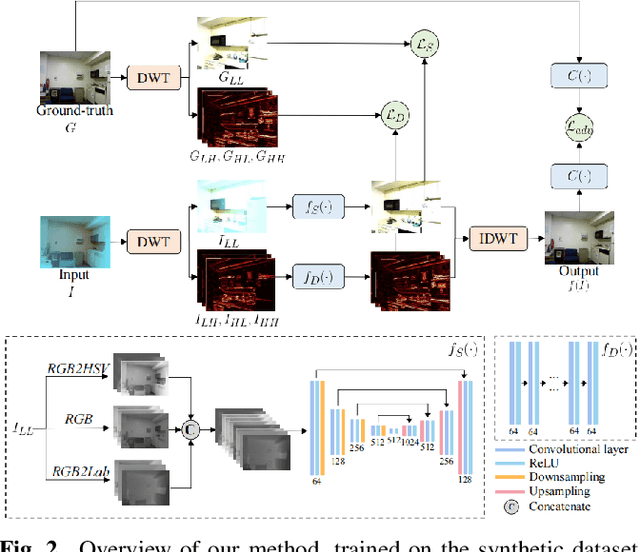
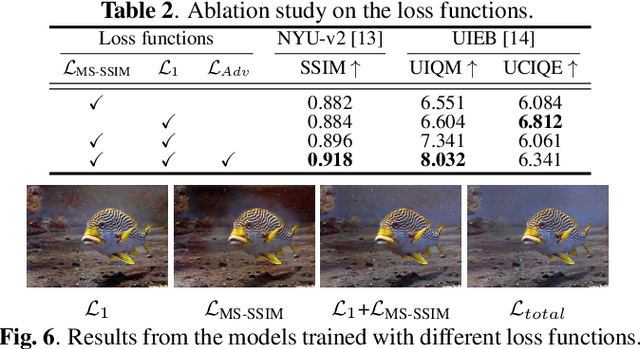
We present a wavelet-based dual-stream network that addresses color cast and blurry details in underwater images. We handle these artifacts separately by decomposing an input image into multiple frequency bands using discrete wavelet transform, which generates the downsampled structure image and detail images. These sub-band images are used as input to our dual-stream network that incorporates two sub-networks: the multi-color space fusion network and the detail enhancement network. The multi-color space fusion network takes the decomposed structure image as input and estimates the color corrected output by employing the feature representations from diverse color spaces of the input. The detail enhancement network addresses the blurriness of the original underwater image by improving the image details from high-frequency sub-bands. We validate the proposed method on both real-world and synthetic underwater datasets and show the effectiveness of our model in color correction and blur removal with low computational complexity.
LapGM: A Multisequence MR Bias Correction and Normalization Model
Sep 27, 2022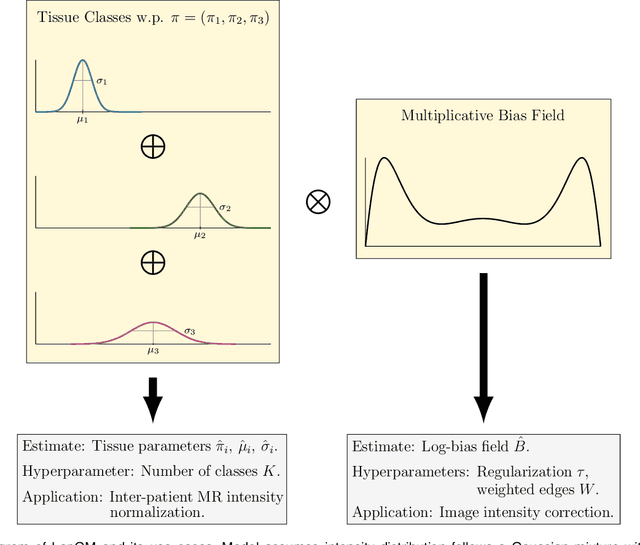
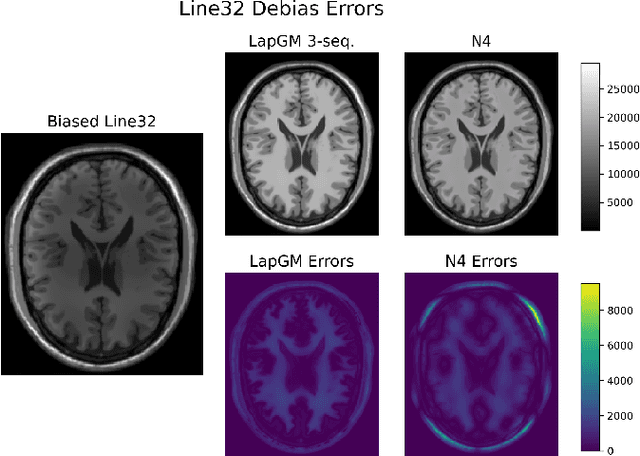
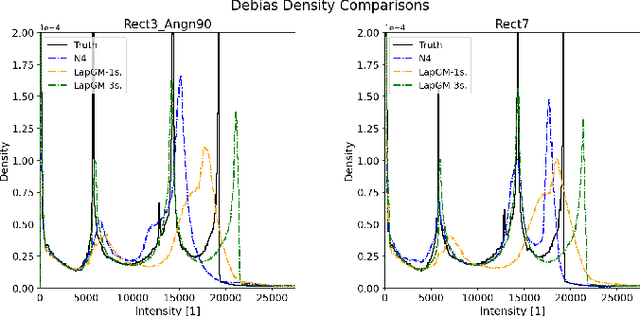
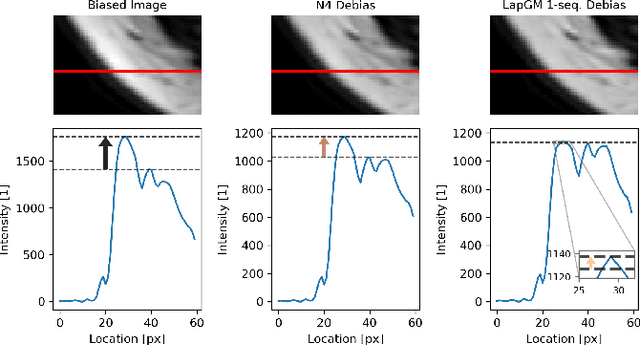
A spatially regularized Gaussian mixture model, LapGM, is proposed for the bias field correction and magnetic resonance normalization problem. The proposed spatial regularizer gives practitioners fine-tuned control between balancing bias field removal and preserving image contrast preservation for multi-sequence, magnetic resonance images. The fitted Gaussian parameters of LapGM serve as control values which can be used to normalize image intensities across different patient scans. LapGM is compared to well-known debiasing algorithm N4ITK in both the single and multi-sequence setting. As a normalization procedure, LapGM is compared to known techniques such as: max normalization, Z-score normalization, and a water-masked region-of-interest normalization. Lastly a CUDA-accelerated Python package $\texttt{lapgm}$ is provided from the authors for use.
Multi-Scale Adaptive Network for Single Image Denoising
Mar 08, 2022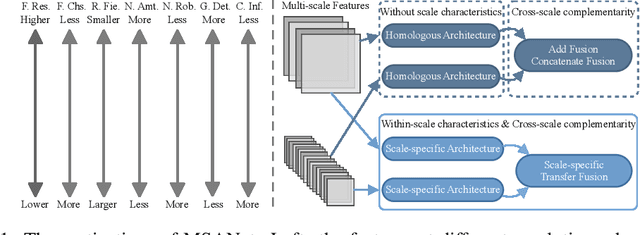
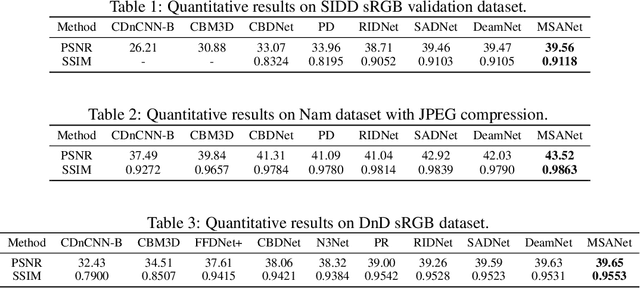
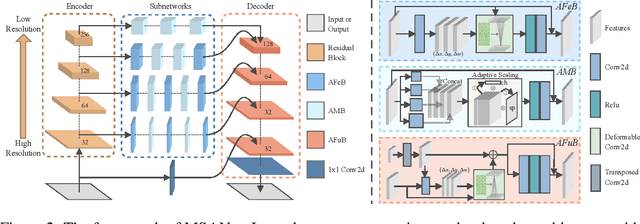

Multi-scale architectures have shown effectiveness in a variety of tasks including single image denoising, thanks to appealing cross-scale complementarity. However, existing methods treat different scale features equally without considering their scale-specific characteristics, i.e., the within-scale characteristics are ignored. In this paper, we reveal this missing piece for multi-scale architecture design and accordingly propose a novel Multi-Scale Adaptive Network (MSANet) for single image denoising. To be specific, MSANet simultaneously embraces the within-scale characteristics and the cross-scale complementarity thanks to three novel neural blocks, i.e., adaptive feature block (AFeB), adaptive multi-scale block (AMB), and adaptive fusion block (AFuB). In brief, AFeB is designed to adaptively select details and filter noises, which is highly expected for fine-grained features. AMB could enlarge the receptive field and aggregate the multi-scale information, which is designed to satisfy the demands of both fine- and coarse-grained features. AFuB devotes to adaptively sampling and transferring the features from one scale to another scale, which is used to fuse the features with varying characteristics from coarse to fine. Extensive experiments on both three real and six synthetic noisy image datasets show the superiority of MSANet compared with 12 methods.
DebiasBench: Benchmark for Fair Comparison of Debiasing in Image Classification
Jun 08, 2022
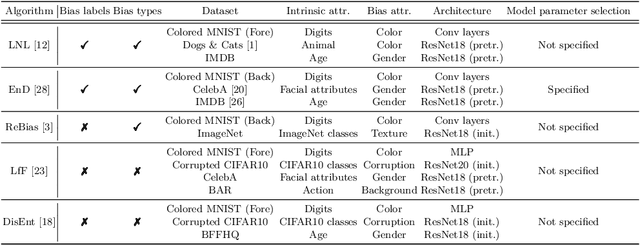
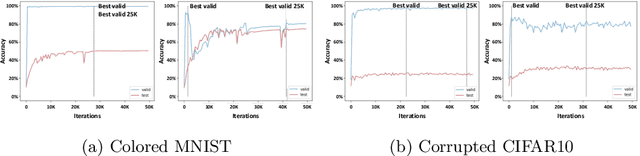
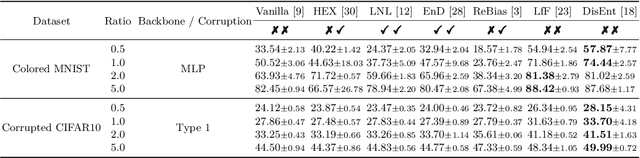
Image classifiers often rely overly on peripheral attributes that have a strong correlation with the target class (i.e., dataset bias) when making predictions. Recently, a myriad of studies focus on mitigating such dataset bias, the task of which is referred to as debiasing. However, these debiasing methods often have inconsistent experimental settings (e.g., datasets and neural network architectures). Additionally, most of the previous studies in debiasing do not specify how they select their model parameters which involve early stopping and hyper-parameter tuning. The goal of this paper is to standardize the inconsistent experimental settings and propose a consistent model parameter selection criterion for debiasing. Based on such unified experimental settings and model parameter selection criterion, we build a benchmark named DebiasBench which includes five datasets and seven debiasing methods. We carefully conduct extensive experiments in various aspects and show that different state-of-the-art methods work best in different datasets, respectively. Even, the vanilla method, the method with no debiasing module, also shows competitive results in datasets with low bias severity. We publicly release the implementation of existing debiasing methods in DebiasBench to encourage future researchers in debiasing to conduct fair comparisons and further push the state-of-the-art performances.