 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Super-Resolution Analysis via Machine Learning: A Survey for Fluid Flows
Jan 26, 2023
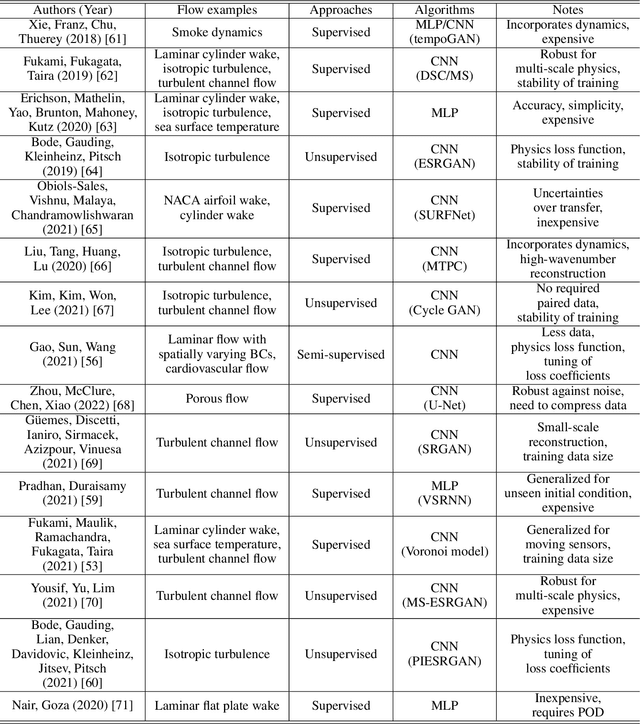
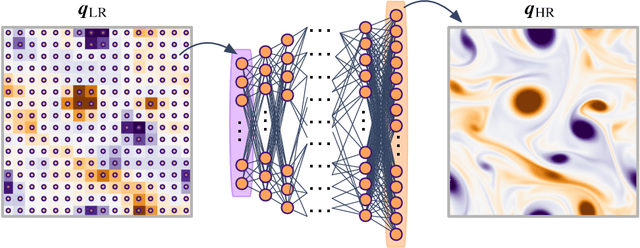
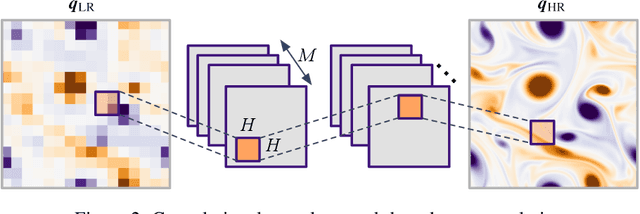
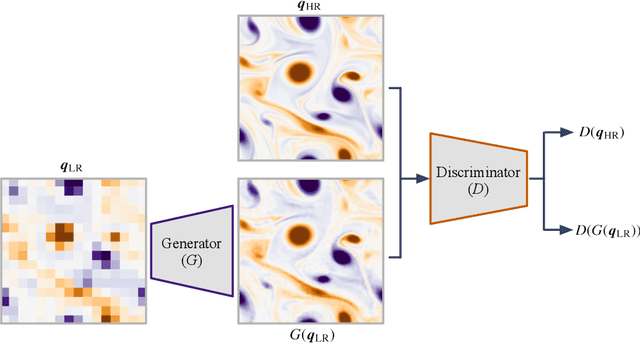
This paper surveys machine-learning-based super-resolution reconstruction for vortical flows. Super resolution aims to find the high-resolution flow fields from low-resolution data and is generally an approach used in image reconstruction. In addition to surveying a variety of recent super-resolution applications, we provide case studies of super-resolution analysis for an example of two-dimensional decaying isotropic turbulence. We demonstrate that physics-inspired model designs enable successful reconstruction of vortical flows from spatially limited measurements. We also discuss the challenges and outlooks of machine-learning-based super-resolution analysis for fluid flow applications. The insights gained from this study can be leveraged for super-resolution analysis of numerical and experimental flow data.
FV-MgNet: Fully Connected V-cycle MgNet for Interpretable Time Series Forecasting
Feb 02, 2023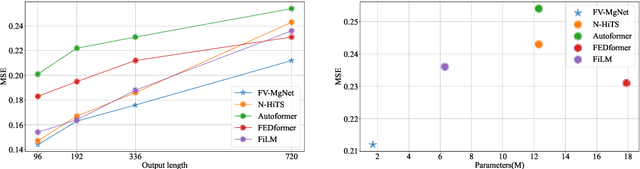
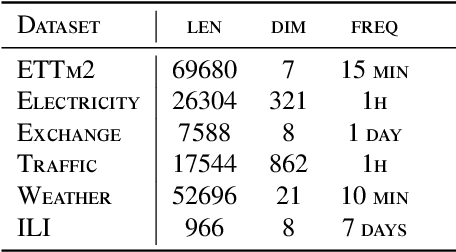
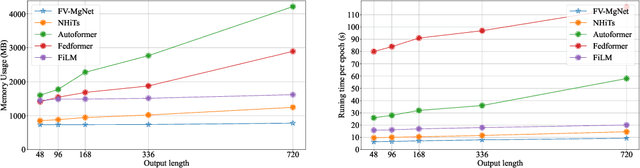
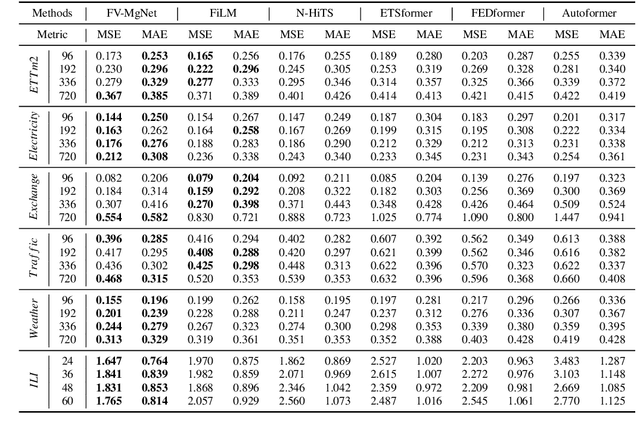
By investigating iterative methods for a constrained linear model, we propose a new class of fully connected V-cycle MgNet for long-term time series forecasting, which is one of the most difficult tasks in forecasting. MgNet is a CNN model that was proposed for image classification based on the multigrid (MG) methods for solving discretized partial differential equations (PDEs). We replace the convolutional operations with fully connected operations in the existing MgNet and then apply them to forecasting problems. Motivated by the V-cycle structure in MG, we further propose the FV-MgNet, a V-cycle version of the fully connected MgNet, to extract features hierarchically. By evaluating the performance of FV-MgNet on popular data sets and comparing it with state-of-the-art models, we show that the FV-MgNet achieves better results with less memory usage and faster inference speed. In addition, we develop ablation experiments to demonstrate that the structure of FV-MgNet is the best choice among the many variants.
Domain Generalization Emerges from Dreaming
Feb 02, 2023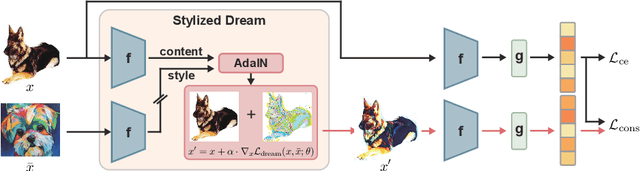
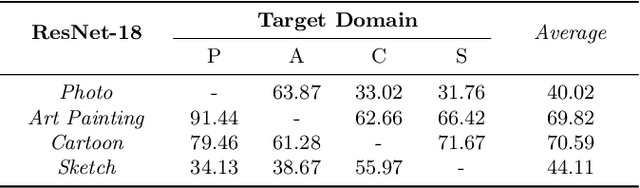

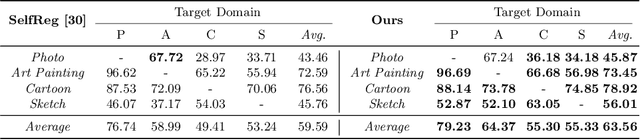
Recent studies have proven that DNNs, unlike human vision, tend to exploit texture information rather than shape. Such texture bias is one of the factors for the poor generalization performance of DNNs. We observe that the texture bias negatively affects not only in-domain generalization but also out-of-distribution generalization, i.e., Domain Generalization. Motivated by the observation, we propose a new framework to reduce the texture bias of a model by a novel optimization-based data augmentation, dubbed Stylized Dream. Our framework utilizes adaptive instance normalization (AdaIN) to augment the style of an original image yet preserve the content. We then adopt a regularization loss to predict consistent outputs between Stylized Dream and original images, which encourages the model to learn shape-based representations. Extensive experiments show that the proposed method achieves state-of-the-art performance in out-of-distribution settings on public benchmark datasets: PACS, VLCS, OfficeHome, TerraIncognita, and DomainNet.
SceneScape: Text-Driven Consistent Scene Generation
Feb 02, 2023
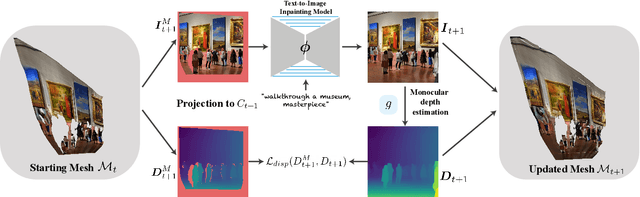

We propose a method for text-driven perpetual view generation -- synthesizing long videos of arbitrary scenes solely from an input text describing the scene and camera poses. We introduce a novel framework that generates such videos in an online fashion by combining the generative power of a pre-trained text-to-image model with the geometric priors learned by a pre-trained monocular depth prediction model. To achieve 3D consistency, i.e., generating videos that depict geometrically-plausible scenes, we deploy an online test-time training to encourage the predicted depth map of the current frame to be geometrically consistent with the synthesized scene; the depth maps are used to construct a unified mesh representation of the scene, which is updated throughout the generation and is used for rendering. In contrast to previous works, which are applicable only for limited domains (e.g., landscapes), our framework generates diverse scenes, such as walkthroughs in spaceships, caves, or ice castles. Project page: https://scenescape.github.io/
Algorithms for Least-Squares Noncartesian MR Image Reconstruction
Dec 13, 2022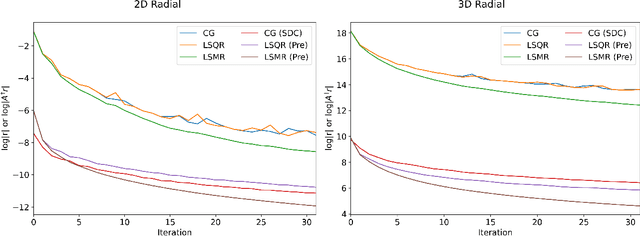
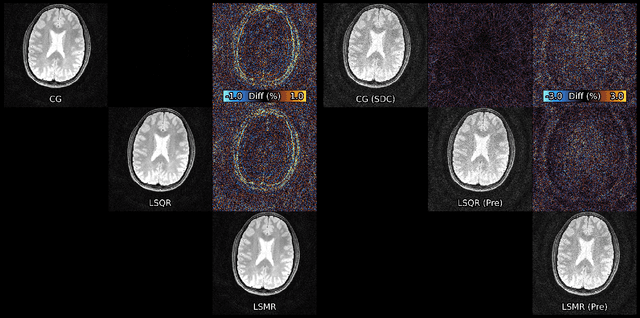
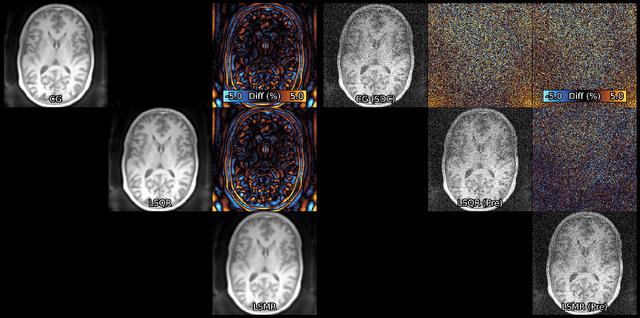
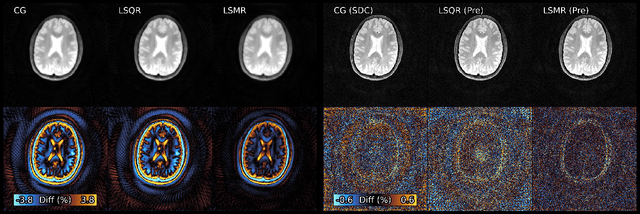
Iterative least-squares MR reconstructions typically use the Conjugate Gradient algorithm, despite known numerical issues. This paper demonstrates that the more recent LSMR algorithm has favourable numerical properties, and is to be preferred in situations where Toeplitz embedding cannot be used to accelerate the Conjugate Gradient method.
XAI based Performance Preserving Adaptive Image Compression for Efficient Satellite Communication
Jul 22, 2022


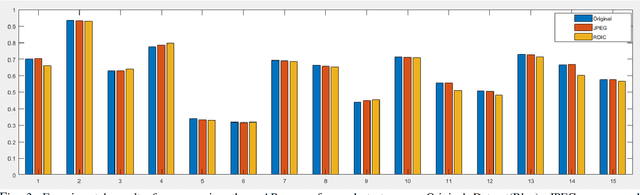
In the era of multinational cooperation, gathering and analyzing the satellite images are getting easier and more important. Typical procedure of the satellite image analysis include transmission of the bulky image data from satellite to the ground producing significant overhead. To reduce the amount of the transmission overhead while making no harm to the analysis result, we propose a novel image compression scheme RDIC in this paper. RDIC is a reasoning based image compression scheme that compresses an image according to the pixel importance score acquired from the analysis model itself. From the experimental results we showed that our RDIC scheme successfully captures the important regions in an image showing high compression rate and low accuracy loss.
Domain-incremental Cardiac Image Segmentation with Style-oriented Replay and Domain-sensitive Feature Whitening
Nov 09, 2022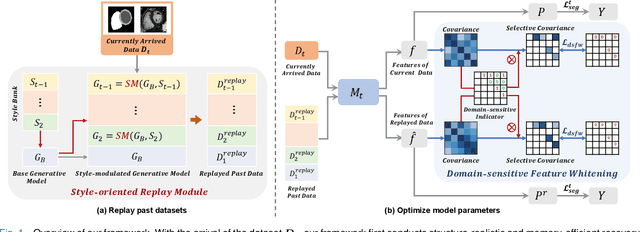
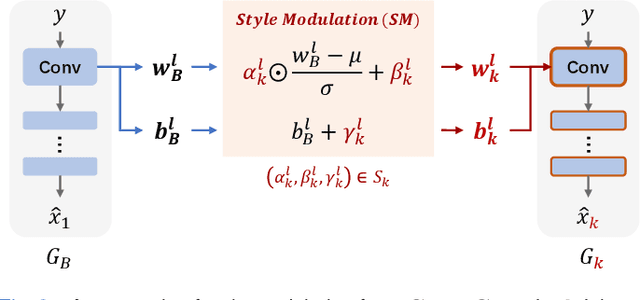
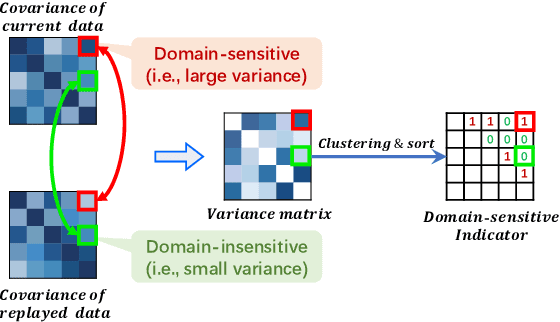
Contemporary methods have shown promising results on cardiac image segmentation, but merely in static learning, i.e., optimizing the network once for all, ignoring potential needs for model updating. In real-world scenarios, new data continues to be gathered from multiple institutions over time and new demands keep growing to pursue more satisfying performance. The desired model should incrementally learn from each incoming dataset and progressively update with improved functionality as time goes by. As the datasets sequentially delivered from multiple sites are normally heterogenous with domain discrepancy, each updated model should not catastrophically forget previously learned domains while well generalizing to currently arrived domains or even unseen domains. In medical scenarios, this is particularly challenging as accessing or storing past data is commonly not allowed due to data privacy. To this end, we propose a novel domain-incremental learning framework to recover past domain inputs first and then regularly replay them during model optimization. Particularly, we first present a style-oriented replay module to enable structure-realistic and memory-efficient reproduction of past data, and then incorporate the replayed past data to jointly optimize the model with current data to alleviate catastrophic forgetting. During optimization, we additionally perform domain-sensitive feature whitening to suppress model's dependency on features that are sensitive to domain changes (e.g., domain-distinctive style features) to assist domain-invariant feature exploration and gradually improve the generalization performance of the network. We have extensively evaluated our approach with the M&Ms Dataset in single-domain and compound-domain incremental learning settings with improved performance over other comparison approaches.
Fast Fourier Convolution Based Remote Sensor Image Object Detection for Earth Observation
Sep 01, 2022
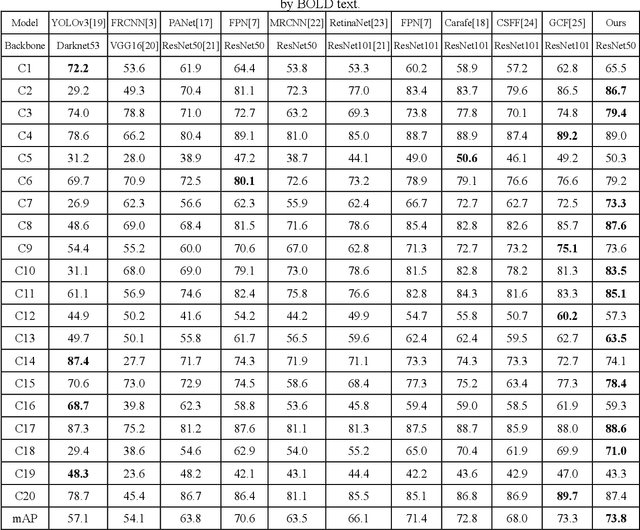
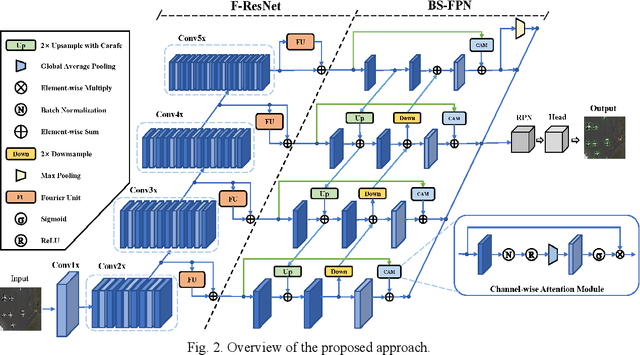

Remote sensor image object detection is an important technology for Earth observation, and is used in various tasks such as forest fire monitoring and ocean monitoring. Image object detection technology, despite the significant developments, is struggling to handle remote sensor images and small-scale objects, due to the limited pixels of small objects. Numerous existing studies have demonstrated that an effective way to promote small object detection is to introduce the spatial context. Meanwhile, recent researches for image classification have shown that spectral convolution operations can perceive long-term spatial dependence more efficiently in the frequency domain than spatial domain. Inspired by this observation, we propose a Frequency-aware Feature Pyramid Framework (FFPF) for remote sensing object detection, which consists of a novel Frequency-aware ResNet (F-ResNet) and a Bilateral Spectral-aware Feature Pyramid Network (BS-FPN). Specifically, the F-ResNet is proposed to perceive the spectral context information by plugging the frequency domain convolution into each stage of the backbone, extracting richer features of small objects. To the best of our knowledge, this is the first work to introduce frequency-domain convolution into remote sensing object detection task. In addition, the BSFPN is designed to use a bilateral sampling strategy and skipping connection to better model the association of object features at different scales, towards unleashing the potential of the spectral context information from F-ResNet. Extensive experiments are conducted for object detection in the optical remote sensing image dataset (DIOR and DOTA). The experimental results demonstrate the excellent performance of our method. It achieves an average accuracy (mAP) without any tricks.
Latent Multi-Relation Reasoning for GAN-Prior based Image Super-Resolution
Aug 04, 2022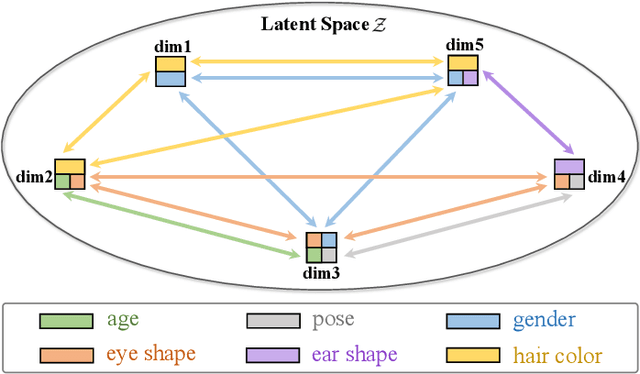
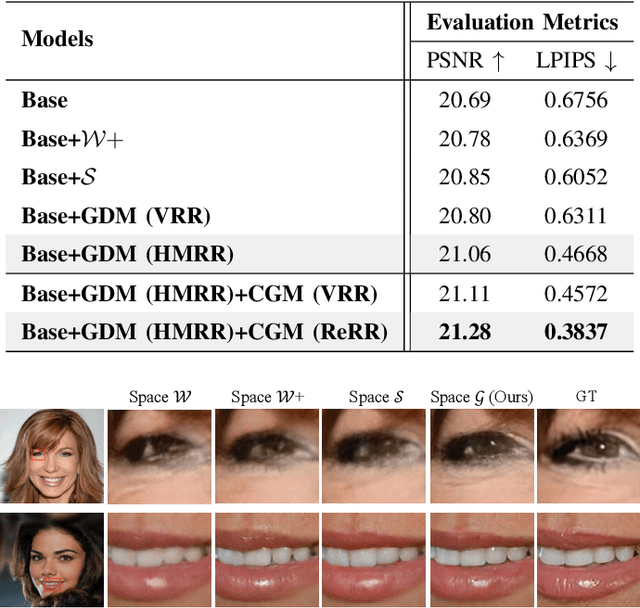


Recently, single image super-resolution (SR) under large scaling factors has witnessed impressive progress by introducing pre-trained generative adversarial networks (GANs) as priors. However, most GAN-Priors based SR methods are constrained by an attribute disentanglement problem in inverted latent codes which directly leads to mismatches of visual attributes in the generator layers and further degraded reconstruction. In addition, stochastic noises fed to the generator are employed for unconditional detail generation, which tends to produce unfaithful details that compromise the fidelity of the generated SR image. We design LAREN, a LAtent multi-Relation rEasoNing technique that achieves superb large-factor SR through graph-based multi-relation reasoning in latent space. LAREN consists of two innovative designs. The first is graph-based disentanglement that constructs a superior disentangled latent space via hierarchical multi-relation reasoning. The second is graph-based code generation that produces image-specific codes progressively via recursive relation reasoning which enables prior GANs to generate desirable image details. Extensive experiments show that LAREN achieves superior large-factor image SR and outperforms the state-of-the-art consistently across multiple benchmarks.
Meta-Learned Kernel For Blind Super-Resolution Kernel Estimation
Dec 15, 2022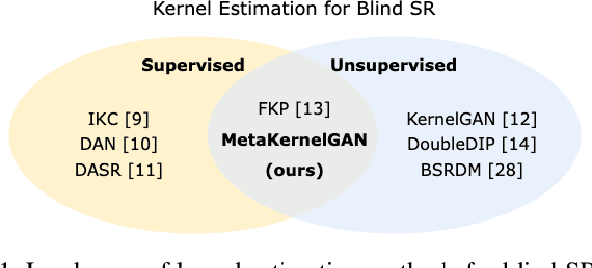
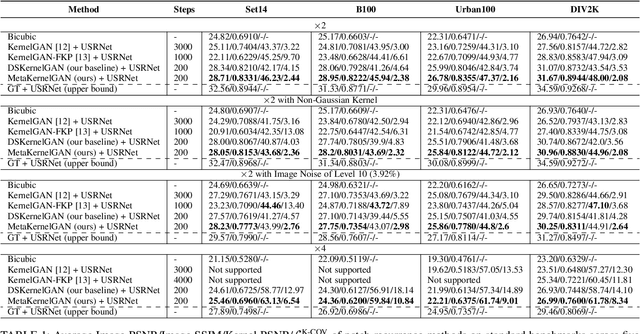
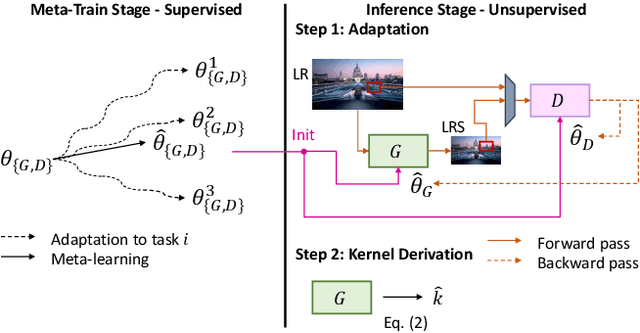
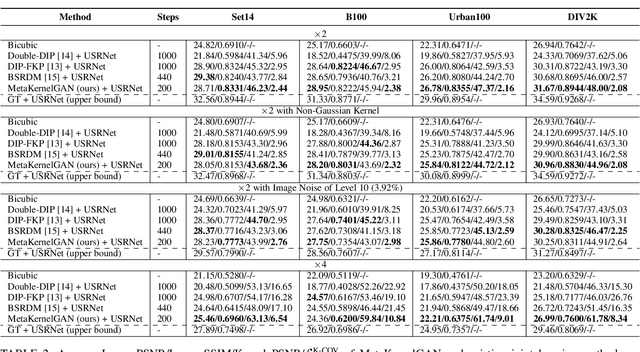
Recent image degradation estimation methods have enabled single-image super-resolution (SR) approaches to better upsample real-world images. Among these methods, explicit kernel estimation approaches have demonstrated unprecedented performance at handling unknown degradations. Nonetheless, a number of limitations constrain their efficacy when used by downstream SR models. Specifically, this family of methods yields i) excessive inference time due to long per-image adaptation times and ii) inferior image fidelity due to kernel mismatch. In this work, we introduce a learning-to-learn approach that meta-learns from the information contained in a distribution of images, thereby enabling significantly faster adaptation to new images with substantially improved performance in both kernel estimation and image fidelity. Specifically, we meta-train a kernel-generating GAN, named MetaKernelGAN, on a range of tasks, such that when a new image is presented, the generator starts from an informed kernel estimate and the discriminator starts with a strong capability to distinguish between patch distributions. Compared with state-of-the-art methods, our experiments show that MetaKernelGAN better estimates the magnitude and covariance of the kernel, leading to state-of-the-art blind SR results within a similar computational regime when combined with a non-blind SR model. Through supervised learning of an unsupervised learner, our method maintains the generalizability of the unsupervised learner, improves the optimization stability of kernel estimation, and hence image adaptation, and leads to a faster inference with a speedup between 14.24 to 102.1x over existing methods.