 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniLight: One Model to Rule All Lighting Conditions
Apr 16, 2026Adverse lighting conditions, such as cast shadows and irregular illumination, pose significant challenges to computer vision systems by degrading visibility and color fidelity. Consequently, effective shadow removal and ALN are critical for restoring underlying image content, improving perceptual quality, and facilitating robust performance in downstream tasks. However, while achieving state-of-the-art results on specific benchmarks is a primary goal in image restoration challenges, real-world applications often demand robust models capable of handling diverse domains. To address this, we present a comprehensive study on lighting-related image restoration by exploring two contrasting strategies. We leverage a robust framework for ALN, DINOLight, as a specialized baseline to exploit the characteristics of each individual dataset, and extend it to OmniLight, a generalized alternative incorporating our proposed Wavelet Domain Mixture-of-Experts (WD-MoE) that is trained across all provided datasets. Through a comparative analysis of these two methods, we discuss the impact of data distribution on the performance of specialized and unified architectures in lighting-related image restoration. Notably, both approaches secured top-tier rankings across all three lighting-related tracks in the NTIRE 2026 Challenge, demonstrating their outstanding perceptual quality and generalization capabilities. Our codes are available at https://github.com/OBAKSA/Lighting-Restoration.
TM-BSN: Triangular-Masked Blind-Spot Network for Real-World Self-Supervised Image Denoising
Apr 06, 2026Blind-spot networks (BSNs) enable self-supervised image denoising by preventing access to the target pixel, allowing clean signal estimation without ground-truth supervision. However, this approach assumes pixel-wise noise independence, which is violated in real-world sRGB images due to spatially correlated noise from the camera's image signal processing (ISP) pipeline. While several methods employ downsampling to decorrelate noise, they alter noise statistics and limit the network's ability to utilize full contextual information. In this paper, we propose the Triangular-Masked Blind-Spot Network (TM-BSN), a novel blind-spot architecture that accurately models the spatial correlation of real sRGB noise. This correlation originates from demosaicing, where each pixel is reconstructed from neighboring samples with spatially decaying weights, resulting in a diamond-shaped pattern. To align the receptive field with this geometry, we introduce a triangular-masked convolution that restricts the kernel to its upper-triangular region, creating a diamond-shaped blind spot at the original resolution. This design excludes correlated pixels while fully leveraging uncorrelated context, eliminating the need for downsampling or post-processing. Furthermore, we use knowledge distillation to transfer complementary knowledge from multiple blind-spot predictions into a lightweight U-Net, improving both accuracy and efficiency. Extensive experiments on real-world benchmarks demonstrate that our method achieves state-of-the-art performance, significantly outperforming existing self-supervised approaches. Our code is available at https://github.com/parkjun210/TM-BSN.
DINOLight: Robust Ambient Light Normalization with Self-supervised Visual Prior Integration
Mar 13, 2026This paper presents a new ambient light normalization framework, DINOLight, that integrates the self-supervised model DINOv2's image understanding capability into the restoration process as a visual prior. Ambient light normalization aims to restore images degraded by non-uniform shadows and lighting caused by multiple light sources and complex scene geometries. We observe that DINOv2 can reliably extract both semantic and geometric information from a degraded image. Based on this observation, we develop a novel framework to utilize DINOv2 features for lighting normalization. First, we propose an adaptive feature fusion module that combines features from different DINOv2 layers using a point-wise softmax mask. Next, the fused features are integrated into our proposed restoration network in both spatial and frequency domains through an auxiliary cross-attention mechanism. Experiments show that DINOLight achieves superior performance on the Ambient6K dataset, and that DINOv2 features are effective for enhancing ambient light normalization. We also apply our method to shadow-removal benchmark datasets, achieving competitive results compared to methods that use mask priors. Codes will be released upon acceptance.
Exploring Syn-to-Real Domain Adaptation for Military Target Detection
Dec 29, 2025Object detection is one of the key target tasks of interest in the context of civil and military applications. In particular, the real-world deployment of target detection methods is pivotal in the decision-making process during military command and reconnaissance. However, current domain adaptive object detection algorithms consider adapting one domain to another similar one only within the scope of natural or autonomous driving scenes. Since military domains often deal with a mixed variety of environments, detecting objects from multiple varying target domains poses a greater challenge. Several studies for armored military target detection have made use of synthetic aperture radar (SAR) data due to its robustness to all weather, long range, and high-resolution characteristics. Nevertheless, the costs of SAR data acquisition and processing are still much higher than those of the conventional RGB camera, which is a more affordable alternative with significantly lower data processing time. Furthermore, the lack of military target detection datasets limits the use of such a low-cost approach. To mitigate these issues, we propose to generate RGB-based synthetic data using a photorealistic visual tool, Unreal Engine, for military target detection in a cross-domain setting. To this end, we conducted synthetic-to-real transfer experiments by training our synthetic dataset and validating on our web-collected real military target datasets. We benchmark the state-of-the-art domain adaptation methods distinguished by the degree of supervision on our proposed train-val dataset pair, and find that current methods using minimal hints on the image (e.g., object class) achieve a substantial improvement over unsupervised or semi-supervised DA methods. From these observations, we recognize the current challenges that remain to be overcome.
Towards Controllable Real Image Denoising with Camera Parameters
Jul 02, 2025

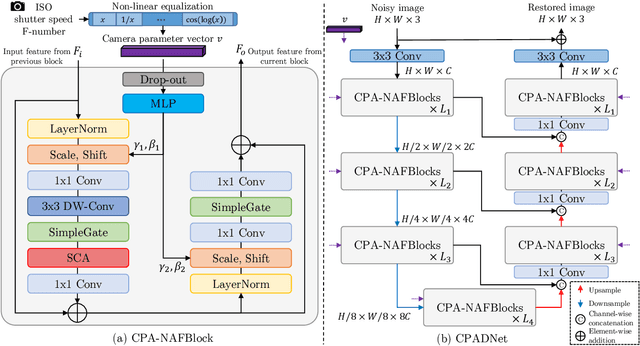
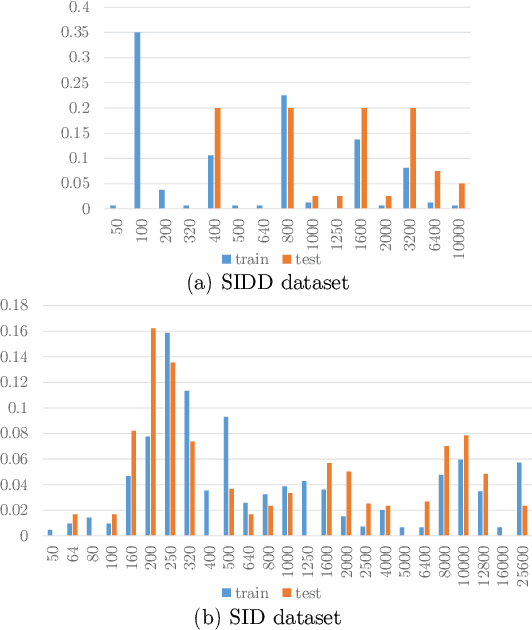
Recent deep learning-based image denoising methods have shown impressive performance; however, many lack the flexibility to adjust the denoising strength based on the noise levels, camera settings, and user preferences. In this paper, we introduce a new controllable denoising framework that adaptively removes noise from images by utilizing information from camera parameters. Specifically, we focus on ISO, shutter speed, and F-number, which are closely related to noise levels. We convert these selected parameters into a vector to control and enhance the performance of the denoising network. Experimental results show that our method seamlessly adds controllability to standard denoising neural networks and improves their performance. Code is available at https://github.com/OBAKSA/CPADNet.
Domain Generalization Emerges from Dreaming
Feb 02, 2023



Recent studies have proven that DNNs, unlike human vision, tend to exploit texture information rather than shape. Such texture bias is one of the factors for the poor generalization performance of DNNs. We observe that the texture bias negatively affects not only in-domain generalization but also out-of-distribution generalization, i.e., Domain Generalization. Motivated by the observation, we propose a new framework to reduce the texture bias of a model by a novel optimization-based data augmentation, dubbed Stylized Dream. Our framework utilizes adaptive instance normalization (AdaIN) to augment the style of an original image yet preserve the content. We then adopt a regularization loss to predict consistent outputs between Stylized Dream and original images, which encourages the model to learn shape-based representations. Extensive experiments show that the proposed method achieves state-of-the-art performance in out-of-distribution settings on public benchmark datasets: PACS, VLCS, OfficeHome, TerraIncognita, and DomainNet.