 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Data-Efficient Training of CNNs and Transformers with Coresets: A Stability Perspective
Mar 10, 2023
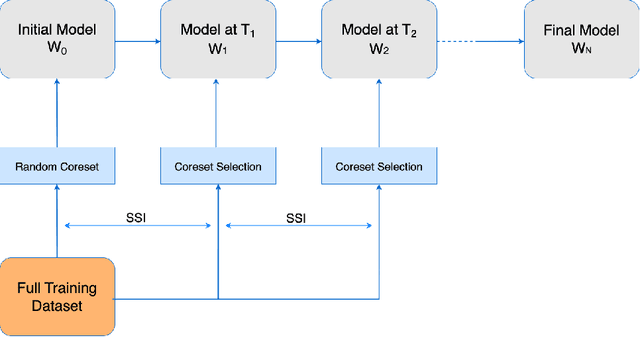

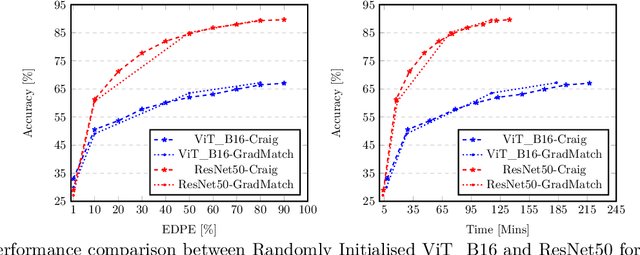
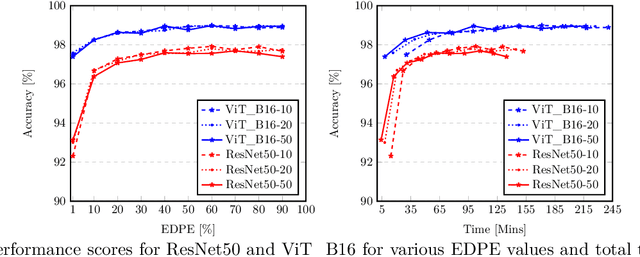
Coreset selection is among the most effective ways to reduce the training time of CNNs, however, only limited is known on how the resultant models will behave under variations of the coreset size, and choice of datasets and models. Moreover, given the recent paradigm shift towards transformer-based models, it is still an open question how coreset selection would impact their performance. There are several similar intriguing questions that need to be answered for a wide acceptance of coreset selection methods, and this paper attempts to answer some of these. We present a systematic benchmarking setup and perform a rigorous comparison of different coreset selection methods on CNNs and transformers. Our investigation reveals that under certain circumstances, random selection of subsets is more robust and stable when compared with the SOTA selection methods. We demonstrate that the conventional concept of uniform subset sampling across the various classes of the data is not the appropriate choice. Rather samples should be adaptively chosen based on the complexity of the data distribution for each class. Transformers are generally pretrained on large datasets, and we show that for certain target datasets, it helps to keep their performance stable at even very small coreset sizes. We further show that when no pretraining is done or when the pretrained transformer models are used with non-natural images (e.g. medical data), CNNs tend to generalize better than transformers at even very small coreset sizes. Lastly, we demonstrate that in the absence of the right pretraining, CNNs are better at learning the semantic coherence between spatially distant objects within an image, and these tend to outperform transformers at almost all choices of the coreset size.
Transcending shift-invariance in the paraxial regime via end-to-end inverse design of freeform nanophotonics
Feb 03, 2023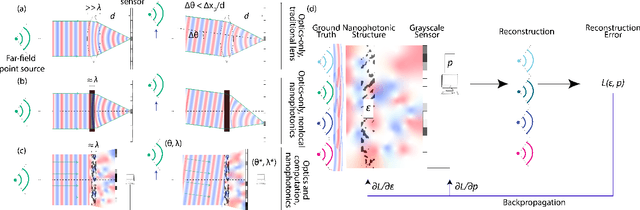
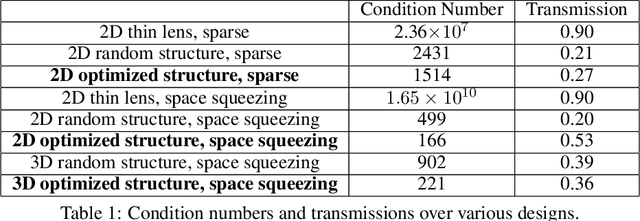
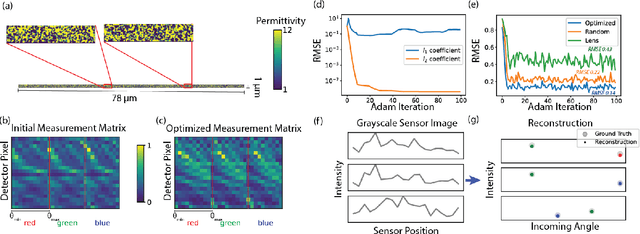

Traditional optical elements and conventional metasurfaces obey shift-invariance in the paraxial regime. For imaging systems obeying paraxial shift-invariance, a small shift in input angle causes a corresponding shift in the sensor image. Shift-invariance has deep implications for the design and functionality of optical devices, such as the necessity of free space between components (as in compound objectives made of several curved surfaces). We present a method for nanophotonic inverse design of compact imaging systems whose resolution is not constrained by paraxial shift-invariance. Our method is end-to-end, in that it integrates density-based full-Maxwell topology optimization with a fully iterative elastic-net reconstruction algorithm. By the design of nanophotonic structures that scatter light in a non-shift-invariant manner, our optimized nanophotonic imaging system overcomes the limitations of paraxial shift-invariance, achieving accurate, noise-robust image reconstruction beyond shift-invariant resolution.
Organelle-specific segmentation, spatial analysis, and visualization of volume electron microscopy datasets
Mar 07, 2023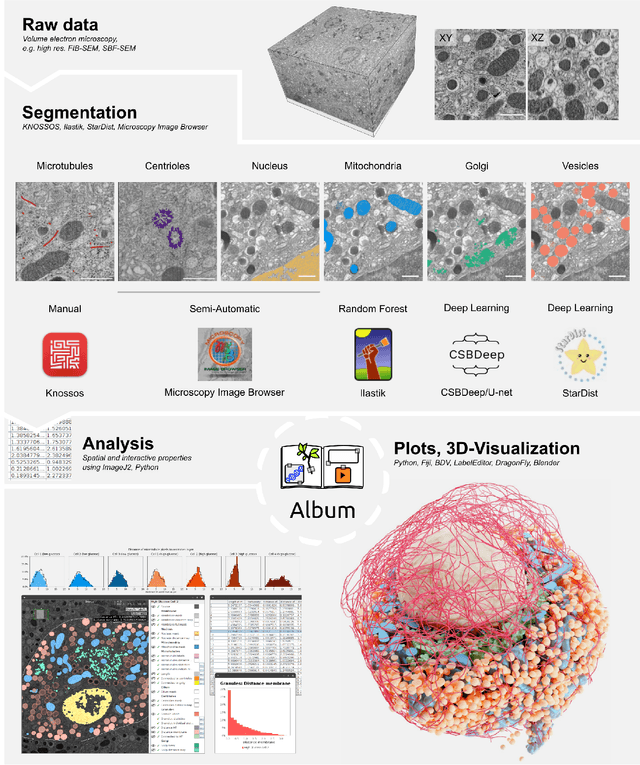
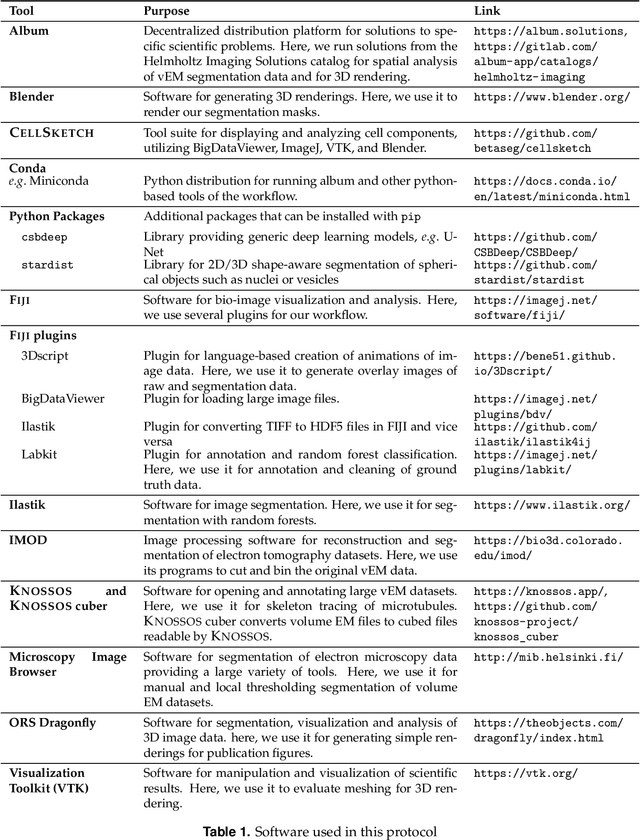
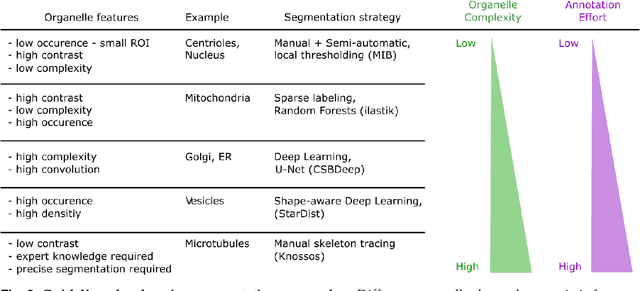
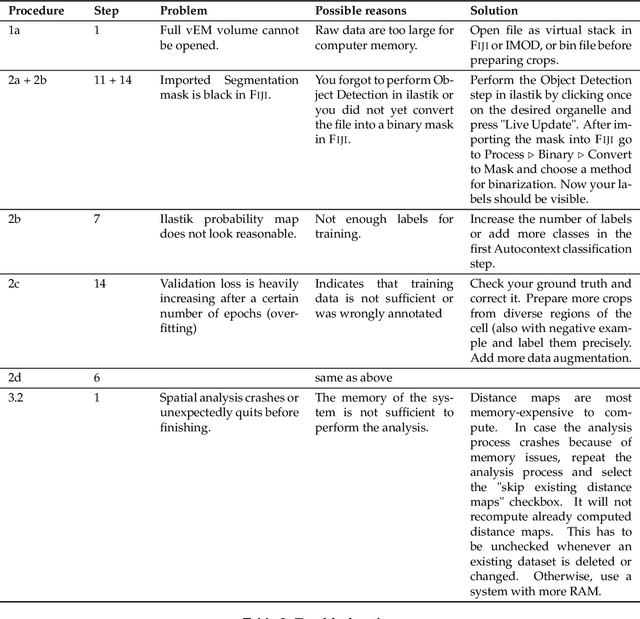
Volume electron microscopy is the method of choice for the in-situ interrogation of cellular ultrastructure at the nanometer scale. Recent technical advances have led to a rapid increase in large raw image datasets that require computational strategies for segmentation and spatial analysis. In this protocol, we describe a practical and annotation-efficient pipeline for organelle-specific segmentation, spatial analysis, and visualization of large volume electron microscopy datasets using freely available, user-friendly software tools that can be run on a single standard workstation. We specifically target researchers in the life sciences with limited computational expertise, who face the following tasks within their volume electron microscopy projects: i) How to generate 3D segmentation labels for different types of cell organelles while minimizing manual annotation efforts, ii) how to analyze the spatial interactions between organelle instances, and iii) how to best visualize the 3D segmentation results. To meet these demands we give detailed guidelines for choosing the most efficient segmentation tools for the specific cell organelle. We furthermore provide easily executable components for spatial analysis and 3D rendering and bridge compatibility issues between freely available open-source tools, such that others can replicate our full pipeline starting from a raw dataset up to the final plots and rendered images. We believe that our detailed description can serve as a valuable reference for similar projects requiring special strategies for single- or multiple organelle analysis which can be achieved with computational resources commonly available to single-user setups.
StudyFormer : Attention-Based and Dynamic Multi View Classifier for X-ray images
Feb 23, 2023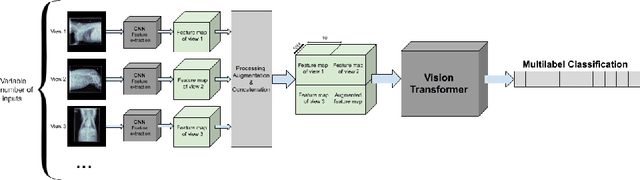
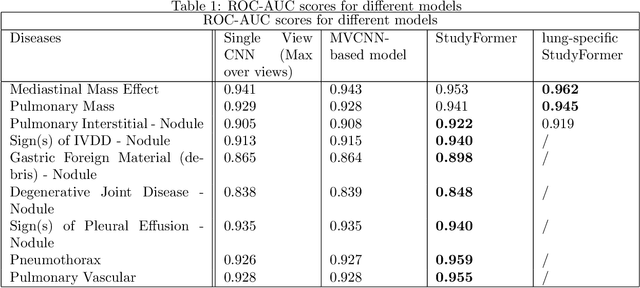
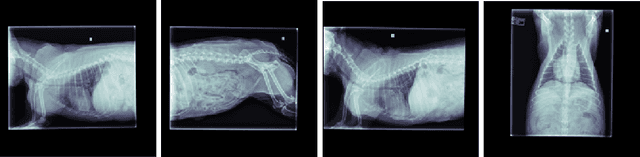
Chest X-ray images are commonly used in medical diagnosis, and AI models have been developed to assist with the interpretation of these images. However, many of these models rely on information from a single view of the X-ray, while multiple views may be available. In this work, we propose a novel approach for combining information from multiple views to improve the performance of X-ray image classification. Our approach is based on the use of a convolutional neural network to extract feature maps from each view, followed by an attention mechanism implemented using a Vision Transformer. The resulting model is able to perform multi-label classification on 41 labels and outperforms both single-view models and traditional multi-view classification architectures. We demonstrate the effectiveness of our approach through experiments on a dataset of 363,000 X-ray images.
A Tale of Two Latent Flows: Learning Latent Space Normalizing Flow with Short-run Langevin Flow for Approximate Inference
Jan 23, 2023


We study a normalizing flow in the latent space of a top-down generator model, in which the normalizing flow model plays the role of the informative prior model of the generator. We propose to jointly learn the latent space normalizing flow prior model and the top-down generator model by a Markov chain Monte Carlo (MCMC)-based maximum likelihood algorithm, where a short-run Langevin sampling from the intractable posterior distribution is performed to infer the latent variables for each observed example, so that the parameters of the normalizing flow prior and the generator can be updated with the inferred latent variables. We show that, under the scenario of non-convergent short-run MCMC, the finite step Langevin dynamics is a flow-like approximate inference model and the learning objective actually follows the perturbation of the maximum likelihood estimation (MLE). We further point out that the learning framework seeks to (i) match the latent space normalizing flow and the aggregated posterior produced by the short-run Langevin flow, and (ii) bias the model from MLE such that the short-run Langevin flow inference is close to the true posterior. Empirical results of extensive experiments validate the effectiveness of the proposed latent space normalizing flow model in the tasks of image generation, image reconstruction, anomaly detection, supervised image inpainting and unsupervised image recovery.
Impact of PCA-based preprocessing and different CNN structures on deformable registration of sonograms
Jan 20, 2023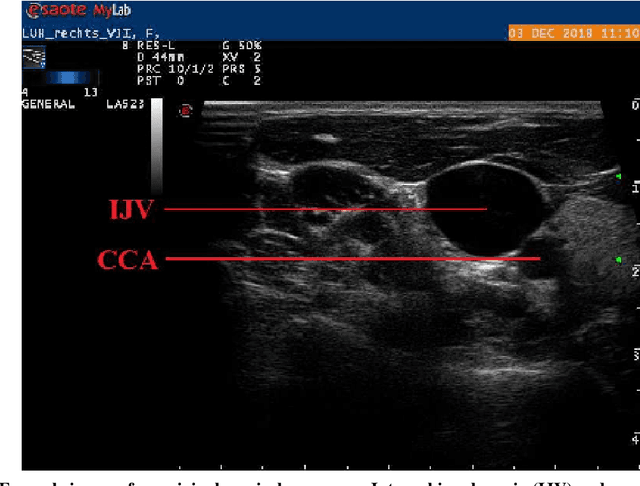

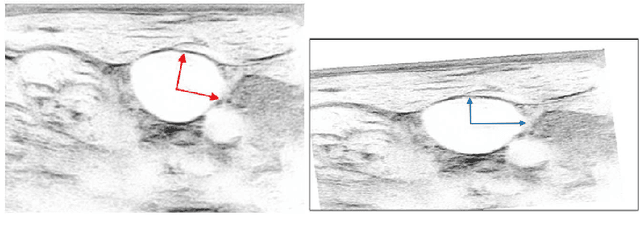
Central venous catheters (CVC) are commonly inserted into the large veins of the neck, e.g. the internal jugular vein (IJV). CVC insertion may cause serious complications like misplacement into an artery or perforation of cervical vessels. Placing a CVC under sonographic guidance is an appropriate method to reduce such adverse events, if anatomical landmarks like venous and arterial vessels can be detected reliably. This task shall be solved by registration of patient individual images vs. an anatomically labelled reference image. In this work, a linear, affine transformation is performed on cervical sonograms, followed by a non-linear transformation to achieve a more precise registration. Voxelmorph (VM), a learning-based library for deformable image registration using a convolutional neural network (CNN) with U-Net structure was used for non-linear transformation. The impact of principal component analysis (PCA)-based pre-denoising of patient individual images, as well as the impact of modified net structures with differing complexities on registration results were examined visually and quantitatively, the latter using metrics for deformation and image similarity. Using the PCA-approximated cervical sonograms resulted in decreased mean deformation lengths between 18% and 66% compared to their original image counterparts, depending on net structure. In addition, reducing the number of convolutional layers led to improved image similarity with PCA images, while worsening in original images. Despite a large reduction of network parameters, no overall decrease in registration quality was observed, leading to the conclusion that the original net structure is oversized for the task at hand.
* 8 pages, 7 figures Presented at WSCG 2022
Images as Weight Matrices: Sequential Image Generation Through Synaptic Learning Rules
Oct 07, 2022
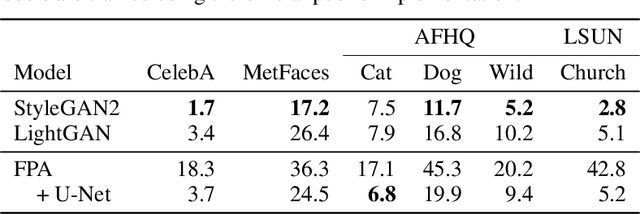
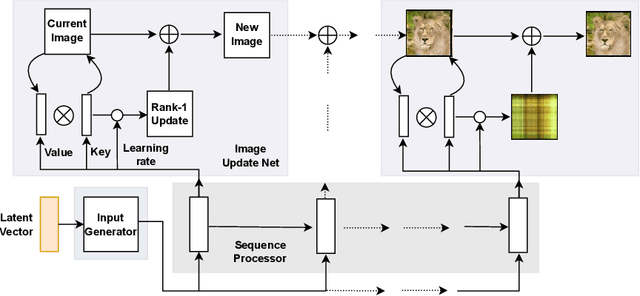
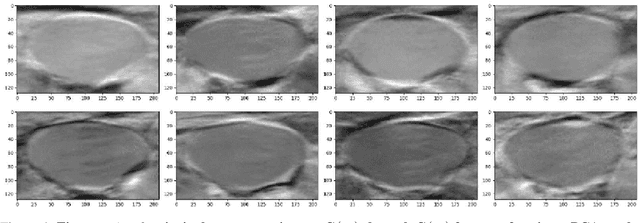
Work on fast weight programmers has demonstrated the effectiveness of key/value outer product-based learning rules for sequentially generating a weight matrix (WM) of a neural net (NN) by another NN or itself. However, the weight generation steps are typically not visually interpretable by humans, because the contents stored in the WM of an NN are not. Here we apply the same principle to generate natural images. The resulting fast weight painters (FPAs) learn to execute sequences of delta learning rules to sequentially generate images as sums of outer products of self-invented keys and values, one rank at a time, as if each image was a WM of an NN. We train our FPAs in the generative adversarial networks framework, and evaluate on various image datasets. We show how these generic learning rules can generate images with respectable visual quality without any explicit inductive bias for images. While the performance largely lags behind the one of specialised state-of-the-art image generators, our approach allows for visualising how synaptic learning rules iteratively produce complex connection patterns, yielding human-interpretable meaningful images. Finally, we also show that an additional convolutional U-Net (now popular in diffusion models) at the output of an FPA can learn one-step "denoising" of FPA-generated images to enhance their quality. Our code is public.
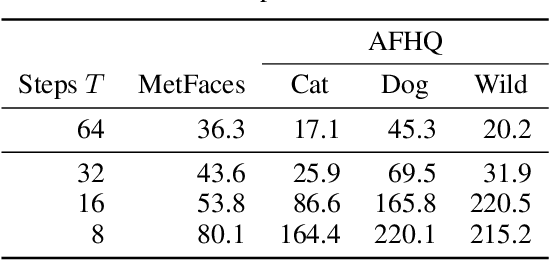
EVA3D: Compositional 3D Human Generation from 2D Image Collections
Oct 10, 2022
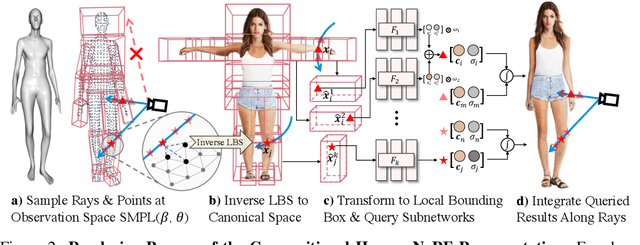
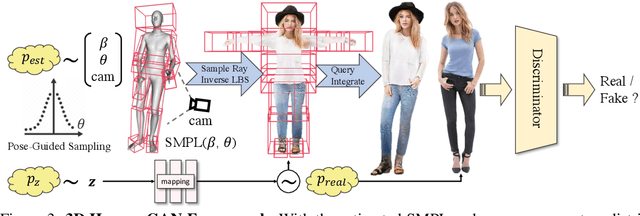

Inverse graphics aims to recover 3D models from 2D observations. Utilizing differentiable rendering, recent 3D-aware generative models have shown impressive results of rigid object generation using 2D images. However, it remains challenging to generate articulated objects, like human bodies, due to their complexity and diversity in poses and appearances. In this work, we propose, EVA3D, an unconditional 3D human generative model learned from 2D image collections only. EVA3D can sample 3D humans with detailed geometry and render high-quality images (up to 512x256) without bells and whistles (e.g. super resolution). At the core of EVA3D is a compositional human NeRF representation, which divides the human body into local parts. Each part is represented by an individual volume. This compositional representation enables 1) inherent human priors, 2) adaptive allocation of network parameters, 3) efficient training and rendering. Moreover, to accommodate for the characteristics of sparse 2D human image collections (e.g. imbalanced pose distribution), we propose a pose-guided sampling strategy for better GAN learning. Extensive experiments validate that EVA3D achieves state-of-the-art 3D human generation performance regarding both geometry and texture quality. Notably, EVA3D demonstrates great potential and scalability to "inverse-graphics" diverse human bodies with a clean framework.
ParaColorizer: Realistic Image Colorization using Parallel Generative Networks
Aug 17, 2022


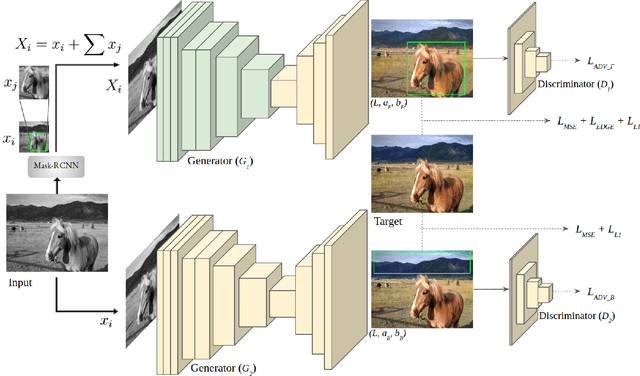
Grayscale image colorization is a fascinating application of AI for information restoration. The inherently ill-posed nature of the problem makes it even more challenging since the outputs could be multi-modal. The learning-based methods currently in use produce acceptable results for straightforward cases but usually fail to restore the contextual information in the absence of clear figure-ground separation. Also, the images suffer from color bleeding and desaturated backgrounds since a single model trained on full image features is insufficient for learning the diverse data modes. To address these issues, we present a parallel GAN-based colorization framework. In our approach, each separately tailored GAN pipeline colorizes the foreground (using object-level features) or the background (using full-image features). The foreground pipeline employs a Residual-UNet with self-attention as its generator trained using the full-image features and the corresponding object-level features from the COCO dataset. The background pipeline relies on full-image features and additional training examples from the Places dataset. We design a DenseFuse-based fusion network to obtain the final colorized image by feature-based fusion of the parallelly generated outputs. We show the shortcomings of the non-perceptual evaluation metrics commonly used to assess multi-modal problems like image colorization and perform extensive performance evaluation of our framework using multiple perceptual metrics. Our approach outperforms most of the existing learning-based methods and produces results comparable to the state-of-the-art. Further, we performed a runtime analysis and obtained an average inference time of 24ms per image.
Structure and Content-Guided Video Synthesis with Diffusion Models
Feb 06, 2023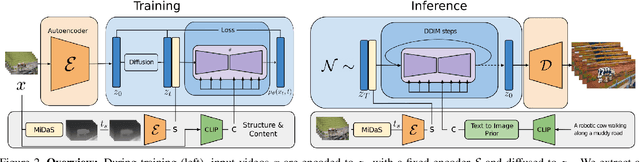
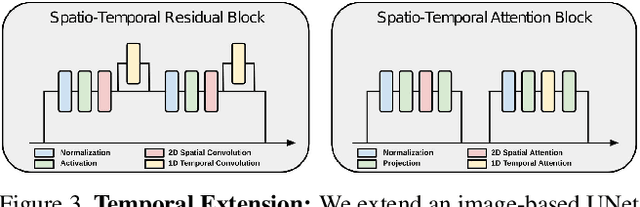


Text-guided generative diffusion models unlock powerful image creation and editing tools. While these have been extended to video generation, current approaches that edit the content of existing footage while retaining structure require expensive re-training for every input or rely on error-prone propagation of image edits across frames. In this work, we present a structure and content-guided video diffusion model that edits videos based on visual or textual descriptions of the desired output. Conflicts between user-provided content edits and structure representations occur due to insufficient disentanglement between the two aspects. As a solution, we show that training on monocular depth estimates with varying levels of detail provides control over structure and content fidelity. Our model is trained jointly on images and videos which also exposes explicit control of temporal consistency through a novel guidance method. Our experiments demonstrate a wide variety of successes; fine-grained control over output characteristics, customization based on a few reference images, and a strong user preference towards results by our model.