 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Detection of Uncertainty in Exceedance of Threshold (DUET): An Adversarial Patch Localizer
Mar 18, 2023

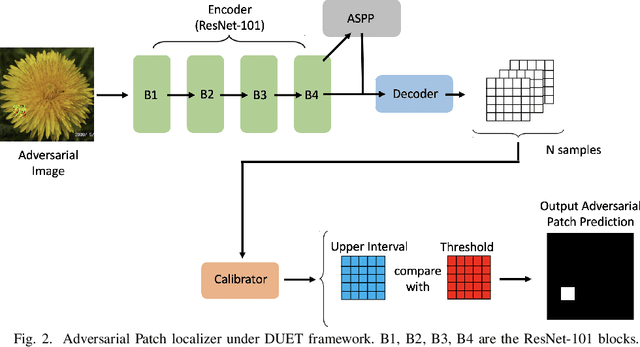

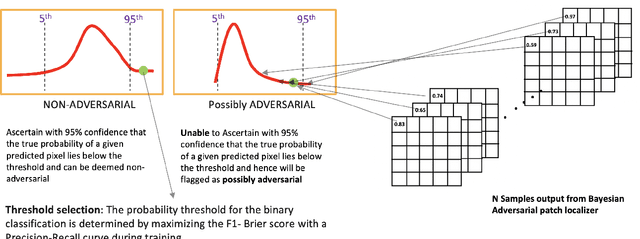
Development of defenses against physical world attacks such as adversarial patches is gaining traction within the research community. We contribute to the field of adversarial patch detection by introducing an uncertainty-based adversarial patch localizer which localizes adversarial patch on an image, permitting post-processing patch-avoidance or patch-reconstruction. We quantify our prediction uncertainties with the development of \textit{\textbf{D}etection of \textbf{U}ncertainties in the \textbf{E}xceedance of \textbf{T}hreshold} (DUET) algorithm. This algorithm provides a framework to ascertain confidence in the adversarial patch localization, which is essential for safety-sensitive applications such as self-driving cars and medical imaging. We conducted experiments on localizing adversarial patches and found our proposed DUET model outperforms baseline models. We then conduct further analyses on our choice of model priors and the adoption of Bayesian Neural Networks in different layers within our model architecture. We found that isometric gaussian priors in Bayesian Neural Networks are suitable for patch localization tasks and the presence of Bayesian layers in the earlier neural network blocks facilitates top-end localization performance, while Bayesian layers added in the later neural network blocks contribute to better model generalization. We then propose two different well-performing models to tackle different use cases.
Learning Multi-Object Positional Relationships via Emergent Communication
Feb 16, 2023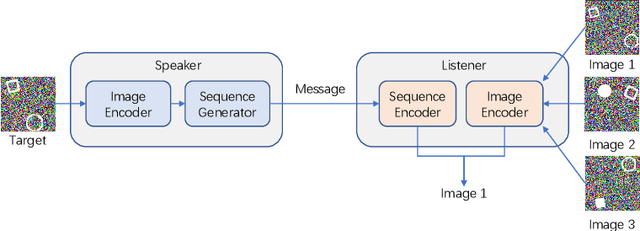

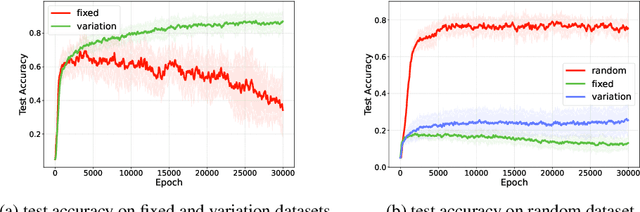
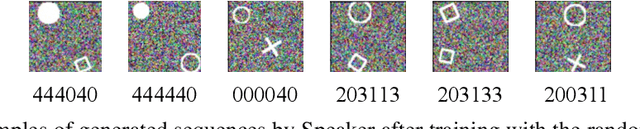
The study of emergent communication has been dedicated to interactive artificial intelligence. While existing work focuses on communication about single objects or complex image scenes, we argue that communicating relationships between multiple objects is important in more realistic tasks, but understudied. In this paper, we try to fill this gap and focus on emergent communication about positional relationships between two objects. We train agents in the referential game where observations contain two objects, and find that generalization is the major problem when the positional relationship is involved. The key factor affecting the generalization ability of the emergent language is the input variation between Speaker and Listener, which is realized by a random image generator in our work. Further, we find that the learned language can generalize well in a new multi-step MDP task where the positional relationship describes the goal, and performs better than raw-pixel images as well as pre-trained image features, verifying the strong generalization ability of discrete sequences. We also show that language transfer from the referential game performs better in the new task than learning language directly in this task, implying the potential benefits of pre-training in referential games. All in all, our experiments demonstrate the viability and merit of having agents learn to communicate positional relationships between multiple objects through emergent communication.
Ringing Artifact Reduction Method for Ultrasound Reconstruction Using Multi-Agent Consensus Equilibrium
Feb 09, 2023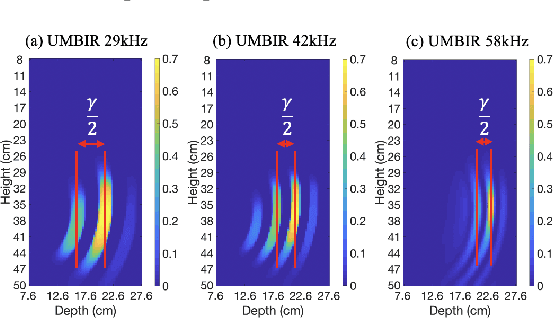
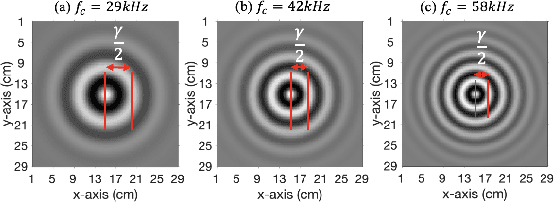
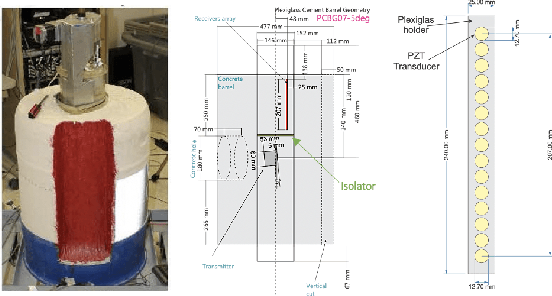
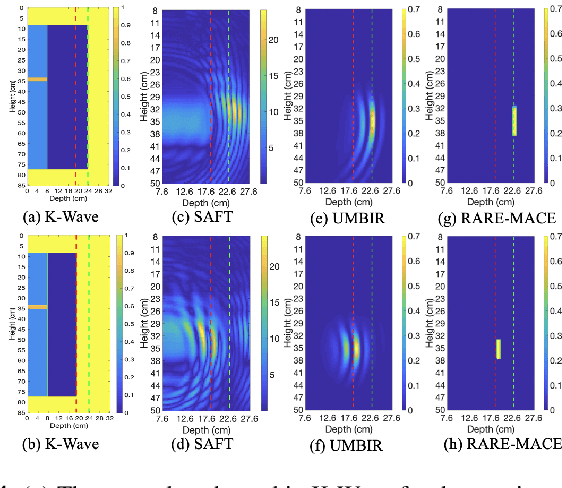
Non-destructive characterization of multi-layered structures that can be accessed from only a single side is important for applications such as well-bore integrity inspection. Existing methods related to Synthetic Aperture Focusing Technique (SAFT) rapidly produce acceptable results but with significant artifacts. Recently, ultrasound model-based iterative reconstruction (UMBIR) approaches have shown significant improvements over SAFT. However, even these methods produce ringing artifacts due to the high fractional-bandwidth of the excitation signal. In this paper, we propose a ringing artifact reduction method for ultrasound image reconstruction that uses a multi-agent consensus equilibrium (RARE-MACE) framework. Our approach integrates a physics-based forward model that accounts for the propagation of a collimated ultrasonic beam in multi-layered media, a spatially varying image prior, and a denoiser designed to suppress the ringing artifacts that are characteristic of reconstructions from high-fractional bandwidth ultrasound sensor data. We test our method on simulated and experimental measurements and show substantial improvements in image quality compared to SAFT and UMBIR.
A Correction-Based Dynamic Enhancement Framework towards Underwater Detection
Feb 06, 2023



To assist underwater object detection for better performance, image enhancement technology is often used as a pre-processing step. However, most of the existing enhancement methods tend to pursue the visual quality of an image, instead of providing effective help for detection tasks. In fact, image enhancement algorithms should be optimized with the goal of utility improvement. In this paper, to adapt to the underwater detection tasks, we proposed a lightweight dynamic enhancement algorithm using a contribution dictionary to guide low-level corrections. Dynamic solutions are designed to capture differences in detection preferences. In addition, it can also balance the inconsistency between the contribution of correction operations and their time complexity. Experimental results in real underwater object detection tasks show the superiority of our proposed method in both generalization and real-time performance.
Black-Box Attack against GAN-Generated Image Detector with Contrastive Perturbation
Nov 07, 2022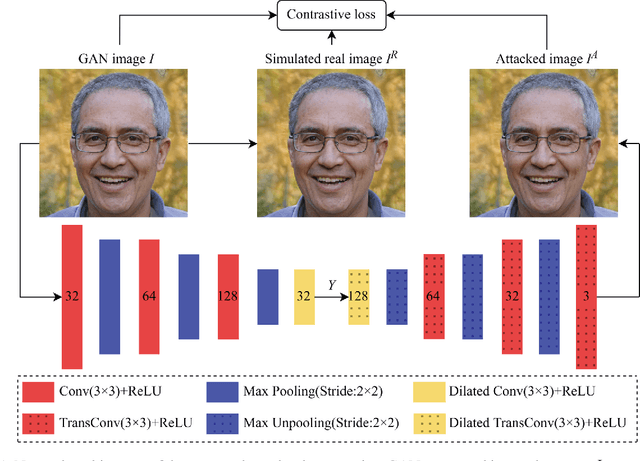
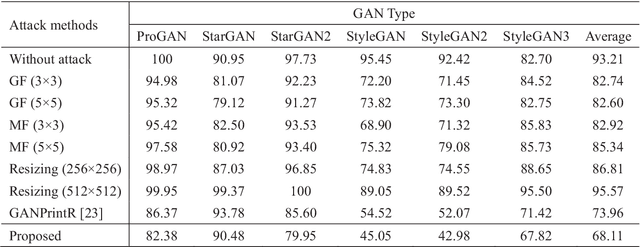
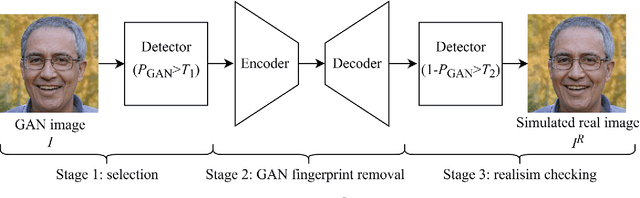
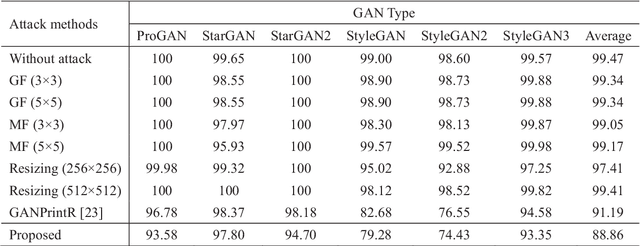
Visually realistic GAN-generated facial images raise obvious concerns on potential misuse. Many effective forensic algorithms have been developed to detect such synthetic images in recent years. It is significant to assess the vulnerability of such forensic detectors against adversarial attacks. In this paper, we propose a new black-box attack method against GAN-generated image detectors. A novel contrastive learning strategy is adopted to train the encoder-decoder network based anti-forensic model under a contrastive loss function. GAN images and their simulated real counterparts are constructed as positive and negative samples, respectively. Leveraging on the trained attack model, imperceptible contrastive perturbation could be applied to input synthetic images for removing GAN fingerprint to some extent. As such, existing GAN-generated image detectors are expected to be deceived. Extensive experimental results verify that the proposed attack effectively reduces the accuracy of three state-of-the-art detectors on six popular GANs. High visual quality of the attacked images is also achieved. The source code will be available at https://github.com/ZXMMD/BAttGAND.
Progressive Tree-Structured Prototype Network for End-to-End Image Captioning
Nov 17, 2022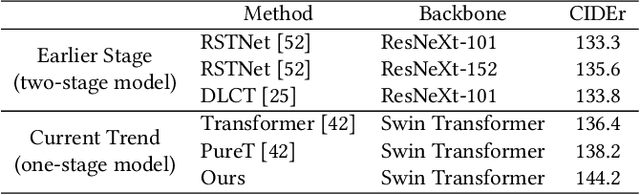
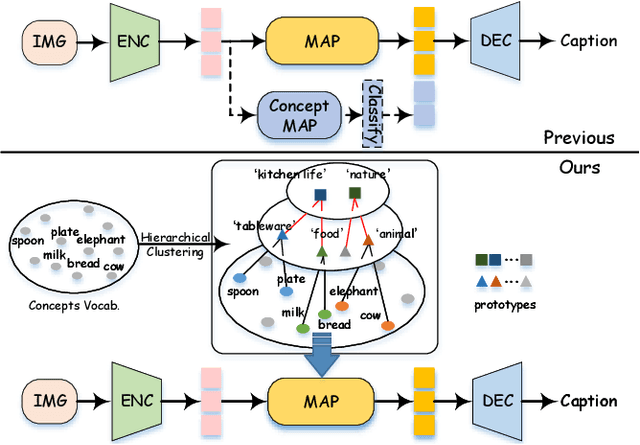
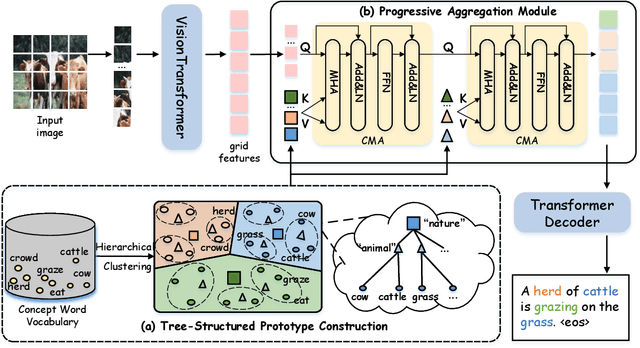
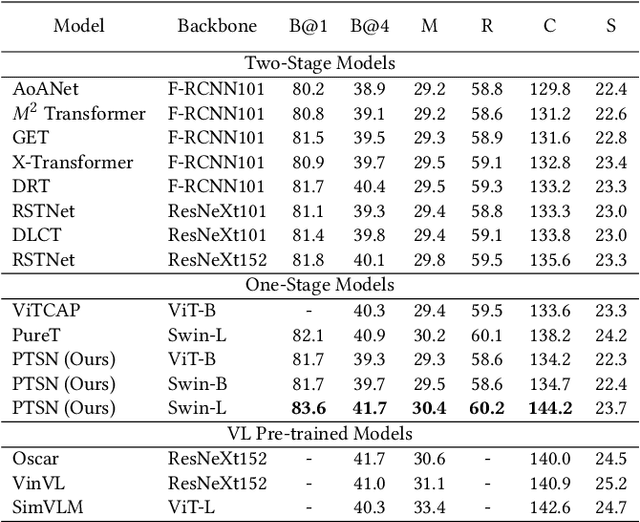
Studies of image captioning are shifting towards a trend of a fully end-to-end paradigm by leveraging powerful visual pre-trained models and transformer-based generation architecture for more flexible model training and faster inference speed. State-of-the-art approaches simply extract isolated concepts or attributes to assist description generation. However, such approaches do not consider the hierarchical semantic structure in the textual domain, which leads to an unpredictable mapping between visual representations and concept words. To this end, we propose a novel Progressive Tree-Structured prototype Network (dubbed PTSN), which is the first attempt to narrow down the scope of prediction words with appropriate semantics by modeling the hierarchical textual semantics. Specifically, we design a novel embedding method called tree-structured prototype, producing a set of hierarchical representative embeddings which capture the hierarchical semantic structure in textual space. To utilize such tree-structured prototypes into visual cognition, we also propose a progressive aggregation module to exploit semantic relationships within the image and prototypes. By applying our PTSN to the end-to-end captioning framework, extensive experiments conducted on MSCOCO dataset show that our method achieves a new state-of-the-art performance with 144.2% (single model) and 146.5% (ensemble of 4 models) CIDEr scores on `Karpathy' split and 141.4% (c5) and 143.9% (c40) CIDEr scores on the official online test server. Trained models and source code have been released at: https://github.com/NovaMind-Z/PTSN.
Genetic Programming-Based Evolutionary Deep Learning for Data-Efficient Image Classification
Sep 27, 2022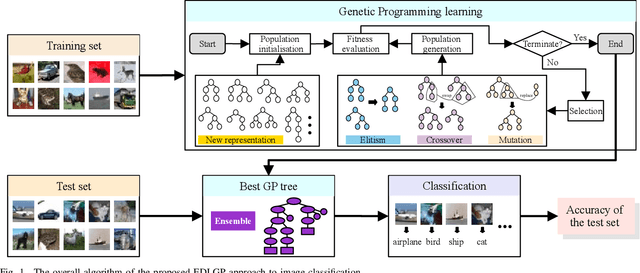

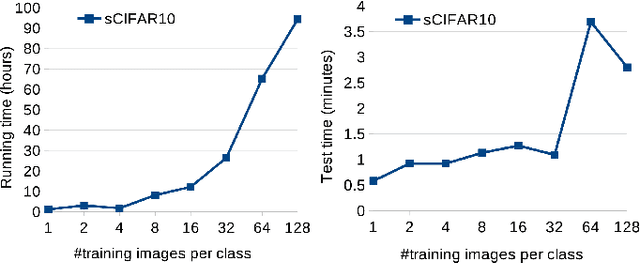
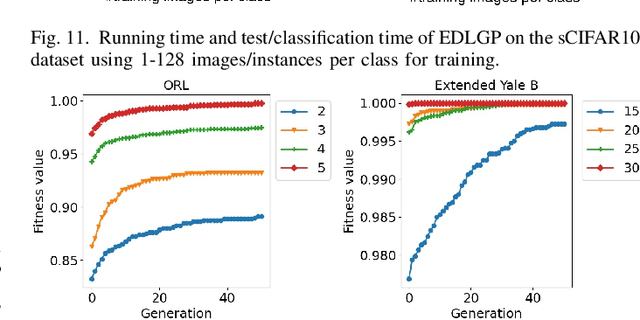
Data-efficient image classification is a challenging task that aims to solve image classification using small training data. Neural network-based deep learning methods are effective for image classification, but they typically require large-scale training data and have major limitations such as requiring expertise to design network architectures and having poor interpretability. Evolutionary deep learning is a recent hot topic that combines evolutionary computation with deep learning. However, most evolutionary deep learning methods focus on evolving architectures of neural networks, which still suffer from limitations such as poor interpretability. To address this, this paper proposes a new genetic programming-based evolutionary deep learning approach to data-efficient image classification. The new approach can automatically evolve variable-length models using many important operators from both image and classification domains. It can learn different types of image features from colour or gray-scale images, and construct effective and diverse ensembles for image classification. A flexible multi-layer representation enables the new approach to automatically construct shallow or deep models/trees for different tasks and perform effective transformations on the input data via multiple internal nodes. The new approach is applied to solve five image classification tasks with different training set sizes. The results show that it achieves better performance in most cases than deep learning methods for data-efficient image classification. A deep analysis shows that the new approach has good convergence and evolves models with high interpretability, different lengths/sizes/shapes, and good transferability.
* Accepted by IEEE Transactions on Evolutionary Computation
Topological Semantic Graph Memory for Image-Goal Navigation
Sep 17, 2022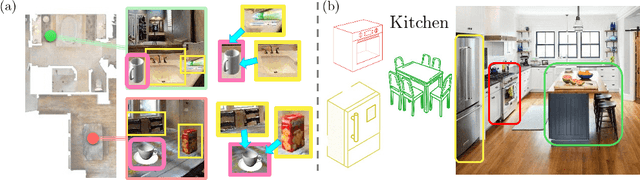
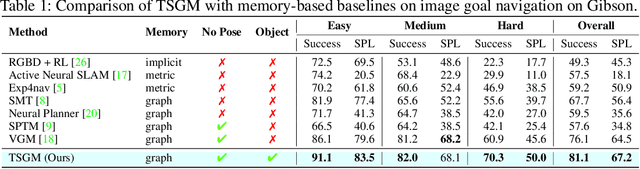
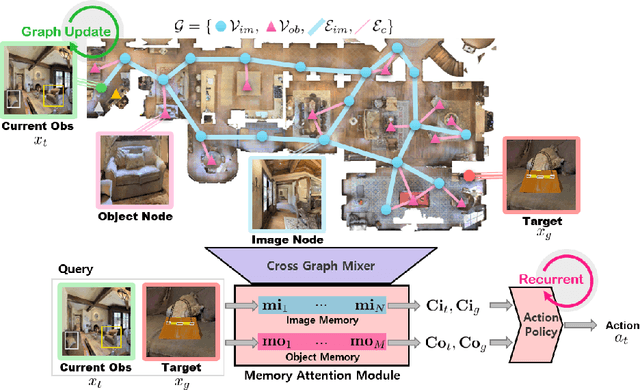
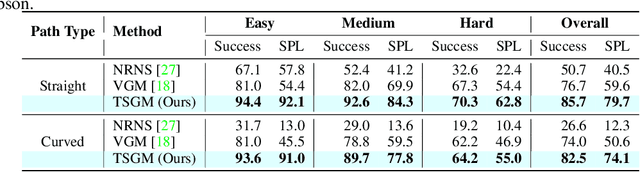
A novel framework is proposed to incrementally collect landmark-based graph memory and use the collected memory for image goal navigation. Given a target image to search, an embodied robot utilizes semantic memory to find the target in an unknown environment. % The semantic graph memory is collected from a panoramic observation of an RGB-D camera without knowing the robot's pose. In this paper, we present a topological semantic graph memory (TSGM), which consists of (1) a graph builder that takes the observed RGB-D image to construct a topological semantic graph, (2) a cross graph mixer module that takes the collected nodes to get contextual information, and (3) a memory decoder that takes the contextual memory as an input to find an action to the target. On the task of image goal navigation, TSGM significantly outperforms competitive baselines by +5.0-9.0% on the success rate and +7.0-23.5% on SPL, which means that the TSGM finds efficient paths. Additionally, we demonstrate our method on a mobile robot in real-world image goal scenarios.
Amodal Intra-class Instance Segmentation: New Dataset and Benchmark
Mar 12, 2023



Images of realistic scenes often contain intra-class objects that are heavily occluded from each other, making the amodal perception task that requires parsing the occluded parts of the objects challenging. Although important for downstream tasks such as robotic grasping systems, the lack of large-scale amodal datasets with detailed annotations makes it difficult to model intra-class occlusions explicitly. This paper introduces a new amodal dataset for image amodal completion tasks, which contains over 255K images of intra-class occlusion scenarios, annotated with multiple masks, amodal bounding boxes, dual order relations and full appearance for instances and background. We also present a point-supervised scheme with layer priors for amodal instance segmentation specifically designed for intra-class occlusion scenarios. Experiments show that our weakly supervised approach outperforms the SOTA fully supervised methods, while our layer priors design exhibits remarkable performance improvements in the case of intra-class occlusion in both synthetic and real images.
LOCATE: Localize and Transfer Object Parts for Weakly Supervised Affordance Grounding
Mar 16, 2023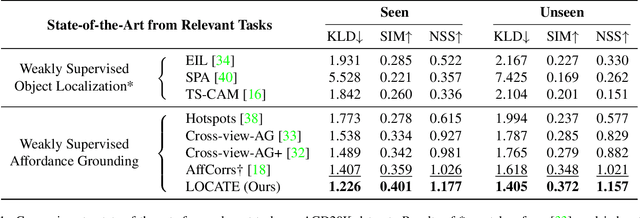
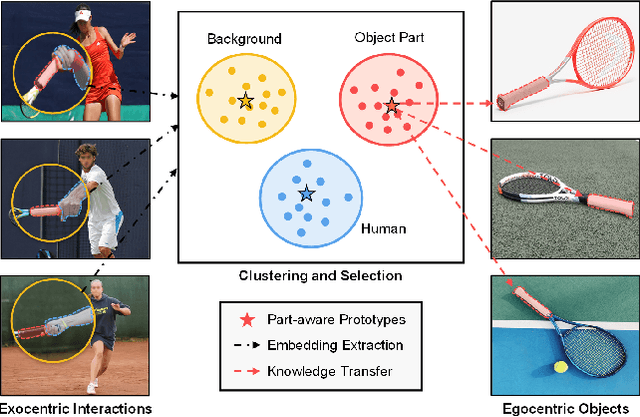
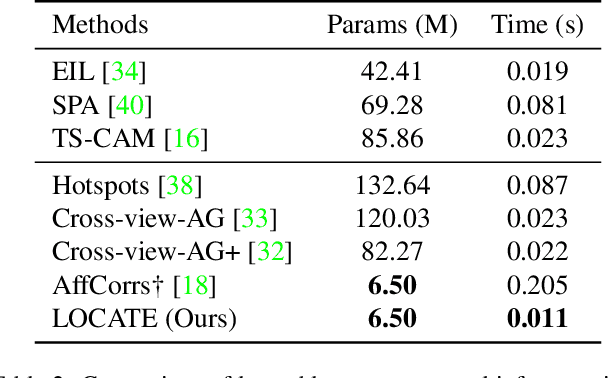
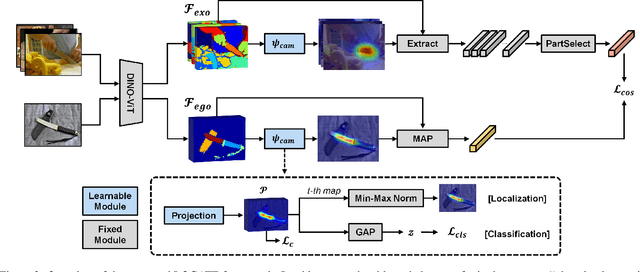
Humans excel at acquiring knowledge through observation. For example, we can learn to use new tools by watching demonstrations. This skill is fundamental for intelligent systems to interact with the world. A key step to acquire this skill is to identify what part of the object affords each action, which is called affordance grounding. In this paper, we address this problem and propose a framework called LOCATE that can identify matching object parts across images, to transfer knowledge from images where an object is being used (exocentric images used for learning), to images where the object is inactive (egocentric ones used to test). To this end, we first find interaction areas and extract their feature embeddings. Then we learn to aggregate the embeddings into compact prototypes (human, object part, and background), and select the one representing the object part. Finally, we use the selected prototype to guide affordance grounding. We do this in a weakly supervised manner, learning only from image-level affordance and object labels. Extensive experiments demonstrate that our approach outperforms state-of-the-art methods by a large margin on both seen and unseen objects.