 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A task-specific deep-learning-based denoising approach for myocardial perfusion SPECT
Mar 01, 2023
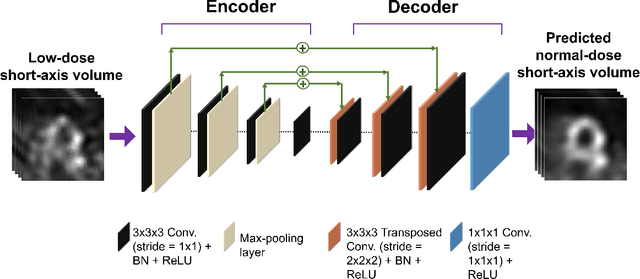
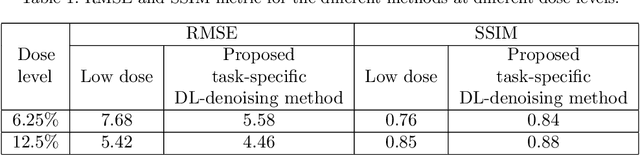
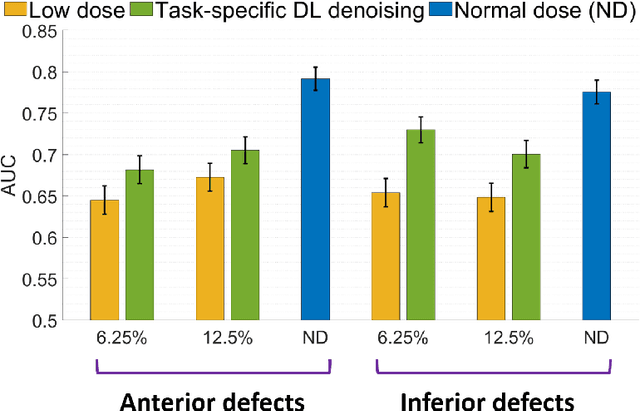
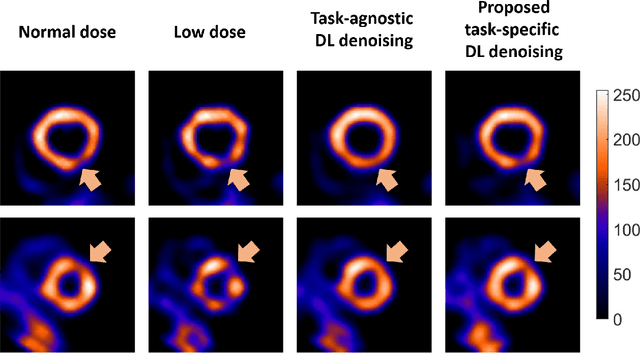
Deep-learning (DL)-based methods have shown significant promise in denoising myocardial perfusion SPECT images acquired at low dose. For clinical application of these methods, evaluation on clinical tasks is crucial. Typically, these methods are designed to minimize some fidelity-based criterion between the predicted denoised image and some reference normal-dose image. However, while promising, studies have shown that these methods may have limited impact on the performance of clinical tasks in SPECT. To address this issue, we use concepts from the literature on model observers and our understanding of the human visual system to propose a DL-based denoising approach designed to preserve observer-related information for detection tasks. The proposed method was objectively evaluated on the task of detecting perfusion defect in myocardial perfusion SPECT images using a retrospective study with anonymized clinical data. Our results demonstrate that the proposed method yields improved performance on this detection task compared to using low-dose images. The results show that by preserving task-specific information, DL may provide a mechanism to improve observer performance in low-dose myocardial perfusion SPECT.
TMS-Net: A Segmentation Network Coupled With A Run-time Quality Control Method For Robust Cardiac Image Segmentation
Dec 21, 2022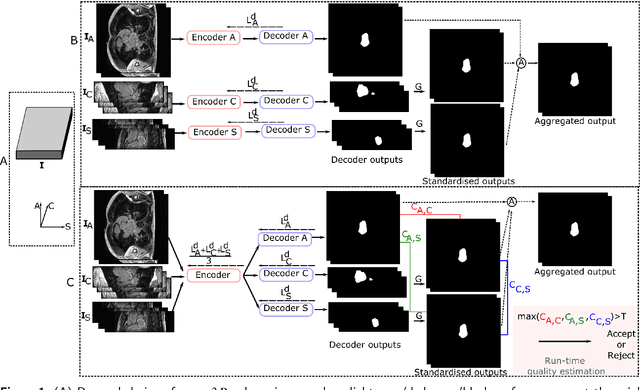
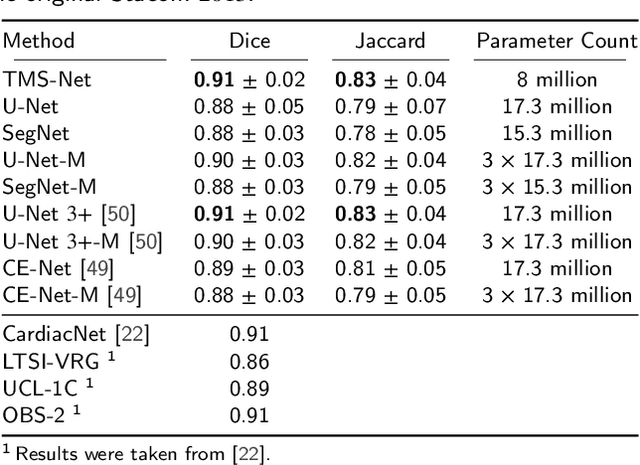
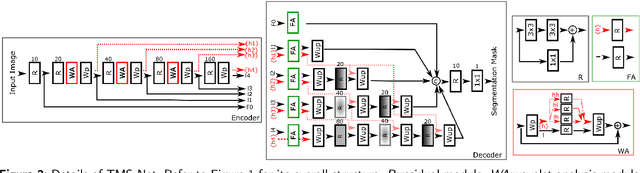
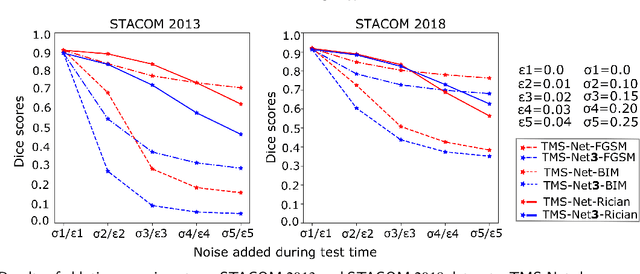
Recently, deep networks have shown impressive performance for the segmentation of cardiac Magnetic Resonance Imaging (MRI) images. However, their achievement is proving slow to transition to widespread use in medical clinics because of robustness issues leading to low trust of clinicians to their results. Predicting run-time quality of segmentation masks can be useful to warn clinicians against poor results. Despite its importance, there are few studies on this problem. To address this gap, we propose a quality control method based on the agreement across decoders of a multi-view network, TMS-Net, measured by the cosine similarity. The network takes three view inputs resliced from the same 3D image along different axes. Different from previous multi-view networks, TMS-Net has a single encoder and three decoders, leading to better noise robustness, segmentation performance and run-time quality estimation in our experiments on the segmentation of the left atrium on STACOM 2013 and STACOM 2018 challenge datasets. We also present a way to generate poor segmentation masks by using noisy images generated with engineered noise and Rician noise to simulate undertraining, high anisotropy and poor imaging settings problems. Our run-time quality estimation method show a good classification of poor and good quality segmentation masks with an AUC reaching to 0.97 on STACOM 2018. We believe that TMS-Net and our run-time quality estimation method has a high potential to increase the thrust of clinicians to automatic image analysis tools.
Markup-to-Image Diffusion Models with Scheduled Sampling
Oct 11, 2022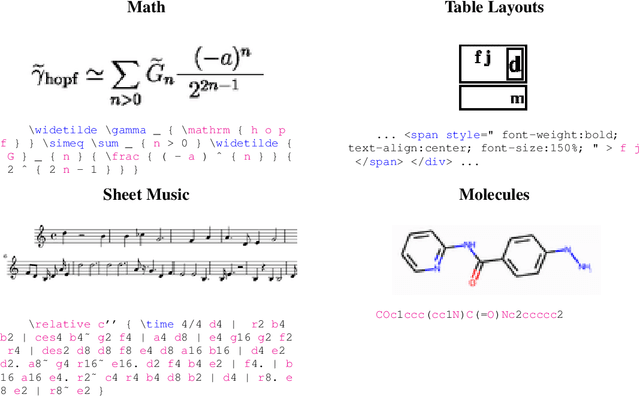

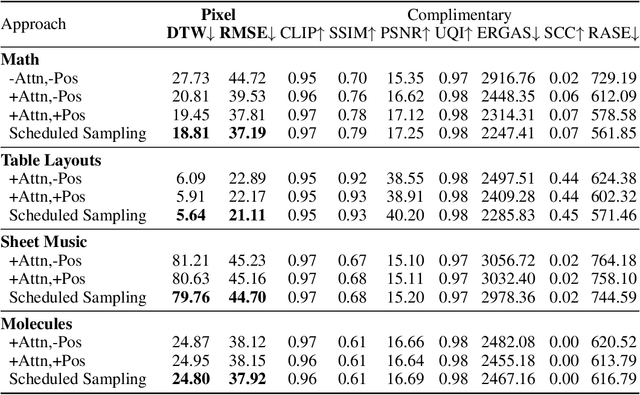
Building on recent advances in image generation, we present a fully data-driven approach to rendering markup into images. The approach is based on diffusion models, which parameterize the distribution of data using a sequence of denoising operations on top of a Gaussian noise distribution. We view the diffusion denoising process as a sequential decision making process, and show that it exhibits compounding errors similar to exposure bias issues in imitation learning problems. To mitigate these issues, we adapt the scheduled sampling algorithm to diffusion training. We conduct experiments on four markup datasets: mathematical formulas (LaTeX), table layouts (HTML), sheet music (LilyPond), and molecular images (SMILES). These experiments each verify the effectiveness of the diffusion process and the use of scheduled sampling to fix generation issues. These results also show that the markup-to-image task presents a useful controlled compositional setting for diagnosing and analyzing generative image models.
ZeroNLG: Aligning and Autoencoding Domains for Zero-Shot Multimodal and Multilingual Natural Language Generation
Mar 11, 2023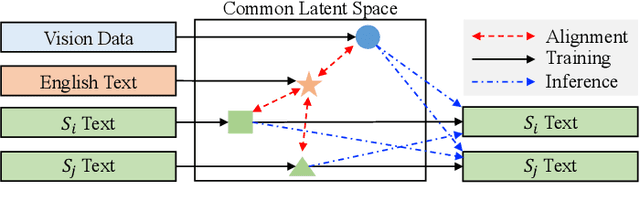
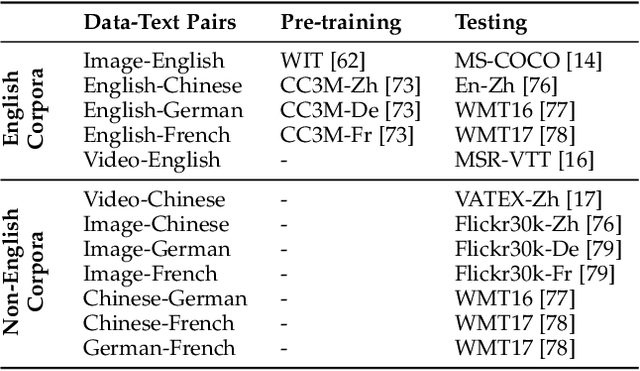
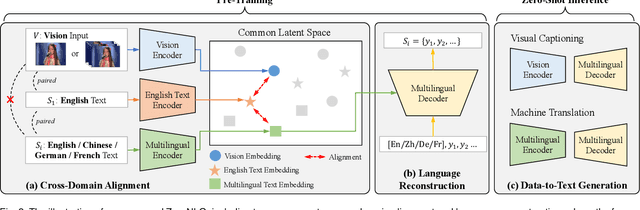
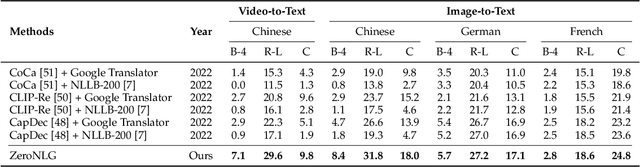
Natural Language Generation (NLG) accepts input data in the form of images, videos, or text and generates corresponding natural language text as output. Existing NLG methods mainly adopt a supervised approach and rely heavily on coupled data-to-text pairs. However, for many targeted scenarios and for non-English languages, sufficient quantities of labeled data are often not available. To relax the dependency on labeled data of downstream tasks, we propose an intuitive and effective zero-shot learning framework, ZeroNLG, which can deal with multiple NLG tasks, including image-to-text (image captioning), video-to-text (video captioning), and text-to-text (neural machine translation), across English, Chinese, German, and French within a unified framework. ZeroNLG does not require any labeled downstream pairs for training. During training, ZeroNLG (i) projects different domains (across modalities and languages) to corresponding coordinates in a shared common latent space; (ii) bridges different domains by aligning their corresponding coordinates in this space; and (iii) builds an unsupervised multilingual auto-encoder to learn to generate text by reconstructing the input text given its coordinate in shared latent space. Consequently, during inference, based on the data-to-text pipeline, ZeroNLG can generate target sentences across different languages given the coordinate of input data in the common space. Within this unified framework, given visual (imaging or video) data as input, ZeroNLG can perform zero-shot visual captioning; given textual sentences as input, ZeroNLG can perform zero-shot machine translation. We present the results of extensive experiments on twelve NLG tasks, showing that, without using any labeled downstream pairs for training, ZeroNLG generates high-quality and believable outputs and significantly outperforms existing zero-shot methods.
Semantic-aware Texture-Structure Feature Collaboration for Underwater Image Enhancement
Nov 19, 2022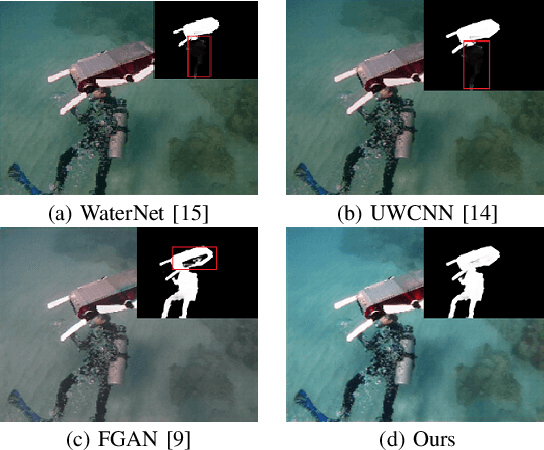
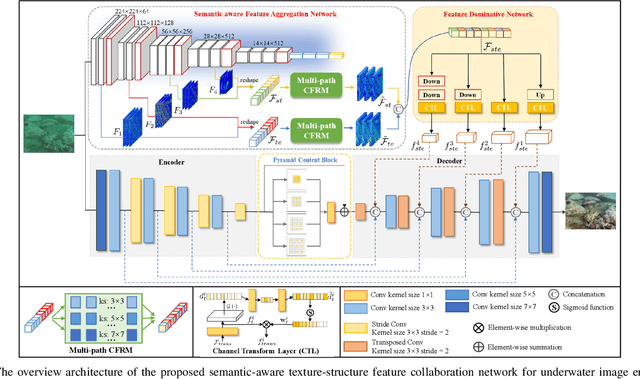
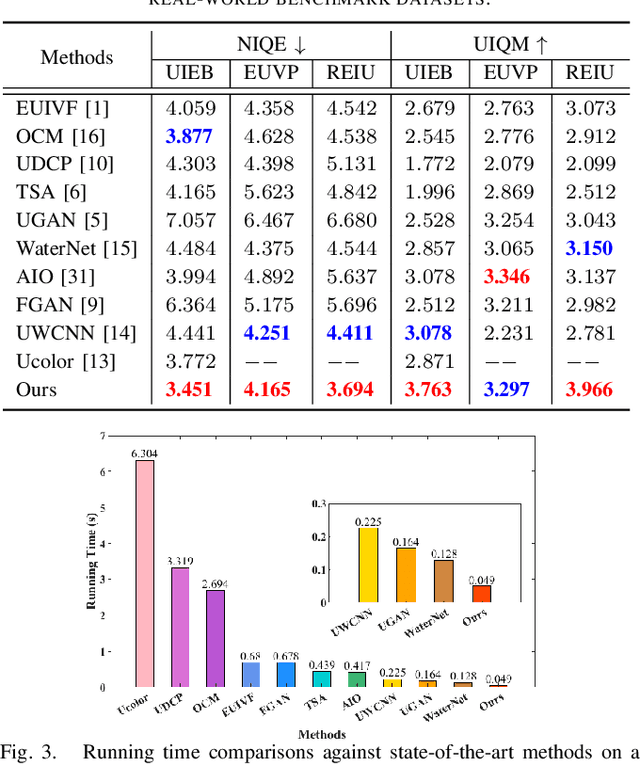

Underwater image enhancement has become an attractive topic as a significant technology in marine engineering and aquatic robotics. However, the limited number of datasets and imperfect hand-crafted ground truth weaken its robustness to unseen scenarios, and hamper the application to high-level vision tasks. To address the above limitations, we develop an efficient and compact enhancement network in collaboration with a high-level semantic-aware pretrained model, aiming to exploit its hierarchical feature representation as an auxiliary for the low-level underwater image enhancement. Specifically, we tend to characterize the shallow layer features as textures while the deep layer features as structures in the semantic-aware model, and propose a multi-path Contextual Feature Refinement Module (CFRM) to refine features in multiple scales and model the correlation between different features. In addition, a feature dominative network is devised to perform channel-wise modulation on the aggregated texture and structure features for the adaptation to different feature patterns of the enhancement network. Extensive experiments on benchmarks demonstrate that the proposed algorithm achieves more appealing results and outperforms state-of-the-art methods by large margins. We also apply the proposed algorithm to the underwater salient object detection task to reveal the favorable semantic-aware ability for high-level vision tasks. The code is available at STSC.
CFNet: Conditional Filter Learning with Dynamic Noise Estimation for Real Image Denoising
Nov 26, 2022
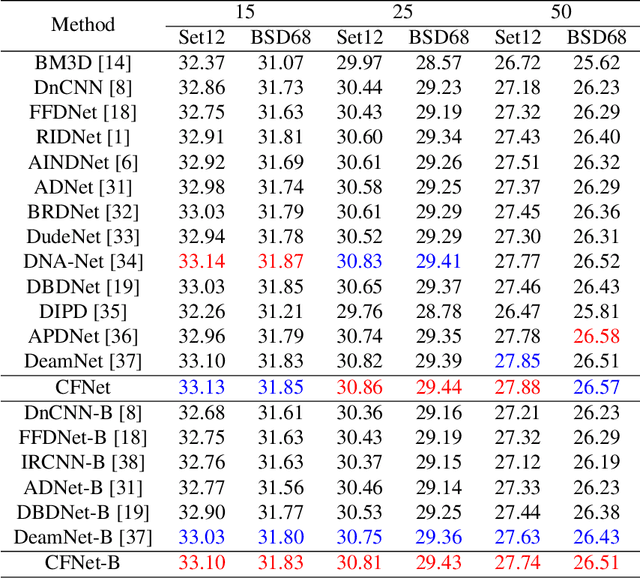
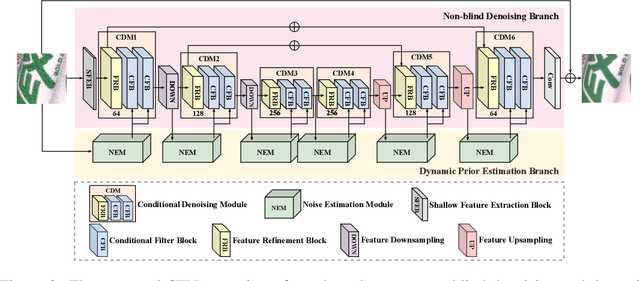
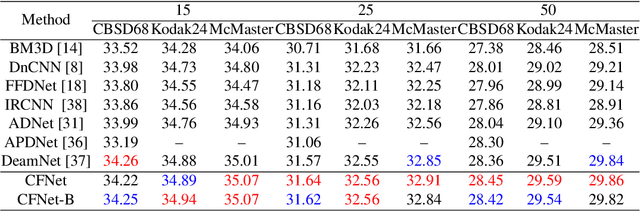
A mainstream type of the state of the arts (SOTAs) based on convolutional neural network (CNN) for real image denoising contains two sub-problems, i.e., noise estimation and non-blind denoising. This paper considers real noise approximated by heteroscedastic Gaussian/Poisson Gaussian distributions with in-camera signal processing pipelines. The related works always exploit the estimated noise prior via channel-wise concatenation followed by a convolutional layer with spatially sharing kernels. Due to the variable modes of noise strength and frequency details of all feature positions, this design cannot adaptively tune the corresponding denoising patterns. To address this problem, we propose a novel conditional filter in which the optimal kernels for different feature positions can be adaptively inferred by local features from the image and the noise map. Also, we bring the thought that alternatively performs noise estimation and non-blind denoising into CNN structure, which continuously updates noise prior to guide the iterative feature denoising. In addition, according to the property of heteroscedastic Gaussian distribution, a novel affine transform block is designed to predict the stationary noise component and the signal-dependent noise component. Compared with SOTAs, extensive experiments are conducted on five synthetic datasets and three real datasets, which shows the improvement of the proposed CFNet.
Deep Composite Face Image Attacks: Generation, Vulnerability and Detection
Nov 20, 2022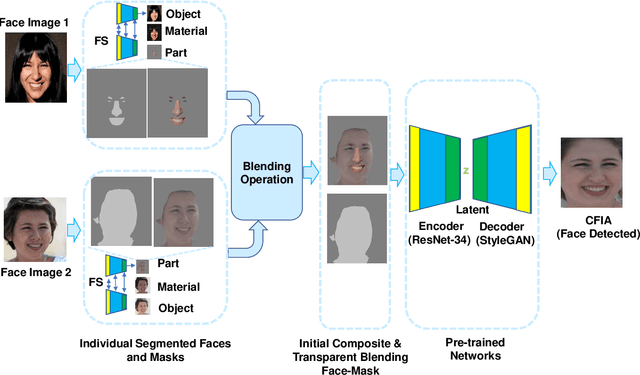
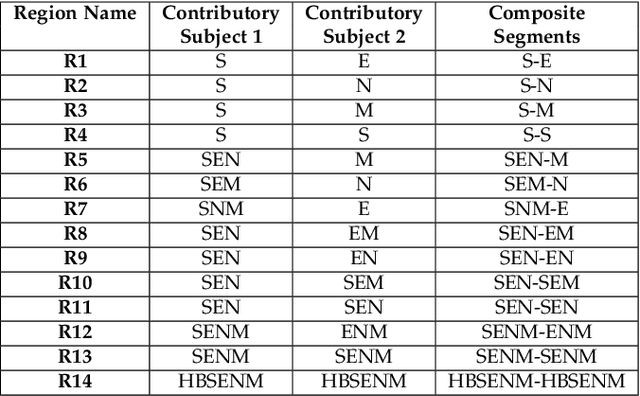
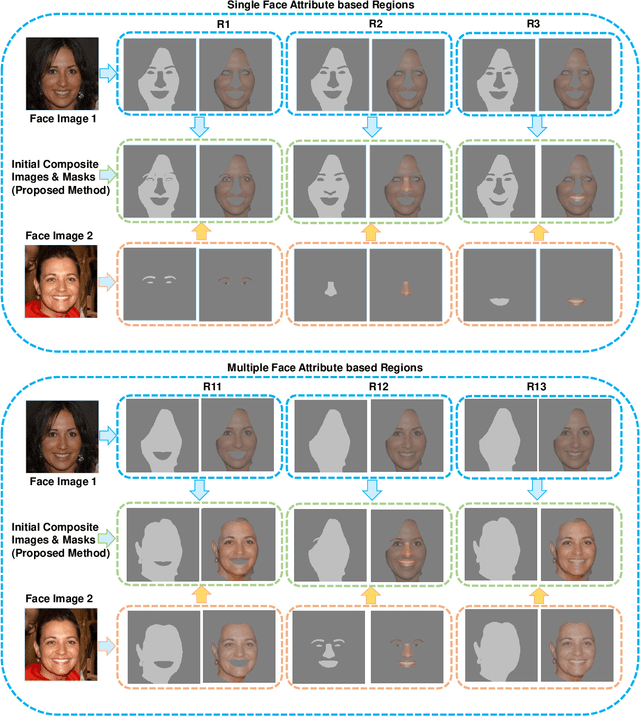
Face manipulation attacks have drawn the attention of biometric researchers because of their vulnerability to Face Recognition Systems (FRS). This paper proposes a novel scheme to generate Composite Face Image Attacks (CFIA) based on the Generative Adversarial Networks (GANs). Given the face images from contributory data subjects, the proposed CFIA method will independently generate the segmented facial attributes, then blend them using transparent masks to generate the CFIA samples. { The primary motivation for CFIA is to utilize deep learning to generate facial attribute-based composite attacks, which has been explored relatively less in the current literature.} We generate $14$ different combinations of facial attributes resulting in $14$ unique CFIA samples for each pair of contributory data subjects. Extensive experiments are carried out on our newly generated CFIA dataset consisting of 1000 unique identities with 2000 bona fide samples and 14000 CFIA samples, thus resulting in an overall 16000 face image samples. We perform a sequence of experiments to benchmark the vulnerability of CFIA to automatic FRS (based on both deep-learning and commercial-off-the-shelf (COTS). We introduced a new metric named Generalized Morphing Attack Potential (GMAP) to benchmark the vulnerability effectively. Additional experiments are performed to compute the perceptual quality of the generated CFIA samples. Finally, the CFIA detection performance is presented using three different Face Morphing Attack Detection (MAD) algorithms. The proposed CFIA method indicates good perceptual quality based on the obtained results. Further, { FRS is vulnerable to CFIA} (much higher than SOTA), making it difficult to detect by human observers and automatic detection algorithms. Lastly, we performed experiments to detect the CFIA samples using three different detection techniques automatically.
Connecting Vision and Language with Video Localized Narratives
Mar 15, 2023
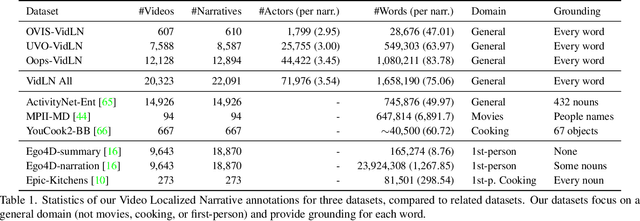


We propose Video Localized Narratives, a new form of multimodal video annotations connecting vision and language. In the original Localized Narratives, annotators speak and move their mouse simultaneously on an image, thus grounding each word with a mouse trace segment. However, this is challenging on a video. Our new protocol empowers annotators to tell the story of a video with Localized Narratives, capturing even complex events involving multiple actors interacting with each other and with several passive objects. We annotated 20k videos of the OVIS, UVO, and Oops datasets, totalling 1.7M words. Based on this data, we also construct new benchmarks for the video narrative grounding and video question answering tasks, and provide reference results from strong baseline models. Our annotations are available at https://google.github.io/video-localized-narratives/.
UniCT DMI Solution for 3rd COV19D Competition on COVID-19 Detection trough attention deep learning for CT Scan
Mar 15, 2023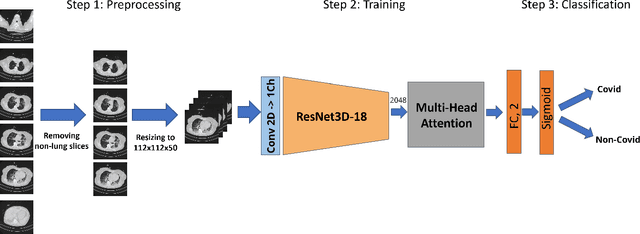
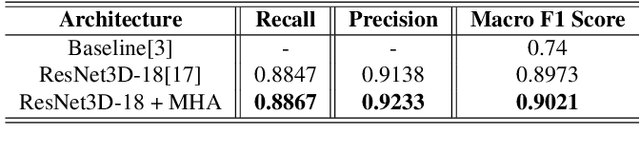
This paper presents our solution for the first challenge of the 3rd Covid-19 competition, which is part of the "AI-enabled Medical Image Analysis Workshop" organized by IEEE International Conference on Acoustic, Speech and Signal Processing (ICASSP) 2023. Our proposed solution is based on a Resnet as a backbone network with the addition of attention mechanisms. The Resnet provides an effective feature extractor for the classification task, while the attention mechanisms improve the model's ability to focus on important regions of interest within the images. We conducted extensive experiments on the provided dataset and achieved promising results. Our proposed approach has the potential to assist in the accurate diagnosis of Covid-19 from chest computed tomography images, which can aid in the early detection and management of the disease.
Lossy Image Compression with Conditional Diffusion Models
Sep 14, 2022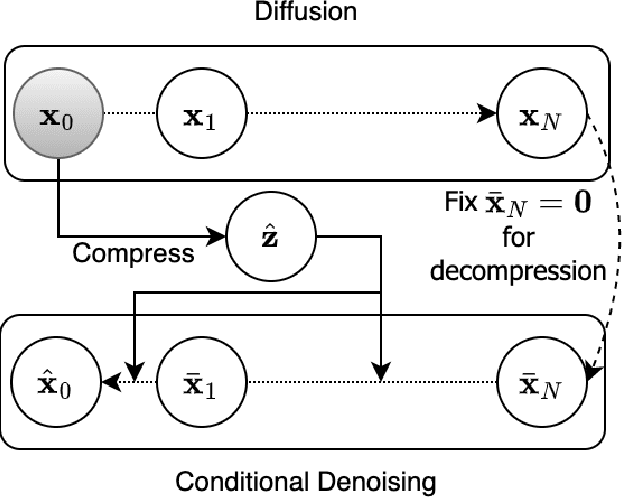

Diffusion models are a new class of generative models that mark a milestone in high-quality image generation while relying on solid probabilistic principles. This makes them promising candidate models for neural image compression. This paper outlines an end-to-end optimized framework based on a conditional diffusion model for image compression. Besides latent variables inherent to the diffusion process, the model introduces an additional per-instance "content" latent variable to condition the denoising process. Upon decoding, the diffusion process conditionally generates/reconstructs an image using ancestral sampling. Our experiments show that this approach outperforms one of the best-performing conventional image codecs (BPG) and one neural codec on two compression benchmarks, where we focus on rate-perception tradeoffs. Qualitatively, our approach shows fewer decompression artifacts than the classical approach.