 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Robust Sound-Guided Image Manipulation
Aug 31, 2022

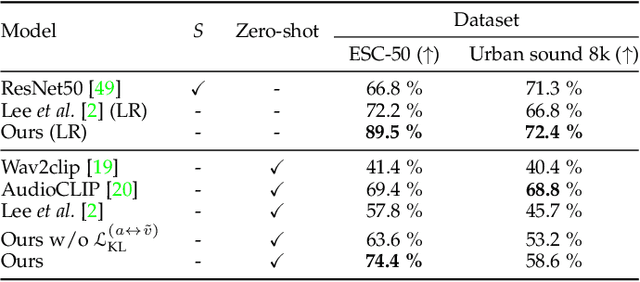


Recent successes suggest that an image can be manipulated by a text prompt, e.g., a landscape scene on a sunny day is manipulated into the same scene on a rainy day driven by a text input "raining". These approaches often utilize a StyleCLIP-based image generator, which leverages multi-modal (text and image) embedding space. However, we observe that such text inputs are often bottlenecked in providing and synthesizing rich semantic cues, e.g., differentiating heavy rain from rain with thunderstorms. To address this issue, we advocate leveraging an additional modality, sound, which has notable advantages in image manipulation as it can convey more diverse semantic cues (vivid emotions or dynamic expressions of the natural world) than texts. In this paper, we propose a novel approach that first extends the image-text joint embedding space with sound and applies a direct latent optimization method to manipulate a given image based on audio input, e.g., the sound of rain. Our extensive experiments show that our sound-guided image manipulation approach produces semantically and visually more plausible manipulation results than the state-of-the-art text and sound-guided image manipulation methods, which are further confirmed by our human evaluations. Our downstream task evaluations also show that our learned image-text-sound joint embedding space effectively encodes sound inputs.
Modelos Generativos basados en Mecanismos de Difusión
Feb 18, 2023Diffusion-based generative models are a design framework that allows generating new images from processes analogous to those found in non-equilibrium thermodynamics. These models model the reversal of a physical diffusion process in which two miscible liquids of different colors progressively mix until they form a homogeneous mixture. Diffusion models can be applied to signals of a different nature, such as audio and image signals. In the image case, a progressive pixel corruption process is carried out by applying random noise, and a neural network is trained to revert each one of the corruption steps. For the reconstruction process to be reversible, it is necessary to carry out the corruption very progressively. If the training of the neural network is successful, it will be possible to generate an image from random noise by chaining a number of steps similar to those used for image deconstruction at training time. In this article we present the theoretical foundations on which this method is based as well as some of its applications. This article is in Spanish to facilitate the arrival of this scientific knowledge to the Spanish-speaking community.
Improving Fairness in Image Classification via Sketching
Oct 31, 2022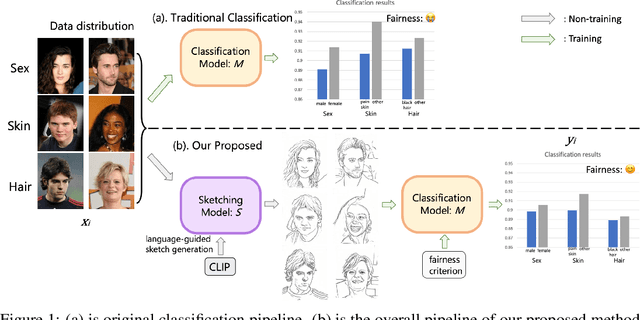


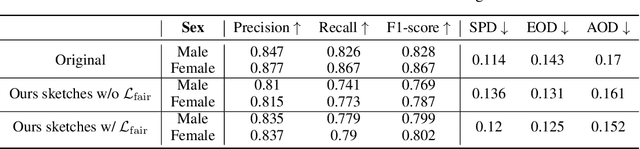
Fairness is a fundamental requirement for trustworthy and human-centered Artificial Intelligence (AI) system. However, deep neural networks (DNNs) tend to make unfair predictions when the training data are collected from different sub-populations with different attributes (i.e. color, sex, age), leading to biased DNN predictions. We notice that such a troubling phenomenon is often caused by data itself, which means that bias information is encoded to the DNN along with the useful information (i.e. class information, semantic information). Therefore, we propose to use sketching to handle this phenomenon. Without losing the utility of data, we explore the image-to-sketching methods that can maintain useful semantic information for the target classification while filtering out the useless bias information. In addition, we design a fair loss to further improve the model fairness. We evaluate our method through extensive experiments on both general scene dataset and medical scene dataset. Our results show that the desired image-to-sketching method improves model fairness and achieves satisfactory results among state-of-the-art.
Style Augmentation improves Medical Image Segmentation
Nov 02, 2022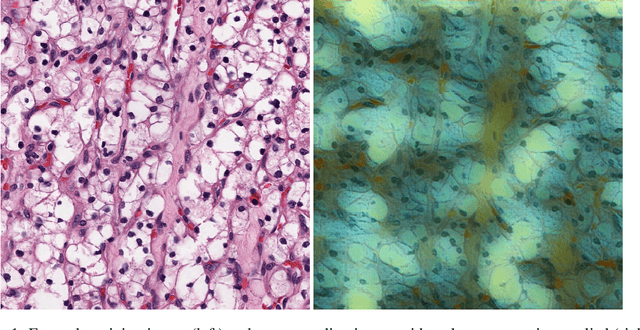
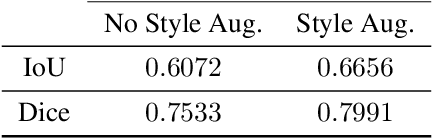


Due to the limitation of available labeled data, medical image segmentation is a challenging task for deep learning. Traditional data augmentation techniques have been shown to improve segmentation network performances by optimizing the usage of few training examples. However, current augmentation approaches for segmentation do not tackle the strong texture bias of convolutional neural networks, observed in several studies. This work shows on the MoNuSeg dataset that style augmentation, which is already used in classification tasks, helps reducing texture over-fitting and improves segmentation performance.
HOICLIP: Efficient Knowledge Transfer for HOI Detection with Vision-Language Models
Mar 29, 2023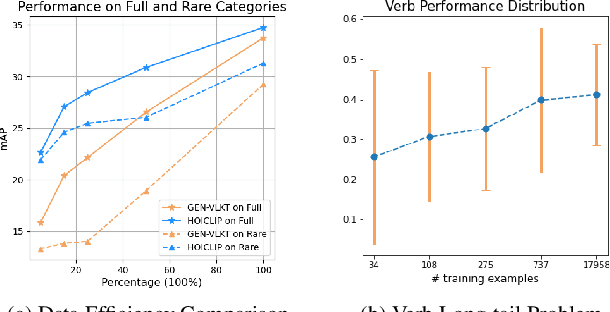
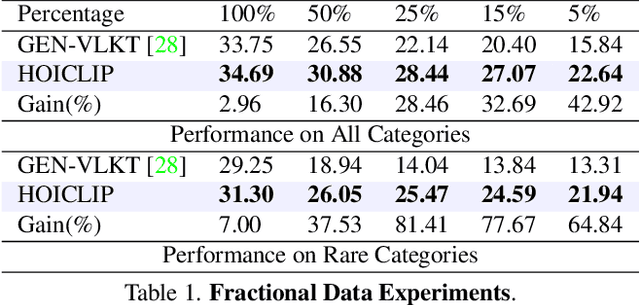
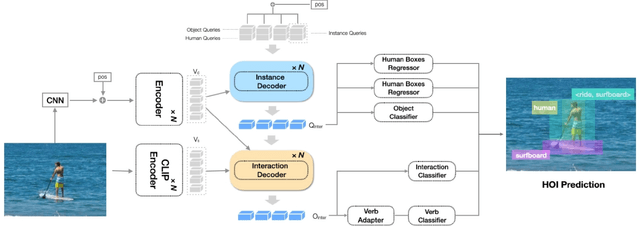
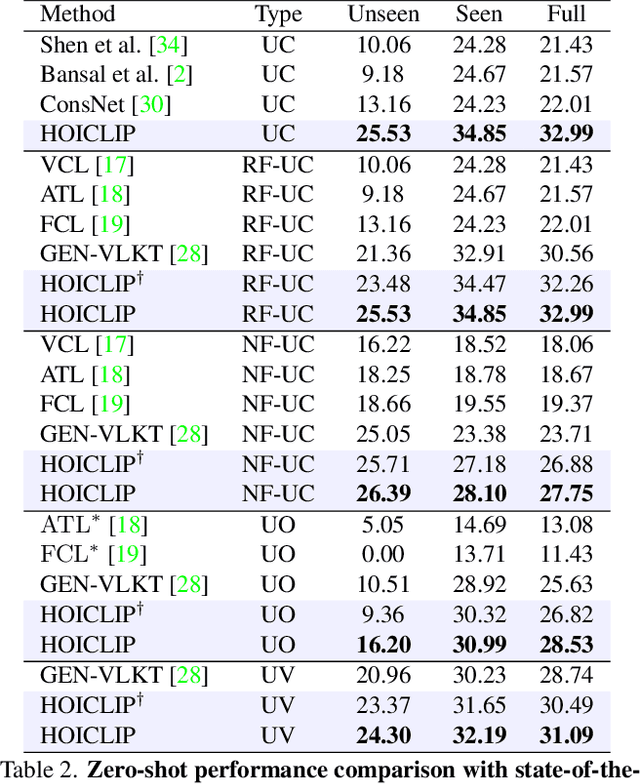
Human-Object Interaction (HOI) detection aims to localize human-object pairs and recognize their interactions. Recently, Contrastive Language-Image Pre-training (CLIP) has shown great potential in providing interaction prior for HOI detectors via knowledge distillation. However, such approaches often rely on large-scale training data and suffer from inferior performance under few/zero-shot scenarios. In this paper, we propose a novel HOI detection framework that efficiently extracts prior knowledge from CLIP and achieves better generalization. In detail, we first introduce a novel interaction decoder to extract informative regions in the visual feature map of CLIP via a cross-attention mechanism, which is then fused with the detection backbone by a knowledge integration block for more accurate human-object pair detection. In addition, prior knowledge in CLIP text encoder is leveraged to generate a classifier by embedding HOI descriptions. To distinguish fine-grained interactions, we build a verb classifier from training data via visual semantic arithmetic and a lightweight verb representation adapter. Furthermore, we propose a training-free enhancement to exploit global HOI predictions from CLIP. Extensive experiments demonstrate that our method outperforms the state of the art by a large margin on various settings, e.g. +4.04 mAP on HICO-Det. The source code is available in https://github.com/Artanic30/HOICLIP.
Depth-based 6DoF Object Pose Estimation using Swin Transformer
Mar 03, 2023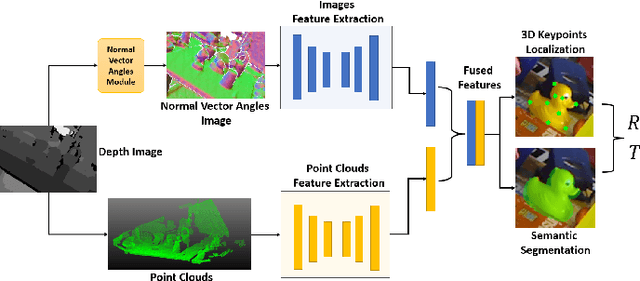
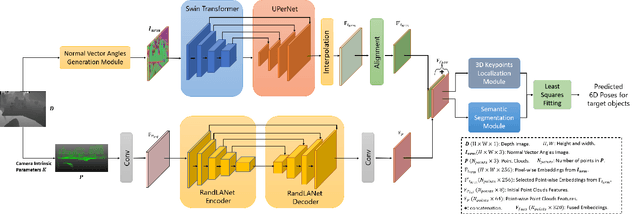
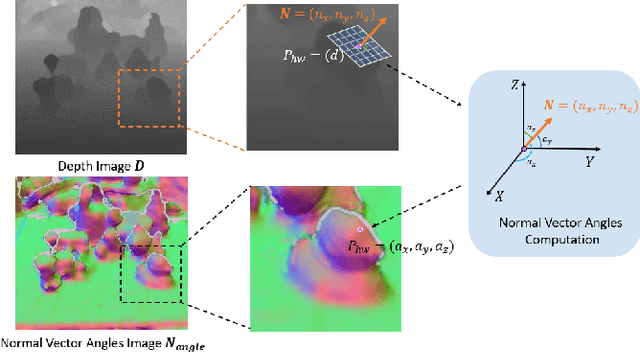
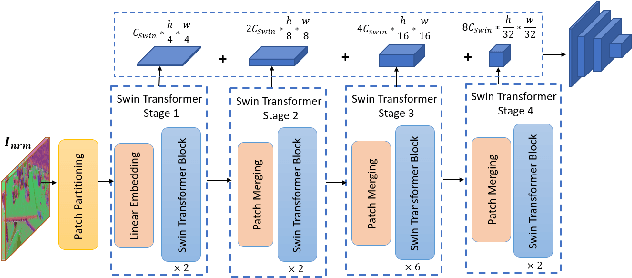
Accurately estimating the 6D pose of objects is crucial for many applications, such as robotic grasping, autonomous driving, and augmented reality. However, this task becomes more challenging in poor lighting conditions or when dealing with textureless objects. To address this issue, depth images are becoming an increasingly popular choice due to their invariance to a scene's appearance and the implicit incorporation of essential geometric characteristics. However, fully leveraging depth information to improve the performance of pose estimation remains a difficult and under-investigated problem. To tackle this challenge, we propose a novel framework called SwinDePose, that uses only geometric information from depth images to achieve accurate 6D pose estimation. SwinDePose first calculates the angles between each normal vector defined in a depth image and the three coordinate axes in the camera coordinate system. The resulting angles are then formed into an image, which is encoded using Swin Transformer. Additionally, we apply RandLA-Net to learn the representations from point clouds. The resulting image and point clouds embeddings are concatenated and fed into a semantic segmentation module and a 3D keypoints localization module. Finally, we estimate 6D poses using a least-square fitting approach based on the target object's predicted semantic mask and 3D keypoints. In experiments on the LineMod and Occlusion LineMod datasets, SwinDePose outperforms existing state-of-the-art methods for 6D object pose estimation using depth images. This demonstrates the effectiveness of our approach and highlights its potential for improving performance in real-world scenarios. Our code is at https://github.com/zhujunli1993/SwinDePose.
DEPAS: De-novo Pathology Semantic Masks using a Generative Model
Feb 13, 2023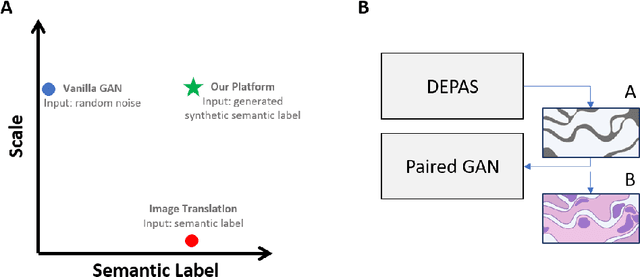
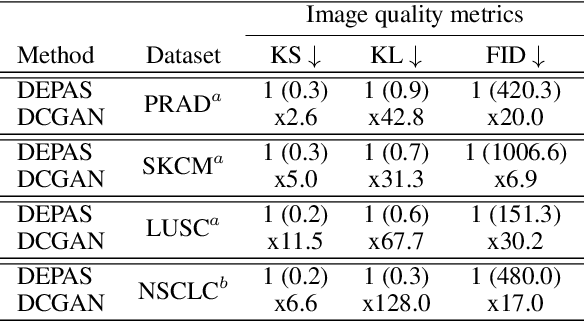
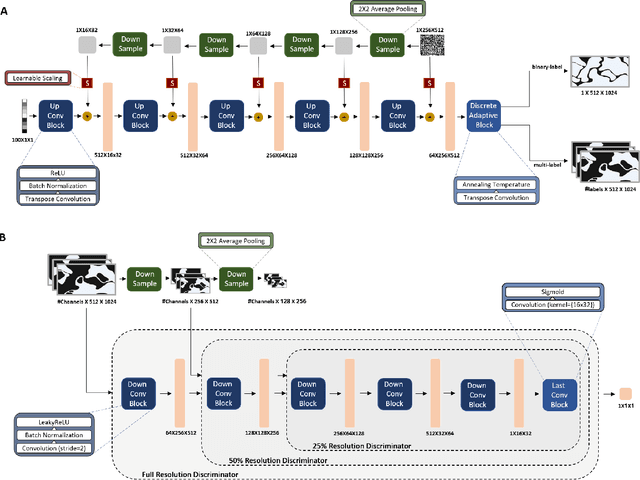
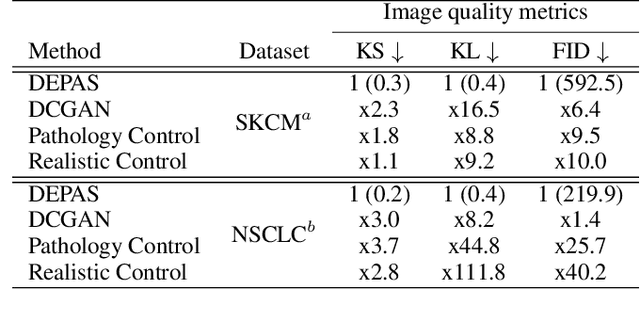
The integration of artificial intelligence into digital pathology has the potential to automate and improve various tasks, such as image analysis and diagnostic decision-making. Yet, the inherent variability of tissues, together with the need for image labeling, lead to biased datasets that limit the generalizability of algorithms trained on them. One of the emerging solutions for this challenge is synthetic histological images. However, debiasing real datasets require not only generating photorealistic images but also the ability to control the features within them. A common approach is to use generative methods that perform image translation between semantic masks that reflect prior knowledge of the tissue and a histological image. However, unlike other image domains, the complex structure of the tissue prevents a simple creation of histology semantic masks that are required as input to the image translation model, while semantic masks extracted from real images reduce the process's scalability. In this work, we introduce a scalable generative model, coined as DEPAS, that captures tissue structure and generates high-resolution semantic masks with state-of-the-art quality. We demonstrate the ability of DEPAS to generate realistic semantic maps of tissue for three types of organs: skin, prostate, and lung. Moreover, we show that these masks can be processed using a generative image translation model to produce photorealistic histology images of two types of cancer with two different types of staining techniques. Finally, we harness DEPAS to generate multi-label semantic masks that capture different cell types distributions and use them to produce histological images with on-demand cellular features. Overall, our work provides a state-of-the-art solution for the challenging task of generating synthetic histological images while controlling their semantic information in a scalable way.
Semantic Brain Decoding: from fMRI to conceptually similar image reconstruction of visual stimuli
Dec 13, 2022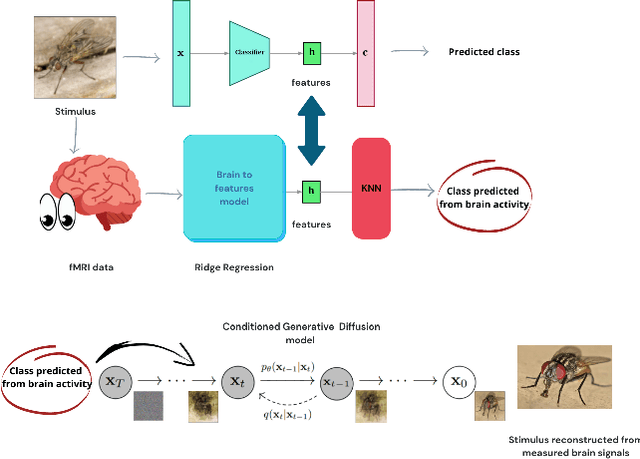
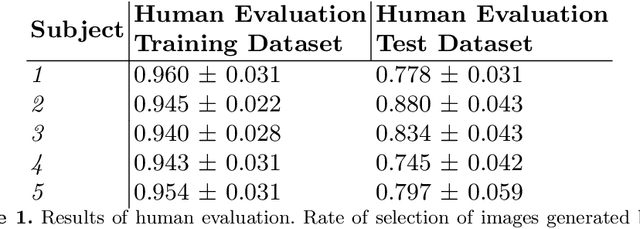
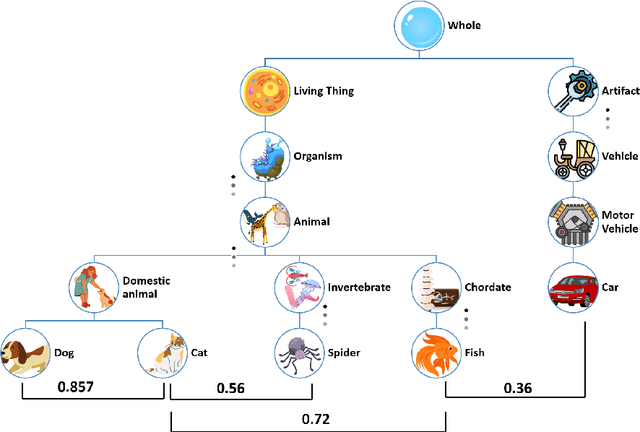

Brain decoding is a field of computational neuroscience that uses measurable brain activity to infer mental states or internal representations of perceptual inputs. Therefore, we propose a novel approach to brain decoding that also relies on semantic and contextual similarity. We employ an fMRI dataset of natural image vision and create a deep learning decoding pipeline inspired by the existence of both bottom-up and top-down processes in human vision. We train a linear brain-to-feature model to map fMRI activity features to visual stimuli features, assuming that the brain projects visual information onto a space that is homeomorphic to the latent space represented by the last convolutional layer of a pretrained convolutional neural network, which typically collects a variety of semantic features that summarize and highlight similarities and differences between concepts. These features are then categorized in the latent space using a nearest-neighbor strategy, and the results are used to condition a generative latent diffusion model to create novel images. From fMRI data only, we produce reconstructions of visual stimuli that match the original content very well on a semantic level, surpassing the state of the art in previous literature. We evaluate our work and obtain good results using a quantitative semantic metric (the Wu-Palmer similarity metric over the WordNet lexicon, which had an average value of 0.57) and perform a human evaluation experiment that resulted in correct evaluation, according to the multiplicity of human criteria in evaluating image similarity, in over 80% of the test set.
Foundation Model Drives Weakly Incremental Learning for Semantic Segmentation
Feb 28, 2023
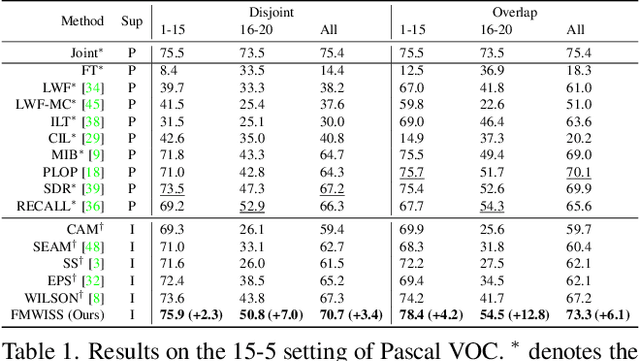
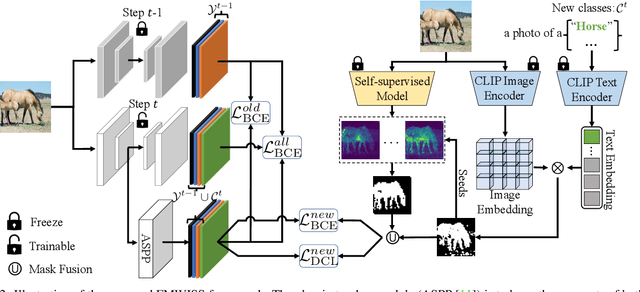
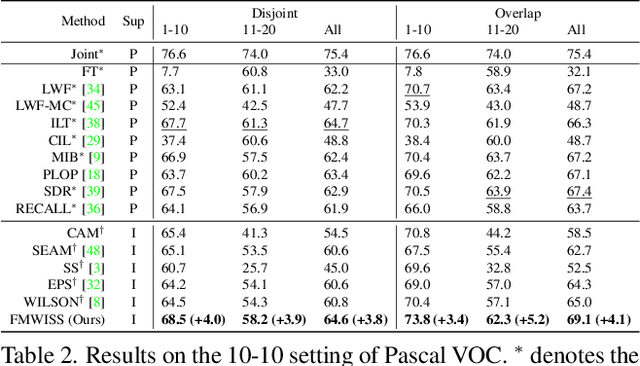
Modern incremental learning for semantic segmentation methods usually learn new categories based on dense annotations. Although achieve promising results, pixel-by-pixel labeling is costly and time-consuming. Weakly incremental learning for semantic segmentation (WILSS) is a novel and attractive task, which aims at learning to segment new classes from cheap and widely available image-level labels. Despite the comparable results, the image-level labels can not provide details to locate each segment, which limits the performance of WILSS. This inspires us to think how to improve and effectively utilize the supervision of new classes given image-level labels while avoiding forgetting old ones. In this work, we propose a novel and data-efficient framework for WILSS, named FMWISS. Specifically, we propose pre-training based co-segmentation to distill the knowledge of complementary foundation models for generating dense pseudo labels. We further optimize the noisy pseudo masks with a teacher-student architecture, where a plug-in teacher is optimized with a proposed dense contrastive loss. Moreover, we introduce memory-based copy-paste augmentation to improve the catastrophic forgetting problem of old classes. Extensive experiments on Pascal VOC and COCO datasets demonstrate the superior performance of our framework, e.g., FMWISS achieves 70.7% and 73.3% in the 15-5 VOC setting, outperforming the state-of-the-art method by 3.4% and 6.1%, respectively.
Markerless Camera-to-Robot Pose Estimation via Self-supervised Sim-to-Real Transfer
Feb 28, 2023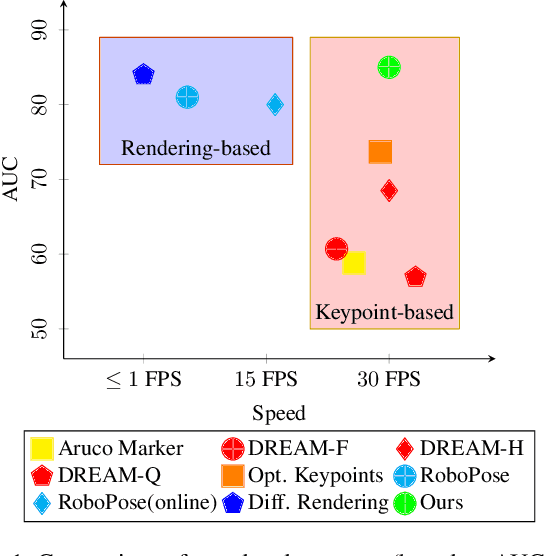

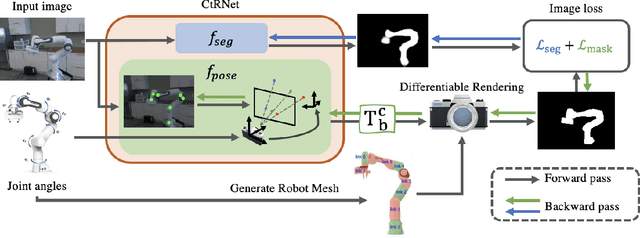
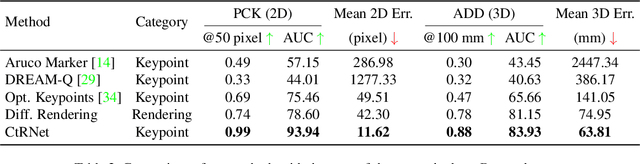
Solving the camera-to-robot pose is a fundamental requirement for vision-based robot control, and is a process that takes considerable effort and cares to make accurate. Traditional approaches require modification of the robot via markers, and subsequent deep learning approaches enabled markerless feature extraction. Mainstream deep learning methods only use synthetic data and rely on Domain Randomization to fill the sim-to-real gap, because acquiring the 3D annotation is labor-intensive. In this work, we go beyond the limitation of 3D annotations for real-world data. We propose an end-to-end pose estimation framework that is capable of online camera-to-robot calibration and a self-supervised training method to scale the training to unlabeled real-world data. Our framework combines deep learning and geometric vision for solving the robot pose, and the pipeline is fully differentiable. To train the Camera-to-Robot Pose Estimation Network (CtRNet), we leverage foreground segmentation and differentiable rendering for image-level self-supervision. The pose prediction is visualized through a renderer and the image loss with the input image is back-propagated to train the neural network. Our experimental results on two public real datasets confirm the effectiveness of our approach over existing works. We also integrate our framework into a visual servoing system to demonstrate the promise of real-time precise robot pose estimation for automation tasks.