 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Cross-View Visual Geo-Localization for Outdoor Augmented Reality
Mar 28, 2023
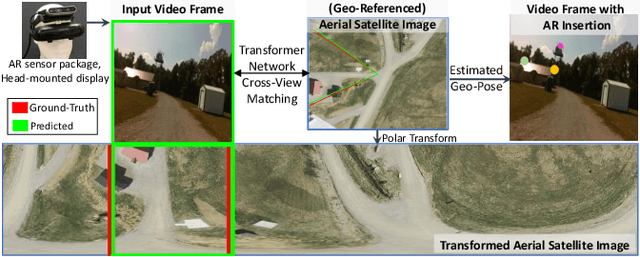
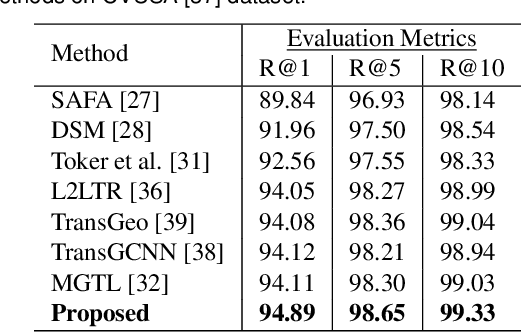
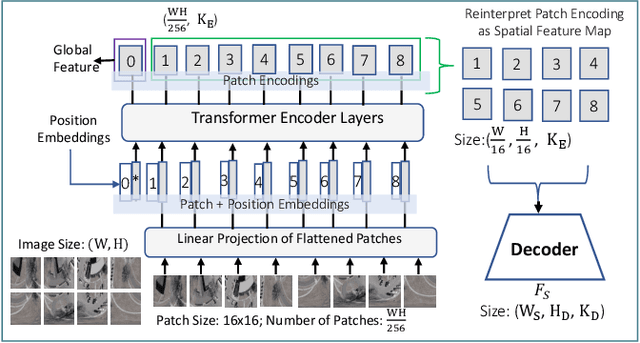
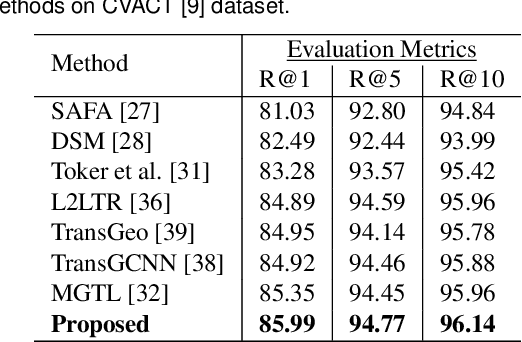
Precise estimation of global orientation and location is critical to ensure a compelling outdoor Augmented Reality (AR) experience. We address the problem of geo-pose estimation by cross-view matching of query ground images to a geo-referenced aerial satellite image database. Recently, neural network-based methods have shown state-of-the-art performance in cross-view matching. However, most of the prior works focus only on location estimation, ignoring orientation, which cannot meet the requirements in outdoor AR applications. We propose a new transformer neural network-based model and a modified triplet ranking loss for joint location and orientation estimation. Experiments on several benchmark cross-view geo-localization datasets show that our model achieves state-of-the-art performance. Furthermore, we present an approach to extend the single image query-based geo-localization approach by utilizing temporal information from a navigation pipeline for robust continuous geo-localization. Experimentation on several large-scale real-world video sequences demonstrates that our approach enables high-precision and stable AR insertion.
Agronav: Autonomous Navigation Framework for Agricultural Robots and Vehicles using Semantic Segmentation and Semantic Line Detection
Apr 10, 2023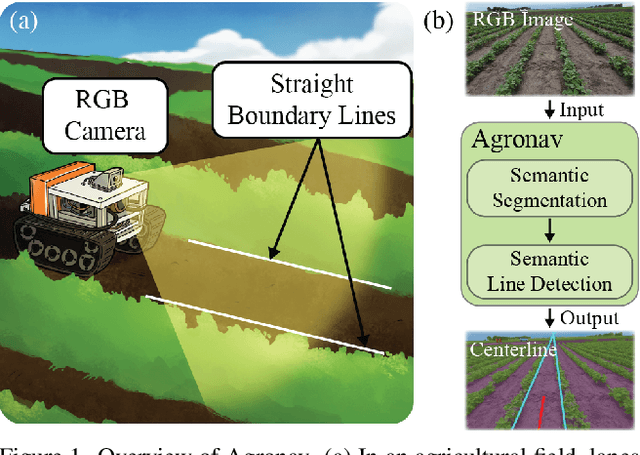
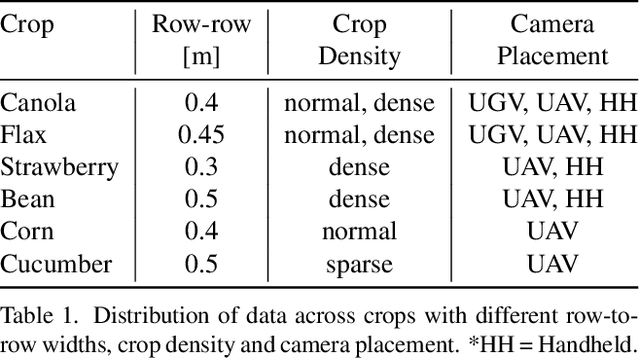

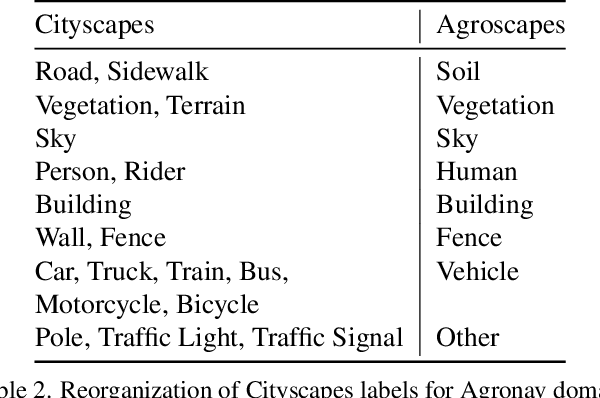
The successful implementation of vision-based navigation in agricultural fields hinges upon two critical components: 1) the accurate identification of key components within the scene, and 2) the identification of lanes through the detection of boundary lines that separate the crops from the traversable ground. We propose Agronav, an end-to-end vision-based autonomous navigation framework, which outputs the centerline from the input image by sequentially processing it through semantic segmentation and semantic line detection models. We also present Agroscapes, a pixel-level annotated dataset collected across six different crops, captured from varying heights and angles. This ensures that the framework trained on Agroscapes is generalizable across both ground and aerial robotic platforms. Codes, models and dataset will be released at \href{https://github.com/shivamkumarpanda/agronav}{github.com/shivamkumarpanda/agronav}.
LitCall: Learning Implicit Topology for CNN-based Aortic Landmark Localization
Apr 15, 2023Landmark detection is a critical component of the image processing pipeline for automated aortic size measurements. Given that the thoracic aorta has a relatively conserved topology across the population and that a human annotator with minimal training can estimate the location of unseen landmarks from limited examples, we proposed an auxiliary learning task to learn the implicit topology of aortic landmarks through a CNN-based network. Specifically, we created a network to predict the location of missing landmarks from the visible ones by minimizing the Implicit Topology loss in an end-to-end manner. The proposed learning task can be easily adapted and combined with Unet-style backbones. To validate our method, we utilized a dataset consisting of 207 CTAs, labeling four landmarks on each aorta. Our method outperforms the state-of-the-art Unet-style architectures (ResUnet, UnetR) in terms of localization accuracy, with only a light (#params=0.4M) overhead. We also demonstrate our approach in two clinically meaningful applications: aortic sub-region division and automatic centerline generation.
CoopInit: Initializing Generative Adversarial Networks via Cooperative Learning
Mar 21, 2023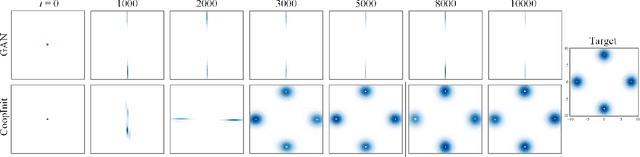
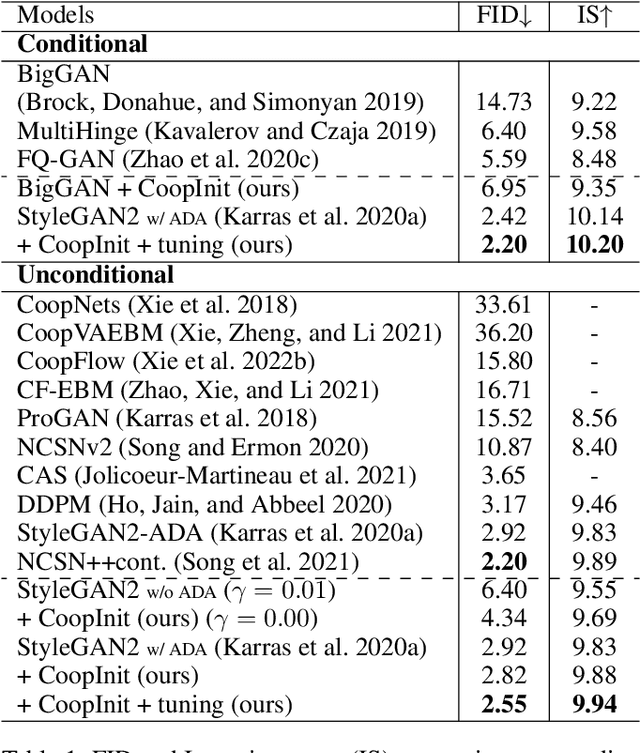

Numerous research efforts have been made to stabilize the training of the Generative Adversarial Networks (GANs), such as through regularization and architecture design. However, we identify the instability can also arise from the fragile balance at the early stage of adversarial learning. This paper proposes the CoopInit, a simple yet effective cooperative learning-based initialization strategy that can quickly learn a good starting point for GANs, with a very small computation overhead during training. The proposed algorithm consists of two learning stages: (i) Cooperative initialization stage: The discriminator of GAN is treated as an energy-based model (EBM) and is optimized via maximum likelihood estimation (MLE), with the help of the GAN's generator to provide synthetic data to approximate the learning gradients. The EBM also guides the MLE learning of the generator via MCMC teaching; (ii) Adversarial finalization stage: After a few iterations of initialization, the algorithm seamlessly transits to the regular mini-max adversarial training until convergence. The motivation is that the MLE-based initialization stage drives the model towards mode coverage, which is helpful in alleviating the issue of mode dropping during the adversarial learning stage. We demonstrate the effectiveness of the proposed approach on image generation and one-sided unpaired image-to-image translation tasks through extensive experiments.
* 9 pages of main text, 2 pages of references
Feature Unlearning for Generative Models via Implicit Feedback
Mar 10, 2023
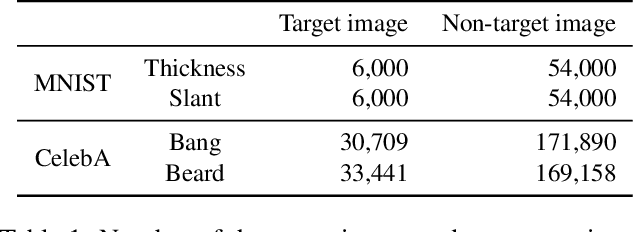
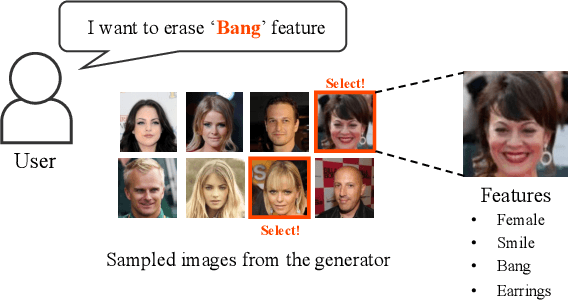
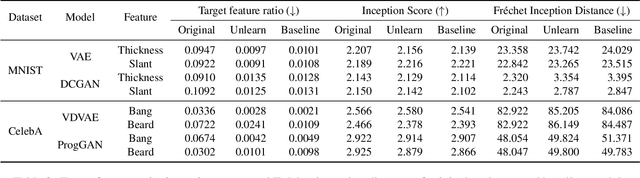
We tackle the problem of feature unlearning from a pretrained image generative model. Unlike a common unlearning task where an unlearning target is a subset of the training set, we aim to unlearn a specific feature, such as hairstyle from facial images, from the pretrained generative models. As the target feature is only presented in a local region of an image, unlearning the entire image from the pretrained model may result in losing other details in the remaining region of the image. To specify which features to unlearn, we develop an implicit feedback mechanism where a user can select images containing the target feature. From the implicit feedback, we identify a latent representation corresponding to the target feature and then use the representation to unlearn the generative model. Our framework is generalizable for the two well-known families of generative models: GANs and VAEs. Through experiments on MNIST and CelebA datasets, we show that target features are successfully removed while keeping the fidelity of the original models.
HabitatDyn Dataset: Dynamic Object Detection to Kinematics Estimation
Apr 21, 2023

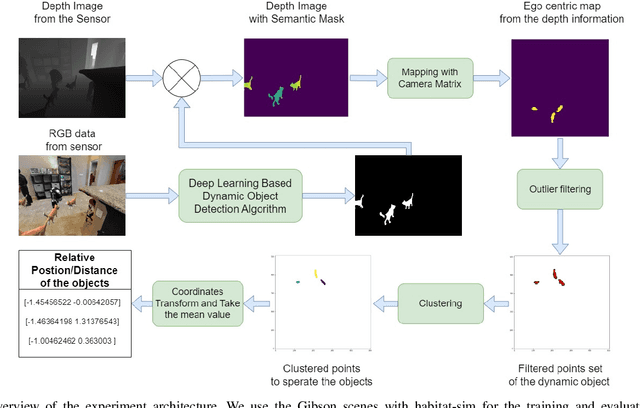
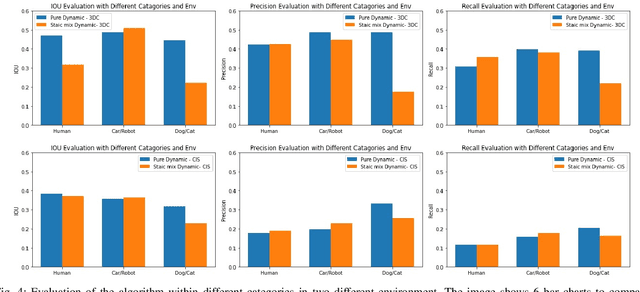
The advancement of computer vision and machine learning has made datasets a crucial element for further research and applications. However, the creation and development of robots with advanced recognition capabilities are hindered by the lack of appropriate datasets. Existing image or video processing datasets are unable to accurately depict observations from a moving robot, and they do not contain the kinematics information necessary for robotic tasks. Synthetic data, on the other hand, are cost-effective to create and offer greater flexibility for adapting to various applications. Hence, they are widely utilized in both research and industry. In this paper, we propose the dataset HabitatDyn, which contains both synthetic RGB videos, semantic labels, and depth information, as well as kinetics information. HabitatDyn was created from the perspective of a mobile robot with a moving camera, and contains 30 scenes featuring six different types of moving objects with varying velocities. To demonstrate the usability of our dataset, two existing algorithms are used for evaluation and an approach to estimate the distance between the object and camera is implemented based on these segmentation methods and evaluated through the dataset. With the availability of this dataset, we aspire to foster further advancements in the field of mobile robotics, leading to more capable and intelligent robots that can navigate and interact with their environments more effectively. The code is publicly available at https://github.com/ignc-research/HabitatDyn.
Person Image Synthesis via Denoising Diffusion Model
Nov 22, 2022
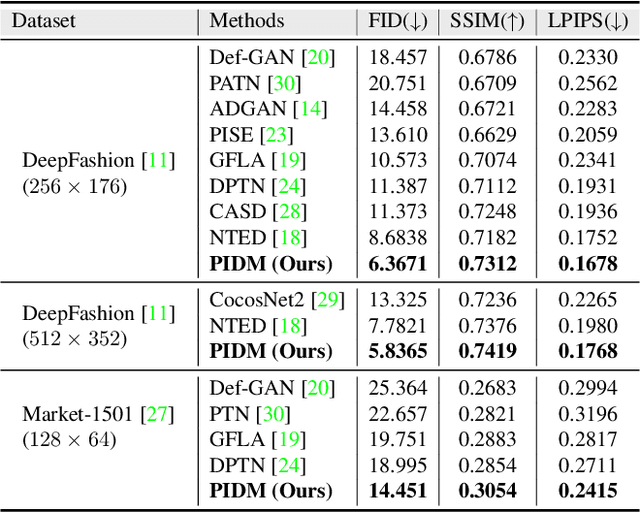
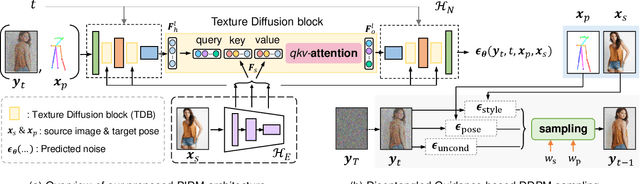
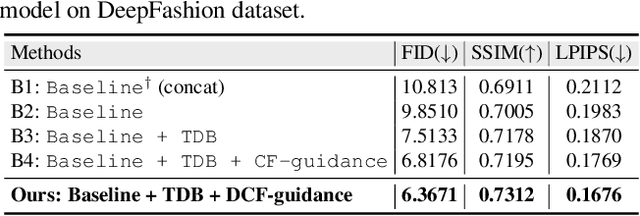
The pose-guided person image generation task requires synthesizing photorealistic images of humans in arbitrary poses. The existing approaches use generative adversarial networks that do not necessarily maintain realistic textures or need dense correspondences that struggle to handle complex deformations and severe occlusions. In this work, we show how denoising diffusion models can be applied for high-fidelity person image synthesis with strong sample diversity and enhanced mode coverage of the learnt data distribution. Our proposed Person Image Diffusion Model (PIDM) disintegrates the complex transfer problem into a series of simpler forward-backward denoising steps. This helps in learning plausible source-to-target transformation trajectories that result in faithful textures and undistorted appearance details. We introduce a 'texture diffusion module' based on cross-attention to accurately model the correspondences between appearance and pose information available in source and target images. Further, we propose 'disentangled classifier-free guidance' to ensure close resemblance between the conditional inputs and the synthesized output in terms of both pose and appearance information. Our extensive results on two large-scale benchmarks and a user study demonstrate the photorealism of our proposed approach under challenging scenarios. We also show how our generated images can help in downstream tasks. Our code and models will be publicly released.
DiffGAR: Model-Agnostic Restoration from Generative Artifacts Using Image-to-Image Diffusion Models
Oct 16, 2022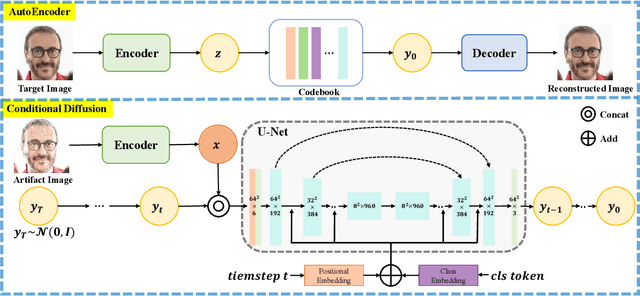

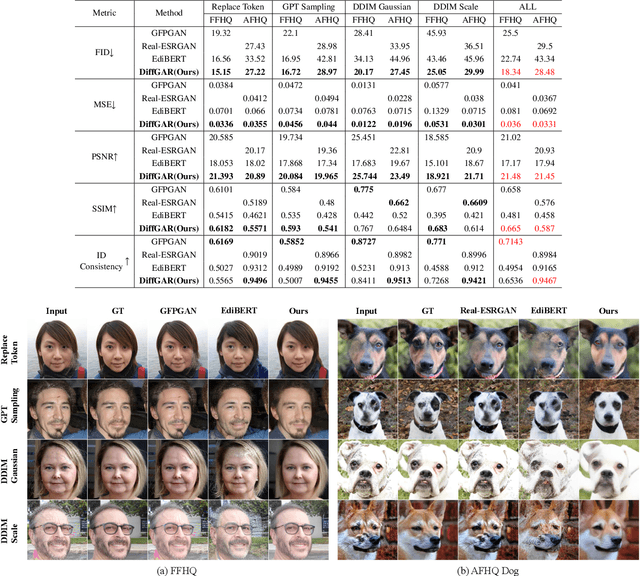
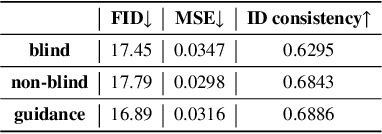
Recent generative models show impressive results in photo-realistic image generation. However, artifacts often inevitably appear in the generated results, leading to downgraded user experience and reduced performance in downstream tasks. This work aims to develop a plugin post-processing module for diverse generative models, which can faithfully restore images from diverse generative artifacts. This is challenging because: (1) Unlike traditional degradation patterns, generative artifacts are non-linear and the transformation function is highly complex. (2) There are no readily available artifact-image pairs. (3) Different from model-specific anti-artifact methods, a model-agnostic framework views the generator as a black-box machine and has no access to the architecture details. In this work, we first design a group of mechanisms to simulate generative artifacts of popular generators (i.e., GANs, autoregressive models, and diffusion models), given real images. Second, we implement the model-agnostic anti-artifact framework as an image-to-image diffusion model, due to its advantage in generation quality and capacity. Finally, we design a conditioning scheme for the diffusion model to enable both blind and non-blind image restoration. A guidance parameter is also introduced to allow for a trade-off between restoration accuracy and image quality. Extensive experiments show that our method significantly outperforms previous approaches on the proposed datasets and real-world artifact images.
Diffusion-HPC: Generating Synthetic Images with Realistic Humans
Mar 16, 2023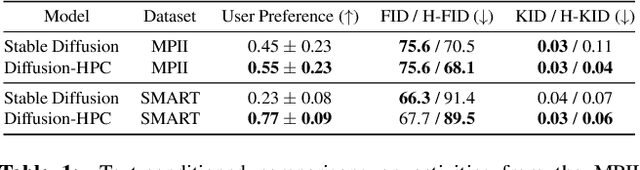
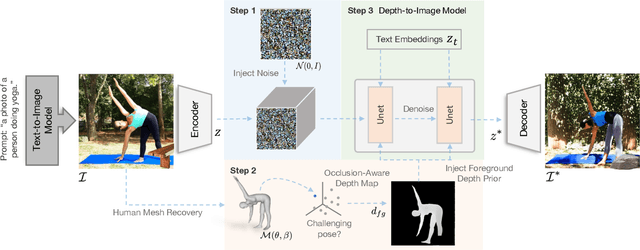
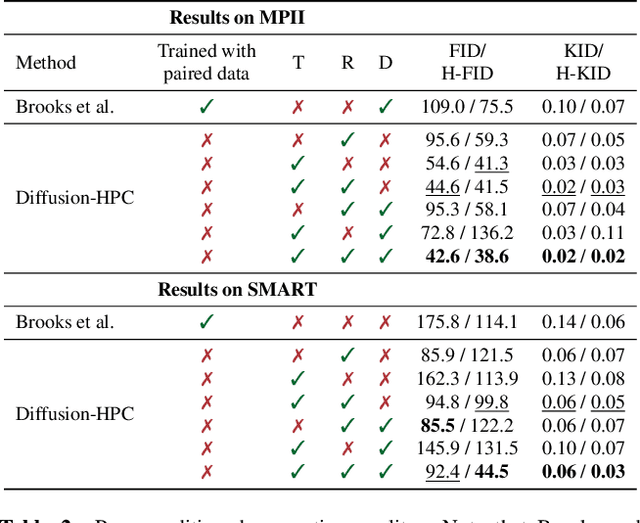

Recent text-to-image generative models have exhibited remarkable abilities in generating high-fidelity and photo-realistic images. However, despite the visually impressive results, these models often struggle to preserve plausible human structure in the generations. Due to this reason, while generative models have shown promising results in aiding downstream image recognition tasks by generating large volumes of synthetic data, they remain infeasible for improving downstream human pose perception and understanding. In this work, we propose Diffusion model with Human Pose Correction (Diffusion HPC), a text-conditioned method that generates photo-realistic images with plausible posed humans by injecting prior knowledge about human body structure. We show that Diffusion HPC effectively improves the realism of human generations. Furthermore, as the generations are accompanied by 3D meshes that serve as ground truths, Diffusion HPC's generated image-mesh pairs are well-suited for downstream human mesh recovery task, where a shortage of 3D training data has long been an issue.
Thread Counting in Plain Weave for Old Paintings Using Semi-Supervised Regression Deep Learning Models
Mar 31, 2023

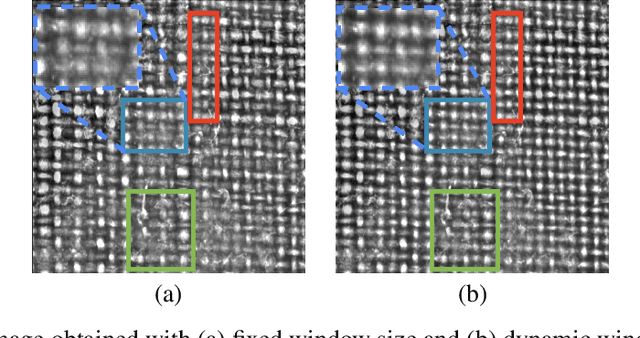
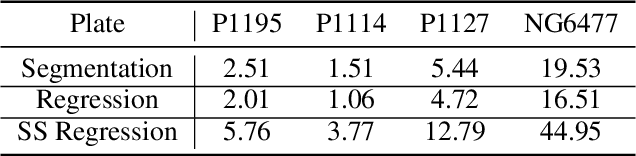
In this work, the authors develop regression approaches based on deep learning to perform thread density estimation for plain weave canvas analysis. Previous approaches were based on Fourier analysis, which is quite robust for some scenarios but fails in some others, in machine learning tools, that involve pre-labeling of the painting at hand, or the segmentation of thread crossing points, that provides good estimations in all scenarios with no need of pre-labeling. The segmentation approach is time-consuming as the estimation of the densities is performed after locating the crossing points. In this novel proposal, we avoid this step by computing the density of threads directly from the image with a regression deep learning model. We also incorporate some improvements in the initial preprocessing of the input image with an impact on the final error. Several models are proposed and analyzed to retain the best one. Furthermore, we further reduce the density estimation error by introducing a semi-supervised approach. The performance of our novel algorithm is analyzed with works by Ribera, Vel\'azquez, and Poussin where we compare our results to the ones of previous approaches. Finally, the method is put into practice to support the change of authorship or a masterpiece at the Museo del Prado.