 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural-Guided Domain Restriction to Accelerate Pseudospectra Computation for Structured Non-normal Banded Matrices
May 06, 2026Computing pseudospectra of non-normal matrices is essential for understanding the stability and transient behavior of dynamical systems. Such analysis is critical in applications including fluid dynamics, control systems, and differential operators, where non-normality can lead to significant transient amplification and sensitivity to perturbations that are not captured by eigenvalue analysis alone. At large scales, commonly used numerical approaches for pseudospectra computation can become computationally demanding, as they require repeated auxiliary computations to identify spectrally sensitive regions in the complex plane. We present a neural network-based approach that predicts sensitive regions directly from matrix features, thereby avoiding exhaustive pseudospectra evaluation across the entire complex plane. We calibrate the prediction threshold on validation data to ensure reliable coverage of sensitive regions. The trained neural network guides the selection of grid points requiring full computation, enabling focused computation only where necessary. The approach provides a practical preprocessing strategy for efficient pseudospectra computation. Numerical experiments on non-normal banded matrices demonstrate substantial speedup compared to full grid-based numerical evaluation while maintaining high accuracy in identifying sensitive regions.
Athena: Synergizing Data Prefetching and Off-Chip Prediction via Online Reinforcement Learning
Jan 24, 2026Prefetching and off-chip prediction are two techniques proposed to hide long memory access latencies in high-performance processors. In this work, we demonstrate that: (1) prefetching and off-chip prediction often provide complementary performance benefits, yet (2) naively combining them often fails to realize their full performance potential, and (3) existing prefetcher control policies leave significant room for performance improvement behind. Our goal is to design a holistic framework that can autonomously learn to coordinate an off-chip predictor with multiple prefetchers employed at various cache levels. To this end, we propose a new technique called Athena, which models the coordination between prefetchers and off-chip predictor (OCP) as a reinforcement learning (RL) problem. Athena acts as the RL agent that observes multiple system-level features (e.g., prefetcher/OCP accuracy, bandwidth usage) over an epoch of program execution, and uses them as state information to select a coordination action (i.e., enabling the prefetcher and/or OCP, and adjusting prefetcher aggressiveness). At the end of every epoch, Athena receives a numerical reward that measures the change in multiple system-level metrics (e.g., number of cycles taken to execute an epoch). Athena uses this reward to autonomously and continuously learn a policy to coordinate prefetchers with OCP. Our extensive evaluation using a diverse set of memory-intensive workloads shows that Athena consistently outperforms prior state-of-the-art coordination policies across a wide range of system configurations with various combinations of underlying prefetchers, OCPs, and main memory bandwidths, while incurring only modest storage overhead. Athena is freely available at https://github.com/CMU-SAFARI/Athena.
GeoSURGE: Geo-localization using Semantic Fusion with Hierarchy of Geographic Embeddings
Oct 01, 2025Worldwide visual geo-localization seeks to determine the geographic location of an image anywhere on Earth using only its visual content. Learned representations of geography for visual geo-localization remain an active research topic despite much progress. We formulate geo-localization as aligning the visual representation of the query image with a learned geographic representation. Our novel geographic representation explicitly models the world as a hierarchy of geographic embeddings. Additionally, we introduce an approach to efficiently fuse the appearance features of the query image with its semantic segmentation map, forming a robust visual representation. Our main experiments demonstrate improved all-time bests in 22 out of 25 metrics measured across five benchmark datasets compared to prior state-of-the-art (SOTA) methods and recent Large Vision-Language Models (LVLMs). Additional ablation studies support the claim that these gains are primarily driven by the combination of geographic and visual representations.
Diffusion-Guided Gaussian Splatting for Large-Scale Unconstrained 3D Reconstruction and Novel View Synthesis
Apr 02, 2025Recent advancements in 3D Gaussian Splatting (3DGS) and Neural Radiance Fields (NeRF) have achieved impressive results in real-time 3D reconstruction and novel view synthesis. However, these methods struggle in large-scale, unconstrained environments where sparse and uneven input coverage, transient occlusions, appearance variability, and inconsistent camera settings lead to degraded quality. We propose GS-Diff, a novel 3DGS framework guided by a multi-view diffusion model to address these limitations. By generating pseudo-observations conditioned on multi-view inputs, our method transforms under-constrained 3D reconstruction problems into well-posed ones, enabling robust optimization even with sparse data. GS-Diff further integrates several enhancements, including appearance embedding, monocular depth priors, dynamic object modeling, anisotropy regularization, and advanced rasterization techniques, to tackle geometric and photometric challenges in real-world settings. Experiments on four benchmarks demonstrate that GS-Diff consistently outperforms state-of-the-art baselines by significant margins.
Cross-View Visual Geo-Localization for Outdoor Augmented Reality
Mar 28, 2023



Precise estimation of global orientation and location is critical to ensure a compelling outdoor Augmented Reality (AR) experience. We address the problem of geo-pose estimation by cross-view matching of query ground images to a geo-referenced aerial satellite image database. Recently, neural network-based methods have shown state-of-the-art performance in cross-view matching. However, most of the prior works focus only on location estimation, ignoring orientation, which cannot meet the requirements in outdoor AR applications. We propose a new transformer neural network-based model and a modified triplet ranking loss for joint location and orientation estimation. Experiments on several benchmark cross-view geo-localization datasets show that our model achieves state-of-the-art performance. Furthermore, we present an approach to extend the single image query-based geo-localization approach by utilizing temporal information from a navigation pipeline for robust continuous geo-localization. Experimentation on several large-scale real-world video sequences demonstrates that our approach enables high-precision and stable AR insertion.
Hardware Acceleration of Neural Graphics
Mar 16, 2023



Rendering and inverse-rendering algorithms that drive conventional computer graphics have recently been superseded by neural representations (NR). NRs have recently been used to learn the geometric and the material properties of the scenes and use the information to synthesize photorealistic imagery, thereby promising a replacement for traditional rendering algorithms with scalable quality and predictable performance. In this work we ask the question: Does neural graphics (NG) need hardware support? We studied representative NG applications showing that, if we want to render 4k res. at 60FPS there is a gap of 1.5X-55X in the desired performance on current GPUs. For AR/VR applications, there is an even larger gap of 2-4 OOM between the desired performance and the required system power. We identify that the input encoding and the MLP kernels are the performance bottlenecks, consuming 72%,60% and 59% of application time for multi res. hashgrid, multi res. densegrid and low res. densegrid encodings, respectively. We propose a NG processing cluster, a scalable and flexible hardware architecture that directly accelerates the input encoding and MLP kernels through dedicated engines and supports a wide range of NG applications. We also accelerate the rest of the kernels by fusing them together in Vulkan, which leads to 9.94X kernel-level performance improvement compared to un-fused implementation of the pre-processing and the post-processing kernels. Our results show that, NGPC gives up to 58X end-to-end application-level performance improvement, for multi res. hashgrid encoding on average across the four NG applications, the performance benefits are 12X,20X,33X and 39X for the scaling factor of 8,16,32 and 64, respectively. Our results show that with multi res. hashgrid encoding, NGPC enables the rendering of 4k res. at 30FPS for NeRF and 8k res. at 120FPS for all our other NG applications.
GraphMapper: Efficient Visual Navigation by Scene Graph Generation
May 17, 2022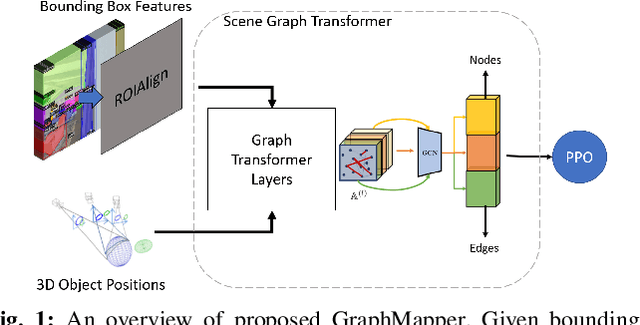
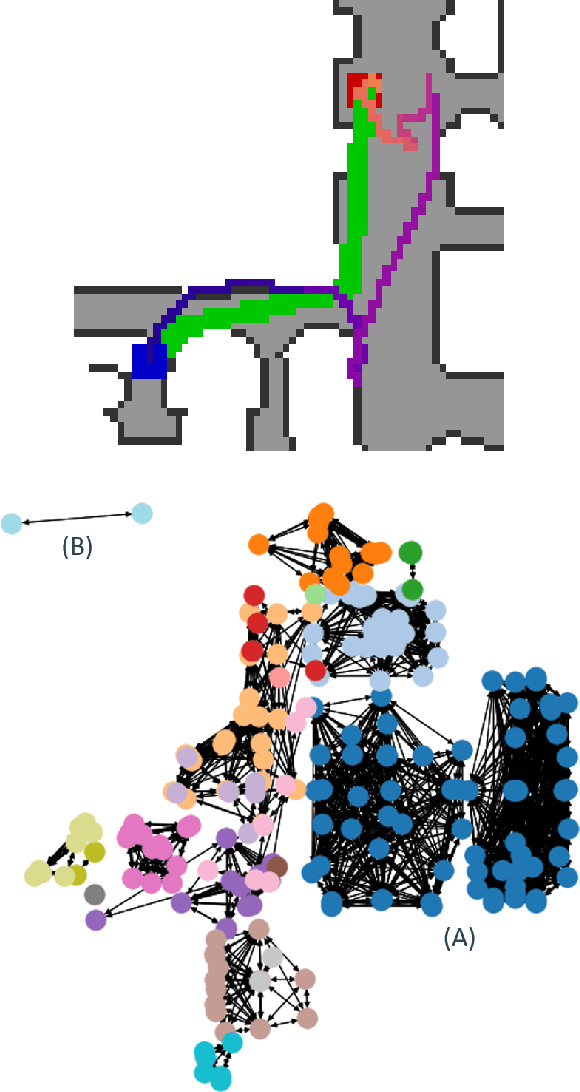
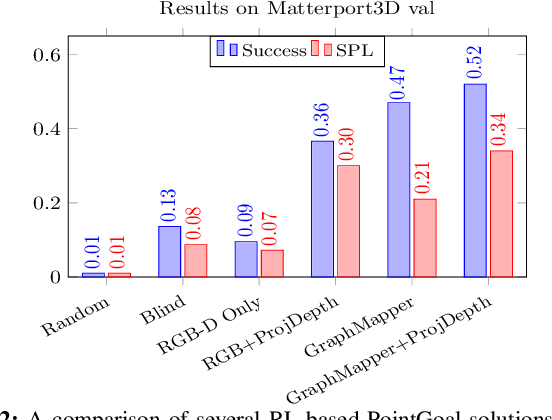
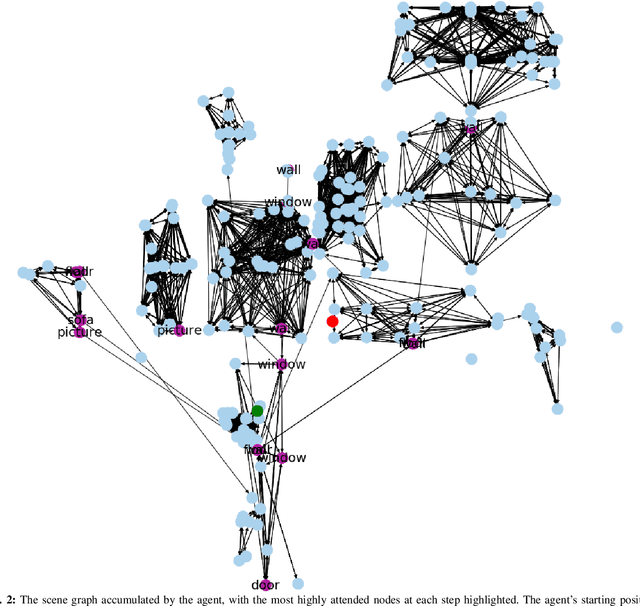
Understanding the geometric relationships between objects in a scene is a core capability in enabling both humans and autonomous agents to navigate in new environments. A sparse, unified representation of the scene topology will allow agents to act efficiently to move through their environment, communicate the environment state with others, and utilize the representation for diverse downstream tasks. To this end, we propose a method to train an autonomous agent to learn to accumulate a 3D scene graph representation of its environment by simultaneously learning to navigate through said environment. We demonstrate that our approach, GraphMapper, enables the learning of effective navigation policies through fewer interactions with the environment than vision-based systems alone. Further, we show that GraphMapper can act as a modular scene encoder to operate alongside existing Learning-based solutions to not only increase navigational efficiency but also generate intermediate scene representations that are useful for other future tasks.
SASRA: Semantically-aware Spatio-temporal Reasoning Agent for Vision-and-Language Navigation in Continuous Environments
Aug 26, 2021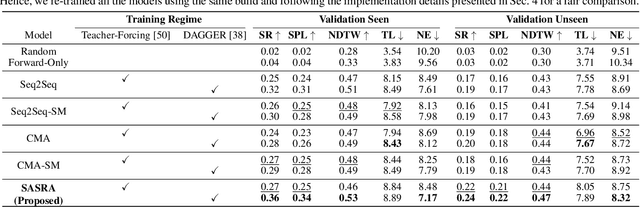
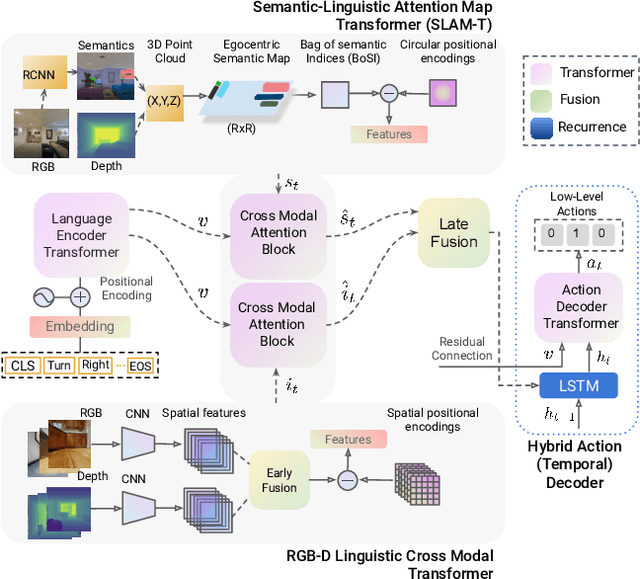
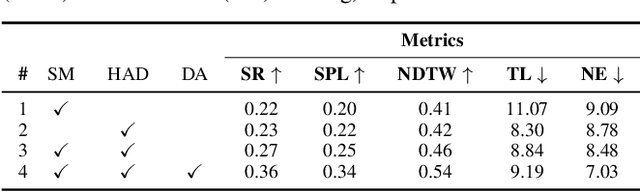
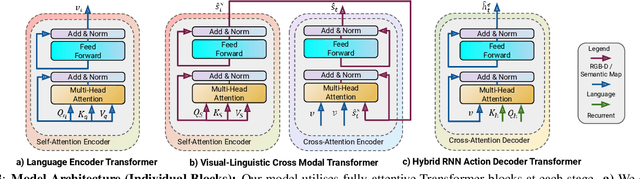
This paper presents a novel approach for the Vision-and-Language Navigation (VLN) task in continuous 3D environments, which requires an autonomous agent to follow natural language instructions in unseen environments. Existing end-to-end learning-based VLN methods struggle at this task as they focus mostly on utilizing raw visual observations and lack the semantic spatio-temporal reasoning capabilities which is crucial in generalizing to new environments. In this regard, we present a hybrid transformer-recurrence model which focuses on combining classical semantic mapping techniques with a learning-based method. Our method creates a temporal semantic memory by building a top-down local ego-centric semantic map and performs cross-modal grounding to align map and language modalities to enable effective learning of VLN policy. Empirical results in a photo-realistic long-horizon simulation environment show that the proposed approach outperforms a variety of state-of-the-art methods and baselines with over 22% relative improvement in SPL in prior unseen environments.
MaAST: Map Attention with Semantic Transformersfor Efficient Visual Navigation
Mar 21, 2021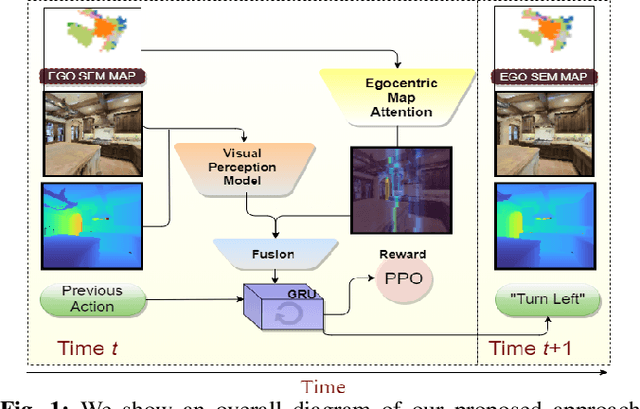

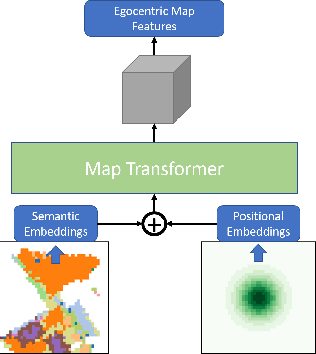
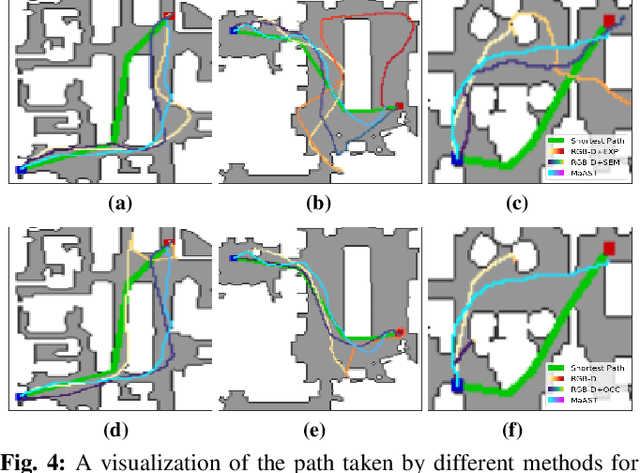
Visual navigation for autonomous agents is a core task in the fields of computer vision and robotics. Learning-based methods, such as deep reinforcement learning, have the potential to outperform the classical solutions developed for this task; however, they come at a significantly increased computational load. Through this work, we design a novel approach that focuses on performing better or comparable to the existing learning-based solutions but under a clear time/computational budget. To this end, we propose a method to encode vital scene semantics such as traversable paths, unexplored areas, and observed scene objects -- alongside raw visual streams such as RGB, depth, and semantic segmentation masks -- into a semantically informed, top-down egocentric map representation. Further, to enable the effective use of this information, we introduce a novel 2-D map attention mechanism, based on the successful multi-layer Transformer networks. We conduct experiments on 3-D reconstructed indoor PointGoal visual navigation and demonstrate the effectiveness of our approach. We show that by using our novel attention schema and auxiliary rewards to better utilize scene semantics, we outperform multiple baselines trained with only raw inputs or implicit semantic information while operating with an 80% decrease in the agent's experience.
Efficient Kernel based Matched Filter Approach for Segmentation of Retinal Blood Vessels
Dec 07, 2020
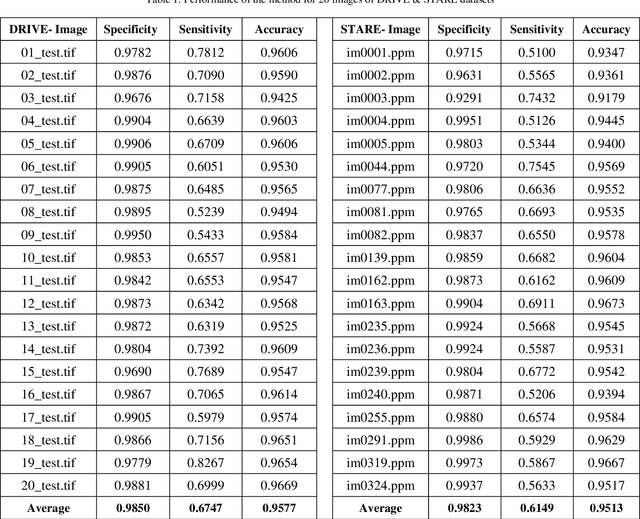
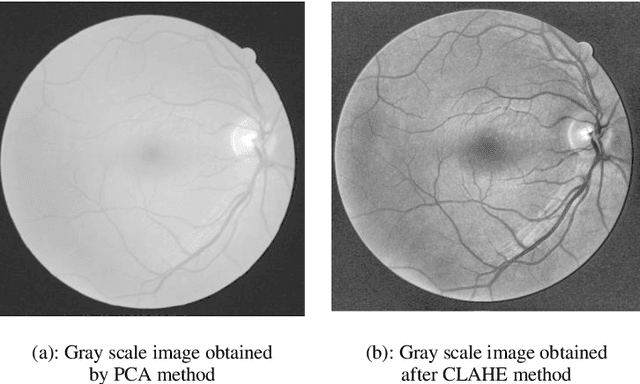
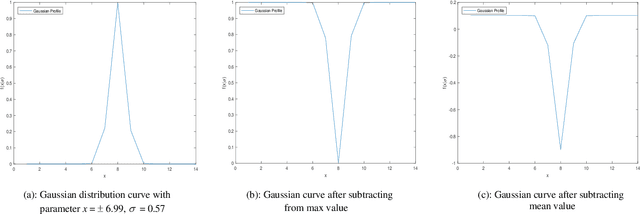
Retinal blood vessels structure contains information about diseases like obesity, diabetes, hypertension and glaucoma. This information is very useful in identification and treatment of these fatal diseases. To obtain this information, there is need to segment these retinal vessels. Many kernel based methods have been given for segmentation of retinal vessels but their kernels are not appropriate to vessel profile cause poor performance. To overcome this, a new and efficient kernel based matched filter approach has been proposed. The new matched filter is used to generate the matched filter response (MFR) image. We have applied Otsu thresholding method on obtained MFR image to extract the vessels. We have conducted extensive experiments to choose best value of parameters for the proposed matched filter kernel. The proposed approach has examined and validated on two online available DRIVE and STARE datasets. The proposed approach has specificity 98.50%, 98.23% and accuracy 95.77 %, 95.13% for DRIVE and STARE dataset respectively. Obtained results confirm that the proposed method has better performance than others. The reason behind increased performance is due to appropriate proposed kernel which matches retinal blood vessel profile more accurately.