 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
One-shot Unsupervised Domain Adaptation with Personalized Diffusion Models
Mar 31, 2023
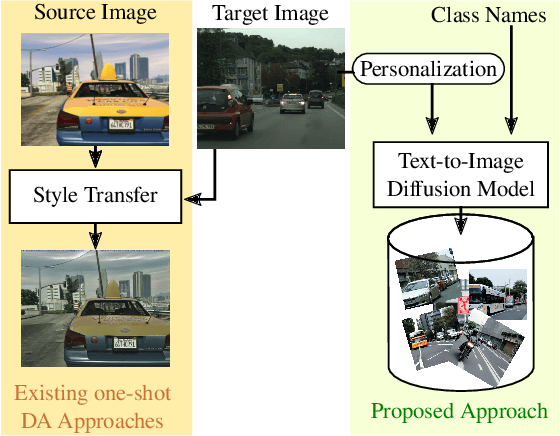
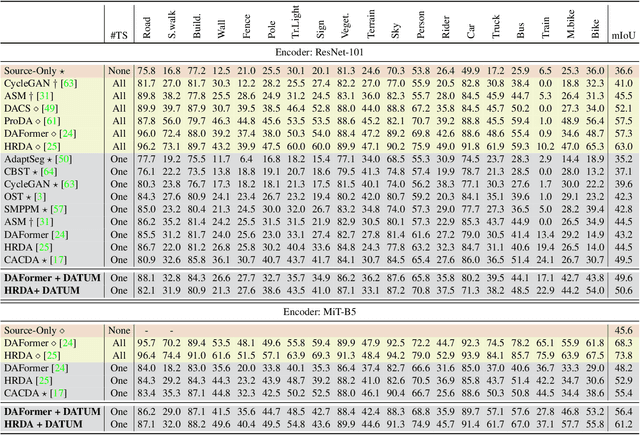
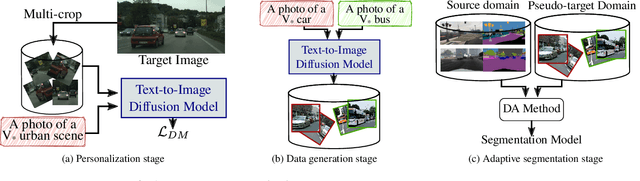
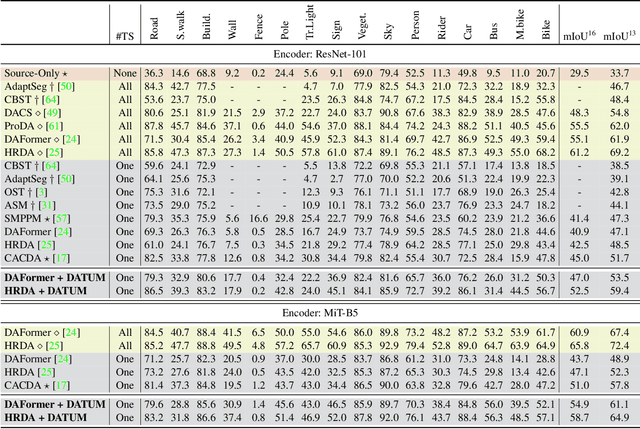
Adapting a segmentation model from a labeled source domain to a target domain, where a single unlabeled datum is available, is one the most challenging problems in domain adaptation and is otherwise known as one-shot unsupervised domain adaptation (OSUDA). Most of the prior works have addressed the problem by relying on style transfer techniques, where the source images are stylized to have the appearance of the target domain. Departing from the common notion of transferring only the target ``texture'' information, we leverage text-to-image diffusion models (e.g., Stable Diffusion) to generate a synthetic target dataset with photo-realistic images that not only faithfully depict the style of the target domain, but are also characterized by novel scenes in diverse contexts. The text interface in our method Data AugmenTation with diffUsion Models (DATUM) endows us with the possibility of guiding the generation of images towards desired semantic concepts while respecting the original spatial context of a single training image, which is not possible in existing OSUDA methods. Extensive experiments on standard benchmarks show that our DATUM surpasses the state-of-the-art OSUDA methods by up to +7.1%. The implementation is available at https://github.com/yasserben/DATUM
Weakly-Supervised Text-driven Contrastive Learning for Facial Behavior Understanding
Mar 31, 2023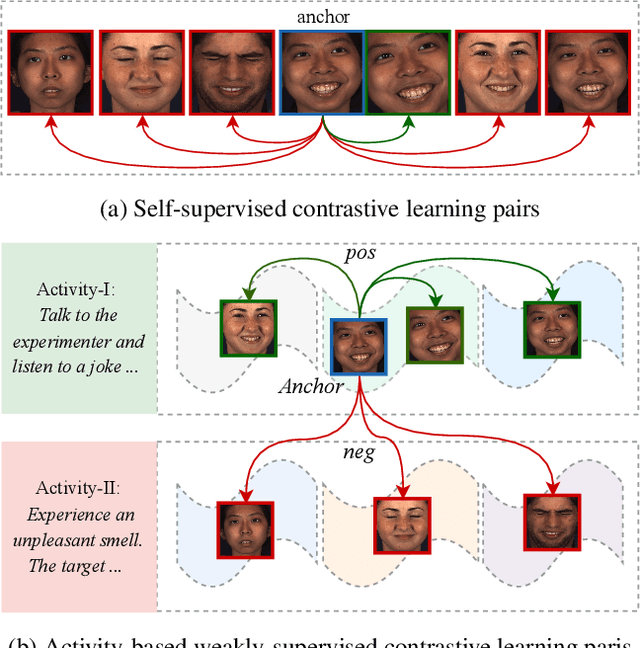
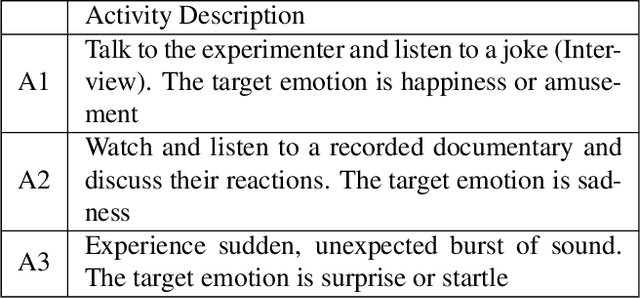
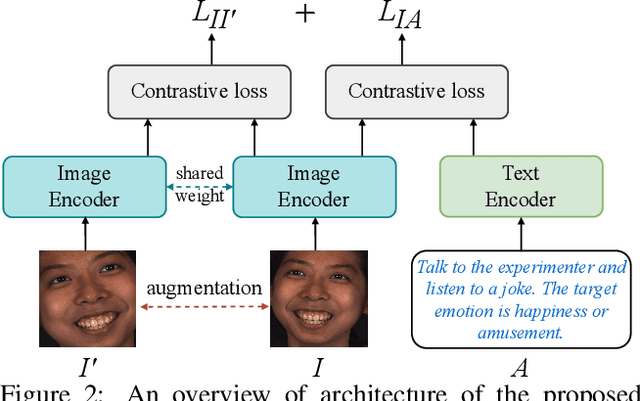
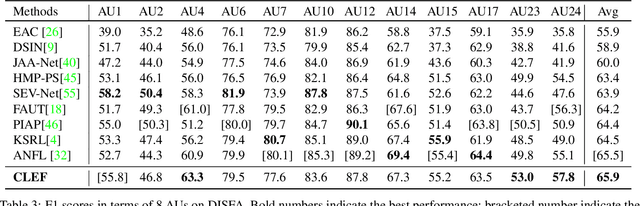
Contrastive learning has shown promising potential for learning robust representations by utilizing unlabeled data. However, constructing effective positive-negative pairs for contrastive learning on facial behavior datasets remains challenging. This is because such pairs inevitably encode the subject-ID information, and the randomly constructed pairs may push similar facial images away due to the limited number of subjects in facial behavior datasets. To address this issue, we propose to utilize activity descriptions, coarse-grained information provided in some datasets, which can provide high-level semantic information about the image sequences but is often neglected in previous studies. More specifically, we introduce a two-stage Contrastive Learning with Text-Embeded framework for Facial behavior understanding (CLEF). The first stage is a weakly-supervised contrastive learning method that learns representations from positive-negative pairs constructed using coarse-grained activity information. The second stage aims to train the recognition of facial expressions or facial action units by maximizing the similarity between image and the corresponding text label names. The proposed CLEF achieves state-of-the-art performance on three in-the-lab datasets for AU recognition and three in-the-wild datasets for facial expression recognition.
Improved Difference Images for Change Detection Classifiers in SAR Imagery Using Deep Learning
Mar 31, 2023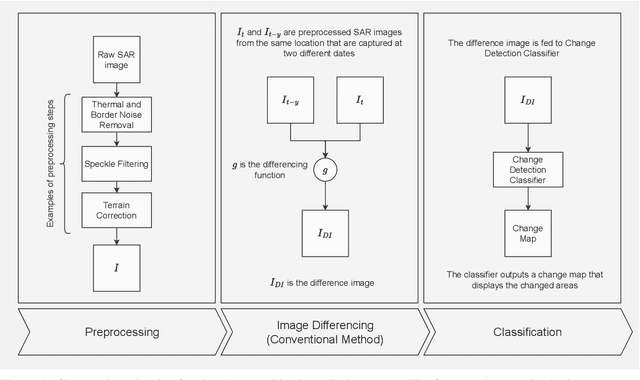
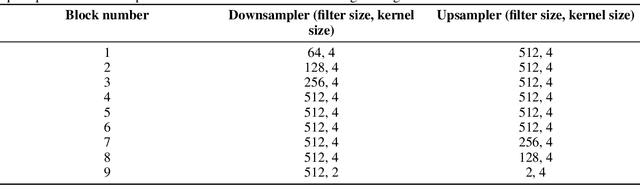
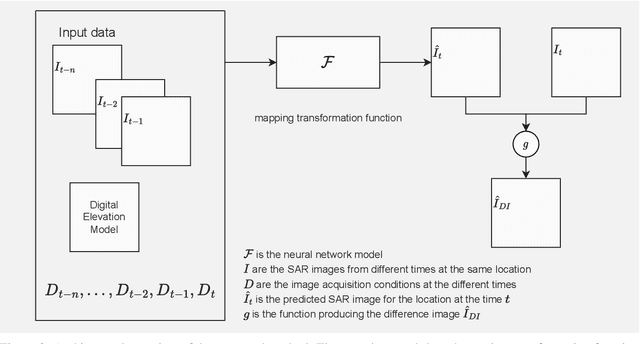

Satellite-based Synthetic Aperture Radar (SAR) images can be used as a source of remote sensed imagery regardless of cloud cover and day-night cycle. However, the speckle noise and varying image acquisition conditions pose a challenge for change detection classifiers. This paper proposes a new method of improving SAR image processing to produce higher quality difference images for the classification algorithms. The method is built on a neural network-based mapping transformation function that produces artificial SAR images from a location in the requested acquisition conditions. The inputs for the model are: previous SAR images from the location, imaging angle information from the SAR images, digital elevation model, and weather conditions. The method was tested with data from a location in North-East Finland by using Sentinel-1 SAR images from European Space Agency, weather data from Finnish Meteorological Institute, and a digital elevation model from National Land Survey of Finland. In order to verify the method, changes to the SAR images were simulated, and the performance of the proposed method was measured using experimentation where it gave substantial improvements to performance when compared to a more conventional method of creating difference images.
SuperDisco: Super-Class Discovery Improves Visual Recognition for the Long-Tail
Mar 31, 2023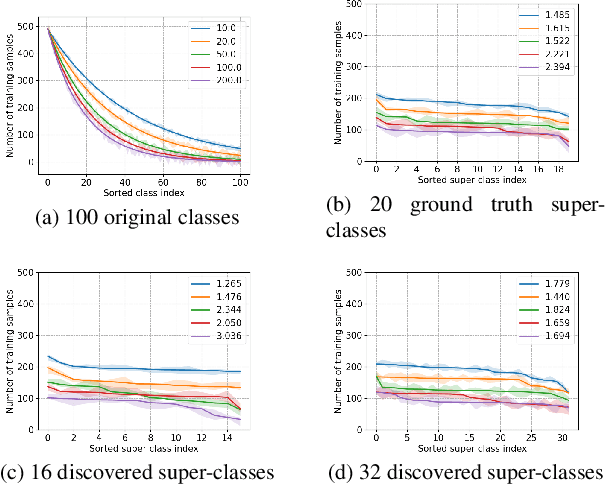

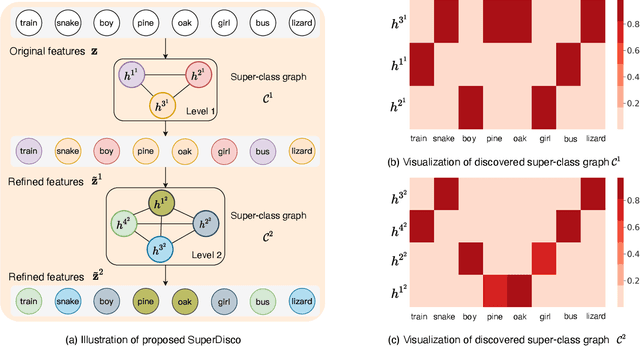
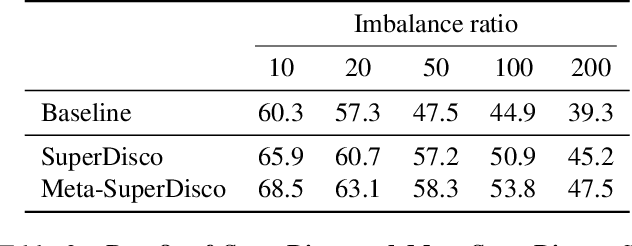
Modern image classifiers perform well on populated classes, while degrading considerably on tail classes with only a few instances. Humans, by contrast, effortlessly handle the long-tailed recognition challenge, since they can learn the tail representation based on different levels of semantic abstraction, making the learned tail features more discriminative. This phenomenon motivated us to propose SuperDisco, an algorithm that discovers super-class representations for long-tailed recognition using a graph model. We learn to construct the super-class graph to guide the representation learning to deal with long-tailed distributions. Through message passing on the super-class graph, image representations are rectified and refined by attending to the most relevant entities based on the semantic similarity among their super-classes. Moreover, we propose to meta-learn the super-class graph under the supervision of a prototype graph constructed from a small amount of imbalanced data. By doing so, we obtain a more robust super-class graph that further improves the long-tailed recognition performance. The consistent state-of-the-art experiments on the long-tailed CIFAR-100, ImageNet, Places and iNaturalist demonstrate the benefit of the discovered super-class graph for dealing with long-tailed distributions.
ODIN: On-demand Data Formulation to Mitigate Dataset Lock-in
Mar 16, 2023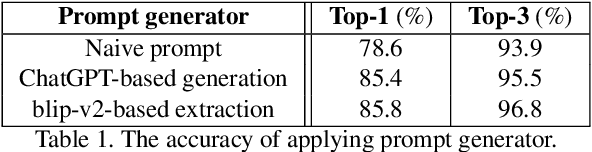

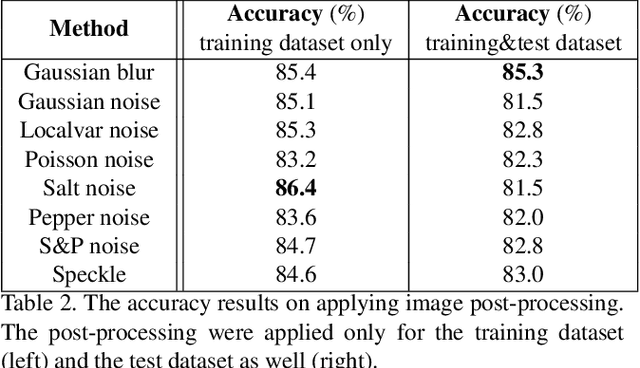

ODIN is an innovative approach that addresses the problem of dataset constraints by integrating generative AI models. Traditional zero-shot learning methods are constrained by the training dataset. To fundamentally overcome this limitation, ODIN attempts to mitigate the dataset constraints by generating on-demand datasets based on user requirements. ODIN consists of three main modules: a prompt generator, a text-to-image generator, and an image post-processor. To generate high-quality prompts and images, we adopted a large language model (e.g., ChatGPT), and a text-to-image diffusion model (e.g., Stable Diffusion), respectively. We evaluated ODIN on various datasets in terms of model accuracy and data diversity to demonstrate its potential, and conducted post-experiments for further investigation. Overall, ODIN is a feasible approach that enables Al to learn unseen knowledge beyond the training dataset.
Audio-Driven Talking Face Generation with Diverse yet Realistic Facial Animations
Apr 18, 2023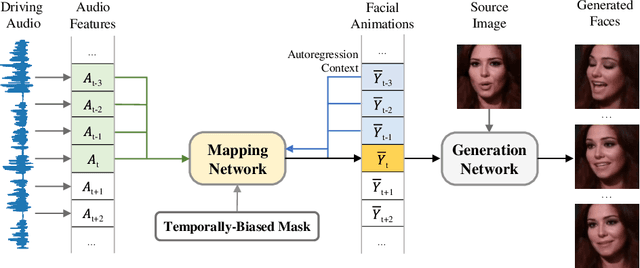
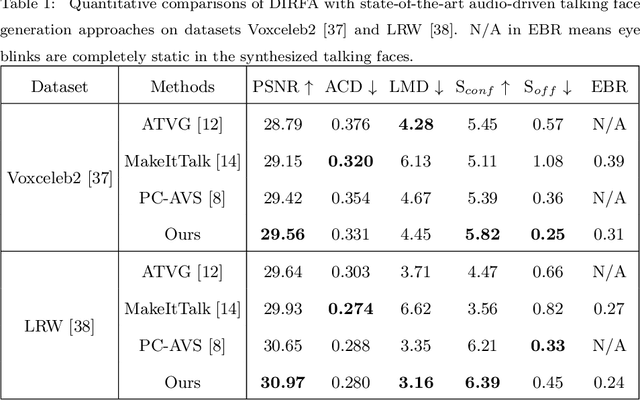

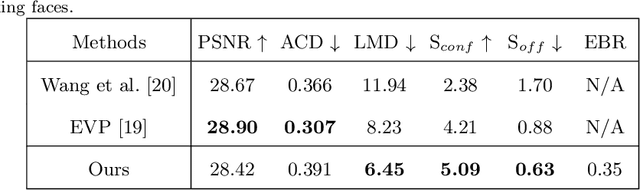
Audio-driven talking face generation, which aims to synthesize talking faces with realistic facial animations (including accurate lip movements, vivid facial expression details and natural head poses) corresponding to the audio, has achieved rapid progress in recent years. However, most existing work focuses on generating lip movements only without handling the closely correlated facial expressions, which degrades the realism of the generated faces greatly. This paper presents DIRFA, a novel method that can generate talking faces with diverse yet realistic facial animations from the same driving audio. To accommodate fair variation of plausible facial animations for the same audio, we design a transformer-based probabilistic mapping network that can model the variational facial animation distribution conditioned upon the input audio and autoregressively convert the audio signals into a facial animation sequence. In addition, we introduce a temporally-biased mask into the mapping network, which allows to model the temporal dependency of facial animations and produce temporally smooth facial animation sequence. With the generated facial animation sequence and a source image, photo-realistic talking faces can be synthesized with a generic generation network. Extensive experiments show that DIRFA can generate talking faces with realistic facial animations effectively.
Model Predictive Spherical Image-Based Visual Servoing On $SO(3)$ for Aggressive Aerial Tracking
Dec 19, 2022
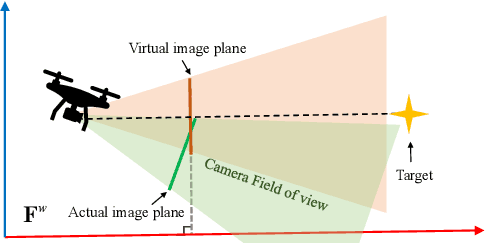
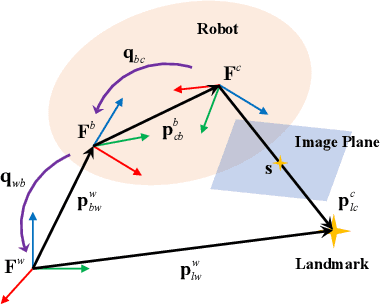
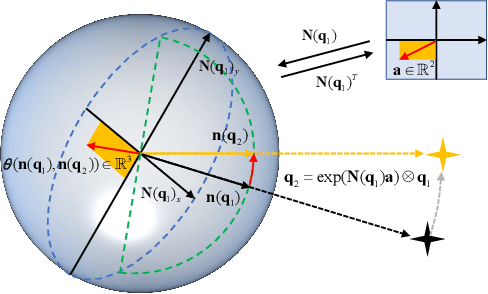
This paper presents an image-based visual servo control (IBVS) method for a first-person-view (FPV) quadrotor to conduct aggressive aerial tracking. There are three major challenges to maneuvering an underactuated vehicle using IBVS: (i) finding a visual feature representation that is robust to large rotations and is suited to be an optimization variable; (ii) keeping the target visible without sacrificing the robot's agility; and (iii) compensating for the rotational effects in the detected features. We propose a complete design framework to address these problems. First, we employ a rotation on $SO(3)$ to represent a spherical image feature on $S^{2}$ to gain singularity-free and second-order differentiable properties. To ensure target visibility, we formulate the IBVS as a nonlinear model predictive control (NMPC) problem with three constraints taken into account: the robot's physical limits, target visibility, and time-to-collision (TTC). Furthermore, we propose a novel attitude-compensation scheme to enable formulating the visibility constraint in the actual image plane instead of a virtual fix-orientation image plane. It guarantees that the visibility constraint is valid under large rotations. Extensive experimental results show that our method can track a fast-moving target stably and aggressively without the aid of a localization system.
UNO-QA: An Unsupervised Anomaly-Aware Framework with Test-Time Clustering for OCTA Image Quality Assessment
Dec 20, 2022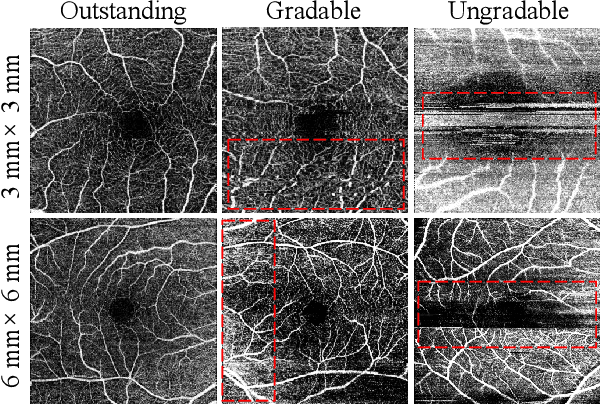
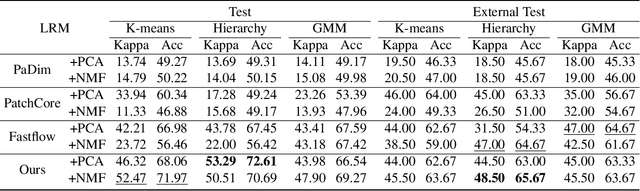
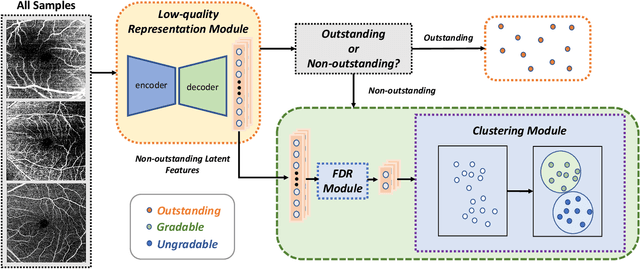
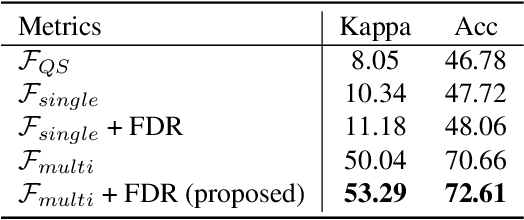
Medical image quality assessment (MIQA) is a vital prerequisite in various medical image analysis applications. Most existing MIQA algorithms are fully supervised that request a large amount of annotated data. However, annotating medical images is time-consuming and labor-intensive. In this paper, we propose an unsupervised anomaly-aware framework with test-time clustering for optical coherence tomography angiography (OCTA) image quality assessment in a setting wherein only a set of high-quality samples are accessible in the training phase. Specifically, a feature-embedding-based low-quality representation module is proposed to quantify the quality of OCTA images and then to discriminate between outstanding quality and non-outstanding quality. Within the non-outstanding quality class, to further distinguish gradable images from ungradable ones, we perform dimension reduction and clustering of multi-scale image features extracted by the trained OCTA quality representation network. Extensive experiments are conducted on one publicly accessible dataset sOCTA-3*3-10k, with superiority of our proposed framework being successfully established.
High Dynamic Range Imaging with Context-aware Transformer
Apr 21, 2023
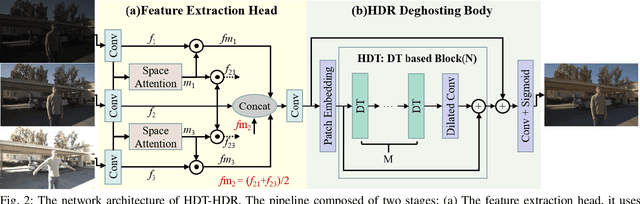
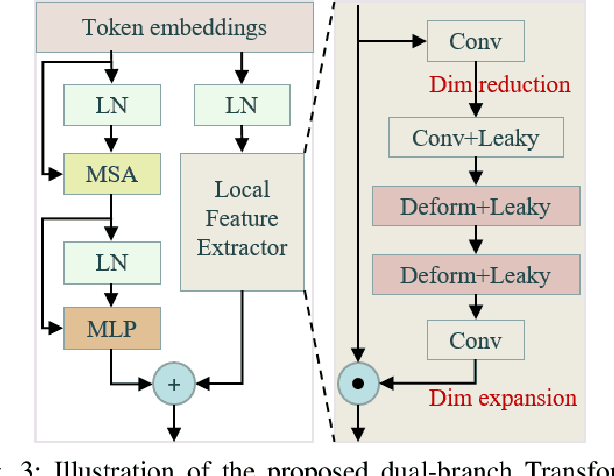

Avoiding the introduction of ghosts when synthesising LDR images as high dynamic range (HDR) images is a challenging task. Convolutional neural networks (CNNs) are effective for HDR ghost removal in general, but are challenging to deal with the LDR images if there are large movements or oversaturation/undersaturation. Existing dual-branch methods combining CNN and Transformer omit part of the information from non-reference images, while the features extracted by the CNN-based branch are bound to the kernel size with small receptive field, which are detrimental to the deblurring and the recovery of oversaturated/undersaturated regions. In this paper, we propose a novel hierarchical dual Transformer method for ghost-free HDR (HDT-HDR) images generation, which extracts global features and local features simultaneously. First, we use a CNN-based head with spatial attention mechanisms to extract features from all the LDR images. Second, the LDR features are delivered to the Hierarchical Dual Transformer (HDT). In each Dual Transformer (DT), the global features are extracted by the window-based Transformer, while the local details are extracted using the channel attention mechanism with deformable CNNs. Finally, the ghost free HDR image is obtained by dimensional mapping on the HDT output. Abundant experiments demonstrate that our HDT-HDR achieves the state-of-the-art performance among existing HDR ghost removal methods.
Fracture Detection in Pediatric Wrist Trauma X-ray Images Using YOLOv8 Algorithm
Apr 21, 2023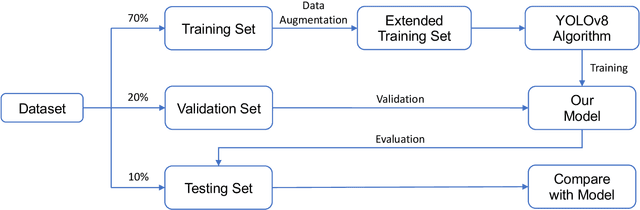
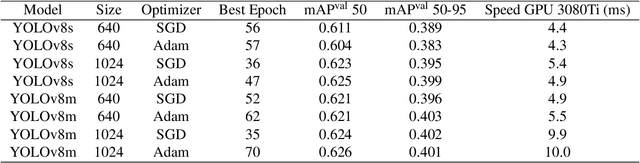
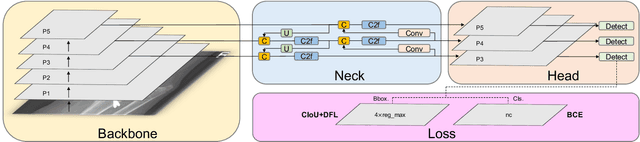
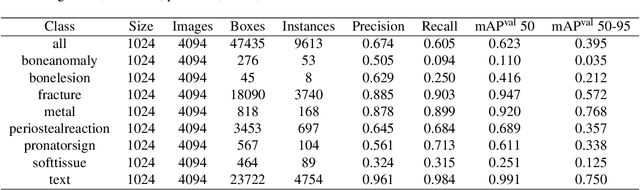
Hospital emergency departments frequently receive lots of bone fracture cases, with pediatric wrist trauma fracture accounting for the majority of them. Before pediatric surgeons perform surgery, they need to ask patients how the fracture occurred and analyze the fracture situation by interpreting X-ray images. The interpretation of X-ray images often requires a combination of techniques from radiologists and surgeons, which requires time-consuming specialized training. With the rise of deep learning in the field of computer vision, network models applying for fracture detection has become an important research topic. In this paper, YOLOv8 algorithm is used to train models on the GRAZPEDWRI-DX dataset, which includes X-ray images from 6,091 pediatric patients with wrist trauma. The experimental results show that YOLOv8 algorithm models have different advantages for different model sizes, with YOLOv8l model achieving the highest mean average precision (mAP 50) of 63.6%, and YOLOv8n model achieving the inference time of 67.4ms per X-ray image on one single CPU with low computing power. This work demonstrates that YOLOv8 algorithm has good generalizability and creates the "Fracture Detection Using YOLOv8 App" to assist surgeons in interpreting fractures in X-ray images, reducing the probability of error, and providing more useful information for fracture surgery. Our implementation code is released at https://github.com/RuiyangJu/Bone_Fracture_Detection_YOLOv8.