 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Bootstrapping Objectness from Videos by Relaxed Common Fate and Visual Grouping
Apr 17, 2023

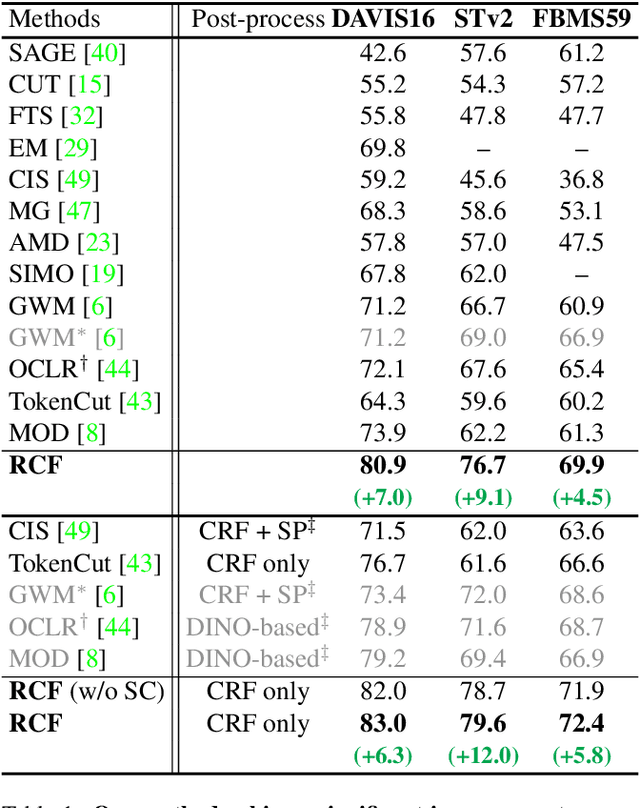

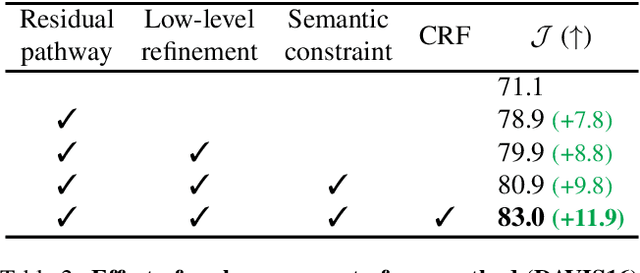
We study learning object segmentation from unlabeled videos. Humans can easily segment moving objects without knowing what they are. The Gestalt law of common fate, i.e., what move at the same speed belong together, has inspired unsupervised object discovery based on motion segmentation. However, common fate is not a reliable indicator of objectness: Parts of an articulated / deformable object may not move at the same speed, whereas shadows / reflections of an object always move with it but are not part of it. Our insight is to bootstrap objectness by first learning image features from relaxed common fate and then refining them based on visual appearance grouping within the image itself and across images statistically. Specifically, we learn an image segmenter first in the loop of approximating optical flow with constant segment flow plus small within-segment residual flow, and then by refining it for more coherent appearance and statistical figure-ground relevance. On unsupervised video object segmentation, using only ResNet and convolutional heads, our model surpasses the state-of-the-art by absolute gains of 7/9/5% on DAVIS16 / STv2 / FBMS59 respectively, demonstrating the effectiveness of our ideas. Our code is publicly available.
LinkGAN: Linking GAN Latents to Pixels for Controllable Image Synthesis
Jan 11, 2023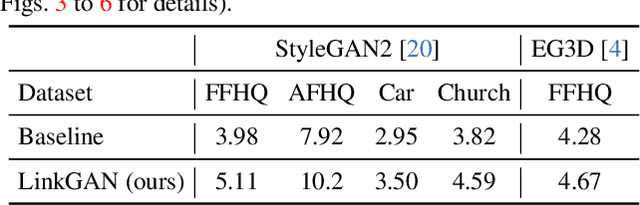
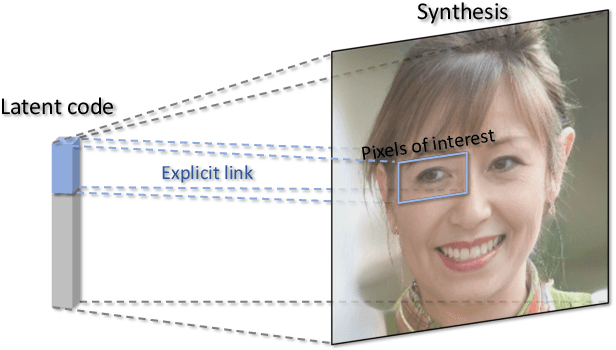
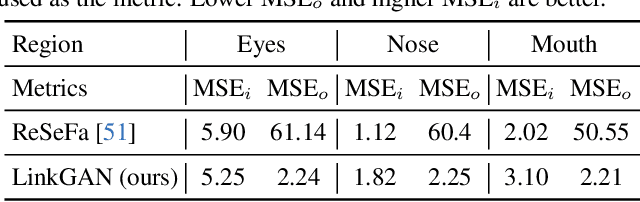

This work presents an easy-to-use regularizer for GAN training, which helps explicitly link some axes of the latent space to an image region or a semantic category (e.g., sky) in the synthesis. Establishing such a connection facilitates a more convenient local control of GAN generation, where users can alter image content only within a spatial area simply by partially resampling the latent codes. Experimental results confirm four appealing properties of our regularizer, which we call LinkGAN. (1) Any image region can be linked to the latent space, even if the region is pre-selected before training and fixed for all instances. (2) Two or multiple regions can be independently linked to different latent axes, surprisingly allowing tokenized control of synthesized images. (3) Our regularizer can improve the spatial controllability of both 2D and 3D GAN models, barely sacrificing the synthesis performance. (4) The models trained with our regularizer are compatible with GAN inversion techniques and maintain editability on real images
Deep Visual-Genetic Biometrics for Taxonomic Classification of Rare Species
May 20, 2023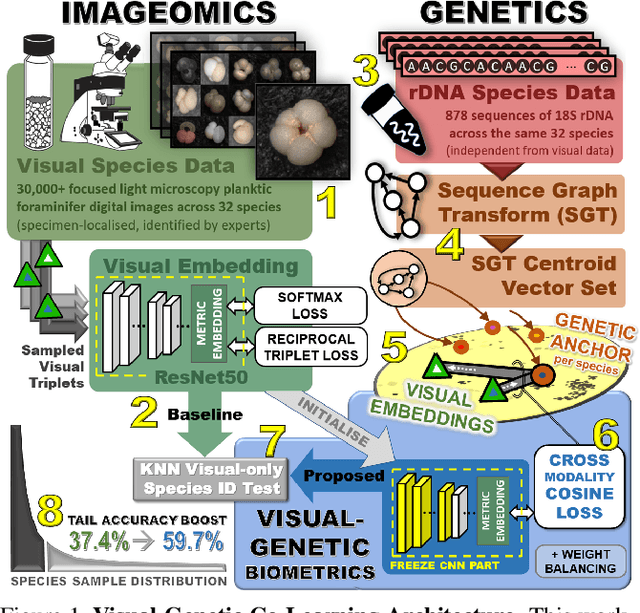
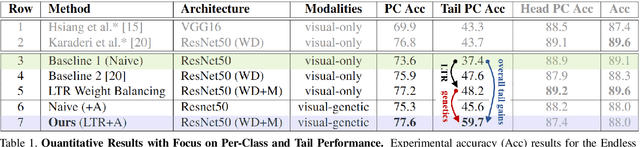
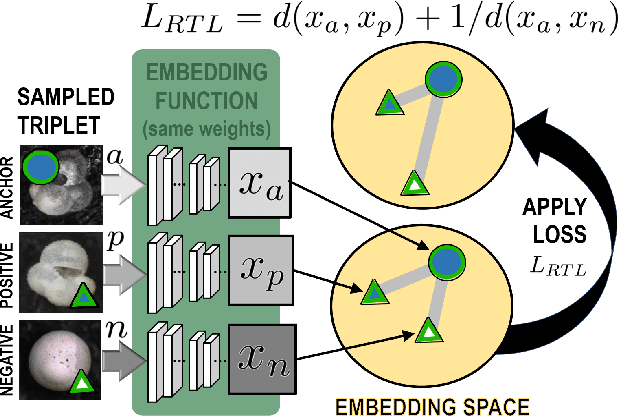
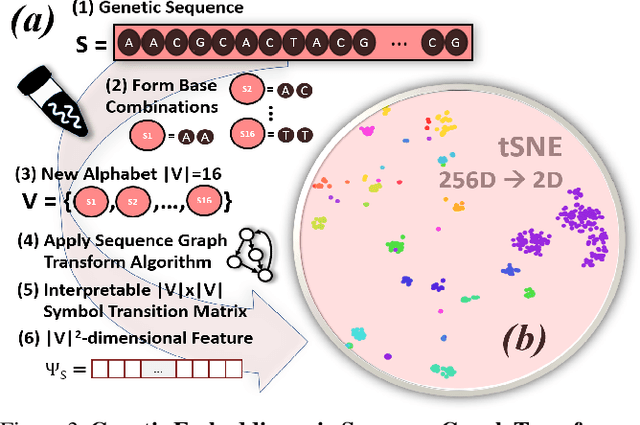
Visual as well as genetic biometrics are routinely employed to identify species and individuals in biological applications. However, no attempts have been made in this domain to computationally enhance visual classification of rare classes with little image data via genetics. In this paper, we thus propose aligned visual-genetic inference spaces with the aim to implicitly encode cross-domain associations for improved performance. We demonstrate for the first time that such alignment can be achieved via deep embedding models and that the approach is directly applicable to boosting long-tailed recognition (LTR) particularly for rare species. We experimentally demonstrate the efficacy of the concept via application to microscopic imagery of 30k+ planktic foraminifer shells across 32 species when used together with independent genetic data samples. Most importantly for practitioners, we show that visual-genetic alignment can significantly benefit visual-only recognition of the rarest species. Technically, we pre-train a visual ResNet50 deep learning model using triplet loss formulations to create an initial embedding space. We re-structure this space based on genetic anchors embedded via a Sequence Graph Transform (SGT) and linked to visual data by cross-domain cosine alignment. We show that an LTR approach improves the state-of-the-art across all benchmarks and that adding our visual-genetic alignment improves per-class and particularly rare tail class benchmarks significantly further. We conclude that visual-genetic alignment can be a highly effective tool for complementing visual biological data containing rare classes. The concept proposed may serve as an important future tool for integrating genetics and imageomics towards a more complete scientific representation of taxonomic spaces and life itself. Code, weights, and data splits are published for full reproducibility.
AVFace: Towards Detailed Audio-Visual 4D Face Reconstruction
May 11, 2023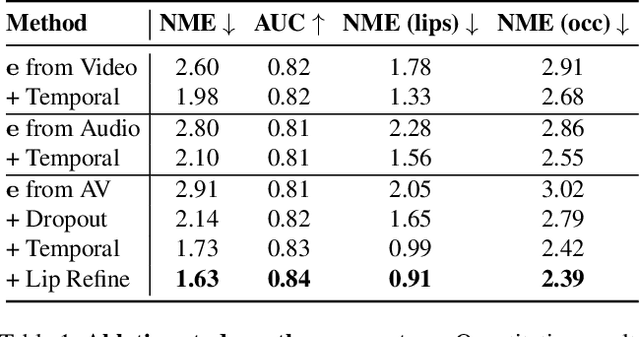
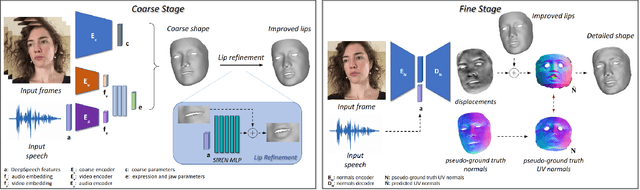
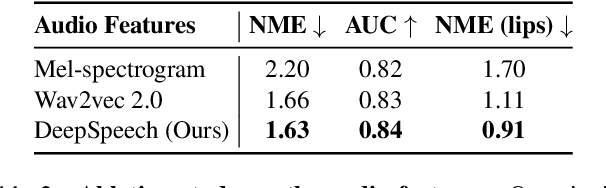

In this work, we present a multimodal solution to the problem of 4D face reconstruction from monocular videos. 3D face reconstruction from 2D images is an under-constrained problem due to the ambiguity of depth. State-of-the-art methods try to solve this problem by leveraging visual information from a single image or video, whereas 3D mesh animation approaches rely more on audio. However, in most cases (e.g. AR/VR applications), videos include both visual and speech information. We propose AVFace that incorporates both modalities and accurately reconstructs the 4D facial and lip motion of any speaker, without requiring any 3D ground truth for training. A coarse stage estimates the per-frame parameters of a 3D morphable model, followed by a lip refinement, and then a fine stage recovers facial geometric details. Due to the temporal audio and video information captured by transformer-based modules, our method is robust in cases when either modality is insufficient (e.g. face occlusions). Extensive qualitative and quantitative evaluation demonstrates the superiority of our method over the current state-of-the-art.
Invariant Scattering Transform for Medical Imaging
Apr 20, 2023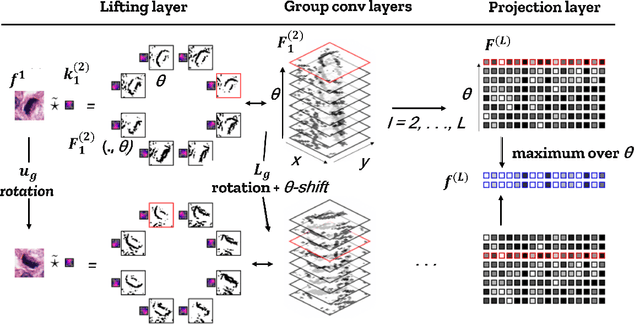
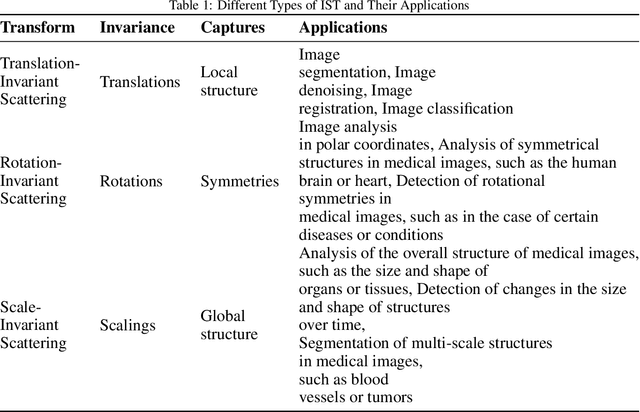
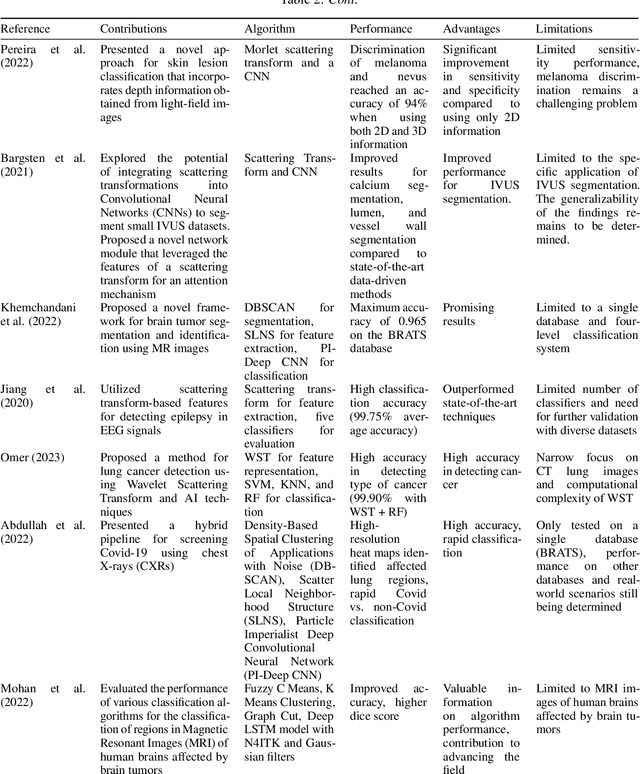
Over the years, the Invariant Scattering Transform (IST) technique has become popular for medical image analysis, including using wavelet transform computation using Convolutional Neural Networks (CNN) to capture patterns' scale and orientation in the input signal. IST aims to be invariant to transformations that are common in medical images, such as translation, rotation, scaling, and deformation, used to improve the performance in medical imaging applications such as segmentation, classification, and registration, which can be integrated into machine learning algorithms for disease detection, diagnosis, and treatment planning. Additionally, combining IST with deep learning approaches has the potential to leverage their strengths and enhance medical image analysis outcomes. This study provides an overview of IST in medical imaging by considering the types of IST, their application, limitations, and potential scopes for future researchers and practitioners.
CLUSTSEG: Clustering for Universal Segmentation
May 03, 2023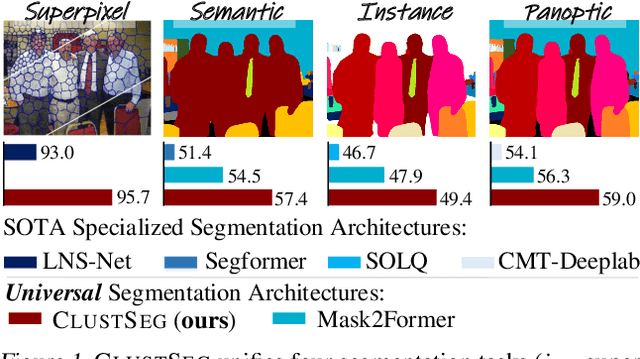
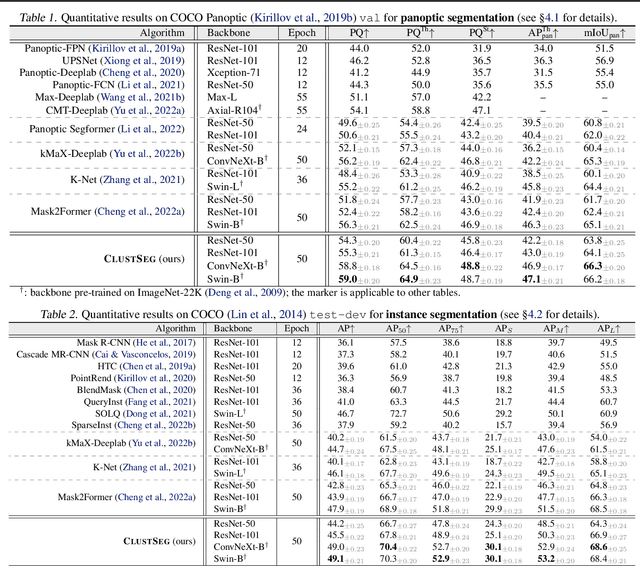
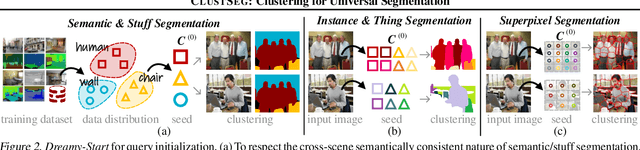
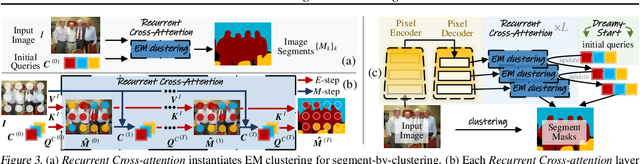
We present CLUSTSEG, a general, transformer-based framework that tackles different image segmentation tasks (i.e., superpixel, semantic, instance, and panoptic) through a unified neural clustering scheme. Regarding queries as cluster centers, CLUSTSEG is innovative in two aspects:1) cluster centers are initialized in heterogeneous ways so as to pointedly address task-specific demands (e.g., instance- or category-level distinctiveness), yet without modifying the architecture; and 2) pixel-cluster assignment, formalized in a cross-attention fashion, is alternated with cluster center update, yet without learning additional parameters. These innovations closely link CLUSTSEG to EM clustering and make it a transparent and powerful framework that yields superior results across the above segmentation tasks.
Using Spatio-Temporal Dual-Stream Network with Self-Supervised Learning for Lung Tumor Classification on Radial Probe Endobronchial Ultrasound Video
May 04, 2023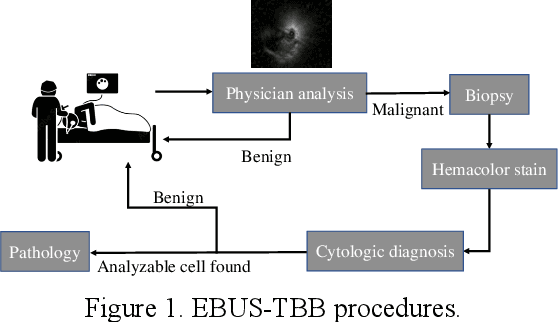
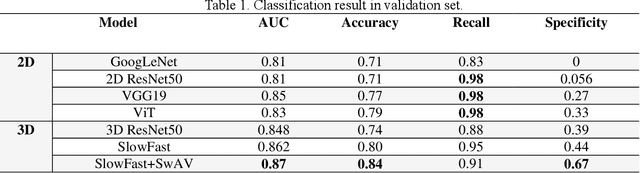
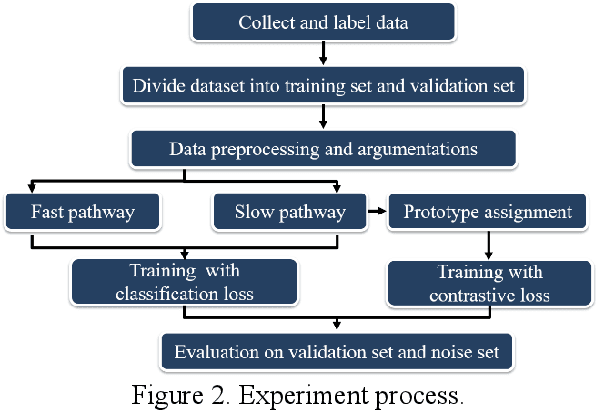
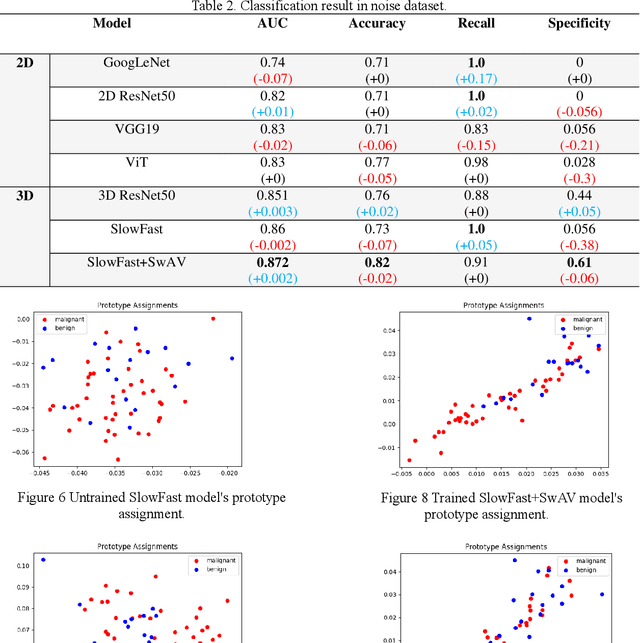
The purpose of this study is to develop a computer-aided diagnosis system for classifying benign and malignant lung lesions, and to assist physicians in real-time analysis of radial probe endobronchial ultrasound (EBUS) videos. During the biopsy process of lung cancer, physicians use real-time ultrasound images to find suitable lesion locations for sampling. However, most of these images are difficult to classify and contain a lot of noise. Previous studies have employed 2D convolutional neural networks to effectively differentiate between benign and malignant lung lesions, but doctors still need to manually select good-quality images, which can result in additional labor costs. In addition, the 2D neural network has no ability to capture the temporal information of the ultrasound video, so it is difficult to obtain the relationship between the features of the continuous images. This study designs an automatic diagnosis system based on a 3D neural network, uses the SlowFast architecture as the backbone to fuse temporal and spatial features, and uses the SwAV method of contrastive learning to enhance the noise robustness of the model. The method we propose includes the following advantages, such as (1) using clinical ultrasound films as model input, thereby reducing the need for high-quality image selection by physicians, (2) high-accuracy classification of benign and malignant lung lesions can assist doctors in clinical diagnosis and reduce the time and risk of surgery, and (3) the capability to classify well even in the presence of significant image noise. The AUC, accuracy, precision, recall and specificity of our proposed method on the validation set reached 0.87, 83.87%, 86.96%, 90.91% and 66.67%, respectively. The results have verified the importance of incorporating temporal information and the effectiveness of using the method of contrastive learning on feature extraction.
PIP: Positional-encoding Image Prior
Nov 25, 2022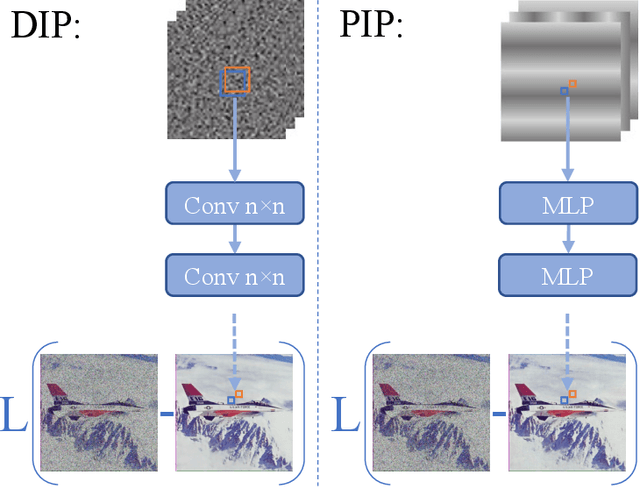
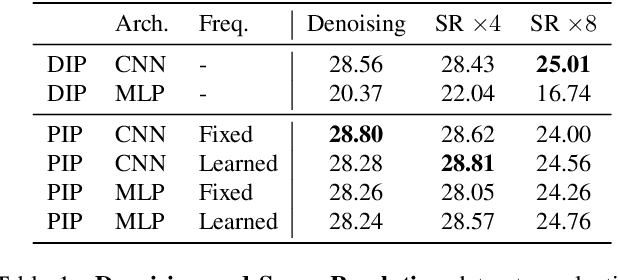
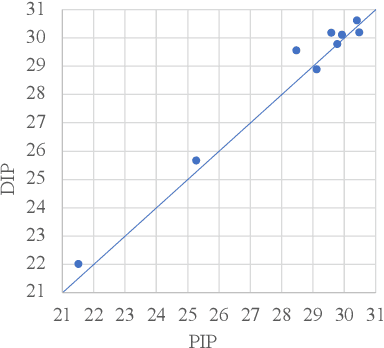
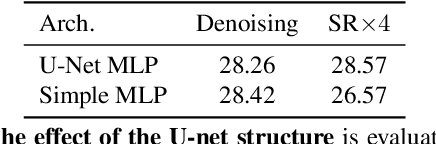
In Deep Image Prior (DIP), a Convolutional Neural Network (CNN) is fitted to map a latent space to a degraded (e.g. noisy) image but in the process learns to reconstruct the clean image. This phenomenon is attributed to CNN's internal image-prior. We revisit the DIP framework, examining it from the perspective of a neural implicit representation. Motivated by this perspective, we replace the random or learned latent with Fourier-Features (Positional Encoding). We show that thanks to the Fourier features properties, we can replace the convolution layers with simple pixel-level MLPs. We name this scheme ``Positional Encoding Image Prior" (PIP) and exhibit that it performs very similarly to DIP on various image-reconstruction tasks with much less parameters required. Additionally, we demonstrate that PIP can be easily extended to videos, where 3D-DIP struggles and suffers from instability. Code and additional examples for all tasks, including videos, are available on the project page https://nimrodshabtay.github.io/PIP/
Accuracy Improvement of Object Detection in VVC Coded Video Using YOLO-v7 Features
Apr 03, 2023
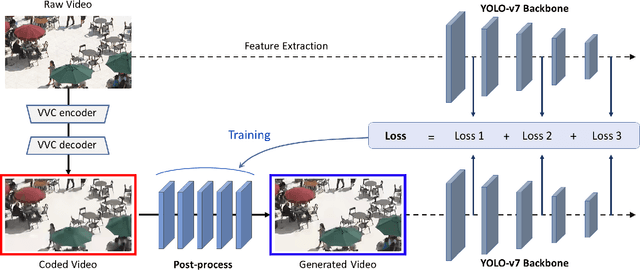
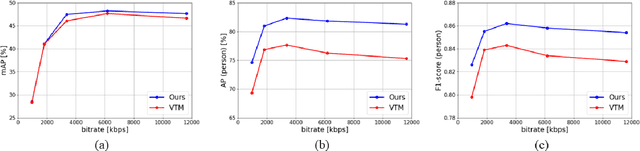

With advances in image recognition technology based on deep learning, automatic video analysis by Artificial Intelligence is becoming more widespread. As the amount of video used for image recognition increases, efficient compression methods for such video data are necessary. In general, when the image quality deteriorates due to image encoding, the image recognition accuracy also falls. Therefore, in this paper, we propose a neural-network-based approach to improve image recognition accuracy, especially the object detection accuracy by applying post-processing to the encoded video. Versatile Video Coding (VVC) will be used for the video compression method, since it is the latest video coding method with the best encoding performance. The neural network is trained using the features of YOLO-v7, the latest object detection model. By using VVC as the video coding method and YOLO-v7 as the detection model, high object detection accuracy is achieved even at low bit rates. Experimental results show that the combination of the proposed method and VVC achieves better coding performance than regular VVC in object detection accuracy.
What does CLIP know about a red circle? Visual prompt engineering for VLMs
Apr 13, 2023
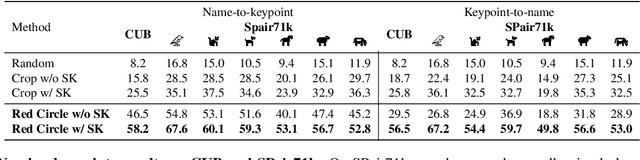
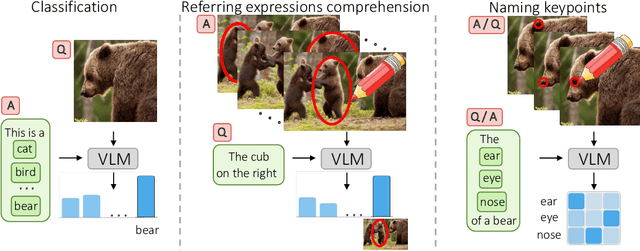

Large-scale Vision-Language Models, such as CLIP, learn powerful image-text representations that have found numerous applications, from zero-shot classification to text-to-image generation. Despite that, their capabilities for solving novel discriminative tasks via prompting fall behind those of large language models, such as GPT-3. Here we explore the idea of visual prompt engineering for solving computer vision tasks beyond classification by editing in image space instead of text. In particular, we discover an emergent ability of CLIP, where, by simply drawing a red circle around an object, we can direct the model's attention to that region, while also maintaining global information. We show the power of this simple approach by achieving state-of-the-art in zero-shot referring expressions comprehension and strong performance in keypoint localization tasks. Finally, we draw attention to some potential ethical concerns of large language-vision models.