 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
The race to robustness: exploiting fragile models for urban camouflage and the imperative for machine learning security
Jun 26, 2023
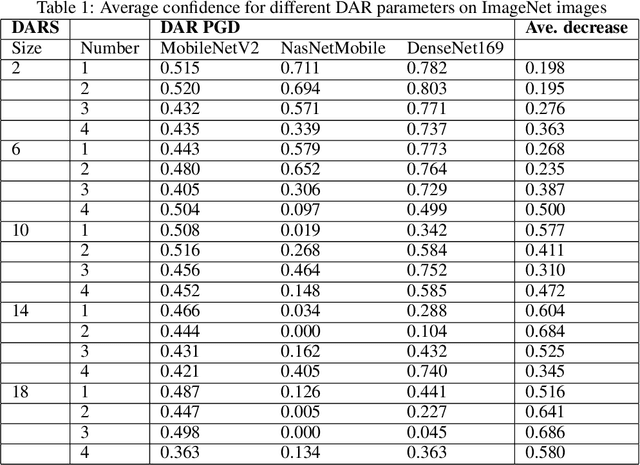
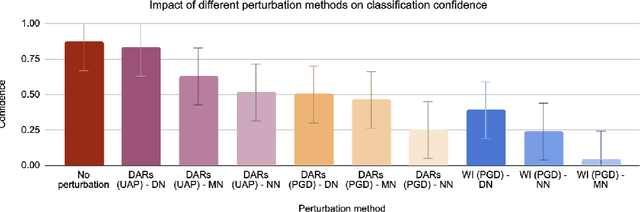

Adversarial Machine Learning (AML) represents the ability to disrupt Machine Learning (ML) algorithms through a range of methods that broadly exploit the architecture of deep learning optimisation. This paper presents Distributed Adversarial Regions (DAR), a novel method that implements distributed instantiations of computer vision-based AML attack methods that may be used to disguise objects from image recognition in both white and black box settings. We consider the context of object detection models used in urban environments, and benchmark the MobileNetV2, NasNetMobile and DenseNet169 models against a subset of relevant images from the ImageNet dataset. We evaluate optimal parameters (size, number and perturbation method), and compare to state-of-the-art AML techniques that perturb the entire image. We find that DARs can cause a reduction in confidence of 40.4% on average, but with the benefit of not requiring the entire image, or the focal object, to be perturbed. The DAR method is a deliberately simple approach where the intention is to highlight how an adversary with very little skill could attack models that may already be productionised, and to emphasise the fragility of foundational object detection models. We present this as a contribution to the field of ML security as well as AML. This paper contributes a novel adversarial method, an original comparison between DARs and other AML methods, and frames it in a new context - that of urban camouflage and the necessity for ML security and model robustness.
Building and Road Segmentation Using EffUNet and Transfer Learning Approach
Jul 08, 2023In city, information about urban objects such as water supply, railway lines, power lines, buildings, roads, etc., is necessary for city planning. In particular, information about the spread of these objects, locations and capacity is needed for the policymakers to make impactful decisions. This thesis aims to segment the building and roads from the aerial image captured by the satellites and UAVs. Many different architectures have been proposed for the semantic segmentation task and UNet being one of them. In this thesis, we propose a novel architecture based on Google's newly proposed EfficientNetV2 as an encoder for feature extraction with UNet decoder for constructing the segmentation map. Using this approach we achieved a benchmark score for the Massachusetts Building and Road dataset with an mIOU of 0.8365 and 0.9153 respectively.
Practical and Asymptotically Exact Conditional Sampling in Diffusion Models
Jun 30, 2023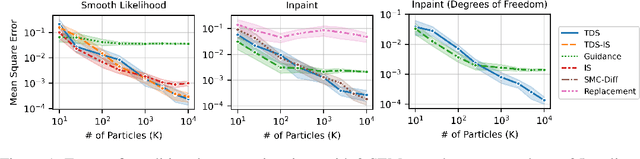
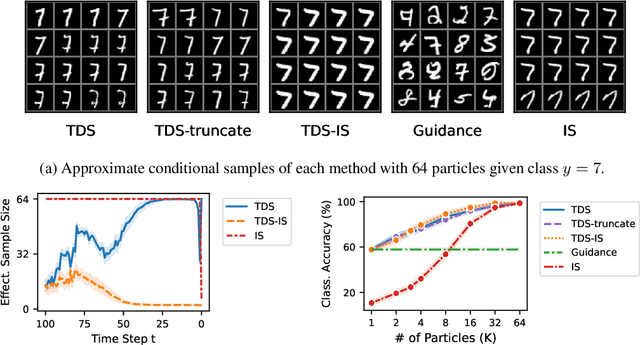
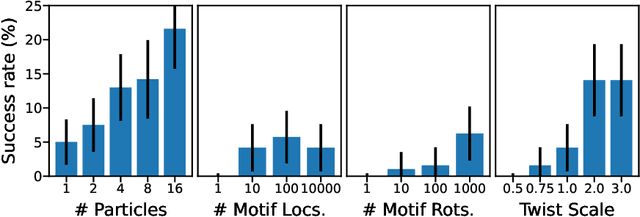
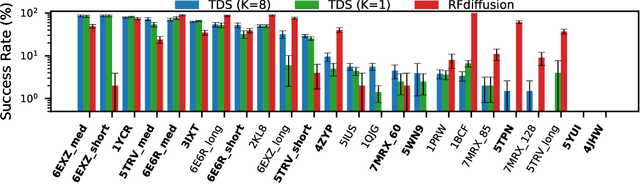
Diffusion models have been successful on a range of conditional generation tasks including molecular design and text-to-image generation. However, these achievements have primarily depended on task-specific conditional training or error-prone heuristic approximations. Ideally, a conditional generation method should provide exact samples for a broad range of conditional distributions without requiring task-specific training. To this end, we introduce the Twisted Diffusion Sampler, or TDS. TDS is a sequential Monte Carlo (SMC) algorithm that targets the conditional distributions of diffusion models. The main idea is to use twisting, an SMC technique that enjoys good computational efficiency, to incorporate heuristic approximations without compromising asymptotic exactness. We first find in simulation and on MNIST image inpainting and class-conditional generation tasks that TDS provides a computational statistical trade-off, yielding more accurate approximations with many particles but with empirical improvements over heuristics with as few as two particles. We then turn to motif-scaffolding, a core task in protein design, using a TDS extension to Riemannian diffusion models. On benchmark test cases, TDS allows flexible conditioning criteria and often outperforms the state of the art.
EmoSet: A Large-scale Visual Emotion Dataset with Rich Attributes
Jul 16, 2023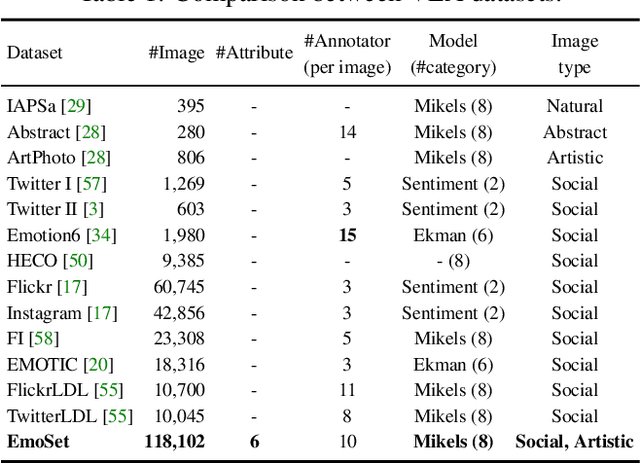
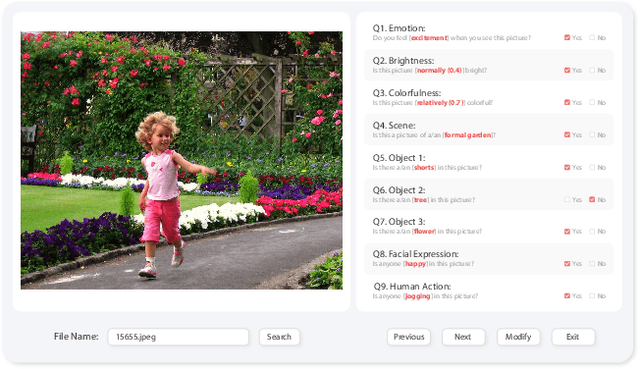
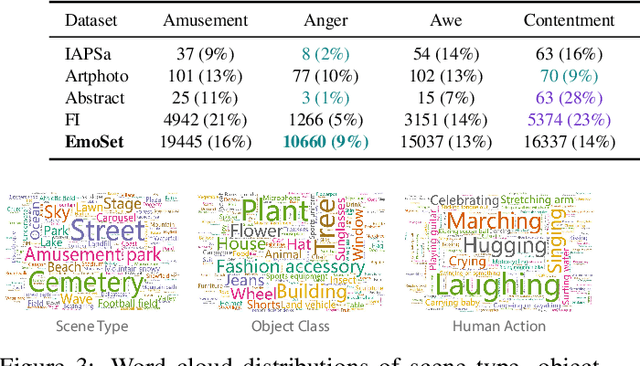
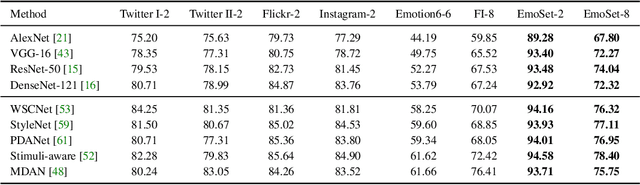
Visual Emotion Analysis (VEA) aims at predicting people's emotional responses to visual stimuli. This is a promising, yet challenging, task in affective computing, which has drawn increasing attention in recent years. Most of the existing work in this area focuses on feature design, while little attention has been paid to dataset construction. In this work, we introduce EmoSet, the first large-scale visual emotion dataset annotated with rich attributes, which is superior to existing datasets in four aspects: scale, annotation richness, diversity, and data balance. EmoSet comprises 3.3 million images in total, with 118,102 of these images carefully labeled by human annotators, making it five times larger than the largest existing dataset. EmoSet includes images from social networks, as well as artistic images, and it is well balanced between different emotion categories. Motivated by psychological studies, in addition to emotion category, each image is also annotated with a set of describable emotion attributes: brightness, colorfulness, scene type, object class, facial expression, and human action, which can help understand visual emotions in a precise and interpretable way. The relevance of these emotion attributes is validated by analyzing the correlations between them and visual emotion, as well as by designing an attribute module to help visual emotion recognition. We believe EmoSet will bring some key insights and encourage further research in visual emotion analysis and understanding. The data and code will be released after the publication of this work.
Learning with Difference Attention for Visually Grounded Self-supervised Representations
Jun 26, 2023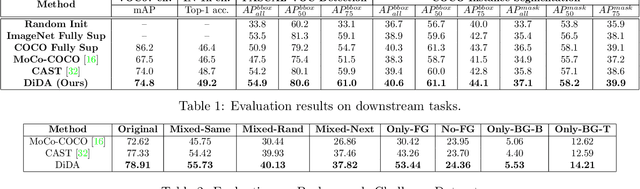


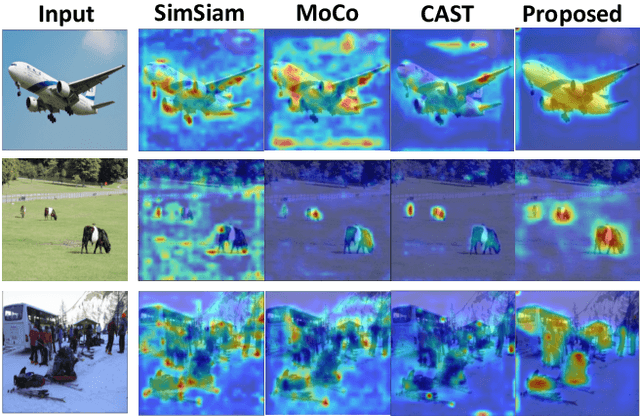
Recent works in self-supervised learning have shown impressive results on single-object images, but they struggle to perform well on complex multi-object images as evidenced by their poor visual grounding. To demonstrate this concretely, we propose visual difference attention (VDA) to compute visual attention maps in an unsupervised fashion by comparing an image with its salient-regions-masked-out version. We use VDA to derive attention maps for state-of-the art SSL methods and show they do not highlight all salient regions in an image accurately, suggesting their inability to learn strong representations for downstream tasks like segmentation. Motivated by these limitations, we cast VDA as a differentiable operation and propose a new learning objective, Differentiable Difference Attention (DiDA) loss, which leads to substantial improvements in an SSL model's visually grounding to an image's salient regions.
Asymmetrically-powered Neural Image Compression with Shallow Decoders
Apr 13, 2023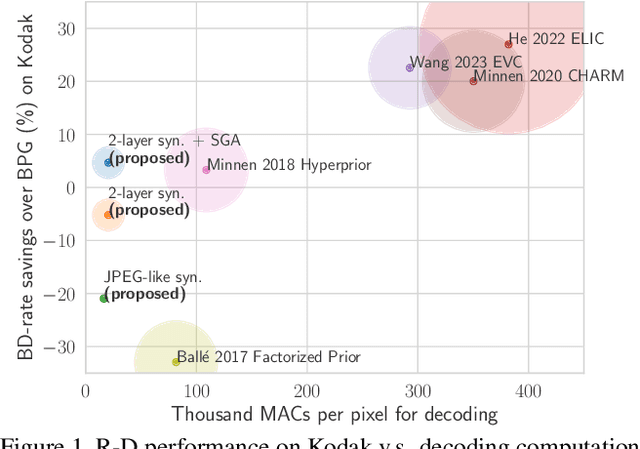
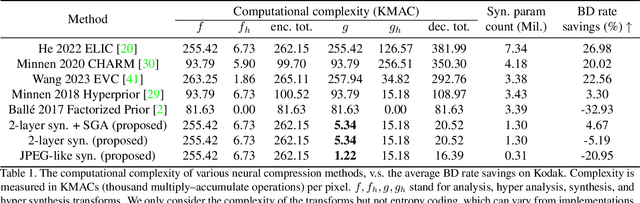

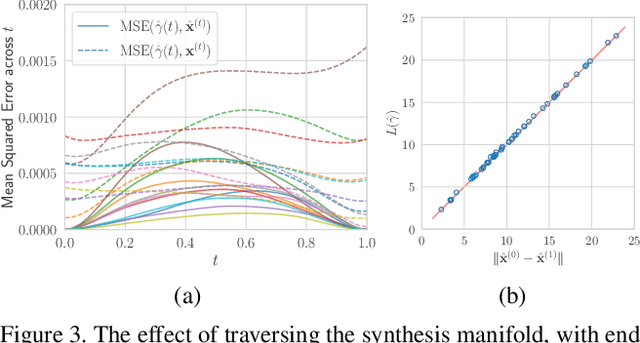
Neural image compression methods have seen increasingly strong performance in recent years. However, they suffer orders of magnitude higher computational complexity compared to traditional codecs, which stands in the way of real-world deployment. This paper takes a step forward in closing this gap in decoding complexity by adopting shallow or even linear decoding transforms. To compensate for the resulting drop in compression performance, we exploit the often asymmetrical computation budget between encoding and decoding, by adopting more powerful encoder networks and iterative encoding. We theoretically formalize the intuition behind, and our experimental results establish a new frontier in the trade-off between rate-distortion and decoding complexity for neural image compression. Specifically, we achieve rate-distortion performance competitive with the established mean-scale hyperprior architecture of Minnen et al. (2018), while reducing the overall decoding complexity by 80 %, or over 90 % for the synthesis transform alone. Our code can be found at https://github.com/mandt-lab/shallow-ntc.
Test your samples jointly: Pseudo-reference for image quality evaluation
Apr 07, 2023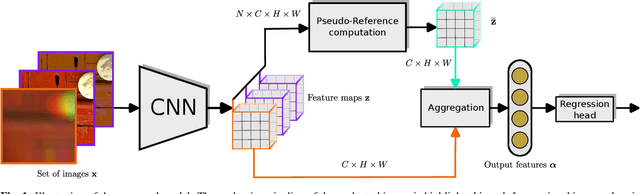
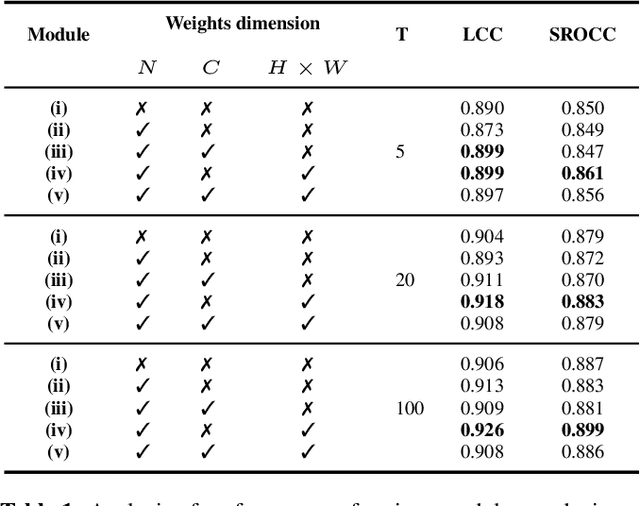
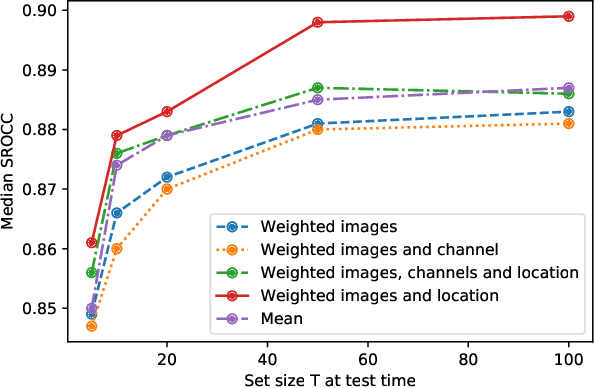
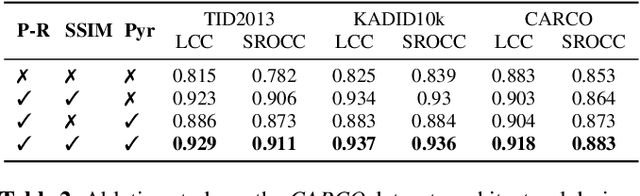
In this paper, we address the well-known image quality assessment problem but in contrast from existing approaches that predict image quality independently for every images, we propose to jointly model different images depicting the same content to improve the precision of quality estimation. This proposal is motivated by the idea that multiple distorted images can provide information to disambiguate image features related to content and quality. To this aim, we combine the feature representations from the different images to estimate a pseudo-reference that we use to enhance score prediction. Our experiments show that at test-time, our method successfully combines the features from multiple images depicting the same new content, improving estimation quality.
Multitemporal SAR images change detection and visualization using RABASAR and simplified GLR
Jul 15, 2023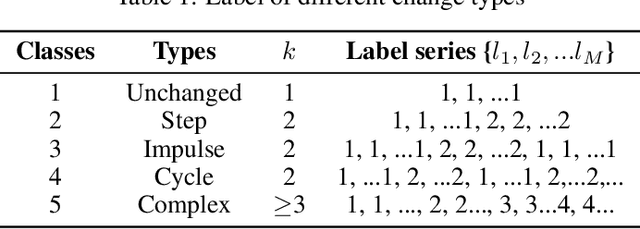
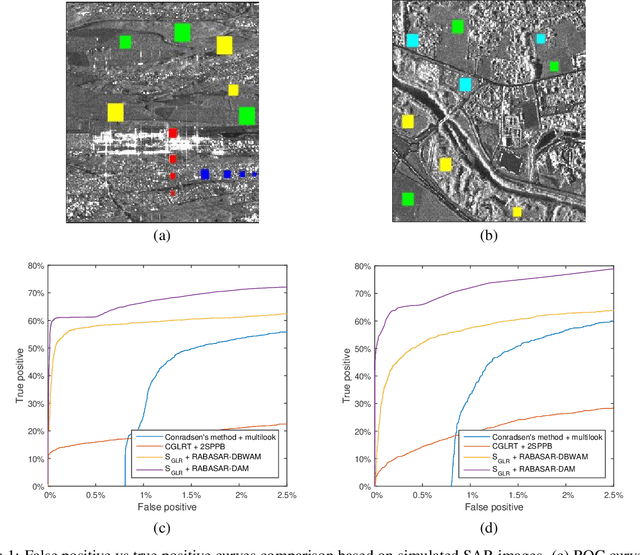


Understanding the state of changed areas requires that precise information be given about the changes. Thus, detecting different kinds of changes is important for land surface monitoring. SAR sensors are ideal to fulfil this task, because of their all-time and all-weather capabilities, with good accuracy of the acquisition geometry and without effects of atmospheric constituents for amplitude data. In this study, we propose a simplified generalized likelihood ratio ($S_{GLR}$) method assuming that corresponding temporal pixels have the same equivalent number of looks (ENL). Thanks to the denoised data provided by a ratio-based multitemporal SAR image denoising method (RABASAR), we successfully applied this similarity test approach to compute the change areas. A new change magnitude index method and an improved spectral clustering-based change classification method are also developed. In addition, we apply the simplified generalized likelihood ratio to detect the maximum change magnitude time, and the change starting and ending times. Then, we propose to use an adaptation of the REACTIV method to visualize the detection results vividly. The effectiveness of the proposed methods is demonstrated through the processing of simulated and SAR images, and the comparison with classical techniques. In particular, numerical experiments proved that the developed method has good performances in detecting farmland area changes, building area changes, harbour area changes and flooding area changes.
Joint Adversarial and Collaborative Learning for Self-Supervised Action Recognition
Jul 15, 2023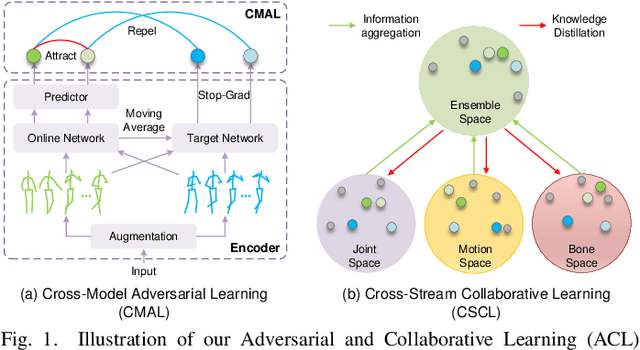
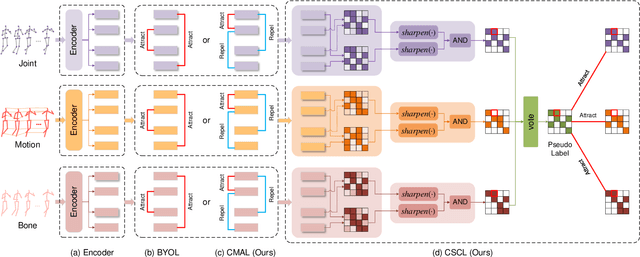
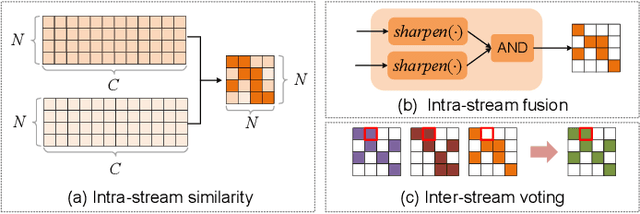
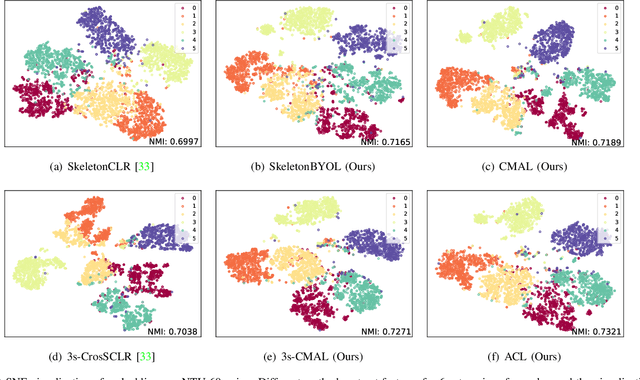
Considering the instance-level discriminative ability, contrastive learning methods, including MoCo and SimCLR, have been adapted from the original image representation learning task to solve the self-supervised skeleton-based action recognition task. These methods usually use multiple data streams (i.e., joint, motion, and bone) for ensemble learning, meanwhile, how to construct a discriminative feature space within a single stream and effectively aggregate the information from multiple streams remains an open problem. To this end, we first apply a new contrastive learning method called BYOL to learn from skeleton data and formulate SkeletonBYOL as a simple yet effective baseline for self-supervised skeleton-based action recognition. Inspired by SkeletonBYOL, we further present a joint Adversarial and Collaborative Learning (ACL) framework, which combines Cross-Model Adversarial Learning (CMAL) and Cross-Stream Collaborative Learning (CSCL). Specifically, CMAL learns single-stream representation by cross-model adversarial loss to obtain more discriminative features. To aggregate and interact with multi-stream information, CSCL is designed by generating similarity pseudo label of ensemble learning as supervision and guiding feature generation for individual streams. Exhaustive experiments on three datasets verify the complementary properties between CMAL and CSCL and also verify that our method can perform favorably against state-of-the-art methods using various evaluation protocols. Our code and models are publicly available at \url{https://github.com/Levigty/ACL}.
Re-IQA: Unsupervised Learning for Image Quality Assessment in the Wild
Apr 02, 2023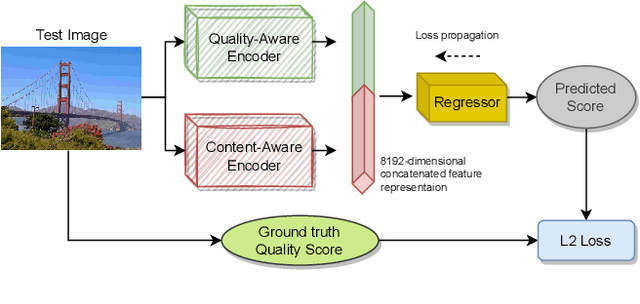


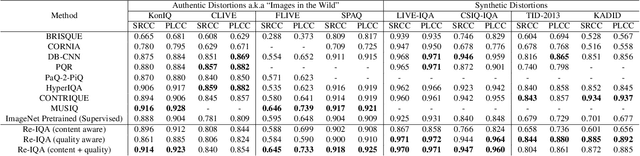
Automatic Perceptual Image Quality Assessment is a challenging problem that impacts billions of internet, and social media users daily. To advance research in this field, we propose a Mixture of Experts approach to train two separate encoders to learn high-level content and low-level image quality features in an unsupervised setting. The unique novelty of our approach is its ability to generate low-level representations of image quality that are complementary to high-level features representing image content. We refer to the framework used to train the two encoders as Re-IQA. For Image Quality Assessment in the Wild, we deploy the complementary low and high-level image representations obtained from the Re-IQA framework to train a linear regression model, which is used to map the image representations to the ground truth quality scores, refer Figure 1. Our method achieves state-of-the-art performance on multiple large-scale image quality assessment databases containing both real and synthetic distortions, demonstrating how deep neural networks can be trained in an unsupervised setting to produce perceptually relevant representations. We conclude from our experiments that the low and high-level features obtained are indeed complementary and positively impact the performance of the linear regressor. A public release of all the codes associated with this work will be made available on GitHub.