 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Downstream-agnostic Adversarial Examples
Jul 23, 2023
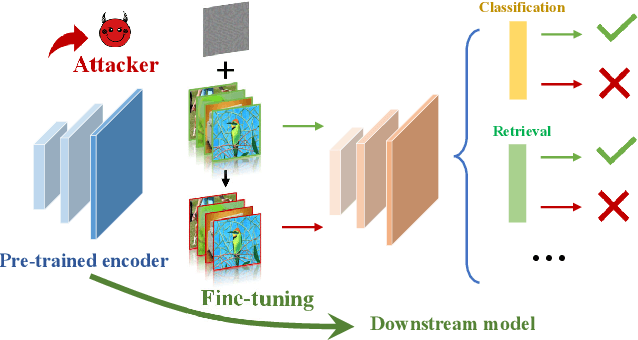
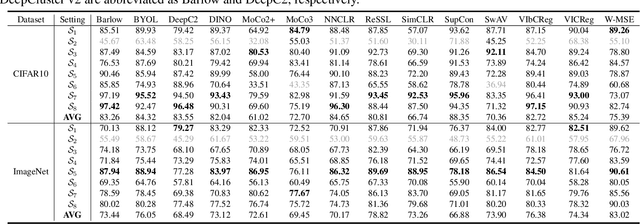
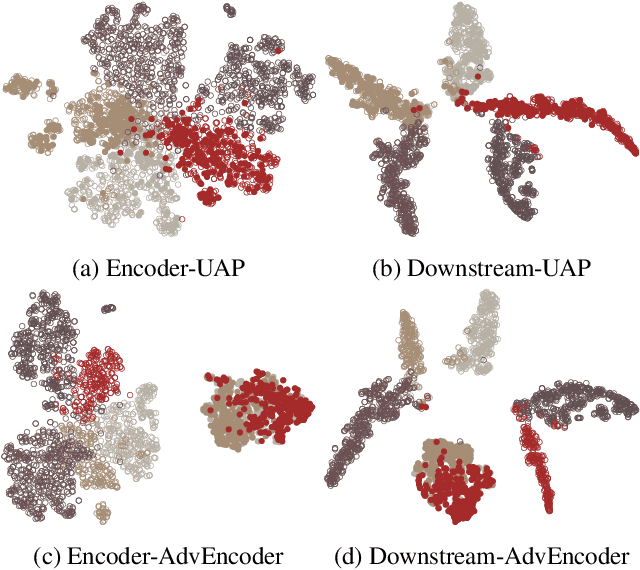
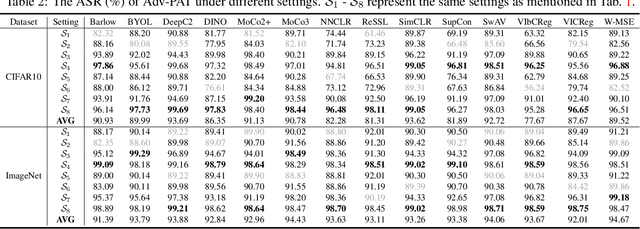
Self-supervised learning usually uses a large amount of unlabeled data to pre-train an encoder which can be used as a general-purpose feature extractor, such that downstream users only need to perform fine-tuning operations to enjoy the benefit of "large model". Despite this promising prospect, the security of pre-trained encoder has not been thoroughly investigated yet, especially when the pre-trained encoder is publicly available for commercial use. In this paper, we propose AdvEncoder, the first framework for generating downstream-agnostic universal adversarial examples based on the pre-trained encoder. AdvEncoder aims to construct a universal adversarial perturbation or patch for a set of natural images that can fool all the downstream tasks inheriting the victim pre-trained encoder. Unlike traditional adversarial example works, the pre-trained encoder only outputs feature vectors rather than classification labels. Therefore, we first exploit the high frequency component information of the image to guide the generation of adversarial examples. Then we design a generative attack framework to construct adversarial perturbations/patches by learning the distribution of the attack surrogate dataset to improve their attack success rates and transferability. Our results show that an attacker can successfully attack downstream tasks without knowing either the pre-training dataset or the downstream dataset. We also tailor four defenses for pre-trained encoders, the results of which further prove the attack ability of AdvEncoder.
Edge-Aware Image Color Appearance and Difference Modeling
Apr 20, 2023
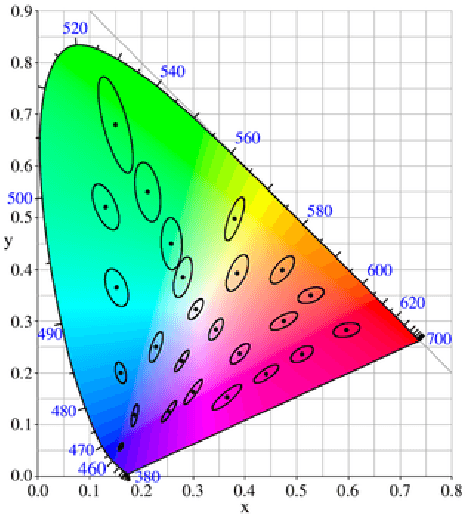

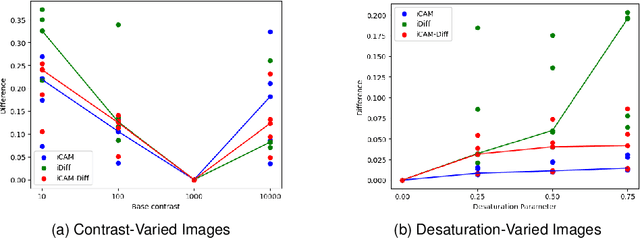
The perception of color is one of the most important aspects of human vision. From an evolutionary perspective, the accurate perception of color is crucial to distinguishing friend from foe, and food from fatal poison. As a result, humans have developed a keen sense of color and are able to detect subtle differences in appearance, while also robustly identifying colors across illumination and viewing conditions. In this paper, we shall briefly review methods for adapting traditional color appearance and difference models to complex image stimuli, and propose mechanisms to improve their performance. In particular, we find that applying contrast sensitivity functions and local adaptation rules in an edge-aware manner improves image difference predictions.
CFSum: A Coarse-to-Fine Contribution Network for Multimodal Summarization
Jul 06, 2023
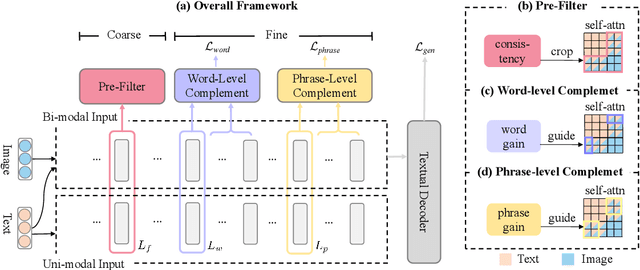
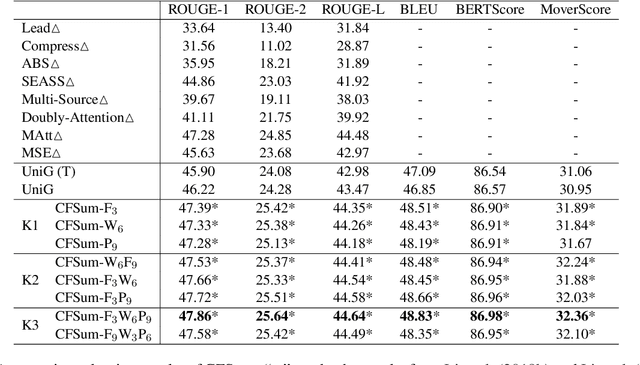
Multimodal summarization usually suffers from the problem that the contribution of the visual modality is unclear. Existing multimodal summarization approaches focus on designing the fusion methods of different modalities, while ignoring the adaptive conditions under which visual modalities are useful. Therefore, we propose a novel Coarse-to-Fine contribution network for multimodal Summarization (CFSum) to consider different contributions of images for summarization. First, to eliminate the interference of useless images, we propose a pre-filter module to abandon useless images. Second, to make accurate use of useful images, we propose two levels of visual complement modules, word level and phrase level. Specifically, image contributions are calculated and are adopted to guide the attention of both textual and visual modalities. Experimental results have shown that CFSum significantly outperforms multiple strong baselines on the standard benchmark. Furthermore, the analysis verifies that useful images can even help generate non-visual words which are implicitly represented in the image.
Image Blending with Osmosis
Mar 15, 2023



Image blending is an integral part of many multi-image applications such as panorama stitching or remote image acquisition processes. In such scenarios, multiple images are connected at predefined boundaries to form a larger image. A convincing transition between these boundaries may be challenging, since each image might have been acquired under different conditions or even by different devices. We propose the first blending approach based on osmosis filters. These drift-diffusion processes define an image evolution with a non-trivial steady state. For our blending purposes, we explore several ways to compose drift vector fields based on the derivatives of our input images. These vector fields guide the evolution such that the steady state yields a convincing blended result. Our method benefits from the well-founded theoretical results for osmosis, which include useful invariances under multiplicative changes of the colour values. Experiments on real-world data show that this yields better quality than traditional gradient domain blending, especially under challenging illumination conditions.
A comparative evaluation of image-to-image translation methods for stain transfer in histopathology
Mar 29, 2023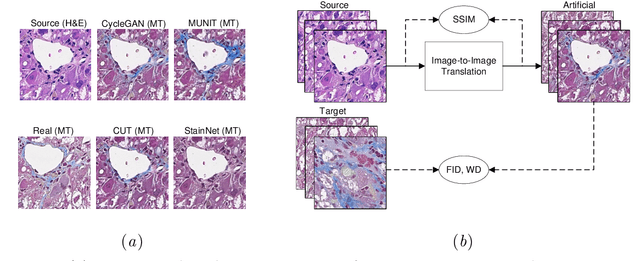
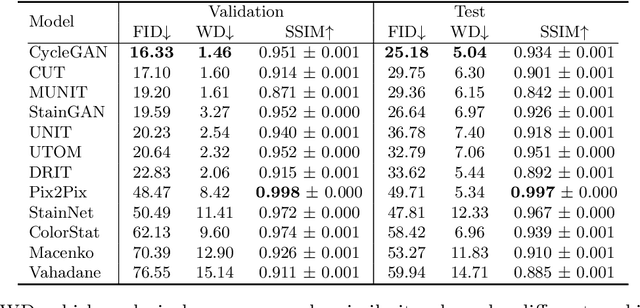


Image-to-image translation (I2I) methods allow the generation of artificial images that share the content of the original image but have a different style. With the advances in Generative Adversarial Networks (GANs)-based methods, I2I methods enabled the generation of artificial images that are indistinguishable from natural images. Recently, I2I methods were also employed in histopathology for generating artificial images of in silico stained tissues from a different type of staining. We refer to this process as stain transfer. The number of I2I variants is constantly increasing, which makes a well justified choice of the most suitable I2I methods for stain transfer challenging. In our work, we compare twelve stain transfer approaches, three of which are based on traditional and nine on GAN-based image processing methods. The analysis relies on complementary quantitative measures for the quality of image translation, the assessment of the suitability for deep learning-based tissue grading, and the visual evaluation by pathologists. Our study highlights the strengths and weaknesses of the stain transfer approaches, thereby allowing a rational choice of the underlying I2I algorithms. Code, data, and trained models for stain transfer between H&E and Masson's Trichrome staining will be made available online.
Answer Mining from a Pool of Images: Towards Retrieval-Based Visual Question Answering
Jun 29, 2023
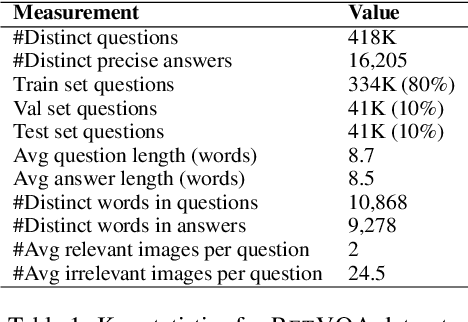
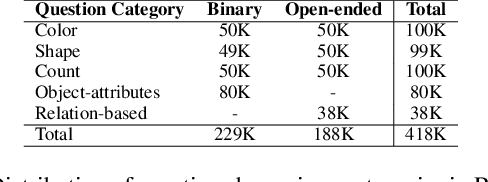
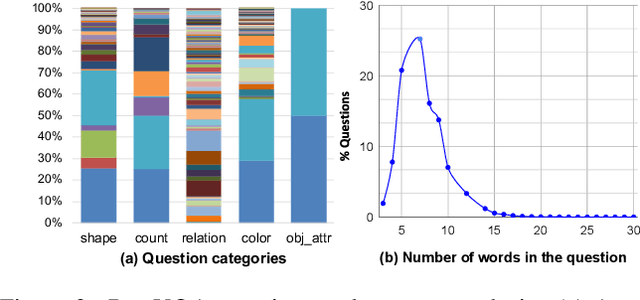
We study visual question answering in a setting where the answer has to be mined from a pool of relevant and irrelevant images given as a context. For such a setting, a model must first retrieve relevant images from the pool and answer the question from these retrieved images. We refer to this problem as retrieval-based visual question answering (or RETVQA in short). The RETVQA is distinctively different and more challenging than the traditionally-studied Visual Question Answering (VQA), where a given question has to be answered with a single relevant image in context. Towards solving the RETVQA task, we propose a unified Multi Image BART (MI-BART) that takes a question and retrieved images using our relevance encoder for free-form fluent answer generation. Further, we introduce the largest dataset in this space, namely RETVQA, which has the following salient features: multi-image and retrieval requirement for VQA, metadata-independent questions over a pool of heterogeneous images, expecting a mix of classification-oriented and open-ended generative answers. Our proposed framework achieves an accuracy of 76.5% and a fluency of 79.3% on the proposed dataset, namely RETVQA and also outperforms state-of-the-art methods by 4.9% and 11.8% on the image segment of the publicly available WebQA dataset on the accuracy and fluency metrics, respectively.
TransHP: Image Classification with Hierarchical Prompting
Apr 13, 2023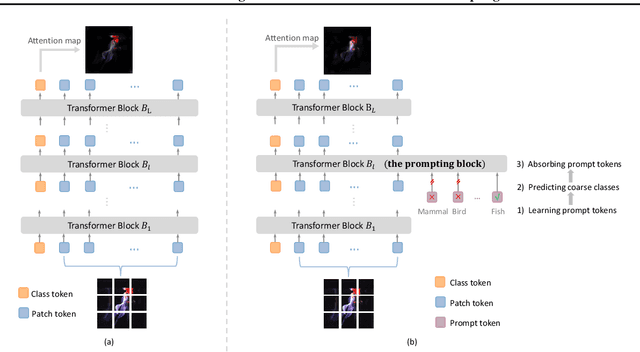

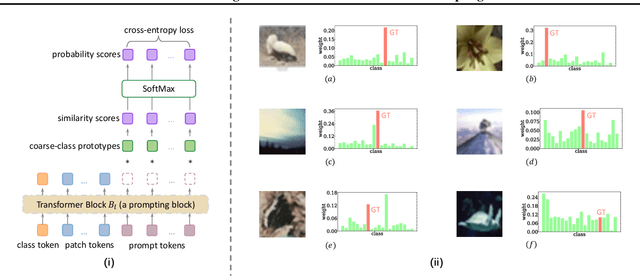

This paper explores a hierarchical prompting mechanism for the hierarchical image classification (HIC) task. Different from prior HIC methods, our hierarchical prompting is the first to explicitly inject ancestor-class information as a tokenized hint that benefits the descendant-class discrimination. We think it well imitates human visual recognition, i.e., humans may use the ancestor class as a prompt to draw focus on the subtle differences among descendant classes. We model this prompting mechanism into a Transformer with Hierarchical Prompting (TransHP). TransHP consists of three steps: 1) learning a set of prompt tokens to represent the coarse (ancestor) classes, 2) on-the-fly predicting the coarse class of the input image at an intermediate block, and 3) injecting the prompt token of the predicted coarse class into the intermediate feature. Though the parameters of TransHP maintain the same for all input images, the injected coarse-class prompt conditions (modifies) the subsequent feature extraction and encourages a dynamic focus on relatively subtle differences among the descendant classes. Extensive experiments show that TransHP improves image classification on accuracy (e.g., improving ViT-B/16 by +2.83% ImageNet classification accuracy), training data efficiency (e.g., +12.69% improvement under 10% ImageNet training data), and model explainability. Moreover, TransHP also performs favorably against prior HIC methods, showing that TransHP well exploits the hierarchical information.
DiffWA: Diffusion Models for Watermark Attack
Jun 22, 2023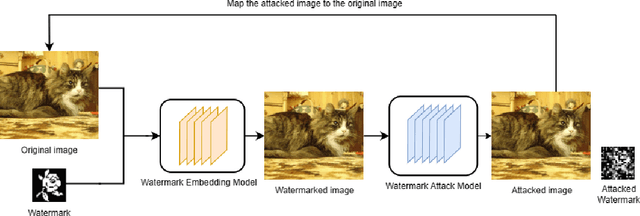



With the rapid development of deep neural networks(DNNs), many robust blind watermarking algorithms and frameworks have been proposed and achieved good results. At present, the watermark attack algorithm can not compete with the watermark addition algorithm. And many watermark attack algorithms only care about interfering with the normal extraction of the watermark, and the watermark attack will cause great visual loss to the image. To this end, we propose DiffWA, a conditional diffusion model with distance guidance for watermark attack, which can restore the image while removing the embedded watermark. The core of our method is training an image-to-image conditional diffusion model on unwatermarked images and guiding the conditional model using a distance guidance when sampling so that the model will generate unwatermarked images which is similar to original images. We conducted experiments on CIFAR-10 using our proposed models. The results shows that the model can remove the watermark with good effect and make the bit error rate of watermark extraction higher than 0.4. At the same time, the attacked image will maintain good visual effect with PSNR more than 31 and SSIM more than 0.97 compared with the original image.
Domain Generalisation with Bidirectional Encoder Representations from Vision Transformers
Jul 16, 2023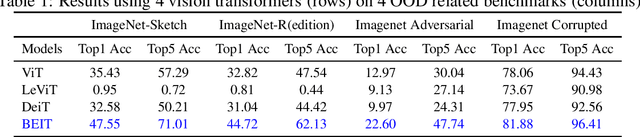

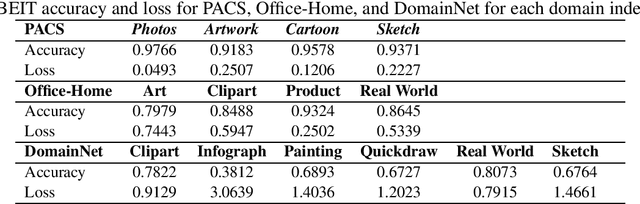
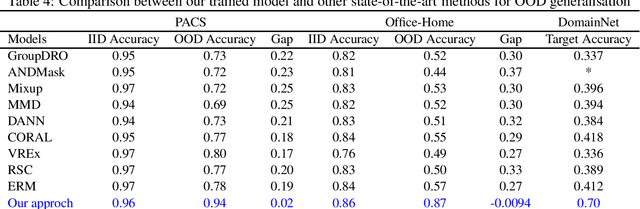
Domain generalisation involves pooling knowledge from source domain(s) into a single model that can generalise to unseen target domain(s). Recent research in domain generalisation has faced challenges when using deep learning models as they interact with data distributions which differ from those they are trained on. Here we perform domain generalisation on out-of-distribution (OOD) vision benchmarks using vision transformers. Initially we examine four vision transformer architectures namely ViT, LeViT, DeiT, and BEIT on out-of-distribution data. As the bidirectional encoder representation from image transformers (BEIT) architecture performs best, we use it in further experiments on three benchmarks PACS, Home-Office and DomainNet. Our results show significant improvements in validation and test accuracy and our implementation significantly overcomes gaps between within-distribution and OOD data.
Registration-Free Hybrid Learning Empowers Simple Multimodal Imaging System for High-quality Fusion Detection
Jul 07, 2023
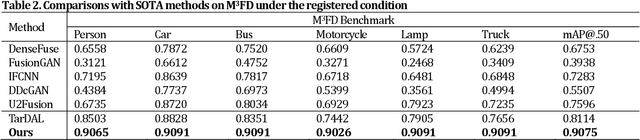

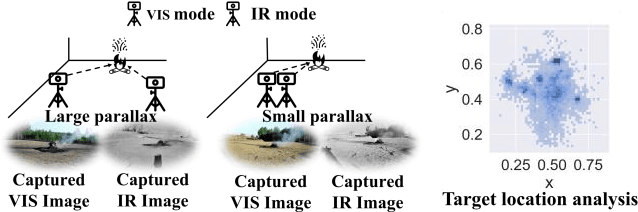
Multimodal fusion detection always places high demands on the imaging system and image pre-processing, while either a high-quality pre-registration system or image registration processing is costly. Unfortunately, the existing fusion methods are designed for registered source images, and the fusion of inhomogeneous features, which denotes a pair of features at the same spatial location that expresses different semantic information, cannot achieve satisfactory performance via these methods. As a result, we propose IA-VFDnet, a CNN-Transformer hybrid learning framework with a unified high-quality multimodal feature matching module (AKM) and a fusion module (WDAF), in which AKM and DWDAF work in synergy to perform high-quality infrared-aware visible fusion detection, which can be applied to smoke and wildfire detection. Furthermore, experiments on the M3FD dataset validate the superiority of the proposed method, with IA-VFDnet achieving the best detection performance than other state-of-the-art methods under conventional registered conditions. In addition, the first unregistered multimodal smoke and wildfire detection benchmark is openly available in this letter.