 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Enhancement of the Prefiltered Rotationally Invariant Non-local PCA Algorithm for MRI
Aug 27, 2023
Magnetic resonance imaging (MRI) is a non-invasive medical imaging technique offering high-resolution 3D images and valuable insights into human tissue conditions. Even at present, the refinement of denoising methods for MRI remains a crucial concern for improving the quality of the images. This study aims to enhance the prefiltered rotationally invariant non-local principal component analysis (PRI-NL-PCA) algorithm. This paper relaxed the original restriction, using the particle swarm optimization and traversal method to determine the optimal parameters of the algorithm. This paper also combined the component filters of the original algorithm and picked the most suitable combination as the new collaborative algorithm. It was found that the original algorithm has already achieved the best possible outcome, apart from a few threshold parameters that need to be adjusted. The effective way to further enhance the performance is to attach only one NL-PCA filter before and after the pre-filtered rotationally invariant non-local mean (PRI-NLM) filter. Although the performance of the new collaborative algorithm is still a little short of advanced deep learning methods, it shows that the algorithm based on PCA denoising is indeed feasible. It requires only a few parameters to be adjusted, and it is conceivable that they can be determined directly from the image, granting it a strong general capacity for various body parts, and it merits further exploration. An auxiliary tool was also extracted from the new algorithm, encouraging further combination of it with other state-of-the-art methods to further improve their denoising performance.
Robust Single-view Cone-beam X-ray Pose Estimation with Neural Tuned Tomography (NeTT) and Masked Neural Radiance Fields (mNeRF)
Aug 18, 2023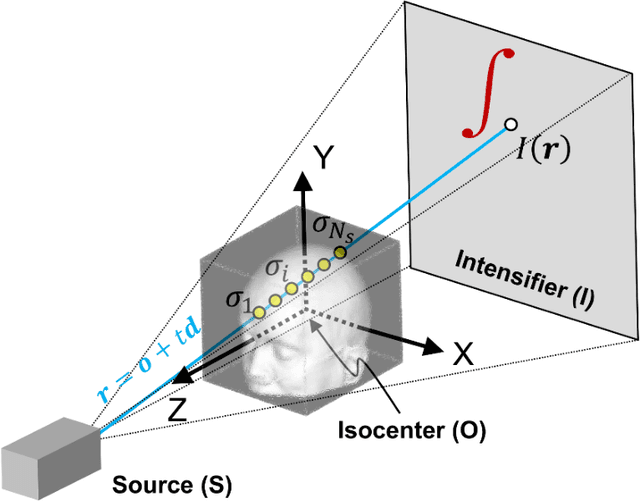

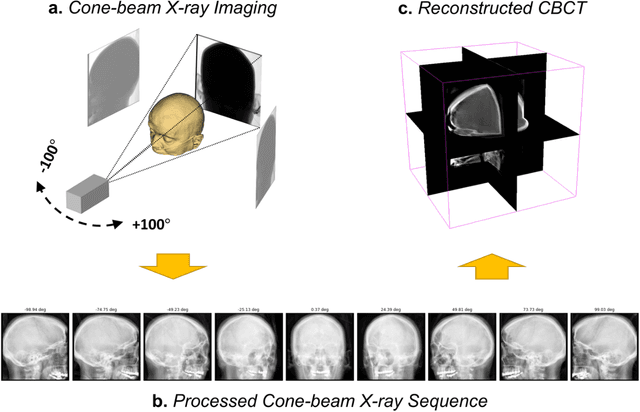

Many tasks performed in image-guided, mini-invasive, medical procedures can be cast as pose estimation problems, where an X-ray projection is utilized to reach a target in 3D space. Expanding on recent advances in the differentiable rendering of optically reflective materials, we introduce new methods for pose estimation of radiolucent objects using X-ray projections, and we demonstrate the critical role of optimal view synthesis in performing this task. We first develop an algorithm (DiffDRR) that efficiently computes Digitally Reconstructed Radiographs (DRRs) and leverages automatic differentiation within TensorFlow. Pose estimation is performed by iterative gradient descent using a loss function that quantifies the similarity of the DRR synthesized from a randomly initialized pose and the true fluoroscopic image at the target pose. We propose two novel methods for high-fidelity view synthesis, Neural Tuned Tomography (NeTT) and masked Neural Radiance Fields (mNeRF). Both methods rely on classic Cone-Beam Computerized Tomography (CBCT); NeTT directly optimizes the CBCT densities, while the non-zero values of mNeRF are constrained by a 3D mask of the anatomic region segmented from CBCT. We demonstrate that both NeTT and mNeRF distinctly improve pose estimation within our framework. By defining a successful pose estimate to be a 3D angle error of less than 3 deg, we find that NeTT and mNeRF can achieve similar results, both with overall success rates more than 93%. However, the computational cost of NeTT is significantly lower than mNeRF in both training and pose estimation. Furthermore, we show that a NeTT trained for a single subject can generalize to synthesize high-fidelity DRRs and ensure robust pose estimations for all other subjects. Therefore, we suggest that NeTT is an attractive option for robust pose estimation using fluoroscopic projections.
HIDFlowNet: A Flow-Based Deep Network for Hyperspectral Image Denoising
Jun 20, 2023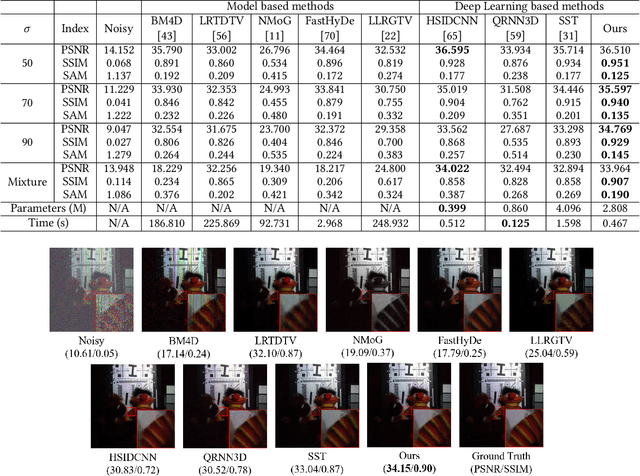
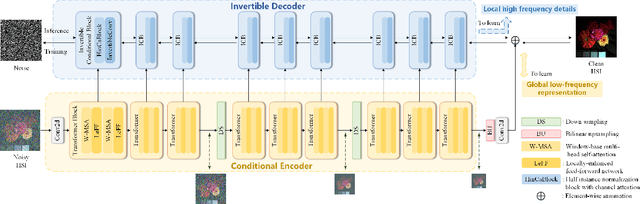
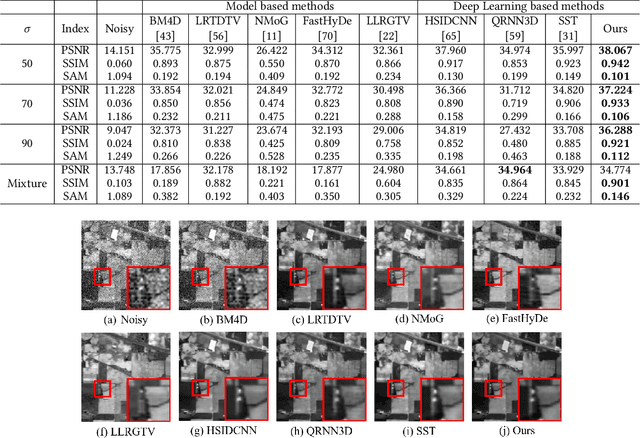
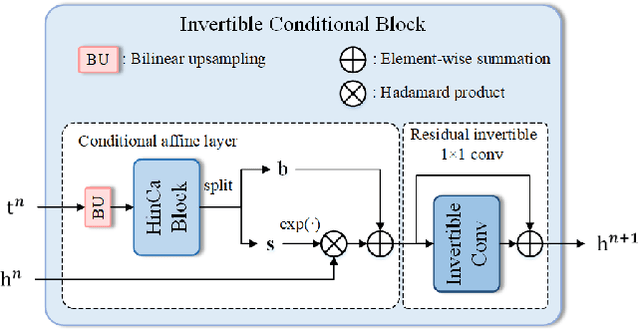
Hyperspectral image (HSI) denoising is essentially ill-posed since a noisy HSI can be degraded from multiple clean HSIs. However, current deep learning-based approaches ignore this fact and restore the clean image with deterministic mapping (i.e., the network receives a noisy HSI and outputs a clean HSI). To alleviate this issue, this paper proposes a flow-based HSI denoising network (HIDFlowNet) to directly learn the conditional distribution of the clean HSI given the noisy HSI and thus diverse clean HSIs can be sampled from the conditional distribution. Overall, our HIDFlowNet is induced from the flow methodology and contains an invertible decoder and a conditional encoder, which can fully decouple the learning of low-frequency and high-frequency information of HSI. Specifically, the invertible decoder is built by staking a succession of invertible conditional blocks (ICBs) to capture the local high-frequency details since the invertible network is information-lossless. The conditional encoder utilizes down-sampling operations to obtain low-resolution images and uses transformers to capture correlations over a long distance so that global low-frequency information can be effectively extracted. Extensive experimental results on simulated and real HSI datasets verify the superiority of our proposed HIDFlowNet compared with other state-of-the-art methods both quantitatively and visually.
Comparative Evaluation of Recent Universal Adversarial Perturbations in Image Classification
Jun 20, 2023The vulnerability of Convolutional Neural Networks (CNNs) to adversarial samples has recently garnered significant attention in the machine learning community. Furthermore, recent studies have unveiled the existence of universal adversarial perturbations (UAPs) that are image-agnostic and highly transferable across different CNN models. In this survey, our primary focus revolves around the recent advancements in UAPs specifically within the image classification task. We categorize UAPs into two distinct categories, i.e., noise-based attacks and generator-based attacks, thereby providing a comprehensive overview of representative methods within each category. By presenting the computational details of these methods, we summarize various loss functions employed for learning UAPs. Furthermore, we conduct a comprehensive evaluation of different loss functions within consistent training frameworks, including noise-based and generator-based. The evaluation covers a wide range of attack settings, including black-box and white-box attacks, targeted and untargeted attacks, as well as the examination of defense mechanisms. Our quantitative evaluation results yield several important findings pertaining to the effectiveness of different loss functions, the selection of surrogate CNN models, the impact of training data and data size, and the training frameworks involved in crafting universal attackers. Finally, to further promote future research on universal adversarial attacks, we provide some visualizations of the perturbations and discuss the potential research directions.
Deep learning techniques for blind image super-resolution: A high-scale multi-domain perspective evaluation
Jun 15, 2023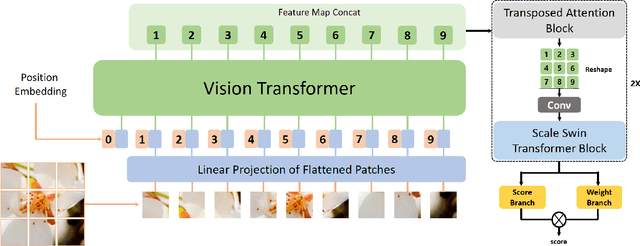
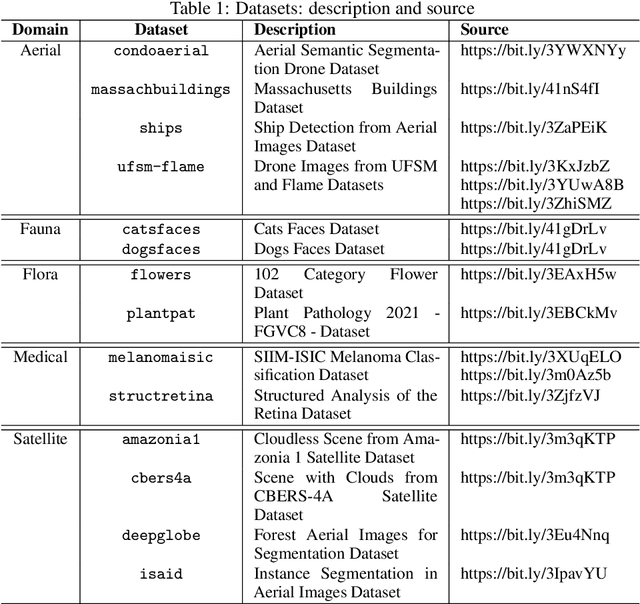
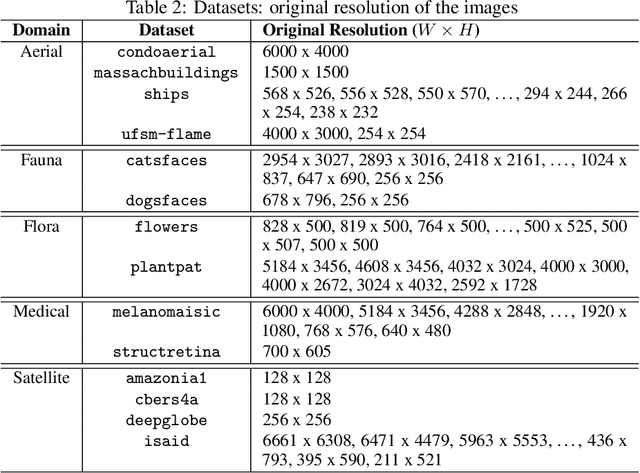

Despite several solutions and experiments have been conducted recently addressing image super-resolution (SR), boosted by deep learning (DL) techniques, they do not usually design evaluations with high scaling factors, capping it at 2x or 4x. Moreover, the datasets are generally benchmarks which do not truly encompass significant diversity of domains to proper evaluate the techniques. It is also interesting to remark that blind SR is attractive for real-world scenarios since it is based on the idea that the degradation process is unknown, and hence techniques in this context rely basically on low-resolution (LR) images. In this article, we present a high-scale (8x) controlled experiment which evaluates five recent DL techniques tailored for blind image SR: Adaptive Pseudo Augmentation (APA), Blind Image SR with Spatially Variant Degradations (BlindSR), Deep Alternating Network (DAN), FastGAN, and Mixture of Experts Super-Resolution (MoESR). We consider 14 small datasets from five different broader domains which are: aerial, fauna, flora, medical, and satellite. Another distinctive characteristic of our evaluation is that some of the DL approaches were designed for single-image SR but others not. Two no-reference metrics were selected, being the classical natural image quality evaluator (NIQE) and the recent transformer-based multi-dimension attention network for no-reference image quality assessment (MANIQA) score, to assess the techniques. Overall, MoESR can be regarded as the best solution although the perceptual quality of the created HR images of all the techniques still needs to improve. Supporting code: https://github.com/vsantjr/DL_BlindSR. Datasets: https://www.kaggle.com/datasets/valdivinosantiago/dl-blindsr-datasets.
Generative Machine Listener
Aug 18, 2023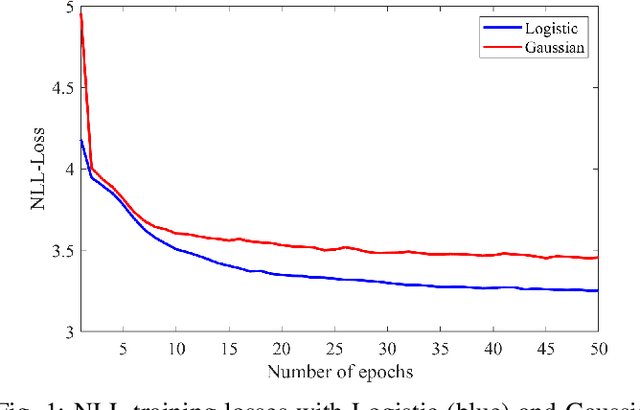
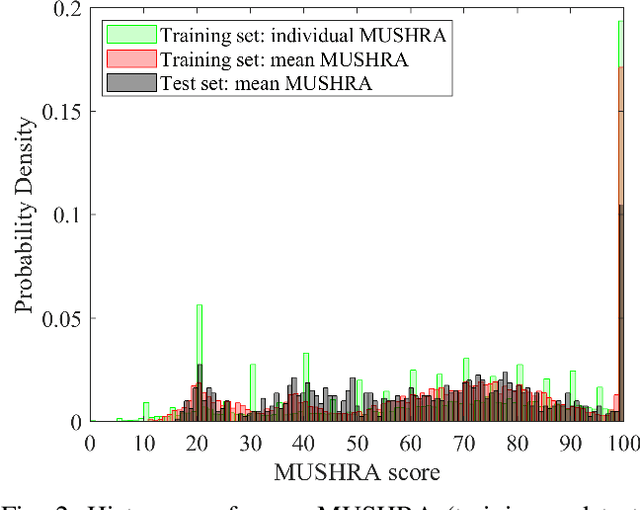
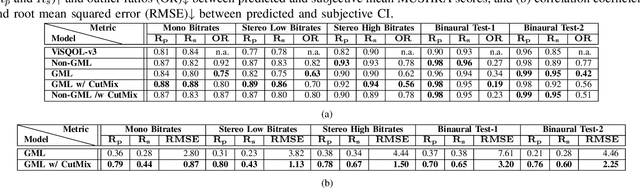
We show how a neural network can be trained on individual intrusive listening test scores to predict a distribution of scores for each pair of reference and coded input stereo or binaural signals. We nickname this method the Generative Machine Listener (GML), as it is capable of generating an arbitrary amount of simulated listening test data. Compared to a baseline system using regression over mean scores, we observe lower outlier ratios (OR) for the mean score predictions, and obtain easy access to the prediction of confidence intervals (CI). The introduction of data augmentation techniques from the image domain results in a significant increase in CI prediction accuracy as well as Pearson and Spearman rank correlation of mean scores.
Brain MRI Segmentation using Template-Based Training and Visual Perception Augmentation
Aug 04, 2023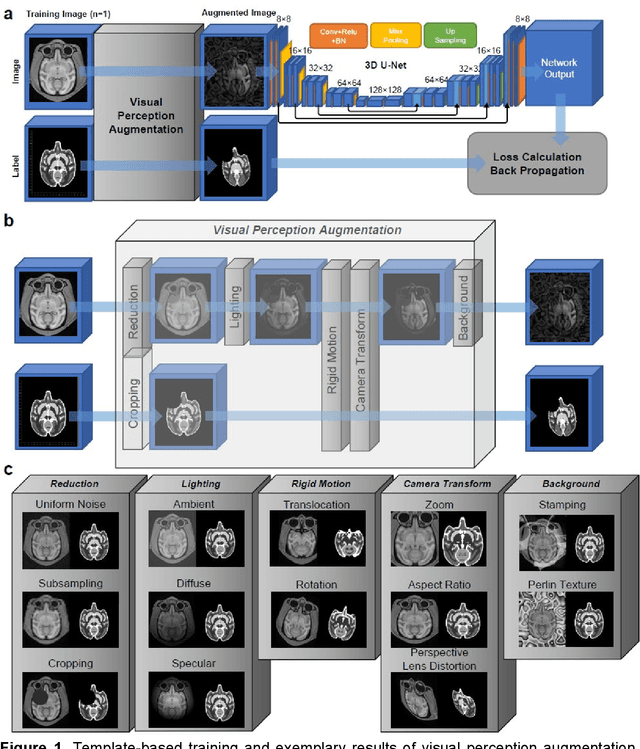
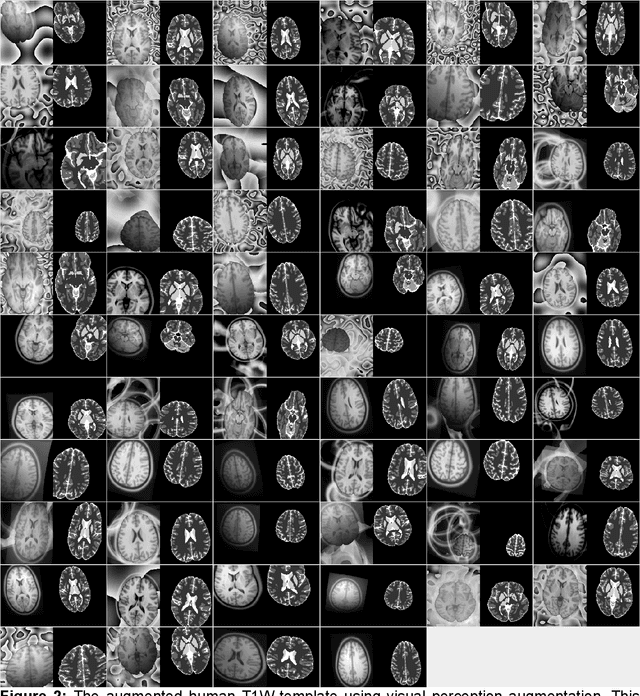
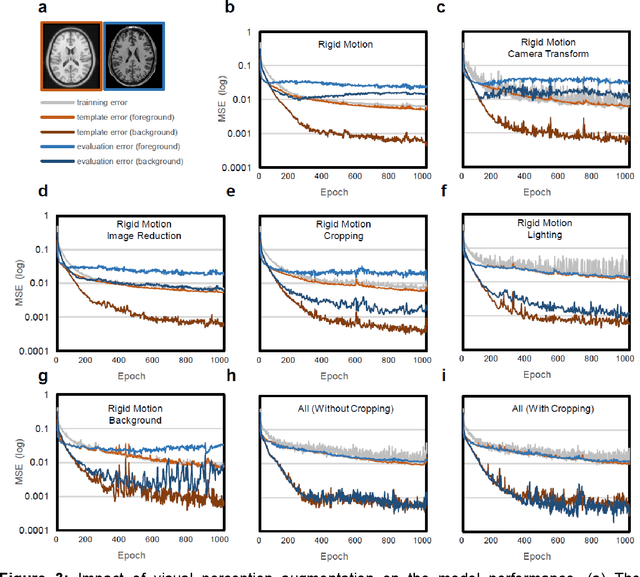
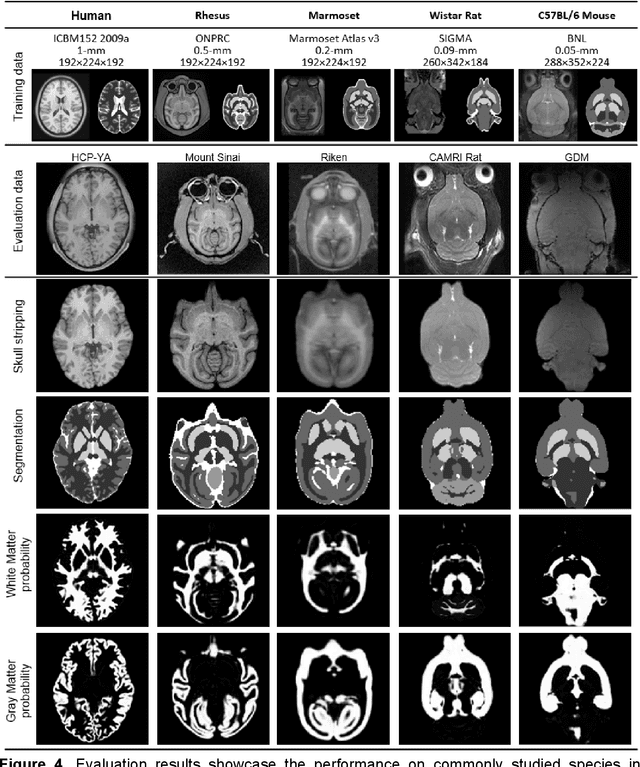
Deep learning models usually require sufficient training data to achieve high accuracy, but obtaining labeled data can be time-consuming and labor-intensive. Here we introduce a template-based training method to train a 3D U-Net model from scratch using only one population-averaged brain MRI template and its associated segmentation label. The process incorporated visual perception augmentation to enhance the model's robustness in handling diverse image inputs and mitigating overfitting. Leveraging this approach, we trained 3D U-Net models for mouse, rat, marmoset, rhesus, and human brain MRI to achieve segmentation tasks such as skull-stripping, brain segmentation, and tissue probability mapping. This tool effectively addresses the limited availability of training data and holds significant potential for expanding deep learning applications in image analysis, providing researchers with a unified solution to train deep neural networks with only one image sample.
Reconstruction Distortion of Learned Image Compression with Imperceptible Perturbations
Jun 01, 2023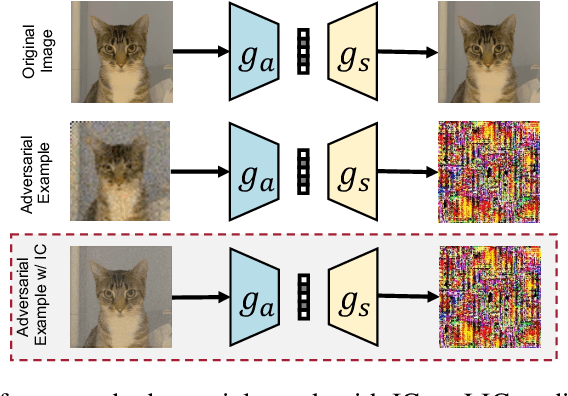
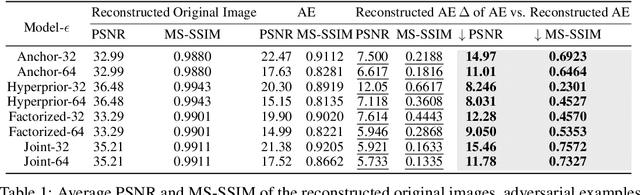

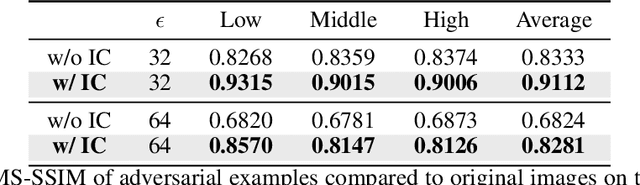
Learned Image Compression (LIC) has recently become the trending technique for image transmission due to its notable performance. Despite its popularity, the robustness of LIC with respect to the quality of image reconstruction remains under-explored. In this paper, we introduce an imperceptible attack approach designed to effectively degrade the reconstruction quality of LIC, resulting in the reconstructed image being severely disrupted by noise where any object in the reconstructed images is virtually impossible. More specifically, we generate adversarial examples by introducing a Frobenius norm-based loss function to maximize the discrepancy between original images and reconstructed adversarial examples. Further, leveraging the insensitivity of high-frequency components to human vision, we introduce Imperceptibility Constraint (IC) to ensure that the perturbations remain inconspicuous. Experiments conducted on the Kodak dataset using various LIC models demonstrate effectiveness. In addition, we provide several findings and suggestions for designing future defenses.
InFusion: Inject and Attention Fusion for Multi Concept Zero Shot Text based Video Editing
Aug 02, 2023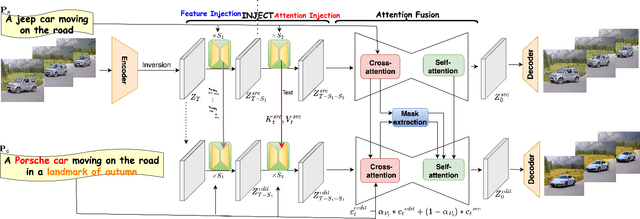
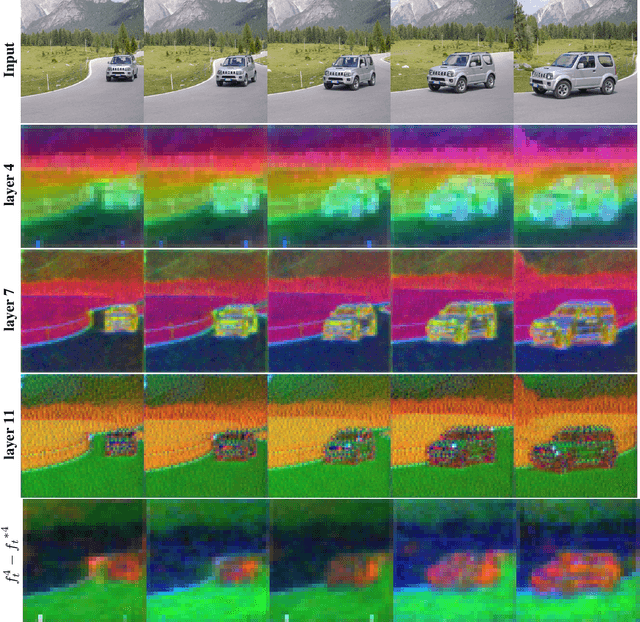
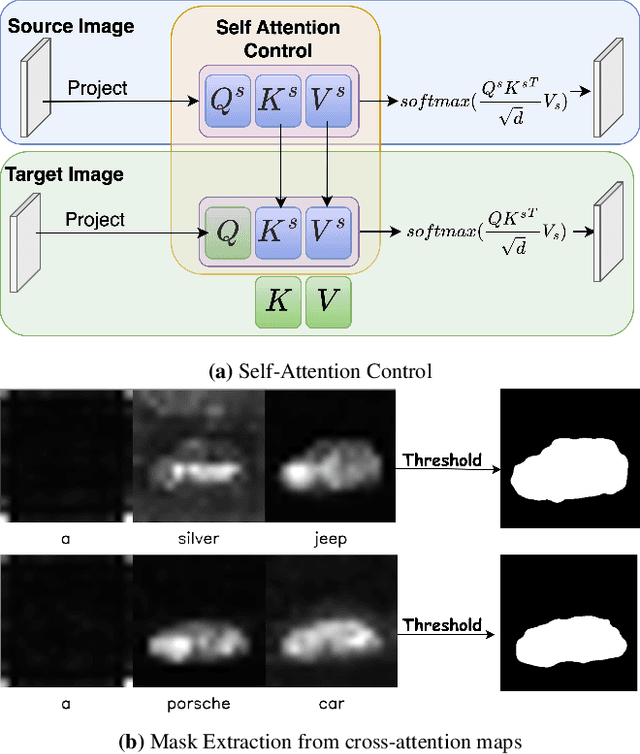
Large text-to-image diffusion models have achieved remarkable success in generating diverse high-quality images in alignment with text prompt used for editing the input image. But, when these models applied to video the main challenge is to ensure temporal consistency and coherence across frames. In this paper, we proposed InFusion, a framework for zero-shot text-based video editing leveraging large pre-trained image diffusion models. Our framework specifically supports editing of multiple concepts with the pixel level control over diverse concepts mentioned in the editing prompt. Specifically, we inject the difference of features obtained with source and edit prompt from U-Net residual blocks in decoder layers, this when combined with injected attention features make it feasible to query the source contents and scale edited concepts along with the injection of unedited parts. The editing is further controlled in fine-grained manner with mask extraction and attention fusion strategy which cuts the edited part from source and paste it into the denoising pipeline for editing prompt. Our framework is a low cost alternative of one-shot tuned models for editing since it does not require training. We demonstrated the complex concept editing with generalised image model (Stable Diffusion v1.5) using LoRA. Adaptation is compatible with all the existing image diffusion techniques. Extensive experimental results demonstrate the effectiveness over existing methods in rendering high-quality and temporally consistent videos.
DM-VTON: Distilled Mobile Real-time Virtual Try-On
Aug 26, 2023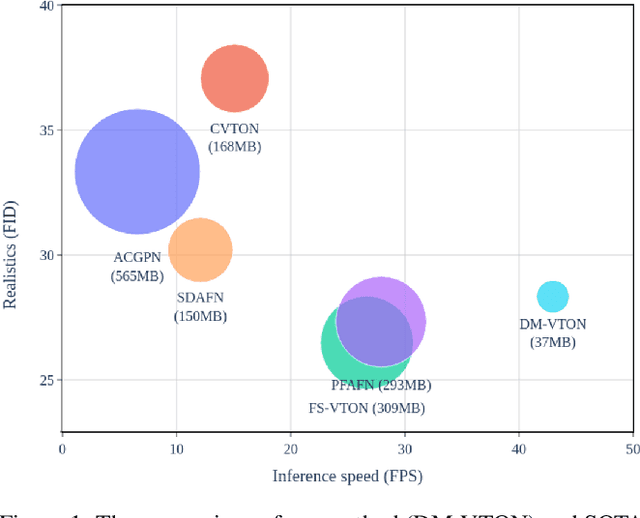

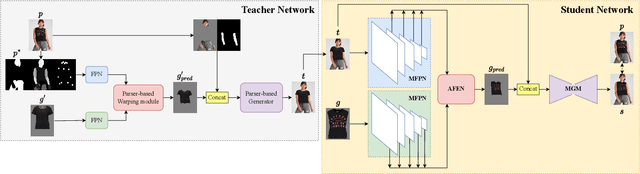
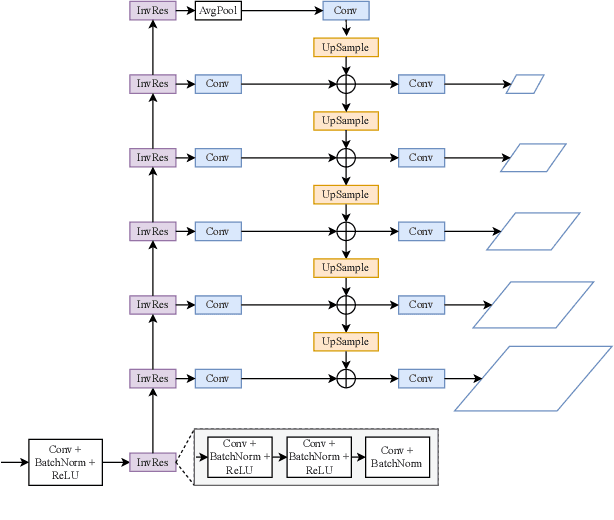
The fashion e-commerce industry has witnessed significant growth in recent years, prompting exploring image-based virtual try-on techniques to incorporate Augmented Reality (AR) experiences into online shopping platforms. However, existing research has primarily overlooked a crucial aspect - the runtime of the underlying machine-learning model. While existing methods prioritize enhancing output quality, they often disregard the execution time, which restricts their applications on a limited range of devices. To address this gap, we propose Distilled Mobile Real-time Virtual Try-On (DM-VTON), a novel virtual try-on framework designed to achieve simplicity and efficiency. Our approach is based on a knowledge distillation scheme that leverages a strong Teacher network as supervision to guide a Student network without relying on human parsing. Notably, we introduce an efficient Mobile Generative Module within the Student network, significantly reducing the runtime while ensuring high-quality output. Additionally, we propose Virtual Try-on-guided Pose for Data Synthesis to address the limited pose variation observed in training images. Experimental results show that the proposed method can achieve 40 frames per second on a single Nvidia Tesla T4 GPU and only take up 37 MB of memory while producing almost the same output quality as other state-of-the-art methods. DM-VTON stands poised to facilitate the advancement of real-time AR applications, in addition to the generation of lifelike attired human figures tailored for diverse specialized training tasks. https://sites.google.com/view/ltnghia/research/DMVTON