 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Temporal-Distributed Backdoor Attack Against Video Based Action Recognition
Sep 01, 2023
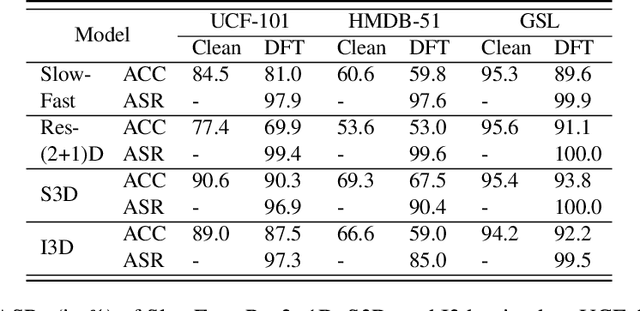

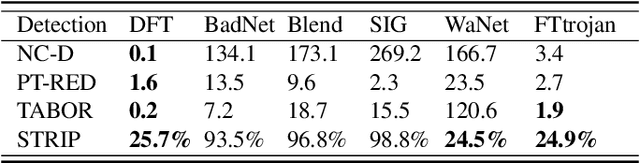
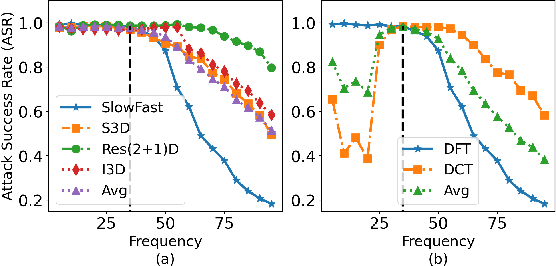
Deep neural networks (DNNs) have achieved tremendous success in various applications including video action recognition, yet remain vulnerable to backdoor attacks (Trojans). The backdoor-compromised model will mis-classify to the target class chosen by the attacker when a test instance (from a non-target class) is embedded with a specific trigger, while maintaining high accuracy on attack-free instances. Although there are extensive studies on backdoor attacks against image data, the susceptibility of video-based systems under backdoor attacks remains largely unexplored. Current studies are direct extensions of approaches proposed for image data, e.g., the triggers are independently embedded within the frames, which tend to be detectable by existing defenses. In this paper, we introduce a simple yet effective backdoor attack against video data. Our proposed attack, adding perturbations in a transformed domain, plants an imperceptible, temporally distributed trigger across the video frames, and is shown to be resilient to existing defensive strategies. The effectiveness of the proposed attack is demonstrated by extensive experiments with various well-known models on two video recognition benchmarks, UCF101 and HMDB51, and a sign language recognition benchmark, Greek Sign Language (GSL) dataset. We delve into the impact of several influential factors on our proposed attack and identify an intriguing effect termed "collateral damage" through extensive studies.
Divide, Evaluate, and Refine: Evaluating and Improving Text-to-Image Alignment with Iterative VQA Feedback
Jul 10, 2023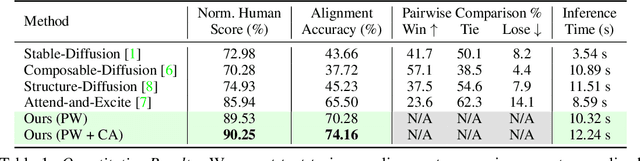


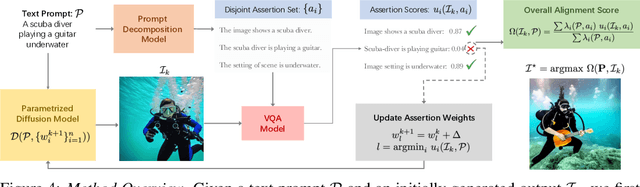
The field of text-conditioned image generation has made unparalleled progress with the recent advent of latent diffusion models. While remarkable, as the complexity of given text input increases, the state-of-the-art diffusion models may still fail in generating images which accurately convey the semantics of the given prompt. Furthermore, it has been observed that such misalignments are often left undetected by pretrained multi-modal models such as CLIP. To address these problems, in this paper we explore a simple yet effective decompositional approach towards both evaluation and improvement of text-to-image alignment. In particular, we first introduce a Decompositional-Alignment-Score which given a complex prompt decomposes it into a set of disjoint assertions. The alignment of each assertion with generated images is then measured using a VQA model. Finally, alignment scores for different assertions are combined aposteriori to give the final text-to-image alignment score. Experimental analysis reveals that the proposed alignment metric shows significantly higher correlation with human ratings as opposed to traditional CLIP, BLIP scores. Furthermore, we also find that the assertion level alignment scores provide a useful feedback which can then be used in a simple iterative procedure to gradually increase the expression of different assertions in the final image outputs. Human user studies indicate that the proposed approach surpasses previous state-of-the-art by 8.7% in overall text-to-image alignment accuracy. Project page for our paper is available at https://1jsingh.github.io/divide-evaluate-and-refine
LInKs "Lifting Independent Keypoints" -- Partial Pose Lifting for Occlusion Handling with Improved Accuracy in 2D-3D Human Pose Estimation
Sep 13, 2023We present LInKs, a novel unsupervised learning method to recover 3D human poses from 2D kinematic skeletons obtained from a single image, even when occlusions are present. Our approach follows a unique two-step process, which involves first lifting the occluded 2D pose to the 3D domain, followed by filling in the occluded parts using the partially reconstructed 3D coordinates. This lift-then-fill approach leads to significantly more accurate results compared to models that complete the pose in 2D space alone. Additionally, we improve the stability and likelihood estimation of normalising flows through a custom sampling function replacing PCA dimensionality reduction previously used in prior work. Furthermore, we are the first to investigate if different parts of the 2D kinematic skeleton can be lifted independently which we find by itself reduces the error of current lifting approaches. We attribute this to the reduction of long-range keypoint correlations. In our detailed evaluation, we quantify the error under various realistic occlusion scenarios, showcasing the versatility and applicability of our model. Our results consistently demonstrate the superiority of handling all types of occlusions in 3D space when compared to others that complete the pose in 2D space. Our approach also exhibits consistent accuracy in scenarios without occlusion, as evidenced by a 7.9% reduction in reconstruction error compared to prior works on the Human3.6M dataset. Furthermore, our method excels in accurately retrieving complete 3D poses even in the presence of occlusions, making it highly applicable in situations where complete 2D pose information is unavailable.
Integrating GAN and Texture Synthesis for Enhanced Road Damage Detection
Sep 13, 2023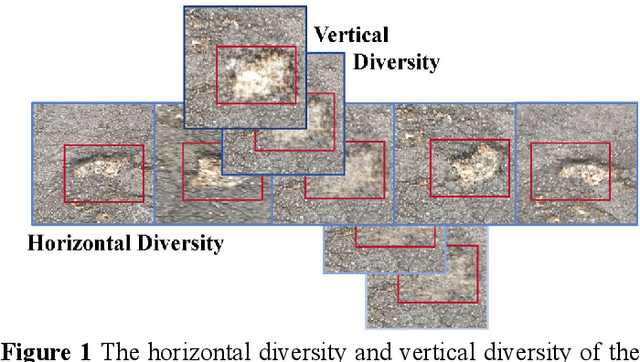

In the domain of traffic safety and road maintenance, precise detection of road damage is crucial for ensuring safe driving and prolonging road durability. However, current methods often fall short due to limited data. Prior attempts have used Generative Adversarial Networks to generate damage with diverse shapes and manually integrate it into appropriate positions. However, the problem has not been well explored and is faced with two challenges. First, they only enrich the location and shape of damage while neglect the diversity of severity levels, and the realism still needs further improvement. Second, they require a significant amount of manual effort. To address these challenges, we propose an innovative approach. In addition to using GAN to generate damage with various shapes, we further employ texture synthesis techniques to extract road textures. These two elements are then mixed with different weights, allowing us to control the severity of the synthesized damage, which are then embedded back into the original images via Poisson blending. Our method ensures both richness of damage severity and a better alignment with the background. To save labor costs, we leverage structural similarity for automated sample selection during embedding. Each augmented data of an original image contains versions with varying severity levels. We implement a straightforward screening strategy to mitigate distribution drift. Experiments are conducted on a public road damage dataset. The proposed method not only eliminates the need for manual labor but also achieves remarkable enhancements, improving the mAP by 4.1% and the F1-score by 4.5%.
GelFlow: Self-supervised Learning of Optical Flow for Vision-Based Tactile Sensor Displacement Measurement
Sep 13, 2023High-resolution multi-modality information acquired by vision-based tactile sensors can support more dexterous manipulations for robot fingers. Optical flow is low-level information directly obtained by vision-based tactile sensors, which can be transformed into other modalities like force, geometry and depth. Current vision-tactile sensors employ optical flow methods from OpenCV to estimate the deformation of markers in gels. However, these methods need to be more precise for accurately measuring the displacement of markers during large elastic deformation of the gel, as this can significantly impact the accuracy of downstream tasks. This study proposes a self-supervised optical flow method based on deep learning to achieve high accuracy in displacement measurement for vision-based tactile sensors. The proposed method employs a coarse-to-fine strategy to handle large deformations by constructing a multi-scale feature pyramid from the input image. To better deal with the elastic deformation caused by the gel, the Helmholtz velocity decomposition constraint combined with the elastic deformation constraint are adopted to address the distortion rate and area change rate, respectively. A local flow fusion module is designed to smooth the optical flow, taking into account the prior knowledge of the blurred effect of gel deformation. We trained the proposed self-supervised network using an open-source dataset and compared it with traditional and deep learning-based optical flow methods. The results show that the proposed method achieved the highest displacement measurement accuracy, thereby demonstrating its potential for enabling more precise measurement of downstream tasks using vision-based tactile sensors.
Optimization of Image Acquisition for Earth Observation Satellites via Quantum Computing
Jul 26, 2023Satellite image acquisition scheduling is a problem that is omnipresent in the earth observation field; its goal is to find the optimal subset of images to be taken during a given orbit pass under a set of constraints. This problem, which can be modeled via combinatorial optimization, has been dealt with many times by the artificial intelligence and operations research communities. However, despite its inherent interest, it has been scarcely studied through the quantum computing paradigm. Taking this situation as motivation, we present in this paper two QUBO formulations for the problem, using different approaches to handle the non-trivial constraints. We compare the formulations experimentally over 20 problem instances using three quantum annealers currently available from D-Wave, as well as one of its hybrid solvers. Fourteen of the tested instances have been obtained from the well-known SPOT5 benchmark, while the remaining six have been generated ad-hoc for this study. Our results show that the formulation and the ancilla handling technique is crucial to solve the problem successfully. Finally, we also provide practical guidelines on the size limits of problem instances that can be realistically solved on current quantum computers.
Multimodal Contrastive Learning and Tabular Attention for Automated Alzheimer's Disease Prediction
Aug 29, 2023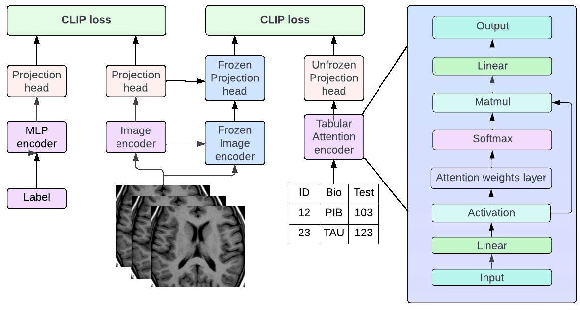
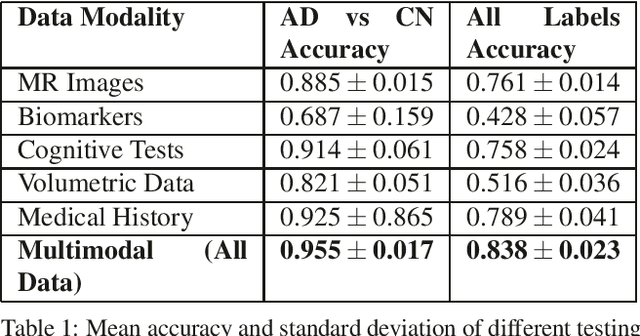
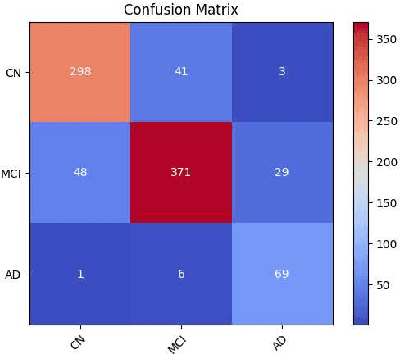

Alongside neuroimaging such as MRI scans and PET, Alzheimer's disease (AD) datasets contain valuable tabular data including AD biomarkers and clinical assessments. Existing computer vision approaches struggle to utilize this additional information. To address these needs, we propose a generalizable framework for multimodal contrastive learning of image data and tabular data, a novel tabular attention module for amplifying and ranking salient features in tables, and the application of these techniques onto Alzheimer's disease prediction. Experimental evaulations demonstrate the strength of our framework by detecting Alzheimer's disease (AD) from over 882 MR image slices from the ADNI database. We take advantage of the high interpretability of tabular data and our novel tabular attention approach and through attribution of the attention scores for each row of the table, we note and rank the most predominant features. Results show that the model is capable of an accuracy of over 83.8%, almost a 10% increase from previous state of the art.
DHC: Dual-debiased Heterogeneous Co-training Framework for Class-imbalanced Semi-supervised Medical Image Segmentation
Jul 22, 2023The volume-wise labeling of 3D medical images is expertise-demanded and time-consuming; hence semi-supervised learning (SSL) is highly desirable for training with limited labeled data. Imbalanced class distribution is a severe problem that bottlenecks the real-world application of these methods but was not addressed much. Aiming to solve this issue, we present a novel Dual-debiased Heterogeneous Co-training (DHC) framework for semi-supervised 3D medical image segmentation. Specifically, we propose two loss weighting strategies, namely Distribution-aware Debiased Weighting (DistDW) and Difficulty-aware Debiased Weighting (DiffDW), which leverage the pseudo labels dynamically to guide the model to solve data and learning biases. The framework improves significantly by co-training these two diverse and accurate sub-models. We also introduce more representative benchmarks for class-imbalanced semi-supervised medical image segmentation, which can fully demonstrate the efficacy of the class-imbalance designs. Experiments show that our proposed framework brings significant improvements by using pseudo labels for debiasing and alleviating the class imbalance problem. More importantly, our method outperforms the state-of-the-art SSL methods, demonstrating the potential of our framework for the more challenging SSL setting. Code and models are available at: https://github.com/xmed-lab/DHC.
A Unified Framework for Discovering Discrete Symmetries
Sep 06, 2023We consider the problem of learning a function respecting a symmetry from among a class of symmetries. We develop a unified framework that enables symmetry discovery across a broad range of subgroups including locally symmetric, dihedral and cyclic subgroups. At the core of the framework is a novel architecture composed of linear and tensor-valued functions that expresses functions invariant to these subgroups in a principled manner. The structure of the architecture enables us to leverage multi-armed bandit algorithms and gradient descent to efficiently optimize over the linear and the tensor-valued functions, respectively, and to infer the symmetry that is ultimately learnt. We also discuss the necessity of the tensor-valued functions in the architecture. Experiments on image-digit sum and polynomial regression tasks demonstrate the effectiveness of our approach.
Joint Hierarchical Priors and Adaptive Spatial Resolution for Efficient Neural Image Compression
Jul 12, 2023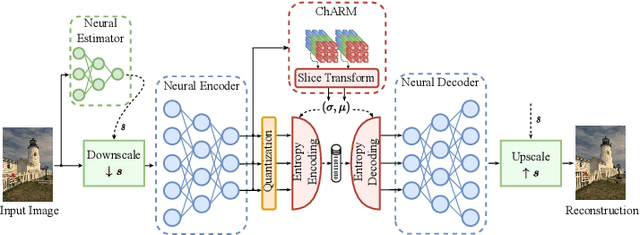
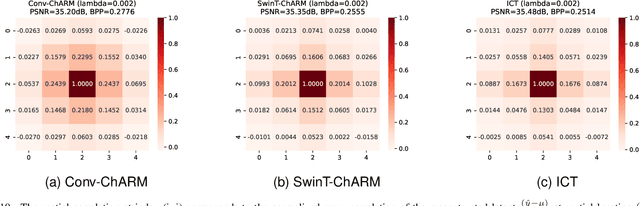

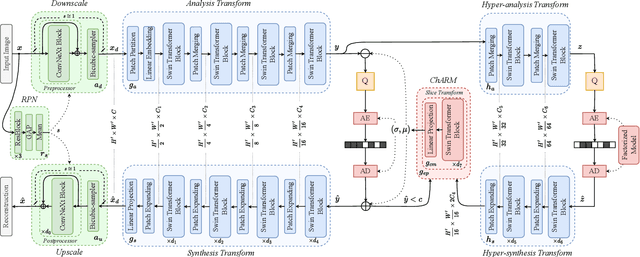
Recently, the performance of neural image compression (NIC) has steadily improved thanks to the last line of study, reaching or outperforming state-of-the-art conventional codecs. Despite significant progress, current NIC methods still rely on ConvNet-based entropy coding, limited in modeling long-range dependencies due to their local connectivity and the increasing number of architectural biases and priors, resulting in complex underperforming models with high decoding latency. Motivated by the efficiency investigation of the Tranformer-based transform coding framework, namely SwinT-ChARM, we propose to enhance the latter, as first, with a more straightforward yet effective Tranformer-based channel-wise auto-regressive prior model, resulting in an absolute image compression transformer (ICT). Through the proposed ICT, we can capture both global and local contexts from the latent representations and better parameterize the distribution of the quantized latents. Further, we leverage a learnable scaling module with a sandwich ConvNeXt-based pre-/post-processor to accurately extract more compact latent codes while reconstructing higher-quality images. Extensive experimental results on benchmark datasets showed that the proposed framework significantly improves the trade-off between coding efficiency and decoder complexity over the versatile video coding (VVC) reference encoder (VTM-18.0) and the neural codec SwinT-ChARM. Moreover, we provide model scaling studies to verify the computational efficiency of our approach and conduct several objective and subjective analyses to bring to the fore the performance gap between the adaptive image compression transformer (AICT) and the neural codec SwinT-ChARM.