 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Understanding Pose and Appearance Disentanglement in 3D Human Pose Estimation
Sep 20, 2023
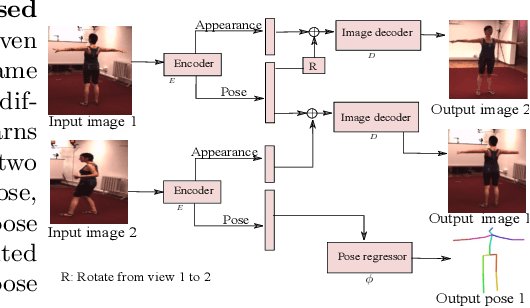
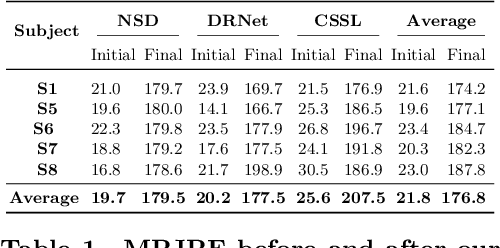


As 3D human pose estimation can now be achieved with very high accuracy in the supervised learning scenario, tackling the case where 3D pose annotations are not available has received increasing attention. In particular, several methods have proposed to learn image representations in a self-supervised fashion so as to disentangle the appearance information from the pose one. The methods then only need a small amount of supervised data to train a pose regressor using the pose-related latent vector as input, as it should be free of appearance information. In this paper, we carry out in-depth analysis to understand to what degree the state-of-the-art disentangled representation learning methods truly separate the appearance information from the pose one. First, we study disentanglement from the perspective of the self-supervised network, via diverse image synthesis experiments. Second, we investigate disentanglement with respect to the 3D pose regressor following an adversarial attack perspective. Specifically, we design an adversarial strategy focusing on generating natural appearance changes of the subject, and against which we could expect a disentangled network to be robust. Altogether, our analyses show that disentanglement in the three state-of-the-art disentangled representation learning frameworks if far from complete, and that their pose codes contain significant appearance information. We believe that our approach provides a valuable testbed to evaluate the degree of disentanglement of pose from appearance in self-supervised 3D human pose estimation.
How to turn your camera into a perfect pinhole model
Sep 20, 2023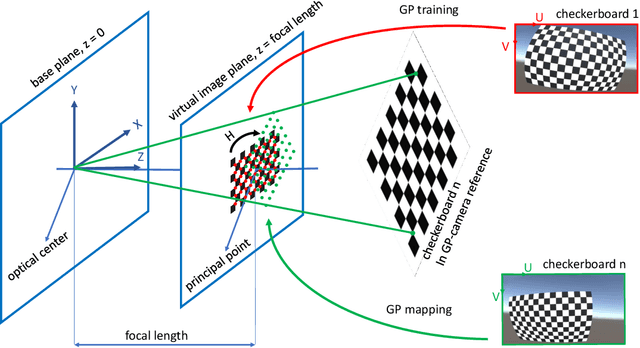
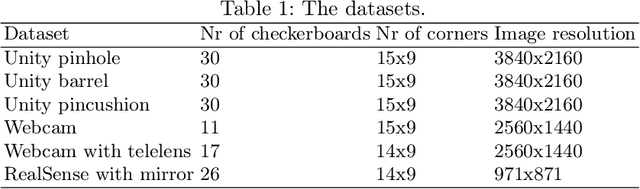

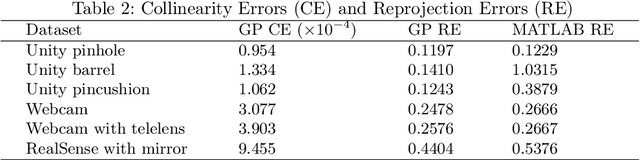
Camera calibration is a first and fundamental step in various computer vision applications. Despite being an active field of research, Zhang's method remains widely used for camera calibration due to its implementation in popular toolboxes. However, this method initially assumes a pinhole model with oversimplified distortion models. In this work, we propose a novel approach that involves a pre-processing step to remove distortions from images by means of Gaussian processes. Our method does not need to assume any distortion model and can be applied to severely warped images, even in the case of multiple distortion sources, e.g., a fisheye image of a curved mirror reflection. The Gaussian processes capture all distortions and camera imperfections, resulting in virtual images as though taken by an ideal pinhole camera with square pixels. Furthermore, this ideal GP-camera only needs one image of a square grid calibration pattern. This model allows for a serious upgrade of many algorithms and applications that are designed in a pure projective geometry setting but with a performance that is very sensitive to nonlinear lens distortions. We demonstrate the effectiveness of our method by simplifying Zhang's calibration method, reducing the number of parameters and getting rid of the distortion parameters and iterative optimization. We validate by means of synthetic data and real world images. The contributions of this work include the construction of a virtual ideal pinhole camera using Gaussian processes, a simplified calibration method and lens distortion removal.
Evaluating the Reliability of CNN Models on Classifying Traffic and Road Signs using LIME
Sep 11, 2023
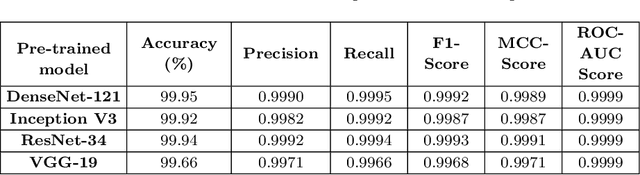
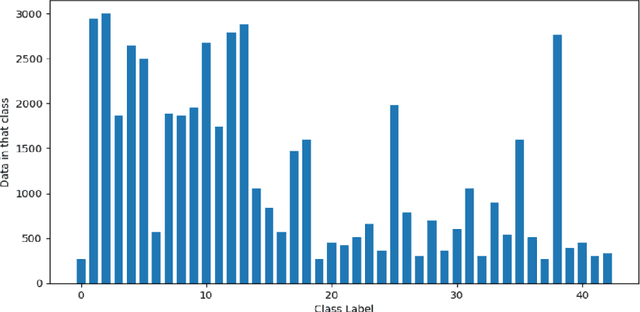
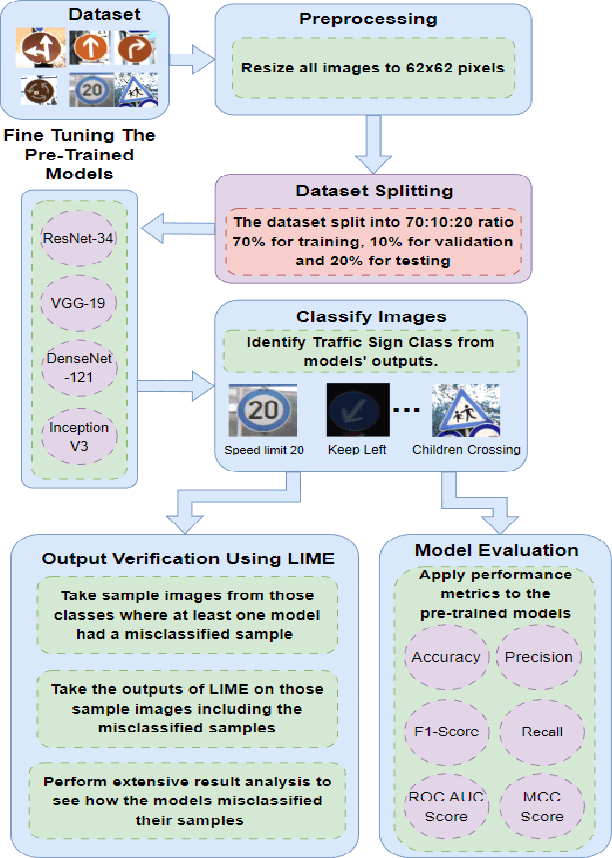
The objective of this investigation is to evaluate and contrast the effectiveness of four state-of-the-art pre-trained models, ResNet-34, VGG-19, DenseNet-121, and Inception V3, in classifying traffic and road signs with the utilization of the GTSRB public dataset. The study focuses on evaluating the accuracy of these models' predictions as well as their ability to employ appropriate features for image categorization. To gain insights into the strengths and limitations of the model's predictions, the study employs the local interpretable model-agnostic explanations (LIME) framework. The findings of this experiment indicate that LIME is a crucial tool for improving the interpretability and dependability of machine learning models for image identification, regardless of the models achieving an f1 score of 0.99 on classifying traffic and road signs. The conclusion of this study has important ramifications for how these models are used in practice, as it is crucial to ensure that model predictions are founded on the pertinent image features.
Unleashing the Power of Depth and Pose Estimation Neural Networks by Designing Compatible Endoscopic Images
Sep 14, 2023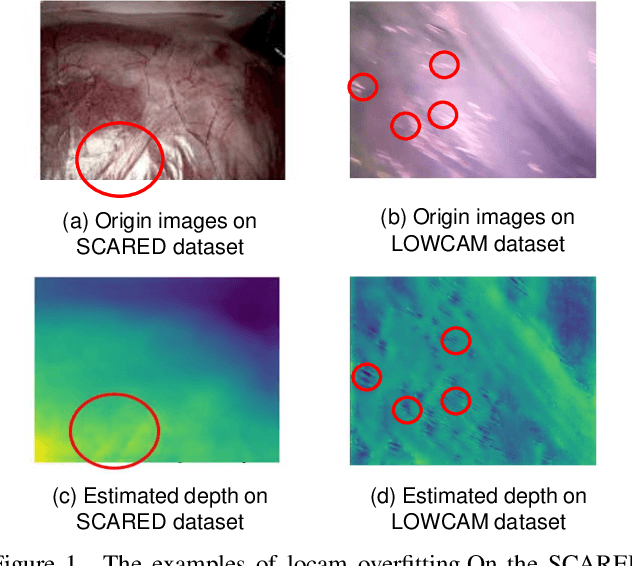
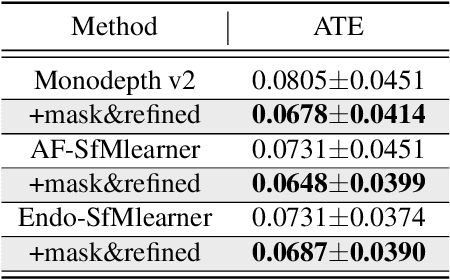
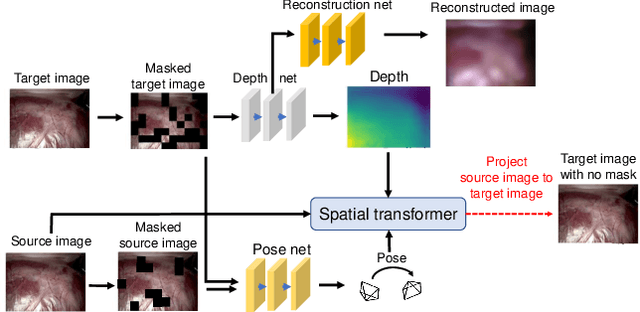
Deep learning models have witnessed depth and pose estimation framework on unannotated datasets as a effective pathway to succeed in endoscopic navigation. Most current techniques are dedicated to developing more advanced neural networks to improve the accuracy. However, existing methods ignore the special properties of endoscopic images, resulting in an inability to fully unleash the power of neural networks. In this study, we conduct a detail analysis of the properties of endoscopic images and improve the compatibility of images and neural networks, to unleash the power of current neural networks. First, we introcude the Mask Image Modelling (MIM) module, which inputs partial image information instead of complete image information, allowing the network to recover global information from partial pixel information. This enhances the network' s ability to perceive global information and alleviates the phenomenon of local overfitting in convolutional neural networks due to local artifacts. Second, we propose a lightweight neural network to enhance the endoscopic images, to explicitly improve the compatibility between images and neural networks. Extensive experiments are conducted on the three public datasets and one inhouse dataset, and the proposed modules improve baselines by a large margin. Furthermore, the enhanced images we proposed, which have higher network compatibility, can serve as an effective data augmentation method and they are able to extract more stable feature points in traditional feature point matching tasks and achieve outstanding performance.
Multi-scale Target-Aware Framework for Constrained Image Splicing Detection and Localization
Aug 18, 2023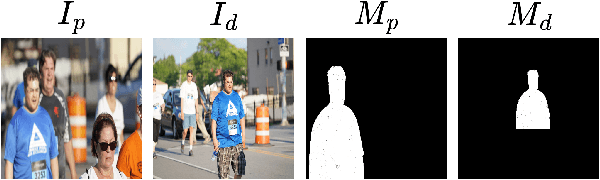
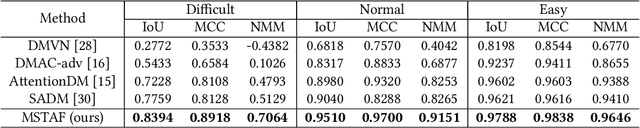
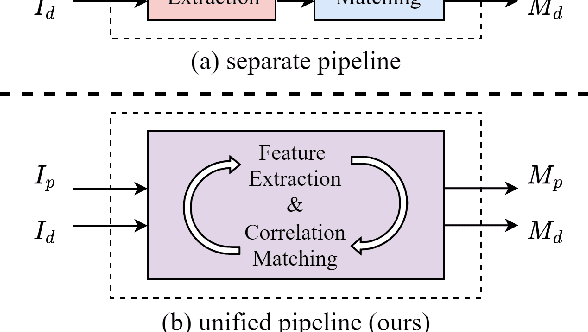
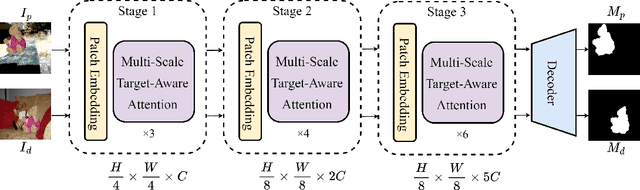
Constrained image splicing detection and localization (CISDL) is a fundamental task of multimedia forensics, which detects splicing operation between two suspected images and localizes the spliced region on both images. Recent works regard it as a deep matching problem and have made significant progress. However, existing frameworks typically perform feature extraction and correlation matching as separate processes, which may hinder the model's ability to learn discriminative features for matching and can be susceptible to interference from ambiguous background pixels. In this work, we propose a multi-scale target-aware framework to couple feature extraction and correlation matching in a unified pipeline. In contrast to previous methods, we design a target-aware attention mechanism that jointly learns features and performs correlation matching between the probe and donor images. Our approach can effectively promote the collaborative learning of related patches, and perform mutual promotion of feature learning and correlation matching. Additionally, in order to handle scale transformations, we introduce a multi-scale projection method, which can be readily integrated into our target-aware framework that enables the attention process to be conducted between tokens containing information of varying scales. Our experiments demonstrate that our model, which uses a unified pipeline, outperforms state-of-the-art methods on several benchmark datasets and is robust against scale transformations.
GAFlow: Incorporating Gaussian Attention into Optical Flow
Sep 28, 2023Optical flow, or the estimation of motion fields from image sequences, is one of the fundamental problems in computer vision. Unlike most pixel-wise tasks that aim at achieving consistent representations of the same category, optical flow raises extra demands for obtaining local discrimination and smoothness, which yet is not fully explored by existing approaches. In this paper, we push Gaussian Attention (GA) into the optical flow models to accentuate local properties during representation learning and enforce the motion affinity during matching. Specifically, we introduce a novel Gaussian-Constrained Layer (GCL) which can be easily plugged into existing Transformer blocks to highlight the local neighborhood that contains fine-grained structural information. Moreover, for reliable motion analysis, we provide a new Gaussian-Guided Attention Module (GGAM) which not only inherits properties from Gaussian distribution to instinctively revolve around the neighbor fields of each point but also is empowered to put the emphasis on contextually related regions during matching. Our fully-equipped model, namely Gaussian Attention Flow network (GAFlow), naturally incorporates a series of novel Gaussian-based modules into the conventional optical flow framework for reliable motion analysis. Extensive experiments on standard optical flow datasets consistently demonstrate the exceptional performance of the proposed approach in terms of both generalization ability evaluation and online benchmark testing. Code is available at https://github.com/LA30/GAFlow.
CLIP-Hand3D: Exploiting 3D Hand Pose Estimation via Context-Aware Prompting
Sep 28, 2023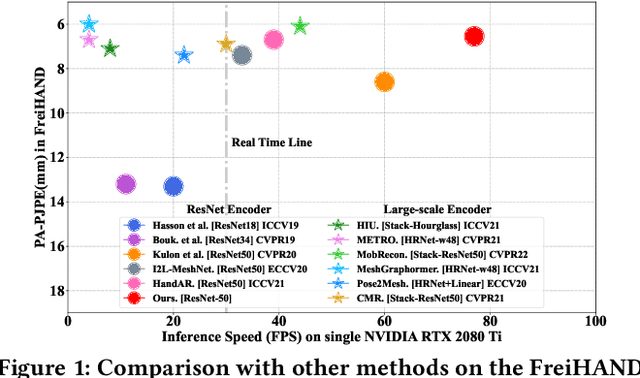
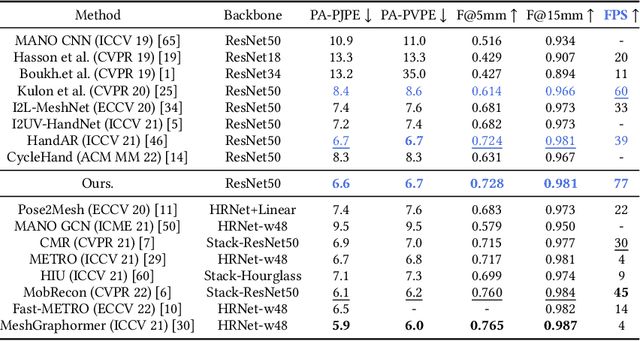
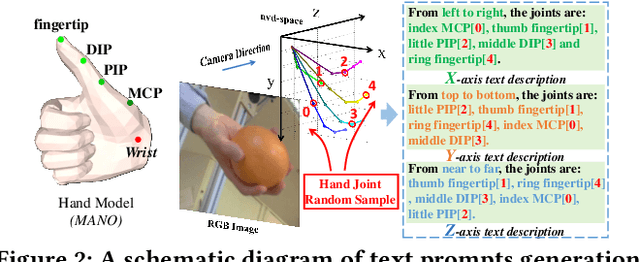
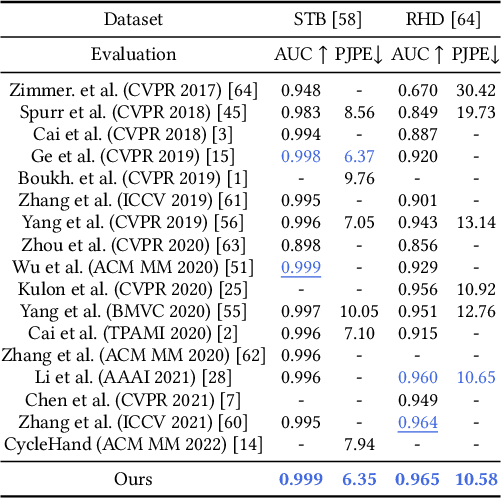
Contrastive Language-Image Pre-training (CLIP) starts to emerge in many computer vision tasks and has achieved promising performance. However, it remains underexplored whether CLIP can be generalized to 3D hand pose estimation, as bridging text prompts with pose-aware features presents significant challenges due to the discrete nature of joint positions in 3D space. In this paper, we make one of the first attempts to propose a novel 3D hand pose estimator from monocular images, dubbed as CLIP-Hand3D, which successfully bridges the gap between text prompts and irregular detailed pose distribution. In particular, the distribution order of hand joints in various 3D space directions is derived from pose labels, forming corresponding text prompts that are subsequently encoded into text representations. Simultaneously, 21 hand joints in the 3D space are retrieved, and their spatial distribution (in x, y, and z axes) is encoded to form pose-aware features. Subsequently, we maximize semantic consistency for a pair of pose-text features following a CLIP-based contrastive learning paradigm. Furthermore, a coarse-to-fine mesh regressor is designed, which is capable of effectively querying joint-aware cues from the feature pyramid. Extensive experiments on several public hand benchmarks show that the proposed model attains a significantly faster inference speed while achieving state-of-the-art performance compared to methods utilizing the similar scale backbone.
Class Activation Map-based Weakly supervised Hemorrhage Segmentation using Resnet-LSTM in Non-Contrast Computed Tomography images
Sep 28, 2023In clinical settings, intracranial hemorrhages (ICH) are routinely diagnosed using non-contrast CT (NCCT) for severity assessment. Accurate automated segmentation of ICH lesions is the initial and essential step, immensely useful for such assessment. However, compared to other structural imaging modalities such as MRI, in NCCT images ICH appears with very low contrast and poor SNR. Over recent years, deep learning (DL)-based methods have shown great potential, however, training them requires a huge amount of manually annotated lesion-level labels, with sufficient diversity to capture the characteristics of ICH. In this work, we propose a novel weakly supervised DL method for ICH segmentation on NCCT scans, using image-level binary classification labels, which are less time-consuming and labor-efficient when compared to the manual labeling of individual ICH lesions. Our method initially determines the approximate location of ICH using class activation maps from a classification network, which is trained to learn dependencies across contiguous slices. We further refine the ICH segmentation using pseudo-ICH masks obtained in an unsupervised manner. The method is flexible and uses a computationally light architecture during testing. On evaluating our method on the validation data of the MICCAI 2022 INSTANCE challenge, our method achieves a Dice value of 0.55, comparable with those of existing weakly supervised method (Dice value of 0.47), despite training on a much smaller training data.
Evaluating the anticipated outcomes of MRI seizure image from open-source tool- Prototype approach
Aug 13, 2023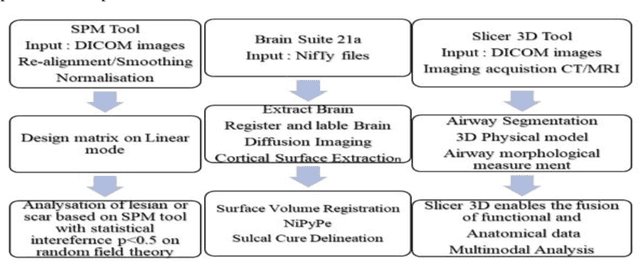
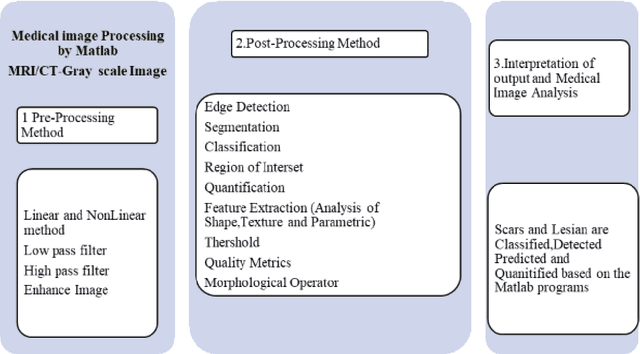
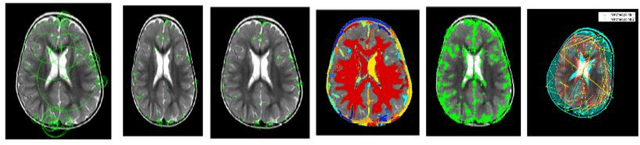
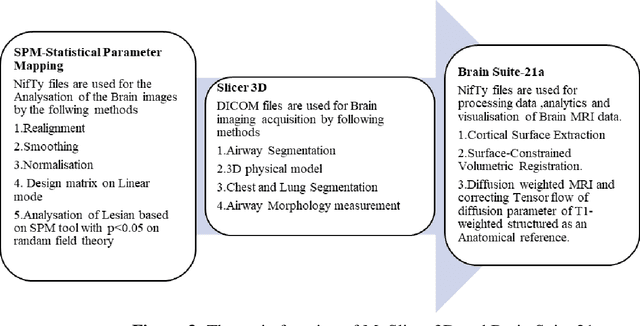
Epileptic Seizure is an abnormal neuronal exertion in the brain, affecting nearly 70 million of the world's population (Ngugi et al., 2010). So many open-source neuroimaging tools are used for metabolism checkups and analysis purposes. The scope of open-source tools like MATLAB, Slicer 3D, Brain Suite21a, SPM, and MedCalc are explained in this paper. MATLAB was used by 60% of the researchers for their image processing and 10% of them use their proprietary software. More than 30% of the researchers use other open-source software tools with their processing techniques for the study of magnetic resonance seizure images
SLiMe: Segment Like Me
Sep 06, 2023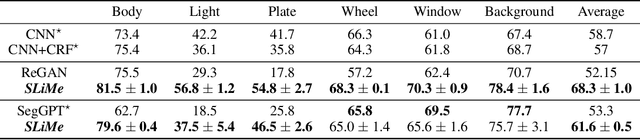

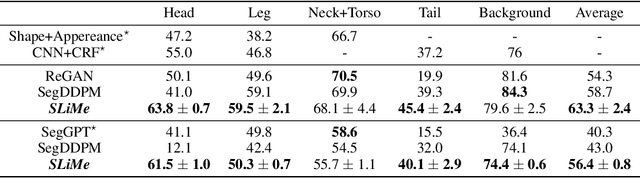

Significant strides have been made using large vision-language models, like Stable Diffusion (SD), for a variety of downstream tasks, including image editing, image correspondence, and 3D shape generation. Inspired by these advancements, we explore leveraging these extensive vision-language models for segmenting images at any desired granularity using as few as one annotated sample by proposing SLiMe. SLiMe frames this problem as an optimization task. Specifically, given a single training image and its segmentation mask, we first extract attention maps, including our novel "weighted accumulated self-attention map" from the SD prior. Then, using the extracted attention maps, the text embeddings of Stable Diffusion are optimized such that, each of them, learn about a single segmented region from the training image. These learned embeddings then highlight the segmented region in the attention maps, which in turn can then be used to derive the segmentation map. This enables SLiMe to segment any real-world image during inference with the granularity of the segmented region in the training image, using just one example. Moreover, leveraging additional training data when available, i.e. few-shot, improves the performance of SLiMe. We carried out a knowledge-rich set of experiments examining various design factors and showed that SLiMe outperforms other existing one-shot and few-shot segmentation methods.