 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBdSL-SPOTER: A Transformer-Based Framework for Bengali Sign Language Recognition with Cultural Adaptation
Nov 15, 2025



We introduce BdSL-SPOTER, a pose-based transformer framework for accurate and efficient recognition of Bengali Sign Language (BdSL). BdSL-SPOTER extends the SPOTER paradigm with cultural specific preprocessing and a compact four-layer transformer encoder featuring optimized learnable positional encodings, while employing curriculum learning to enhance generalization on limited data and accelerate convergence. On the BdSLW60 benchmark, it achieves 97.92% Top-1 validation accuracy, representing a 22.82% improvement over the Bi-LSTM baseline, all while keeping computational costs low. With its reduced number of parameters, lower FLOPs, and higher FPS, BdSL-SPOTER provides a practical framework for real-world accessibility applications and serves as a scalable model for other low-resource regional sign languages.
LLM-Based Evaluation of Low-Resource Machine Translation: A Reference-less Dialect Guided Approach with a Refined Sylheti-English Benchmark
May 18, 2025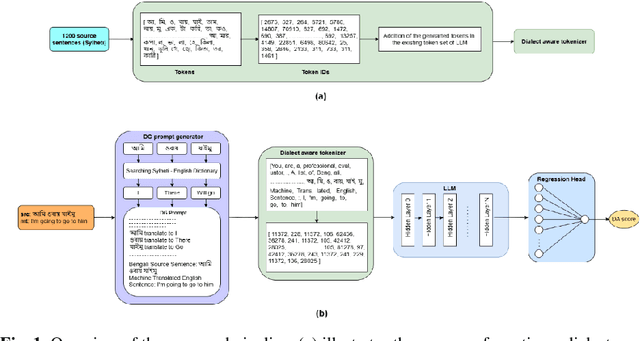
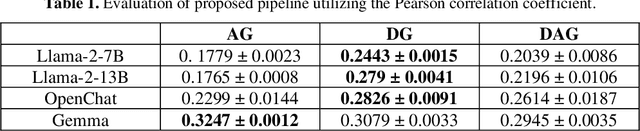

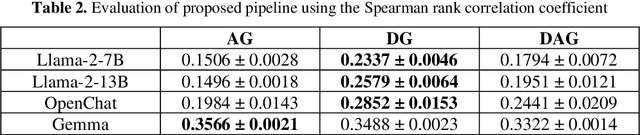
Evaluating machine translation (MT) for low-resource languages poses a persistent challenge, primarily due to the limited availability of high quality reference translations. This issue is further exacerbated in languages with multiple dialects, where linguistic diversity and data scarcity hinder robust evaluation. Large Language Models (LLMs) present a promising solution through reference-free evaluation techniques; however, their effectiveness diminishes in the absence of dialect-specific context and tailored guidance. In this work, we propose a comprehensive framework that enhances LLM-based MT evaluation using a dialect guided approach. We extend the ONUBAD dataset by incorporating Sylheti-English sentence pairs, corresponding machine translations, and Direct Assessment (DA) scores annotated by native speakers. To address the vocabulary gap, we augment the tokenizer vocabulary with dialect-specific terms. We further introduce a regression head to enable scalar score prediction and design a dialect-guided (DG) prompting strategy. Our evaluation across multiple LLMs shows that the proposed pipeline consistently outperforms existing methods, achieving the highest gain of +0.1083 in Spearman correlation, along with improvements across other evaluation settings. The dataset and the code are available at https://github.com/180041123-Atiq/MTEonLowResourceLanguage.
Evaluating the Reliability of CNN Models on Classifying Traffic and Road Signs using LIME
Sep 11, 2023



The objective of this investigation is to evaluate and contrast the effectiveness of four state-of-the-art pre-trained models, ResNet-34, VGG-19, DenseNet-121, and Inception V3, in classifying traffic and road signs with the utilization of the GTSRB public dataset. The study focuses on evaluating the accuracy of these models' predictions as well as their ability to employ appropriate features for image categorization. To gain insights into the strengths and limitations of the model's predictions, the study employs the local interpretable model-agnostic explanations (LIME) framework. The findings of this experiment indicate that LIME is a crucial tool for improving the interpretability and dependability of machine learning models for image identification, regardless of the models achieving an f1 score of 0.99 on classifying traffic and road signs. The conclusion of this study has important ramifications for how these models are used in practice, as it is crucial to ensure that model predictions are founded on the pertinent image features.