 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgepixelcnn
PixelCNN is a generative model that generates images pixel by pixel using a convolutional neural network.
Papers and Code
Out-of-distribution Detection via Frequency-regularized Generative Models
Aug 18, 2022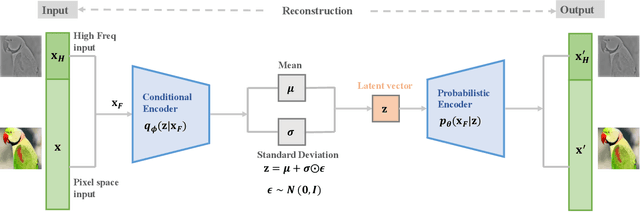
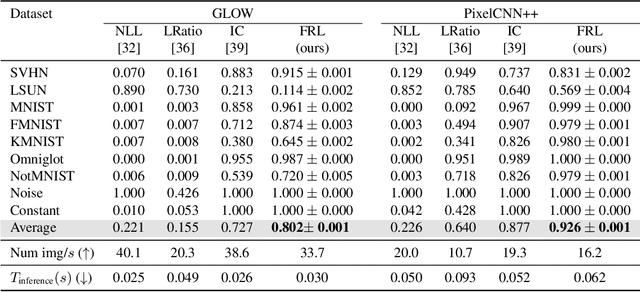

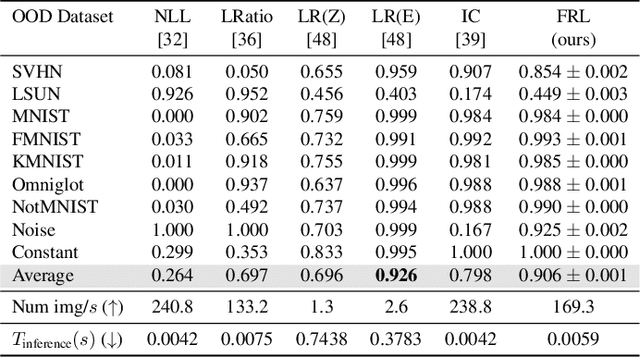
Modern deep generative models can assign high likelihood to inputs drawn from outside the training distribution, posing threats to models in open-world deployments. While much research attention has been placed on defining new test-time measures of OOD uncertainty, these methods do not fundamentally change how deep generative models are regularized and optimized in training. In particular, generative models are shown to overly rely on the background information to estimate the likelihood. To address the issue, we propose a novel frequency-regularized learning FRL framework for OOD detection, which incorporates high-frequency information into training and guides the model to focus on semantically relevant features. FRL effectively improves performance on a wide range of generative architectures, including variational auto-encoder, GLOW, and PixelCNN++. On a new large-scale evaluation task, FRL achieves the state-of-the-art performance, outperforming a strong baseline Likelihood Regret by 10.7% (AUROC) while achieving 147$\times$ faster inference speed. Extensive ablations show that FRL improves the OOD detection performance while preserving the image generation quality. Code is available at https://github.com/mu-cai/FRL.
Information Entropy Initialized Concrete Autoencoder for Optimal Sensor Placement and Reconstruction of Geophysical Fields
Jun 28, 2022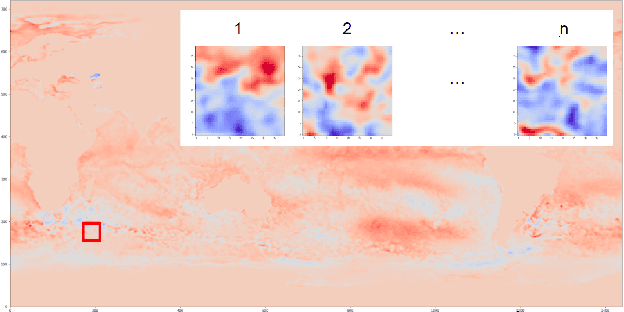
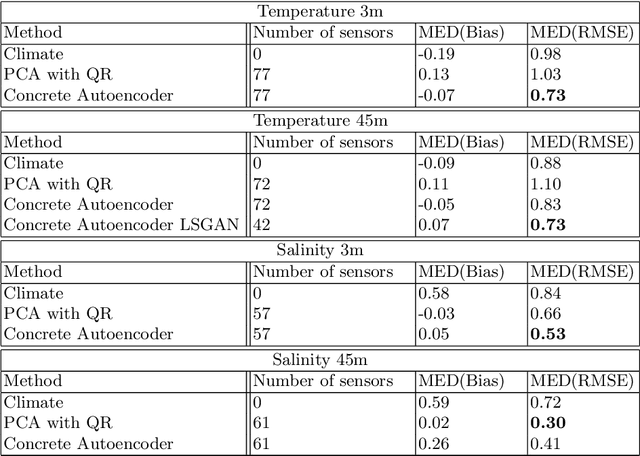
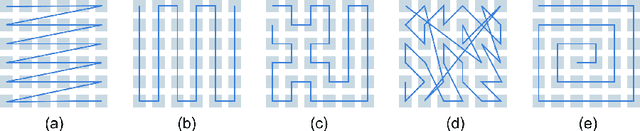
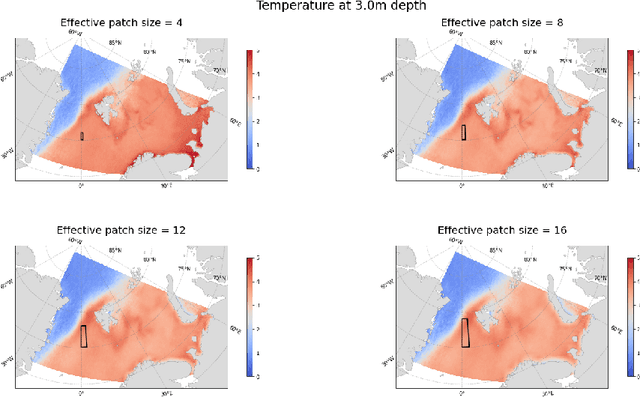
We propose a new approach to the optimal placement of sensors for the problem of reconstructing geophysical fields from sparse measurements. Our method consists of two stages. In the first stage, we estimate the variability of the physical field as a function of spatial coordinates by approximating its information entropy through the Conditional PixelCNN network. To calculate the entropy, a new ordering of a two-dimensional data array (spiral ordering) is proposed, which makes it possible to obtain the entropy of a physical field simultaneously for several spatial scales. In the second stage, the entropy of the physical field is used to initialize the distribution of optimal sensor locations. This distribution is further optimized with the Concrete Autoencoder architecture with the straight-through gradient estimator and adversarial loss to simultaneously minimize the number of sensors and maximize reconstruction accuracy. Our method scales linearly with data size, unlike commonly used Principal Component Analysis. We demonstrate our method on the two examples: (a) temperature and (b) salinity fields around the Barents Sea and the Svalbard group of islands. For these examples, we compute the reconstruction error of our method and a few baselines. We test our approach against two baselines (1) PCA with QR factorization and (2) climatology. We find out that the obtained optimal sensor locations have clear physical interpretation and correspond to the boundaries between sea currents.
Towards Measuring Domain Shift in Histopathological Stain Translation in an Unsupervised Manner
May 09, 2022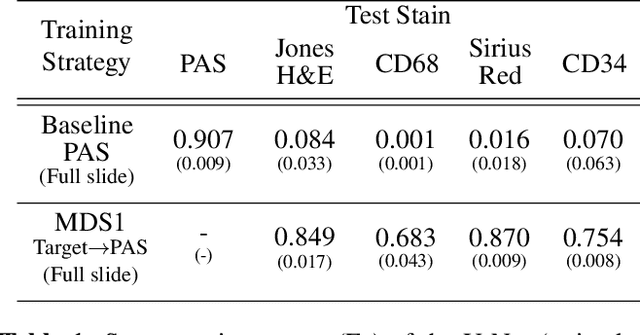
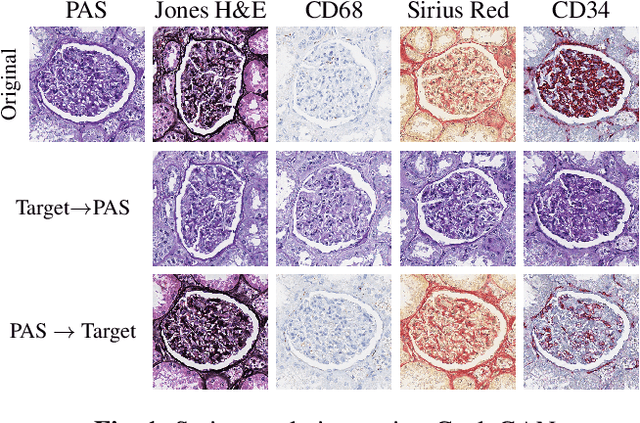
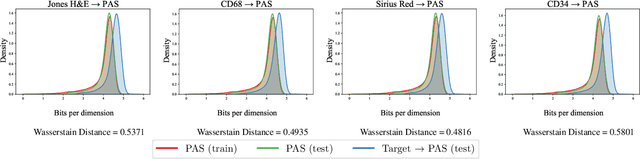

Domain shift in digital histopathology can occur when different stains or scanners are used, during stain translation, etc. A deep neural network trained on source data may not generalise well to data that has undergone some domain shift. An important step towards being robust to domain shift is the ability to detect and measure it. This article demonstrates that the PixelCNN and domain shift metric can be used to detect and quantify domain shift in digital histopathology, and they demonstrate a strong correlation with generalisation performance. These findings pave the way for a mechanism to infer the average performance of a model (trained on source data) on unseen and unlabelled target data.
* 5 pages, 3 figures, 2 tables
Pixel-Stega: Generative Image Steganography Based on Autoregressive Models
Dec 21, 2021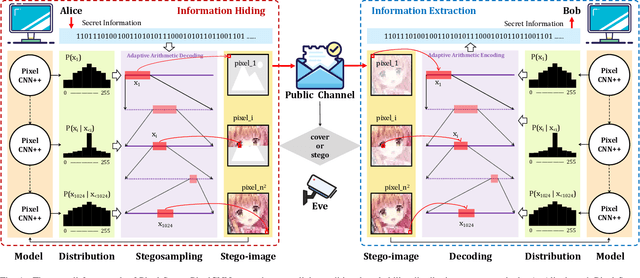

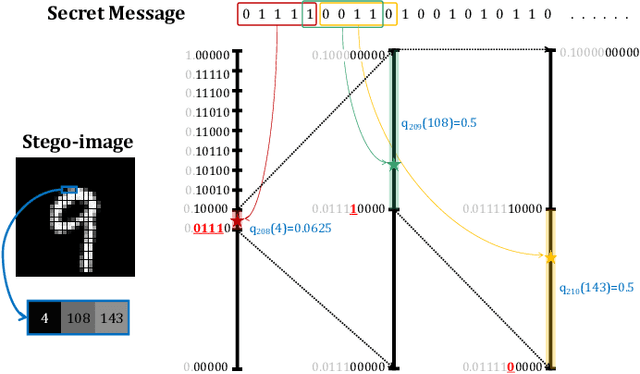

In this letter, we explored generative image steganography based on autoregressive models. We proposed Pixel-Stega, which implements pixel-level information hiding with autoregressive models and arithmetic coding algorithm. Firstly, one of the autoregressive models, PixelCNN++, is utilized to produce explicit conditional probability distribution of each pixel. Secondly, secret messages are encoded to the selection of pixels through steganographic sampling (stegosampling) based on arithmetic coding. We carried out qualitative and quantitative assessment on gray-scale and colour image datasets. Experimental results show that Pixel-Stega is able to embed secret messages adaptively according to the entropy of the pixels to achieve both high embedding capacity (up to 4.3 bpp) and nearly perfect imperceptibility (about 50% detection accuracy).
A model of semantic completion in generative episodic memory
Nov 26, 2021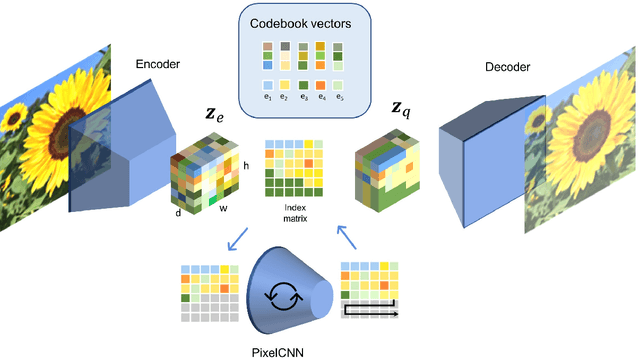
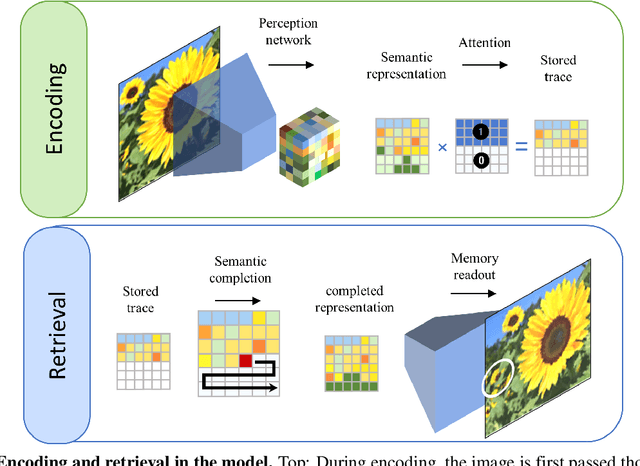
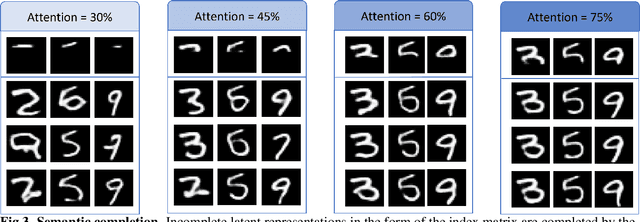
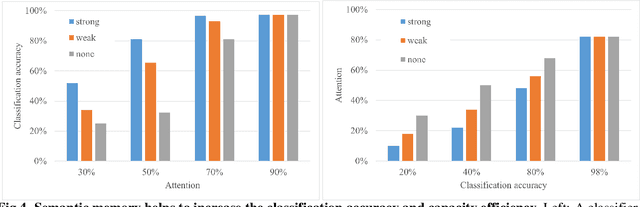
Many different studies have suggested that episodic memory is a generative process, but most computational models adopt a storage view. In this work, we propose a computational model for generative episodic memory. It is based on the central hypothesis that the hippocampus stores and retrieves selected aspects of an episode as a memory trace, which is necessarily incomplete. At recall, the neocortex reasonably fills in the missing information based on general semantic information in a process we call semantic completion. As episodes we use images of digits (MNIST) augmented by different backgrounds representing context. Our model is based on a VQ-VAE which generates a compressed latent representation in form of an index matrix, which still has some spatial resolution. We assume that attention selects some part of the index matrix while others are discarded, this then represents the gist of the episode and is stored as a memory trace. At recall the missing parts are filled in by a PixelCNN, modeling semantic completion, and the completed index matrix is then decoded into a full image by the VQ-VAE. The model is able to complete missing parts of a memory trace in a semantically plausible way up to the point where it can generate plausible images from scratch. Due to the combinatorics in the index matrix, the model generalizes well to images not trained on. Compression as well as semantic completion contribute to a strong reduction in memory requirements and robustness to noise. Finally we also model an episodic memory experiment and can reproduce that semantically congruent contexts are always recalled better than incongruent ones, high attention levels improve memory accuracy in both cases, and contexts that are not remembered correctly are more often remembered semantically congruently than completely wrong.
Unsupervised Representation Learning from Pathology Images with Multi-directional Contrastive Predictive Coding
May 11, 2021
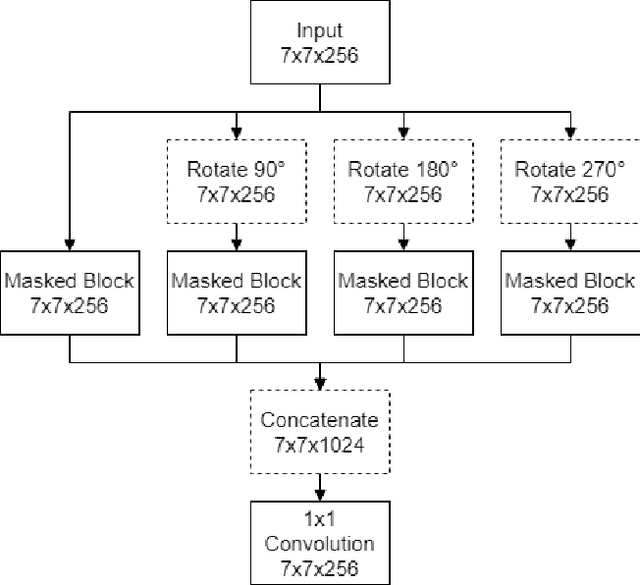
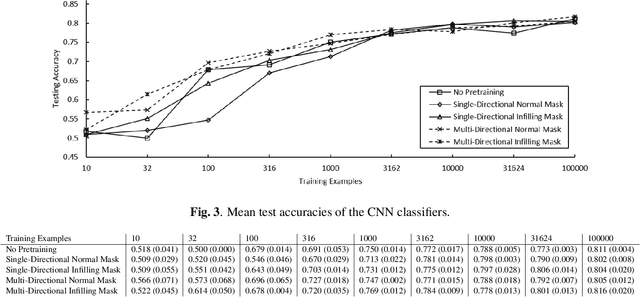
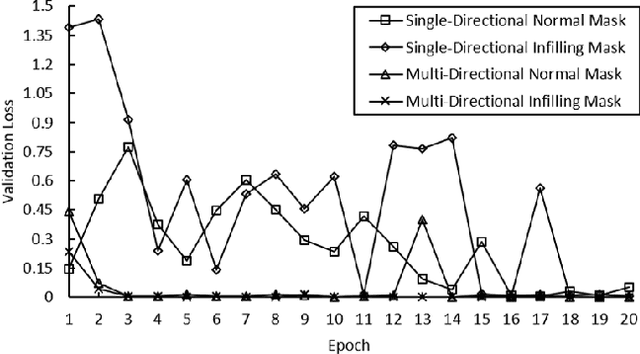
Digital pathology tasks have benefited greatly from modern deep learning algorithms. However, their need for large quantities of annotated data has been identified as a key challenge. This need for data can be countered by using unsupervised learning in situations where data are abundant but access to annotations is limited. Feature representations learned from unannotated data using contrastive predictive coding (CPC) have been shown to enable classifiers to obtain state of the art performance from relatively small amounts of annotated computer vision data. We present a modification to the CPC framework for use with digital pathology patches. This is achieved by introducing an alternative mask for building the latent context and using a multi-directional PixelCNN autoregressor. To demonstrate our proposed method we learn feature representations from the Patch Camelyon histology dataset. We show that our proposed modification can yield improved deep classification of histology patches.
Very Deep VAEs Generalize Autoregressive Models and Can Outperform Them on Images
Nov 20, 2020


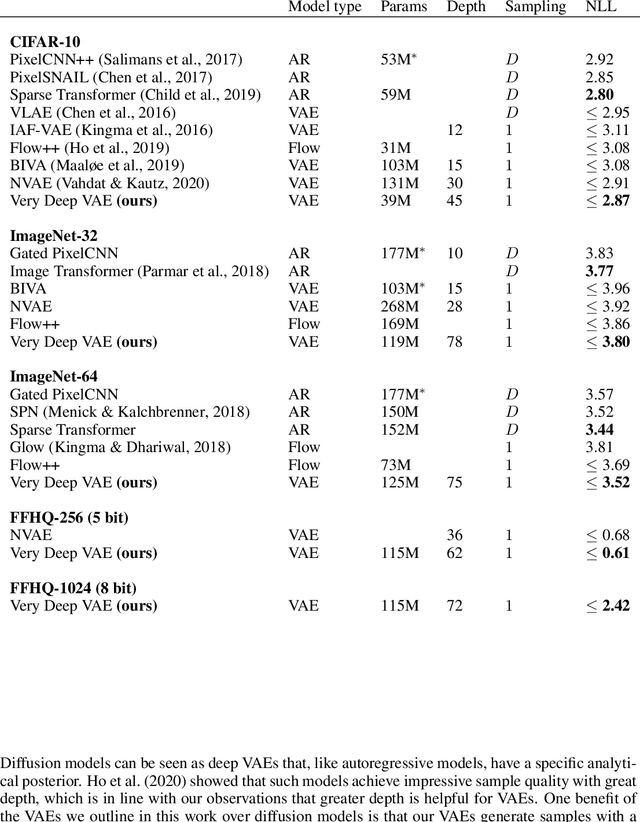
We present a hierarchical VAE that, for the first time, outperforms the PixelCNN in log-likelihood on all natural image benchmarks. We begin by observing that VAEs can actually implement autoregressive models, and other, more efficient generative models, if made sufficiently deep. Despite this, autoregressive models have traditionally outperformed VAEs. We test if insufficient depth explains the performance gap by by scaling a VAE to greater stochastic depth than previously explored and evaluating it on CIFAR-10, ImageNet, and FFHQ. We find that, in comparison to the PixelCNN, these very deep VAEs achieve higher likelihoods, use fewer parameters, generate samples thousands of times faster, and are more easily applied to high-resolution images. We visualize the generative process and show the VAEs learn efficient hierarchical visual representations. We release our source code and models at https://github.com/openai/vdvae.
Context-based Image Segment Labeling (CBISL)
Nov 02, 2020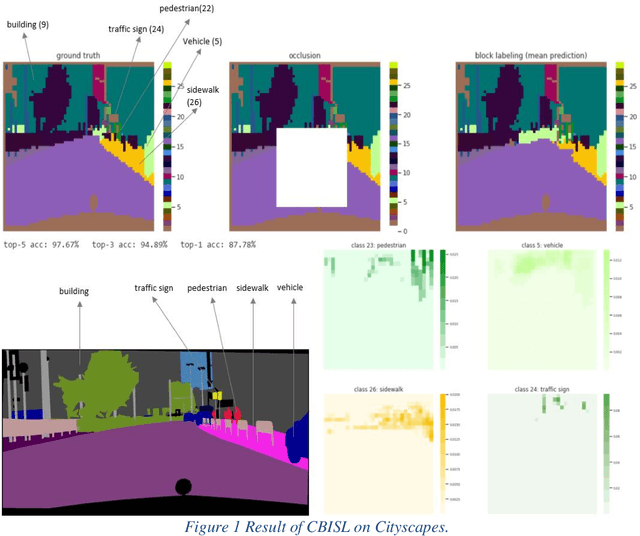
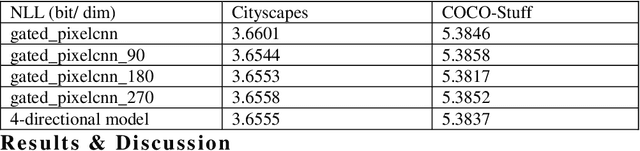
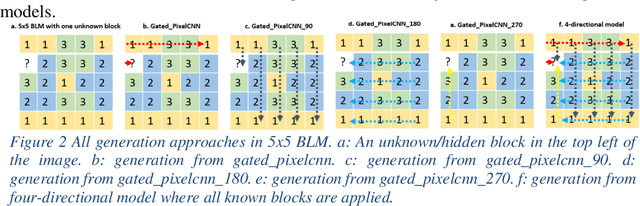
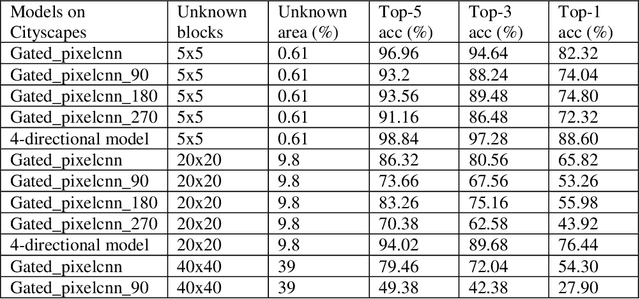
Working with images, one often faces problems with incomplete or unclear information. Image inpainting can be used to restore missing image regions but focuses, however, on low-level image features such as pixel intensity, pixel gradient orientation, and color. This paper aims to recover semantic image features (objects and positions) in images. Based on published gated PixelCNNs, we demonstrate a new approach referred to as quadro-directional PixelCNN to recover missing objects and return probable positions for objects based on the context. We call this approach context-based image segment labeling (CBISL). The results suggest that our four-directional model outperforms one-directional models (gated PixelCNN) and returns a human-comparable performance.
Locally Masked Convolution for Autoregressive Models
Jun 27, 2020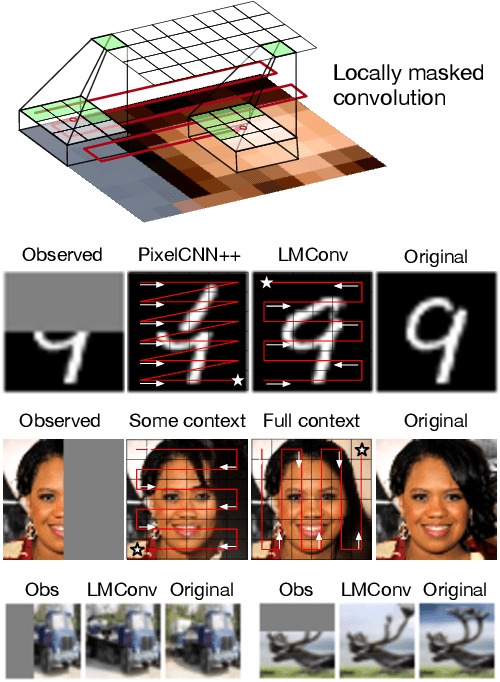
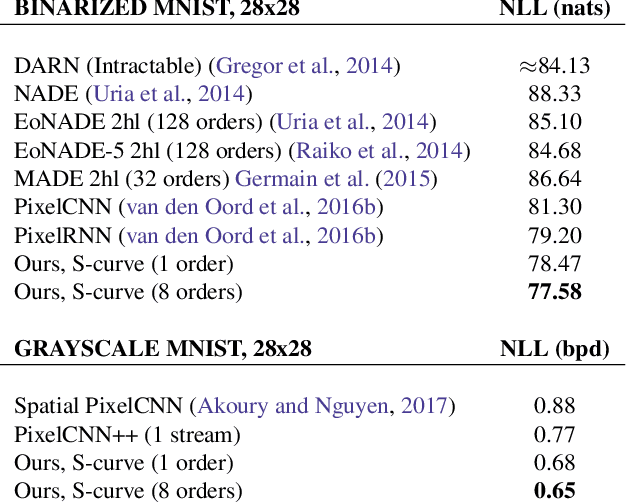
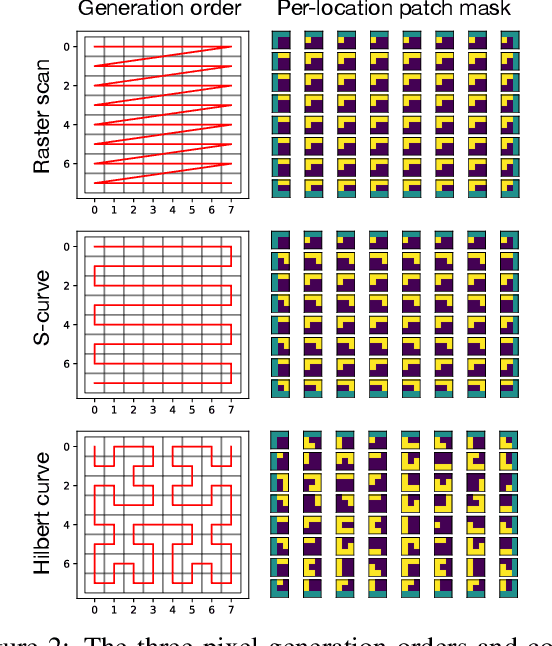

High-dimensional generative models have many applications including image compression, multimedia generation, anomaly detection and data completion. State-of-the-art estimators for natural images are autoregressive, decomposing the joint distribution over pixels into a product of conditionals parameterized by a deep neural network, e.g. a convolutional neural network such as the PixelCNN. However, PixelCNNs only model a single decomposition of the joint, and only a single generation order is efficient. For tasks such as image completion, these models are unable to use much of the observed context. To generate data in arbitrary orders, we introduce LMConv: a simple modification to the standard 2D convolution that allows arbitrary masks to be applied to the weights at each location in the image. Using LMConv, we learn an ensemble of distribution estimators that share parameters but differ in generation order, achieving improved performance on whole-image density estimation (2.89 bpd on unconditional CIFAR10), as well as globally coherent image completions. Our code is available at https://ajayjain.github.io/lmconv.
What Information Does a ResNet Compress?
Mar 13, 2020
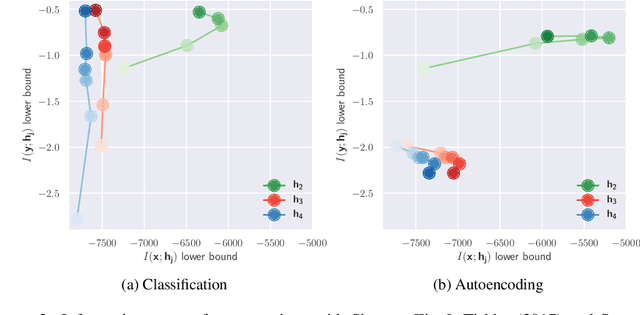
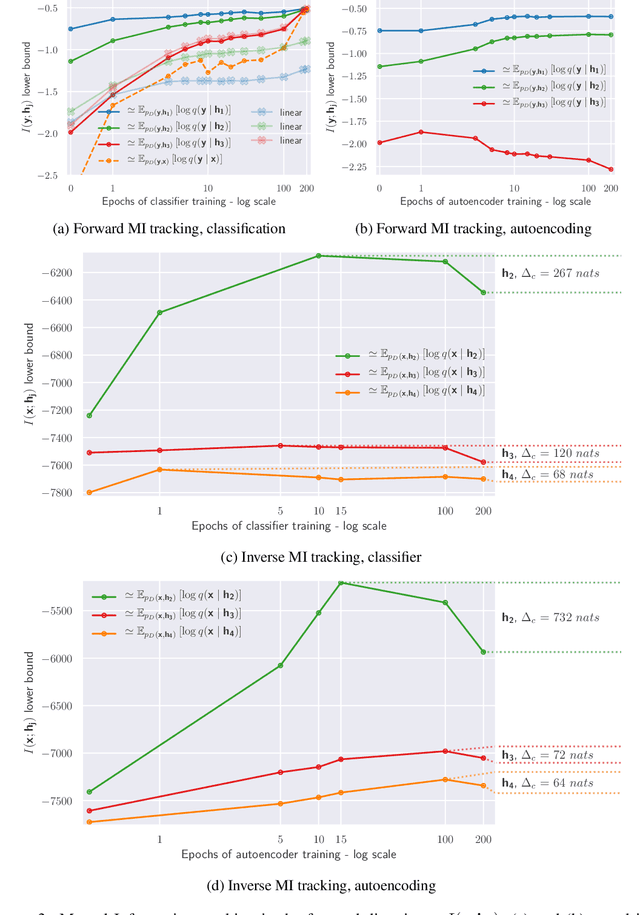
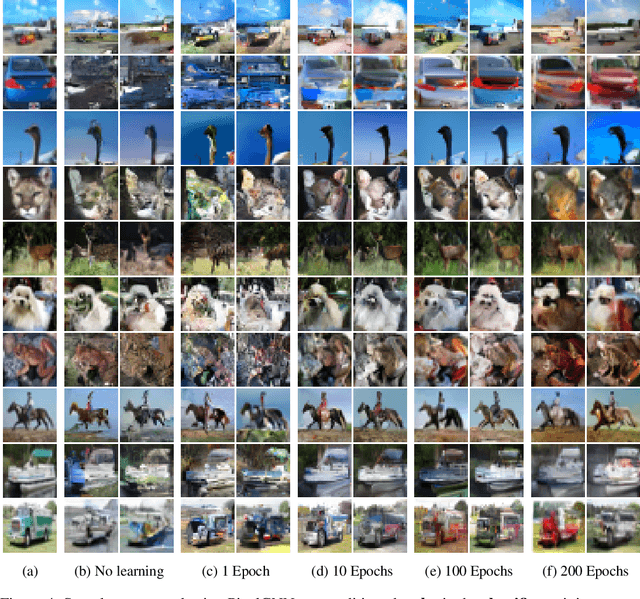
The information bottleneck principle (Shwartz-Ziv & Tishby, 2017) suggests that SGD-based training of deep neural networks results in optimally compressed hidden layers, from an information theoretic perspective. However, this claim was established on toy data. The goal of the work we present here is to test whether the information bottleneck principle is applicable to a realistic setting using a larger and deeper convolutional architecture, a ResNet model. We trained PixelCNN++ models as inverse representation decoders to measure the mutual information between hidden layers of a ResNet and input image data, when trained for (1) classification and (2) autoencoding. We find that two stages of learning happen for both training regimes, and that compression does occur, even for an autoencoder. Sampling images by conditioning on hidden layers' activations offers an intuitive visualisation to understand what a ResNets learns to forget.