 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero Shot Named Entity Recognition Ner
Papers and Code
A Dataset for Named Entity Recognition and Relation Extraction from Art-historical Image Descriptions
Feb 22, 2026This paper introduces FRAME (Fine-grained Recognition of Art-historical Metadata and Entities), a manually annotated dataset of art-historical image descriptions for Named Entity Recognition (NER) and Relation Extraction (RE). Descriptions were collected from museum catalogs, auction listings, open-access platforms, and scholarly databases, then filtered to ensure that each text focuses on a single artwork and contains explicit statements about its material, composition, or iconography. FRAME provides stand-off annotations in three layers: a metadata layer for object-level properties, a content layer for depicted subjects and motifs, and a co-reference layer linking repeated mentions. Across layers, entity spans are labeled with 37 types and connected by typed RE links between mentions. Entity types are aligned with Wikidata to support Named Entity Linking (NEL) and downstream knowledge-graph construction. The dataset is released as UIMA XMI Common Analysis Structure (CAS) files with accompanying images and bibliographic metadata, and can be used to benchmark and fine-tune NER and RE systems, including zero- and few-shot setups with Large Language Models (LLMs).
Local LLM Ensembles for Zero-shot Portuguese Named Entity Recognition
Dec 10, 2025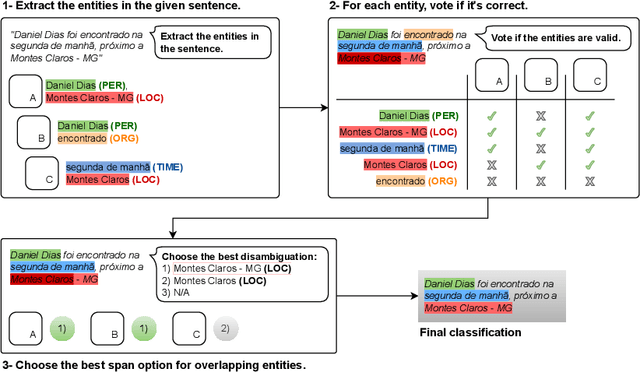
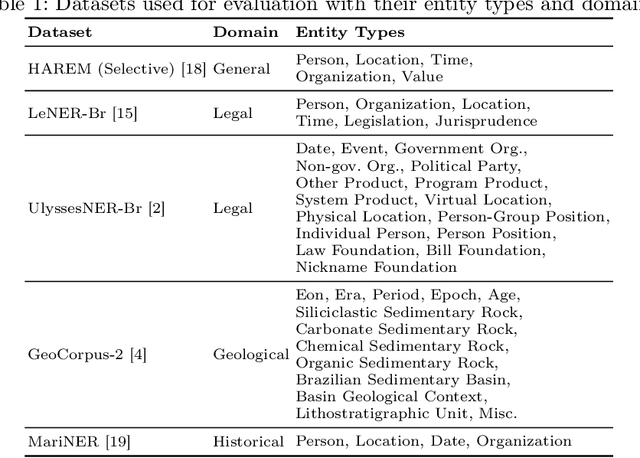
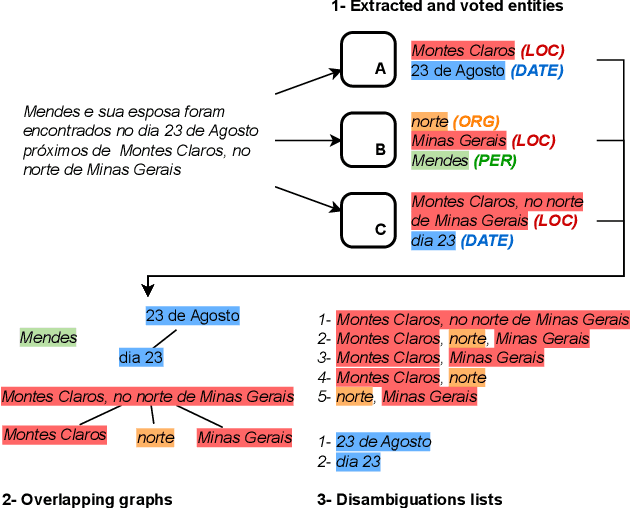
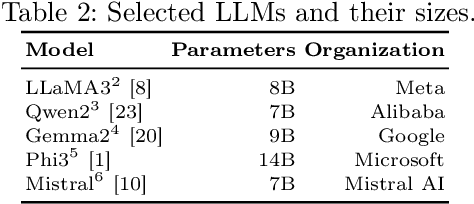
Large Language Models (LLMs) excel in many Natural Language Processing (NLP) tasks through in-context learning but often under-perform in Named Entity Recognition (NER), especially for lower-resource languages like Portuguese. While open-weight LLMs enable local deployment, no single model dominates all tasks, motivating ensemble approaches. However, existing LLM ensembles focus on text generation or classification, leaving NER under-explored. In this context, this work proposes a novel three-step ensemble pipeline for zero-shot NER using similarly capable, locally run LLMs. Our method outperforms individual LLMs in four out of five Portuguese NER datasets by leveraging a heuristic to select optimal model combinations with minimal annotated data. Moreover, we show that ensembles obtained on different source datasets generally outperform individual LLMs in cross-dataset configurations, potentially eliminating the need for annotated data for the current task. Our work advances scalable, low-resource, and zero-shot NER by effectively combining multiple small LLMs without fine-tuning. Code is available at https://github.com/Joao-Luz/local-llm-ner-ensemble.
OEMA: Ontology-Enhanced Multi-Agent Collaboration Framework for Zero-Shot Clinical Named Entity Recognition
Nov 19, 2025Clinical named entity recognition (NER) is crucial for extracting information from electronic health records (EHRs), but supervised models like CRF and BioClinicalBERT require costly annotated data. While zero-shot NER with large language models (LLMs) reduces this dependency, it struggles with example selection granularity and integrating prompts with self-improvement. To address this, we propose OEMA, a zero-shot clinical NER framework using multi-agent collaboration. OEMA's three components are: a self-annotator generating examples, a discriminator filtering them via SNOMED CT, and a predictor using entity descriptions for accurate inference. On MTSamples and VAERS datasets, OEMA achieves state-of-the-art exact-match performance. Under related-match, it matches supervised BioClinicalBERT and surpasses CRF. OEMA addresses key zero-shot NER challenges through ontology-guided reasoning and multi-agent collaboration, achieving near-supervised performance and showing promise for clinical NLP applications.
FiNERweb: Datasets and Artifacts for Scalable Multilingual Named Entity Recognition
Dec 15, 2025



Recent multilingual named entity recognition (NER) work has shown that large language models (LLMs) can provide effective synthetic supervision, yet such datasets have mostly appeared as by-products of broader experiments rather than as systematic, reusable resources. We introduce FiNERweb, a dataset-creation pipeline that scales the teacher-student paradigm to 91 languages and 25 scripts. Building on FineWeb-Edu, our approach trains regression models to identify NER-relevant passages and annotates them with multilingual LLMs, resulting in about 225k passages with 235k distinct entity labels. Our experiments show that the regression model achieves more than 84 F1, and that models trained on FiNERweb obtain comparable or improved performance in zero shot transfer settings on English, Thai, and Swahili, despite being trained on 19x less data than strong baselines. In addition, we assess annotation quality using LLM-as-a-judge and observe consistently high scores for both faithfulness (3.99 out of 5) and completeness (4.05 out of 5), indicating reliable and informative annotations. Further, we release the dataset with both English labels and translated label sets in the respective target languages because we observe that the performance of current state-of-the-art models drops by 0.02 to 0.09 F1 when evaluated using target language labels instead of English ones. We release FiNERweb together with all accompanying artifacts to the research community in order to facilitate more effective student-teacher training for multilingual named entity recognition.
A Reasoning Paradigm for Named Entity Recognition
Nov 15, 2025



Generative LLMs typically improve Named Entity Recognition (NER) performance through instruction tuning. They excel at generating entities by semantic pattern matching but lack an explicit, verifiable reasoning mechanism. This "cognitive shortcutting" leads to suboptimal performance and brittle generalization, especially in zero-shot and lowresource scenarios where reasoning from limited contextual cues is crucial. To address this issue, a reasoning framework is proposed for NER, which shifts the extraction paradigm from implicit pattern matching to explicit reasoning. This framework consists of three stages: Chain of Thought (CoT) generation, CoT tuning, and reasoning enhancement. First, a dataset annotated with NER-oriented CoTs is generated, which contain task-relevant reasoning chains. Then, they are used to tune the NER model to generate coherent rationales before deriving the final answer. Finally, a reasoning enhancement stage is implemented to optimize the reasoning process using a comprehensive reward signal. This stage ensures explicit and verifiable extractions. Experiments show that ReasoningNER demonstrates impressive cognitive ability in the NER task, achieving competitive performance. In zero-shot settings, it achieves state-of-the-art (SOTA) performance, outperforming GPT-4 by 12.3 percentage points on the F1 score. Analytical results also demonstrate its great potential to advance research in reasoningoriented information extraction. Our codes are available at https://github.com/HuiResearch/ReasoningIE.
NER Retriever: Zero-Shot Named Entity Retrieval with Type-Aware Embeddings
Sep 04, 2025We present NER Retriever, a zero-shot retrieval framework for ad-hoc Named Entity Retrieval, a variant of Named Entity Recognition (NER), where the types of interest are not provided in advance, and a user-defined type description is used to retrieve documents mentioning entities of that type. Instead of relying on fixed schemas or fine-tuned models, our method builds on internal representations of large language models (LLMs) to embed both entity mentions and user-provided open-ended type descriptions into a shared semantic space. We show that internal representations, specifically the value vectors from mid-layer transformer blocks, encode fine-grained type information more effectively than commonly used top-layer embeddings. To refine these representations, we train a lightweight contrastive projection network that aligns type-compatible entities while separating unrelated types. The resulting entity embeddings are compact, type-aware, and well-suited for nearest-neighbor search. Evaluated on three benchmarks, NER Retriever significantly outperforms both lexical and dense sentence-level retrieval baselines. Our findings provide empirical support for representation selection within LLMs and demonstrate a practical solution for scalable, schema-free entity retrieval. The NER Retriever Codebase is publicly available at https://github.com/ShacharOr100/ner_retriever
Inference Gap in Domain Expertise and Machine Intelligence in Named Entity Recognition: Creation of and Insights from a Substance Use-related Dataset
Aug 26, 2025Nonmedical opioid use is an urgent public health challenge, with far-reaching clinical and social consequences that are often underreported in traditional healthcare settings. Social media platforms, where individuals candidly share first-person experiences, offer a valuable yet underutilized source of insight into these impacts. In this study, we present a named entity recognition (NER) framework to extract two categories of self-reported consequences from social media narratives related to opioid use: ClinicalImpacts (e.g., withdrawal, depression) and SocialImpacts (e.g., job loss). To support this task, we introduce RedditImpacts 2.0, a high-quality dataset with refined annotation guidelines and a focus on first-person disclosures, addressing key limitations of prior work. We evaluate both fine-tuned encoder-based models and state-of-the-art large language models (LLMs) under zero- and few-shot in-context learning settings. Our fine-tuned DeBERTa-large model achieves a relaxed token-level F1 of 0.61 [95% CI: 0.43-0.62], consistently outperforming LLMs in precision, span accuracy, and adherence to task-specific guidelines. Furthermore, we show that strong NER performance can be achieved with substantially less labeled data, emphasizing the feasibility of deploying robust models in resource-limited settings. Our findings underscore the value of domain-specific fine-tuning for clinical NLP tasks and contribute to the responsible development of AI tools that may enhance addiction surveillance, improve interpretability, and support real-world healthcare decision-making. The best performing model, however, still significantly underperforms compared to inter-expert agreement (Cohen's kappa: 0.81), demonstrating that a gap persists between expert intelligence and current state-of-the-art NER/AI capabilities for tasks requiring deep domain knowledge.
Named Entity Recognition of Historical Text via Large Language Model
Aug 25, 2025Large language models have demonstrated remarkable versatility across a wide range of natural language processing tasks and domains. One such task is Named Entity Recognition (NER), which involves identifying and classifying proper names in text, such as people, organizations, locations, dates, and other specific entities. NER plays a crucial role in extracting information from unstructured textual data, enabling downstream applications such as information retrieval from unstructured text. Traditionally, NER is addressed using supervised machine learning approaches, which require large amounts of annotated training data. However, historical texts present a unique challenge, as the annotated datasets are often scarce or nonexistent, due to the high cost and expertise required for manual labeling. In addition, the variability and noise inherent in historical language, such as inconsistent spelling and archaic vocabulary, further complicate the development of reliable NER systems for these sources. In this study, we explore the feasibility of applying LLMs to NER in historical documents using zero-shot and few-shot prompting strategies, which require little to no task-specific training data. Our experiments, conducted on the HIPE-2022 (Identifying Historical People, Places and other Entities) dataset, show that LLMs can achieve reasonably strong performance on NER tasks in this setting. While their performance falls short of fully supervised models trained on domain-specific annotations, the results are nevertheless promising. These findings suggest that LLMs offer a viable and efficient alternative for information extraction in low-resource or historically significant corpora, where traditional supervised methods are infeasible.
Cross-Lingual IPA Contrastive Learning for Zero-Shot NER
Mar 10, 2025Existing approaches to zero-shot Named Entity Recognition (NER) for low-resource languages have primarily relied on machine translation, whereas more recent methods have shifted focus to phonemic representation. Building upon this, we investigate how reducing the phonemic representation gap in IPA transcription between languages with similar phonetic characteristics enables models trained on high-resource languages to perform effectively on low-resource languages. In this work, we propose CONtrastive Learning with IPA (CONLIPA) dataset containing 10 English and high resource languages IPA pairs from 10 frequently used language families. We also propose a cross-lingual IPA Contrastive learning method (IPAC) using the CONLIPA dataset. Furthermore, our proposed dataset and methodology demonstrate a substantial average gain when compared to the best performing baseline.
A Cooperative Multi-Agent Framework for Zero-Shot Named Entity Recognition
Feb 25, 2025Zero-shot named entity recognition (NER) aims to develop entity recognition systems from unannotated text corpora. This task presents substantial challenges due to minimal human intervention. Recent work has adapted large language models (LLMs) for zero-shot NER by crafting specialized prompt templates. It advances model self-learning abilities by incorporating self-annotated demonstrations. However, two important challenges persist: (i) Correlations between contexts surrounding entities are overlooked, leading to wrong type predictions or entity omissions. (ii) The indiscriminate use of task demonstrations, retrieved through shallow similarity-based strategies, severely misleads LLMs during inference. In this paper, we introduce the cooperative multi-agent system (CMAS), a novel framework for zero-shot NER that uses the collective intelligence of multiple agents to address the challenges outlined above. CMAS has four main agents: (i) a self-annotator, (ii) a type-related feature (TRF) extractor, (iii) a demonstration discriminator, and (iv) an overall predictor. To explicitly capture correlations between contexts surrounding entities, CMAS reformulates NER into two subtasks: recognizing named entities and identifying entity type-related features within the target sentence. To enable controllable utilization of demonstrations, a demonstration discriminator is established to incorporate the self-reflection mechanism, automatically evaluating helpfulness scores for the target sentence. Experimental results show that CMAS significantly improves zero-shot NER performance across six benchmarks, including both domain-specific and general-domain scenarios. Furthermore, CMAS demonstrates its effectiveness in few-shot settings and with various LLM backbones.