 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIC: Contextual Language-Informed Cardiac Pathology Classification
May 18, 2026The electrocardiogram (ECG) is the gold standard for non-invasive diagnosis of cardiac pathologies and is a fundamental pillar of cardiovascular medicine. Recent progress in deep learning has led to the development of robust automated classifiers that achieve high performance by processing raw physiological signals. However, in clinical practice, diagnosis is rarely based solely on the signal. Cardiologists commonly support their interpretation with the patient's characteristics and the specific data-acquisition context. Despite this, most current algorithms remain restricted to signal-only analysis, failing to integrate technical metadata and demographic variables. This paper proposes Contextual Language-Informed Cardiac pathology classification (CLIC), a multimodal framework that significantly enhances diagnostic precision by encoding these variables through natural language. We demonstrate that translating patient-level contextual data into descriptive text provides an informative anchor that helps the model disambiguate complex physiological patterns. We further investigate the use of Large Language Models to synthesize richer clinical descriptions and observe that, while these generated texts remain competitive, controlled template-based contextual clinical text leads to consistent improvements in downstream classification performance.
Text2Graph: Combining Lightweight LLMs and GNNs for Efficient Text Classification in Label-Scarce Scenarios
Dec 12, 2025



Large Language Models (LLMs) have become effective zero-shot classifiers, but their high computational requirements and environmental costs limit their practicality for large-scale annotation in high-performance computing (HPC) environments. To support more sustainable workflows, we present Text2Graph, an open-source Python package that provides a modular implementation of existing text-to-graph classification approaches. The framework enables users to combine LLM-based partial annotation with Graph Neural Network (GNN) label propagation in a flexible manner, making it straightforward to swap components such as feature extractors, edge construction methods, and sampling strategies. We benchmark Text2Graph on a zero-shot setting using five datasets spanning topic classification and sentiment analysis tasks, comparing multiple variants against other zero-shot approaches for text classification. In addition to reporting performance, we provide detailed estimates of energy consumption and carbon emissions, showing that graph-based propagation achieves competitive results at a fraction of the energy and environmental cost.
Local LLM Ensembles for Zero-shot Portuguese Named Entity Recognition
Dec 10, 2025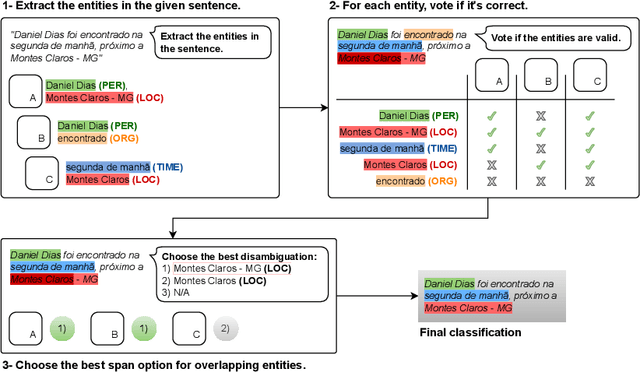
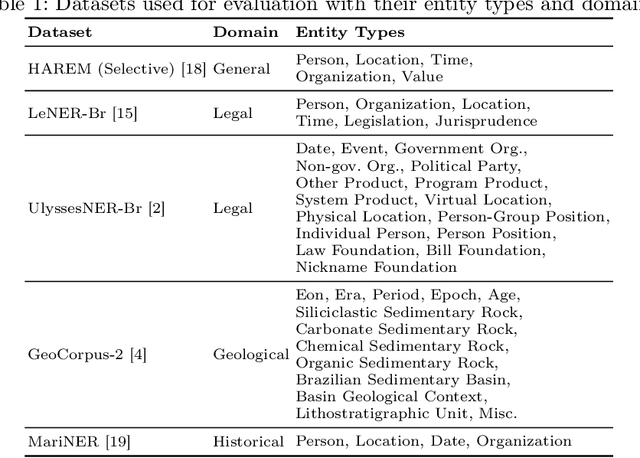
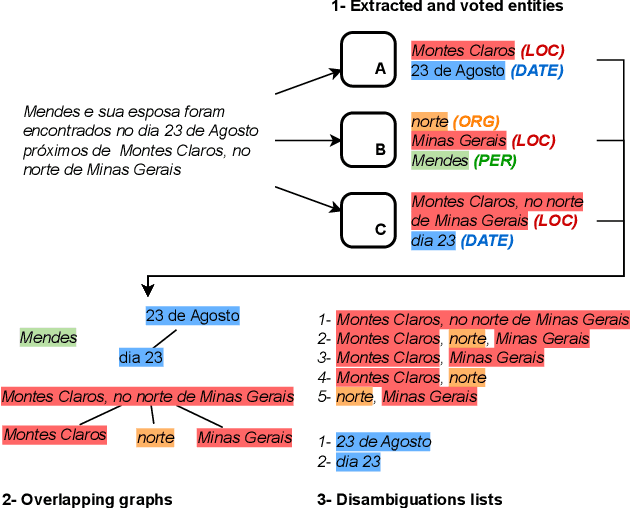
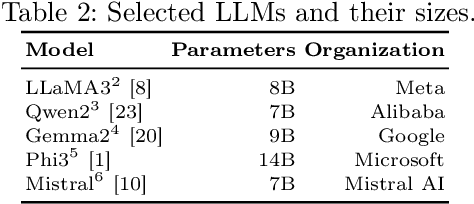
Large Language Models (LLMs) excel in many Natural Language Processing (NLP) tasks through in-context learning but often under-perform in Named Entity Recognition (NER), especially for lower-resource languages like Portuguese. While open-weight LLMs enable local deployment, no single model dominates all tasks, motivating ensemble approaches. However, existing LLM ensembles focus on text generation or classification, leaving NER under-explored. In this context, this work proposes a novel three-step ensemble pipeline for zero-shot NER using similarly capable, locally run LLMs. Our method outperforms individual LLMs in four out of five Portuguese NER datasets by leveraging a heuristic to select optimal model combinations with minimal annotated data. Moreover, we show that ensembles obtained on different source datasets generally outperform individual LLMs in cross-dataset configurations, potentially eliminating the need for annotated data for the current task. Our work advances scalable, low-resource, and zero-shot NER by effectively combining multiple small LLMs without fine-tuning. Code is available at https://github.com/Joao-Luz/local-llm-ner-ensemble.