 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToyota Smarthome
Papers and Code
Synthetic Human Action Video Data Generation with Pose Transfer
Jun 11, 2025



In video understanding tasks, particularly those involving human motion, synthetic data generation often suffers from uncanny features, diminishing its effectiveness for training. Tasks such as sign language translation, gesture recognition, and human motion understanding in autonomous driving have thus been unable to exploit the full potential of synthetic data. This paper proposes a method for generating synthetic human action video data using pose transfer (specifically, controllable 3D Gaussian avatar models). We evaluate this method on the Toyota Smarthome and NTU RGB+D datasets and show that it improves performance in action recognition tasks. Moreover, we demonstrate that the method can effectively scale few-shot datasets, making up for groups underrepresented in the real training data and adding diverse backgrounds. We open-source the method along with RANDOM People, a dataset with videos and avatars of novel human identities for pose transfer crowd-sourced from the internet.
Compact Recurrent Transformer with Persistent Memory
May 02, 2025



The Transformer architecture has shown significant success in many language processing and visual tasks. However, the method faces challenges in efficiently scaling to long sequences because the self-attention computation is quadratic with respect to the input length. To overcome this limitation, several approaches scale to longer sequences by breaking long sequences into a series of segments, restricting self-attention to local dependencies between tokens within each segment and using a memory mechanism to manage information flow between segments. However, these approached generally introduce additional compute overhead that restricts them from being used for applications where limited compute memory and power are of great concern (such as edge computing). We propose a novel and efficient Compact Recurrent Transformer (CRT), which combines shallow Transformer models that process short local segments with recurrent neural networks to compress and manage a single persistent memory vector that summarizes long-range global information between segments. We evaluate CRT on WordPTB and WikiText-103 for next-token-prediction tasks, as well as on the Toyota Smarthome video dataset for classification. CRT achieves comparable or superior prediction results to full-length Transformers in the language datasets while using significantly shorter segments (half or quarter size) and substantially reduced FLOPs. Our approach also demonstrates state-of-the-art performance on the Toyota Smarthome video dataset.
AM Flow: Adapters for Temporal Processing in Action Recognition
Nov 04, 2024



Deep learning models, in particular \textit{image} models, have recently gained generalisability and robustness. %are becoming more general and robust by the day. In this work, we propose to exploit such advances in the realm of \textit{video} classification. Video foundation models suffer from the requirement of extensive pretraining and a large training time. Towards mitigating such limitations, we propose "\textit{Attention Map (AM) Flow}" for image models, a method for identifying pixels relevant to motion in each input video frame. In this context, we propose two methods to compute AM flow, depending on camera motion. AM flow allows the separation of spatial and temporal processing, while providing improved results over combined spatio-temporal processing (as in video models). Adapters, one of the popular techniques in parameter efficient transfer learning, facilitate the incorporation of AM flow into pretrained image models, mitigating the need for full-finetuning. We extend adapters to "\textit{temporal processing adapters}" by incorporating a temporal processing unit into the adapters. Our work achieves faster convergence, therefore reducing the number of epochs needed for training. Moreover, we endow an image model with the ability to achieve state-of-the-art results on popular action recognition datasets. This reduces training time and simplifies pretraining. We present experiments on Kinetics-400, Something-Something v2, and Toyota Smarthome datasets, showcasing state-of-the-art or comparable results.
Are Visual-Language Models Effective in Action Recognition? A Comparative Study
Oct 22, 2024



Current vision-language foundation models, such as CLIP, have recently shown significant improvement in performance across various downstream tasks. However, whether such foundation models significantly improve more complex fine-grained action recognition tasks is still an open question. To answer this question and better find out the future research direction on human behavior analysis in-the-wild, this paper provides a large-scale study and insight on current state-of-the-art vision foundation models by comparing their transfer ability onto zero-shot and frame-wise action recognition tasks. Extensive experiments are conducted on recent fine-grained, human-centric action recognition datasets (e.g., Toyota Smarthome, Penn Action, UAV-Human, TSU, Charades) including action classification and segmentation.
Enhancing Action Recognition by Leveraging the Hierarchical Structure of Actions and Textual Context
Oct 28, 2024



The sequential execution of actions and their hierarchical structure consisting of different levels of abstraction, provide features that remain unexplored in the task of action recognition. In this study, we present a novel approach to improve action recognition by exploiting the hierarchical organization of actions and by incorporating contextualized textual information, including location and prior actions to reflect the sequential context. To achieve this goal, we introduce a novel transformer architecture tailored for action recognition that utilizes both visual and textual features. Visual features are obtained from RGB and optical flow data, while text embeddings represent contextual information. Furthermore, we define a joint loss function to simultaneously train the model for both coarse and fine-grained action recognition, thereby exploiting the hierarchical nature of actions. To demonstrate the effectiveness of our method, we extend the Toyota Smarthome Untrimmed (TSU) dataset to introduce action hierarchies, introducing the Hierarchical TSU dataset. We also conduct an ablation study to assess the impact of different methods for integrating contextual and hierarchical data on action recognition performance. Results show that the proposed approach outperforms pre-trained SOTA methods when trained with the same hyperparameters. Moreover, they also show a 17.12% improvement in top-1 accuracy over the equivalent fine-grained RGB version when using ground-truth contextual information, and a 5.33% improvement when contextual information is obtained from actual predictions.
AAN: Attributes-Aware Network for Temporal Action Detection
Sep 01, 2023



The challenge of long-term video understanding remains constrained by the efficient extraction of object semantics and the modelling of their relationships for downstream tasks. Although the CLIP visual features exhibit discriminative properties for various vision tasks, particularly in object encoding, they are suboptimal for long-term video understanding. To address this issue, we present the Attributes-Aware Network (AAN), which consists of two key components: the Attributes Extractor and a Graph Reasoning block. These components facilitate the extraction of object-centric attributes and the modelling of their relationships within the video. By leveraging CLIP features, AAN outperforms state-of-the-art approaches on two popular action detection datasets: Charades and Toyota Smarthome Untrimmed datasets.
Self-Supervised Video Representation Learning via Latent Time Navigation
May 10, 2023



Self-supervised video representation learning aimed at maximizing similarity between different temporal segments of one video, in order to enforce feature persistence over time. This leads to loss of pertinent information related to temporal relationships, rendering actions such as `enter' and `leave' to be indistinguishable. To mitigate this limitation, we propose Latent Time Navigation (LTN), a time-parameterized contrastive learning strategy that is streamlined to capture fine-grained motions. Specifically, we maximize the representation similarity between different video segments from one video, while maintaining their representations time-aware along a subspace of the latent representation code including an orthogonal basis to represent temporal changes. Our extensive experimental analysis suggests that learning video representations by LTN consistently improves performance of action classification in fine-grained and human-oriented tasks (e.g., on Toyota Smarthome dataset). In addition, we demonstrate that our proposed model, when pre-trained on Kinetics-400, generalizes well onto the unseen real world video benchmark datasets UCF101 and HMDB51, achieving state-of-the-art performance in action recognition.
DG-STGCN: Dynamic Spatial-Temporal Modeling for Skeleton-based Action Recognition
Oct 12, 2022
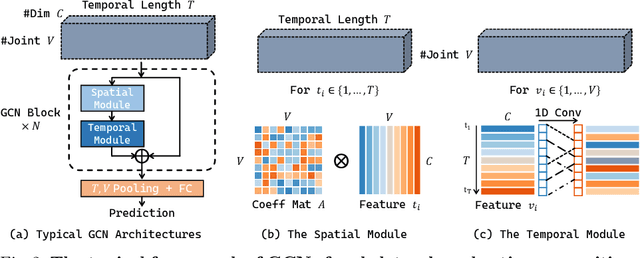
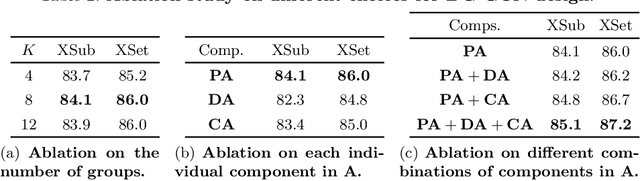
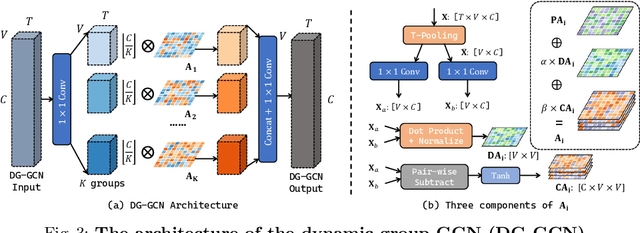
Graph convolution networks (GCN) have been widely used in skeleton-based action recognition. We note that existing GCN-based approaches primarily rely on prescribed graphical structures (ie., a manually defined topology of skeleton joints), which limits their flexibility to capture complicated correlations between joints. To move beyond this limitation, we propose a new framework for skeleton-based action recognition, namely Dynamic Group Spatio-Temporal GCN (DG-STGCN). It consists of two modules, DG-GCN and DG-TCN, respectively, for spatial and temporal modeling. In particular, DG-GCN uses learned affinity matrices to capture dynamic graphical structures instead of relying on a prescribed one, while DG-TCN performs group-wise temporal convolutions with varying receptive fields and incorporates a dynamic joint-skeleton fusion module for adaptive multi-level temporal modeling. On a wide range of benchmarks, including NTURGB+D, Kinetics-Skeleton, BABEL, and Toyota SmartHome, DG-STGCN consistently outperforms state-of-the-art methods, often by a notable margin.
UNIK: A Unified Framework for Real-world Skeleton-based Action Recognition
Jul 19, 2021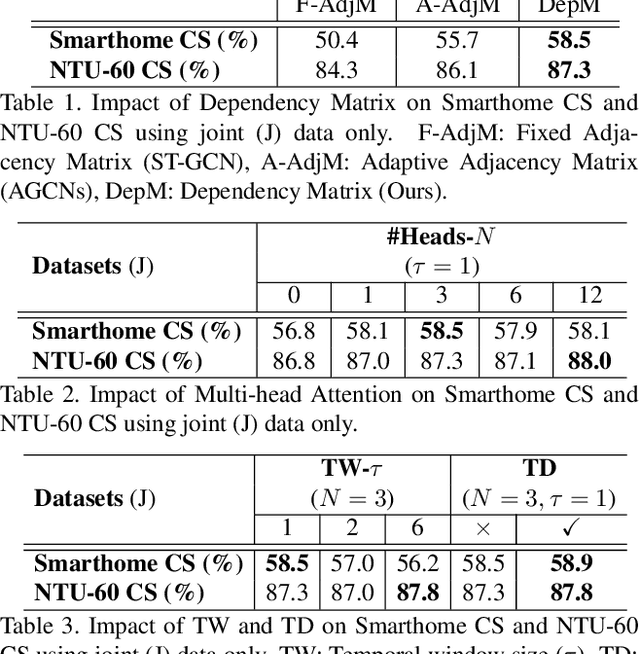
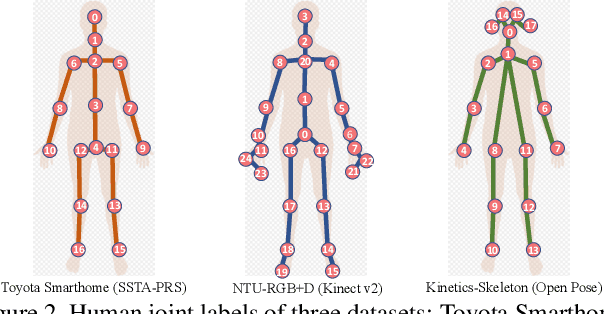
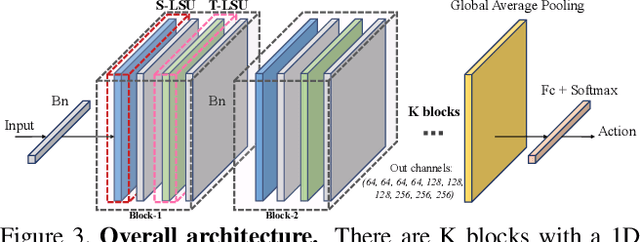
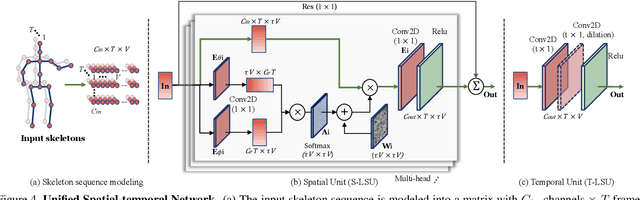
Action recognition based on skeleton data has recently witnessed increasing attention and progress. State-of-the-art approaches adopting Graph Convolutional networks (GCNs) can effectively extract features on human skeletons relying on the pre-defined human topology. Despite associated progress, GCN-based methods have difficulties to generalize across domains, especially with different human topological structures. In this context, we introduce UNIK, a novel skeleton-based action recognition method that is not only effective to learn spatio-temporal features on human skeleton sequences but also able to generalize across datasets. This is achieved by learning an optimal dependency matrix from the uniform distribution based on a multi-head attention mechanism. Subsequently, to study the cross-domain generalizability of skeleton-based action recognition in real-world videos, we re-evaluate state-of-the-art approaches as well as the proposed UNIK in light of a novel Posetics dataset. This dataset is created from Kinetics-400 videos by estimating, refining and filtering poses. We provide an analysis on how much performance improves on smaller benchmark datasets after pre-training on Posetics for the action classification task. Experimental results show that the proposed UNIK, with pre-training on Posetics, generalizes well and outperforms state-of-the-art when transferred onto four target action classification datasets: Toyota Smarthome, Penn Action, NTU-RGB+D 60 and NTU-RGB+D 120.
Toyota Smarthome Untrimmed: Real-World Untrimmed Videos for Activity Detection
Oct 28, 2020
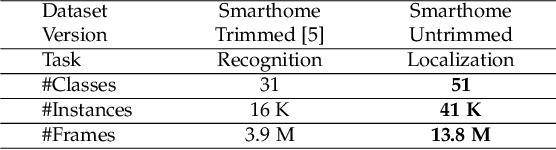
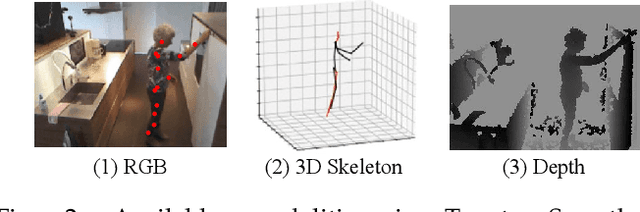
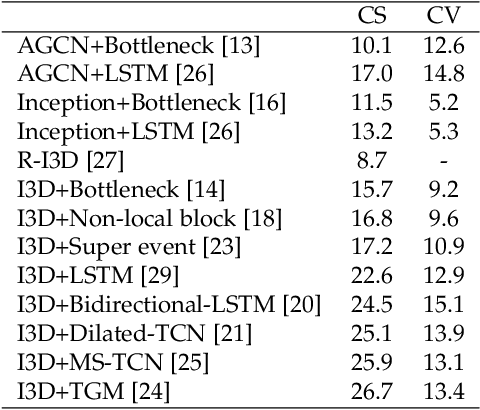
This work aims at building a large scale dataset with daily-living activities performed in a natural manner. Activities performed in a spontaneous manner lead to many real-world challenges that are often ignored by the vision community. This includes low inter-class due to the presence of similar activities and high intra-class variance, low camera framing, low resolution, long-tail distribution of activities, and occlusions. To this end, we propose the Toyota Smarthome Untrimmed (TSU) dataset, which provides spontaneous activities with rich and dense annotations to address the detection of complex activities in real-world scenarios.