 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoccernet V2
Papers and Code
Unifying Global and Local Scene Entities Modelling for Precise Action Spotting
Apr 15, 2024



Sports videos pose complex challenges, including cluttered backgrounds, camera angle changes, small action-representing objects, and imbalanced action class distribution. Existing methods for detecting actions in sports videos heavily rely on global features, utilizing a backbone network as a black box that encompasses the entire spatial frame. However, these approaches tend to overlook the nuances of the scene and struggle with detecting actions that occupy a small portion of the frame. In particular, they face difficulties when dealing with action classes involving small objects, such as balls or yellow/red cards in soccer, which only occupy a fraction of the screen space. To address these challenges, we introduce a novel approach that analyzes and models scene entities using an adaptive attention mechanism. Particularly, our model disentangles the scene content into the global environment feature and local relevant scene entities feature. To efficiently extract environmental features while considering temporal information with less computational cost, we propose the use of a 2D backbone network with a time-shift mechanism. To accurately capture relevant scene entities, we employ a Vision-Language model in conjunction with the adaptive attention mechanism. Our model has demonstrated outstanding performance, securing the 1st place in the SoccerNet-v2 Action Spotting, FineDiving, and FineGym challenge with a substantial performance improvement of 1.6, 2.0, and 1.3 points in avg-mAP compared to the runner-up methods. Furthermore, our approach offers interpretability capabilities in contrast to other deep learning models, which are often designed as black boxes. Our code and models are released at: https://github.com/Fsoft-AIC/unifying-global-local-feature.
COMEDIAN: Self-Supervised Learning and Knowledge Distillation for Action Spotting using Transformers
Sep 03, 2023



We present COMEDIAN, a novel pipeline to initialize spatio-temporal transformers for action spotting, which involves self-supervised learning and knowledge distillation. Action spotting is a timestamp-level temporal action detection task. Our pipeline consists of three steps, with two initialization stages. First, we perform self-supervised initialization of a spatial transformer using short videos as input. Additionally, we initialize a temporal transformer that enhances the spatial transformer's outputs with global context through knowledge distillation from a pre-computed feature bank aligned with each short video segment. In the final step, we fine-tune the transformers to the action spotting task. The experiments, conducted on the SoccerNet-v2 dataset, demonstrate state-of-the-art performance and validate the effectiveness of COMEDIAN's pretraining paradigm. Our results highlight several advantages of our pretraining pipeline, including improved performance and faster convergence compared to non-pretrained models.
Towards Active Learning for Action Spotting in Association Football Videos
Apr 09, 2023



Association football is a complex and dynamic sport, with numerous actions occurring simultaneously in each game. Analyzing football videos is challenging and requires identifying subtle and diverse spatio-temporal patterns. Despite recent advances in computer vision, current algorithms still face significant challenges when learning from limited annotated data, lowering their performance in detecting these patterns. In this paper, we propose an active learning framework that selects the most informative video samples to be annotated next, thus drastically reducing the annotation effort and accelerating the training of action spotting models to reach the highest accuracy at a faster pace. Our approach leverages the notion of uncertainty sampling to select the most challenging video clips to train on next, hastening the learning process of the algorithm. We demonstrate that our proposed active learning framework effectively reduces the required training data for accurate action spotting in football videos. We achieve similar performances for action spotting with NetVLAD++ on SoccerNet-v2, using only one-third of the dataset, indicating significant capabilities for reducing annotation time and improving data efficiency. We further validate our approach on two new datasets that focus on temporally localizing actions of headers and passes, proving its effectiveness across different action semantics in football. We believe our active learning framework for action spotting would support further applications of action spotting algorithms and accelerate annotation campaigns in the sports domain.
Temporally Precise Action Spotting in Soccer Videos Using Dense Detection Anchors
May 20, 2022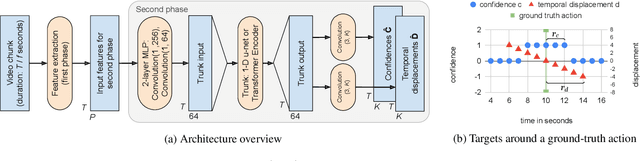
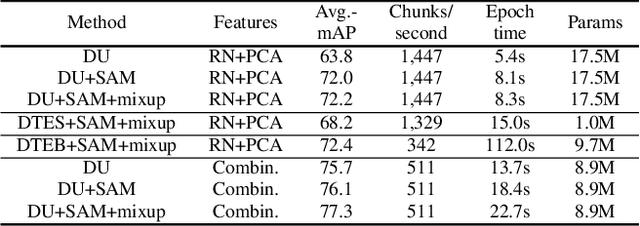
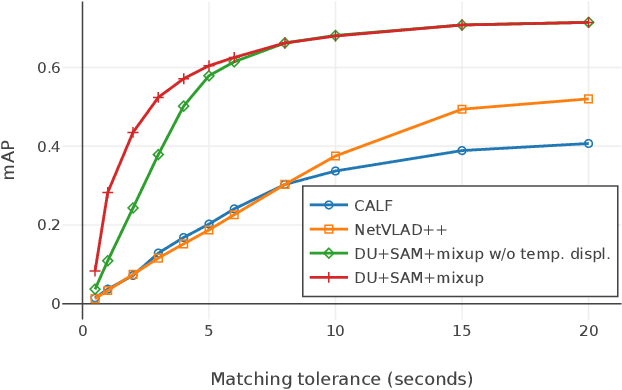
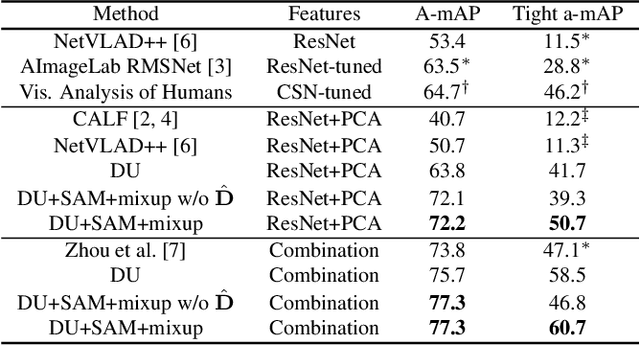
We present a model for temporally precise action spotting in videos, which uses a dense set of detection anchors, predicting a detection confidence and corresponding fine-grained temporal displacement for each anchor. We experiment with two trunk architectures, both of which are able to incorporate large temporal contexts while preserving the smaller-scale features required for precise localization: a one-dimensional version of a u-net, and a Transformer encoder (TE). We also suggest best practices for training models of this kind, by applying Sharpness-Aware Minimization (SAM) and mixup data augmentation. We achieve a new state-of-the-art on SoccerNet-v2, the largest soccer video dataset of its kind, with marked improvements in temporal localization. Additionally, our ablations show: the importance of predicting the temporal displacements; the trade-offs between the u-net and TE trunks; and the benefits of training with SAM and mixup.
Camera Calibration and Player Localization in SoccerNet-v2 and Investigation of their Representations for Action Spotting
Apr 19, 2021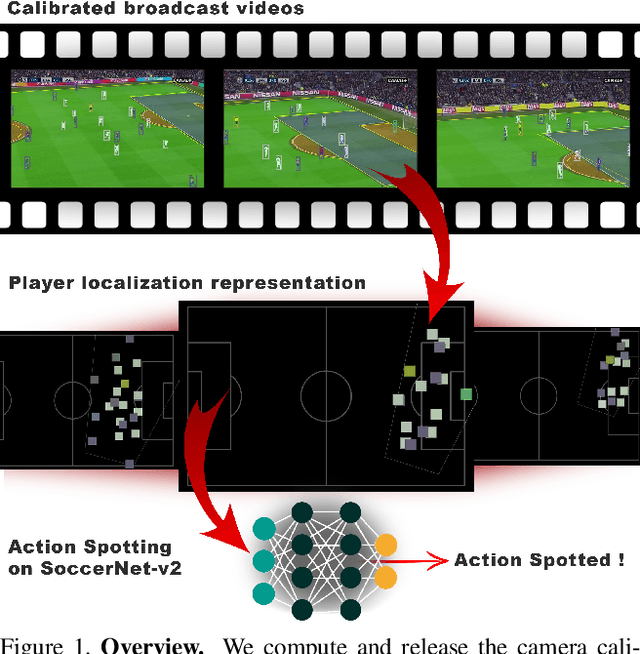
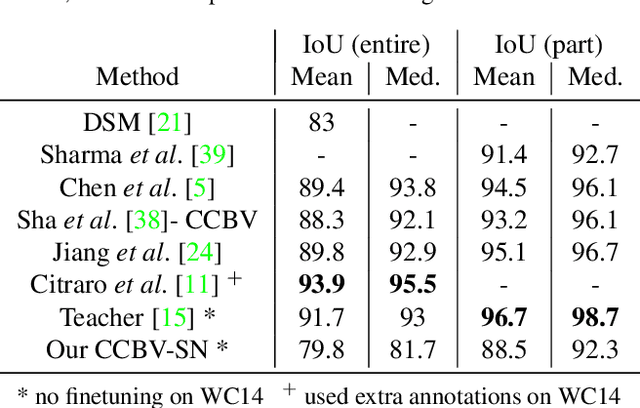
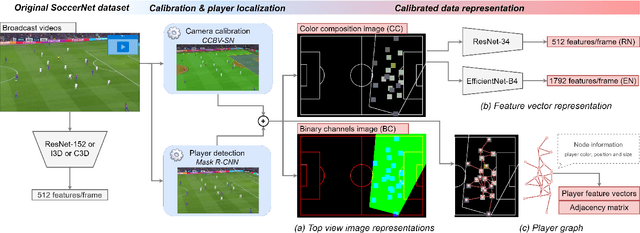
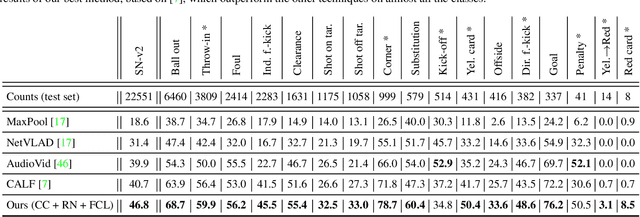
Soccer broadcast video understanding has been drawing a lot of attention in recent years within data scientists and industrial companies. This is mainly due to the lucrative potential unlocked by effective deep learning techniques developed in the field of computer vision. In this work, we focus on the topic of camera calibration and on its current limitations for the scientific community. More precisely, we tackle the absence of a large-scale calibration dataset and of a public calibration network trained on such a dataset. Specifically, we distill a powerful commercial calibration tool in a recent neural network architecture on the large-scale SoccerNet dataset, composed of untrimmed broadcast videos of 500 soccer games. We further release our distilled network, and leverage it to provide 3 ways of representing the calibration results along with player localization. Finally, we exploit those representations within the current best architecture for the action spotting task of SoccerNet-v2, and achieve new state-of-the-art performances.
Feature Combination Meets Attention: Baidu Soccer Embeddings and Transformer based Temporal Detection
Jun 28, 2021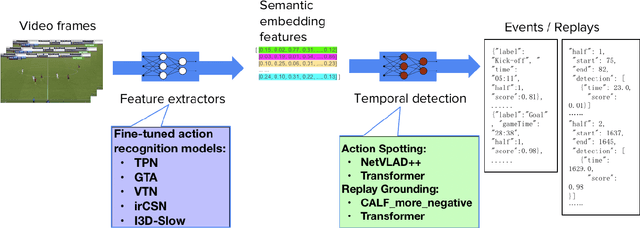
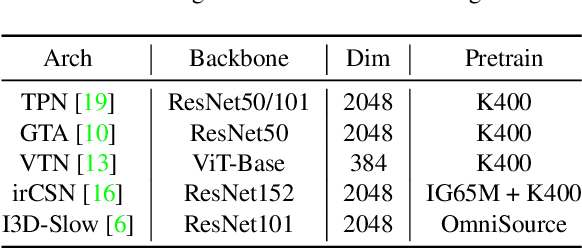
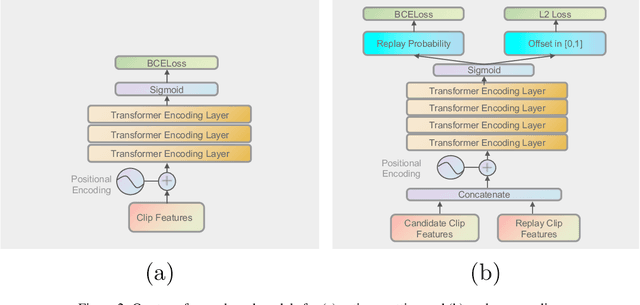
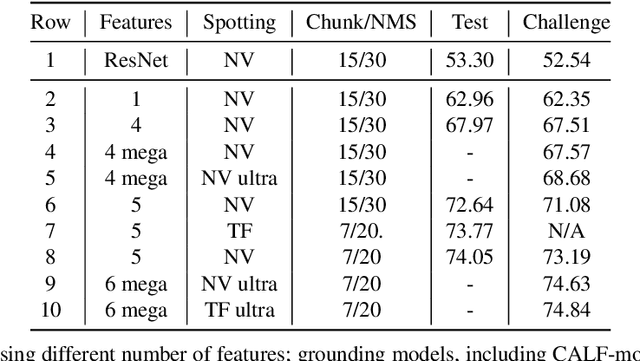
With rapidly evolving internet technologies and emerging tools, sports related videos generated online are increasing at an unprecedentedly fast pace. To automate sports video editing/highlight generation process, a key task is to precisely recognize and locate the events in the long untrimmed videos. In this tech report, we present a two-stage paradigm to detect what and when events happen in soccer broadcast videos. Specifically, we fine-tune multiple action recognition models on soccer data to extract high-level semantic features, and design a transformer based temporal detection module to locate the target events. This approach achieved the state-of-the-art performance in both two tasks, i.e., action spotting and replay grounding, in the SoccerNet-v2 Challenge, under CVPR 2021 ActivityNet workshop. Our soccer embedding features are released at https://github.com/baidu-research/vidpress-sports. By sharing these features with the broader community, we hope to accelerate the research into soccer video understanding.
SoccerNet-v2 : A Dataset and Benchmarks for Holistic Understanding of Broadcast Soccer Videos
Nov 26, 2020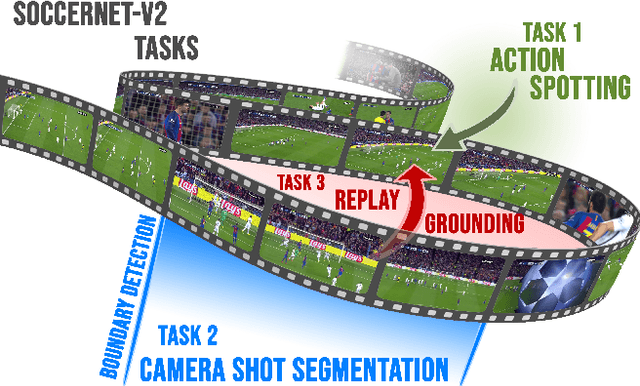
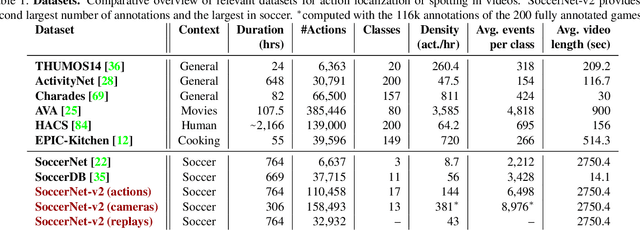
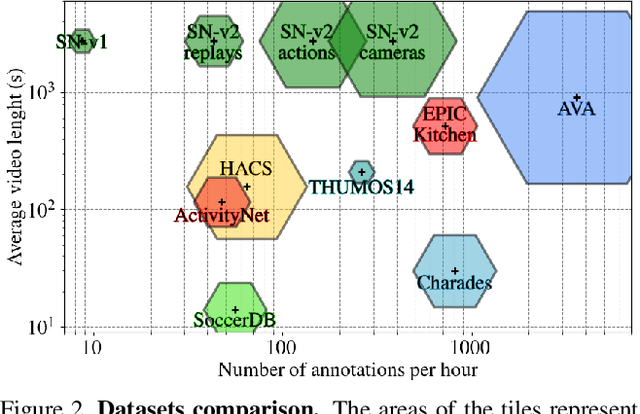
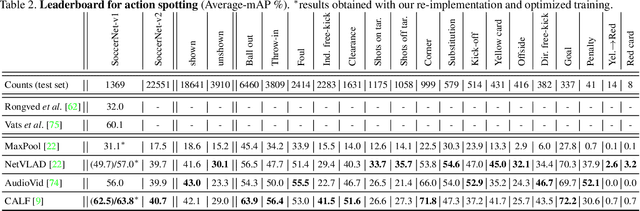
Understanding broadcast videos is a challenging task in computer vision, as it requires generic reasoning capabilities to appreciate the content offered by the video editing. In this work, we propose SoccerNet-v2, a novel large-scale corpus of manual annotations for the SoccerNet video dataset, along with open challenges to encourage more research in soccer understanding and broadcast production. Specifically, we release around 300k annotations within SoccerNet's 500 untrimmed broadcast soccer videos. We extend current tasks in the realm of soccer to include action spotting, camera shot segmentation with boundary detection, and we define a novel replay grounding task. For each task, we provide and discuss benchmark results, reproducible with our open-source adapted implementations of the most relevant works in the field. SoccerNet-v2 is presented to the broader research community to help push computer vision closer to automatic solutions for more general video understanding and production purposes.
Temporally-Aware Feature Pooling for Action Spotting in Soccer Broadcasts
Apr 14, 2021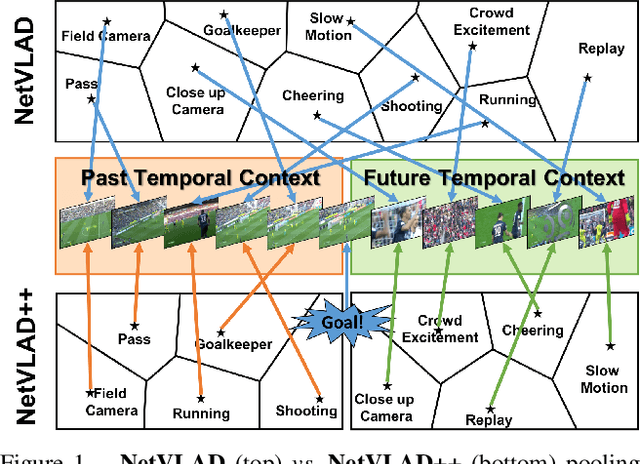

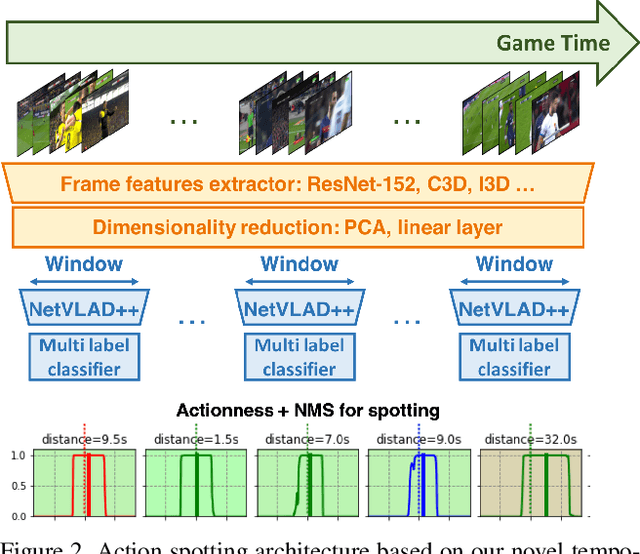
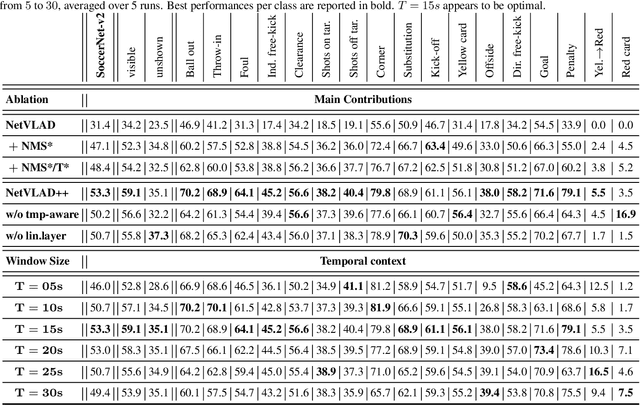
Toward the goal of automatic production for sports broadcasts, a paramount task consists in understanding the high-level semantic information of the game in play. For instance, recognizing and localizing the main actions of the game would allow producers to adapt and automatize the broadcast production, focusing on the important details of the game and maximizing the spectator engagement. In this paper, we focus our analysis on action spotting in soccer broadcast, which consists in temporally localizing the main actions in a soccer game. To that end, we propose a novel feature pooling method based on NetVLAD, dubbed NetVLAD++, that embeds temporally-aware knowledge. Different from previous pooling methods that consider the temporal context as a single set to pool from, we split the context before and after an action occurs. We argue that considering the contextual information around the action spot as a single entity leads to a sub-optimal learning for the pooling module. With NetVLAD++, we disentangle the context from the past and future frames and learn specific vocabularies of semantics for each subsets, avoiding to blend and blur such vocabulary in time. Injecting such prior knowledge creates more informative pooling modules and more discriminative pooled features, leading into a better understanding of the actions. We train and evaluate our methodology on the recent large-scale dataset SoccerNet-v2, reaching 53.4% Average-mAP for action spotting, a +12.7% improvement w.r.t the current state-of-the-art.