 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantization-Aware Distillation for NVFP4 Inference Accuracy Recovery
Jan 27, 2026This technical report presents quantization-aware distillation (QAD) and our best practices for recovering accuracy of NVFP4-quantized large language models (LLMs) and vision-language models (VLMs). QAD distills a full-precision teacher model into a quantized student model using a KL divergence loss. While applying distillation to quantized models is not a new idea, we observe key advantages of QAD for today's LLMs: 1. It shows remarkable effectiveness and stability for models trained through multi-stage post-training pipelines, including supervised fine-tuning (SFT), reinforcement learning (RL), and model merging, where traditional quantization-aware training (QAT) suffers from engineering complexity and training instability; 2. It is robust to data quality and coverage, enabling accuracy recovery without full training data. We evaluate QAD across multiple post-trained models including AceReason Nemotron, Nemotron 3 Nano, Nemotron Nano V2, Nemotron Nano V2 VL (VLM), and Llama Nemotron Super v1, showing consistent recovery to near-BF16 accuracy.
NVIDIA Nemotron Nano V2 VL
Nov 07, 2025We introduce Nemotron Nano V2 VL, the latest model of the Nemotron vision-language series designed for strong real-world document understanding, long video comprehension, and reasoning tasks. Nemotron Nano V2 VL delivers significant improvements over our previous model, Llama-3.1-Nemotron-Nano-VL-8B, across all vision and text domains through major enhancements in model architecture, datasets, and training recipes. Nemotron Nano V2 VL builds on Nemotron Nano V2, a hybrid Mamba-Transformer LLM, and innovative token reduction techniques to achieve higher inference throughput in long document and video scenarios. We are releasing model checkpoints in BF16, FP8, and FP4 formats and sharing large parts of our datasets, recipes and training code.
CRoP: Context-wise Robust Static Human-Sensing Personalization
Sep 26, 2024



The advancement in deep learning and internet-of-things have led to diverse human sensing applications. However, distinct patterns in human sensing, influenced by various factors or contexts, challenge generic neural network model's performance due to natural distribution shifts. To address this, personalization tailors models to individual users. Yet most personalization studies overlook intra-user heterogeneity across contexts in sensory data, limiting intra-user generalizability. This limitation is especially critical in clinical applications, where limited data availability hampers both generalizability and personalization. Notably, intra-user sensing attributes are expected to change due to external factors such as treatment progression, further complicating the challenges.This work introduces CRoP, a novel static personalization approach using an off-the-shelf pre-trained model and pruning to optimize personalization and generalization. CRoP shows superior personalization effectiveness and intra-user robustness across four human-sensing datasets, including two from real-world health domains, highlighting its practical and social impact. Additionally, to support CRoP's generalization ability and design choices, we provide empirical justification through gradient inner product analysis, ablation studies, and comparisons against state-of-the-art baselines.
Feature Combination Meets Attention: Baidu Soccer Embeddings and Transformer based Temporal Detection
Jun 28, 2021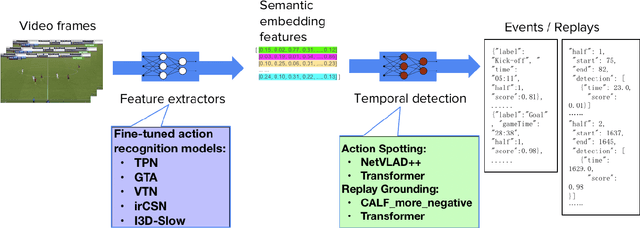
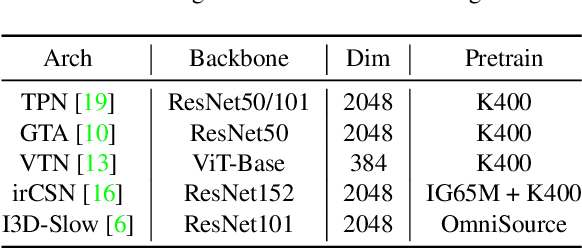
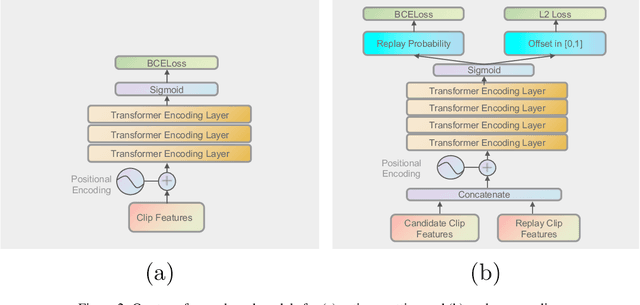
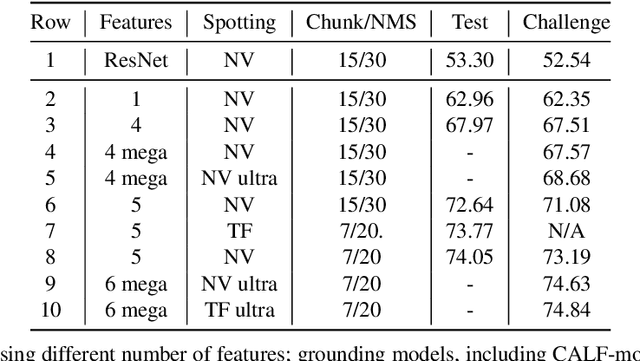
With rapidly evolving internet technologies and emerging tools, sports related videos generated online are increasing at an unprecedentedly fast pace. To automate sports video editing/highlight generation process, a key task is to precisely recognize and locate the events in the long untrimmed videos. In this tech report, we present a two-stage paradigm to detect what and when events happen in soccer broadcast videos. Specifically, we fine-tune multiple action recognition models on soccer data to extract high-level semantic features, and design a transformer based temporal detection module to locate the target events. This approach achieved the state-of-the-art performance in both two tasks, i.e., action spotting and replay grounding, in the SoccerNet-v2 Challenge, under CVPR 2021 ActivityNet workshop. Our soccer embedding features are released at https://github.com/baidu-research/vidpress-sports. By sharing these features with the broader community, we hope to accelerate the research into soccer video understanding.