 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoccerNet 2022 Challenges Results
Oct 05, 2022
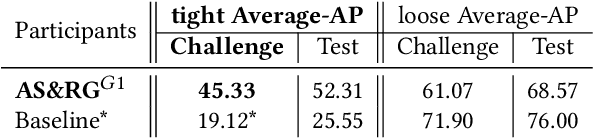
The SoccerNet 2022 challenges were the second annual video understanding challenges organized by the SoccerNet team. In 2022, the challenges were composed of 6 vision-based tasks: (1) action spotting, focusing on retrieving action timestamps in long untrimmed videos, (2) replay grounding, focusing on retrieving the live moment of an action shown in a replay, (3) pitch localization, focusing on detecting line and goal part elements, (4) camera calibration, dedicated to retrieving the intrinsic and extrinsic camera parameters, (5) player re-identification, focusing on retrieving the same players across multiple views, and (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams. Compared to last year's challenges, tasks (1-2) had their evaluation metrics redefined to consider tighter temporal accuracies, and tasks (3-6) were novel, including their underlying data and annotations. More information on the tasks, challenges and leaderboards are available on https://www.soccer-net.org. Baselines and development kits are available on https://github.com/SoccerNet.
Action Spotting using Dense Detection Anchors Revisited: Submission to the SoccerNet Challenge 2022
Jun 15, 2022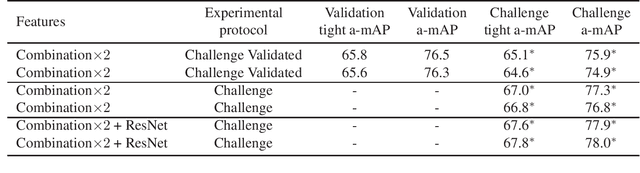
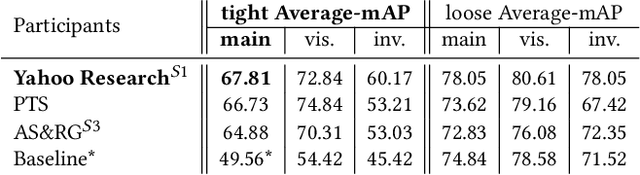
This technical report describes our submission to the Action Spotting SoccerNet Challenge 2022. The challenge is part of the CVPR 2022 ActivityNet Workshop. Our submission is based on a method that we proposed recently, which focuses on increasing temporal precision via a densely sampled set of detection anchors. Due to its emphasis on temporal precision, this approach is able to produce competitive results on the tight average-mAP metric, which uses small temporal evaluation tolerances. This recently proposed metric is the evaluation criterion used for the challenge. In order to further improve results, here we introduce small changes in the pre- and post-processing steps, and also combine different input feature types via late fusion. This report describes the resulting overall approach, focusing on the modifications introduced. We also describe the training procedures used, and present our results.
Temporally Precise Action Spotting in Soccer Videos Using Dense Detection Anchors
May 20, 2022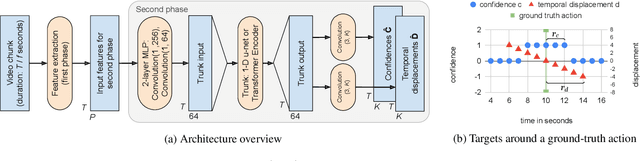
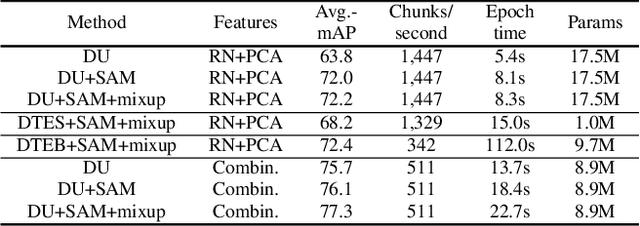
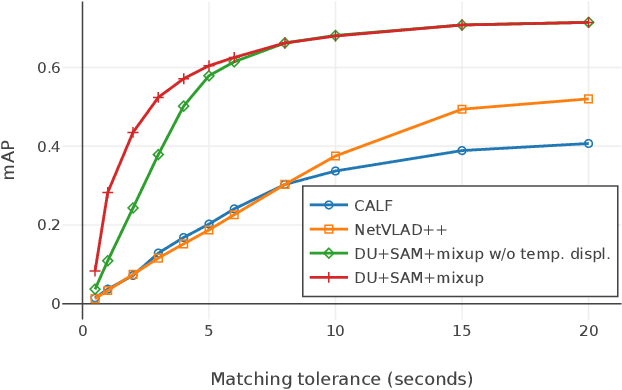
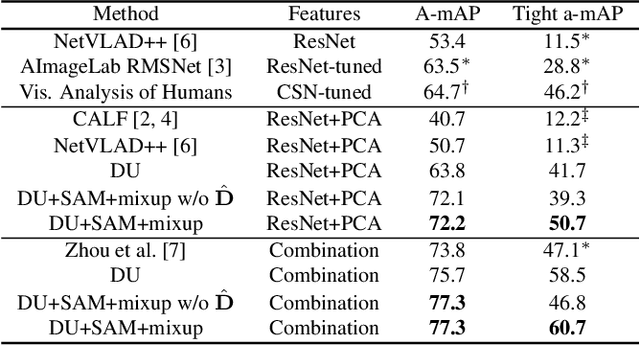
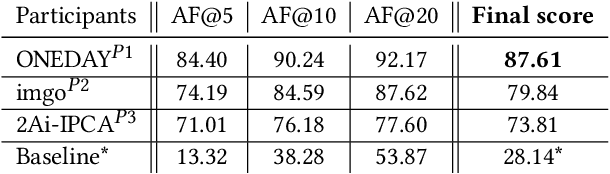
We present a model for temporally precise action spotting in videos, which uses a dense set of detection anchors, predicting a detection confidence and corresponding fine-grained temporal displacement for each anchor. We experiment with two trunk architectures, both of which are able to incorporate large temporal contexts while preserving the smaller-scale features required for precise localization: a one-dimensional version of a u-net, and a Transformer encoder (TE). We also suggest best practices for training models of this kind, by applying Sharpness-Aware Minimization (SAM) and mixup data augmentation. We achieve a new state-of-the-art on SoccerNet-v2, the largest soccer video dataset of its kind, with marked improvements in temporal localization. Additionally, our ablations show: the importance of predicting the temporal displacements; the trade-offs between the u-net and TE trunks; and the benefits of training with SAM and mixup.
Multi-Objective Software Suite of Two-Dimensional Shape Descriptors for Object-Based Image Analysis
Feb 02, 2017
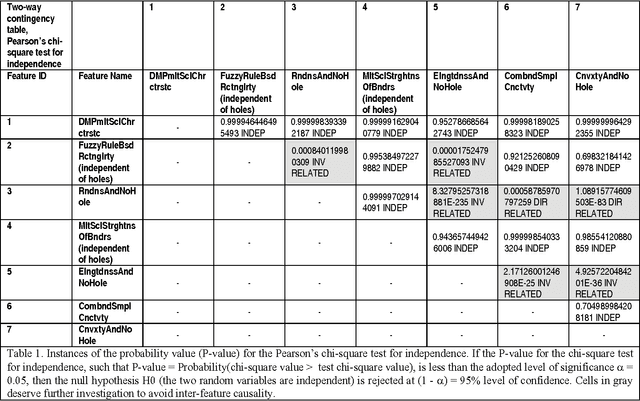
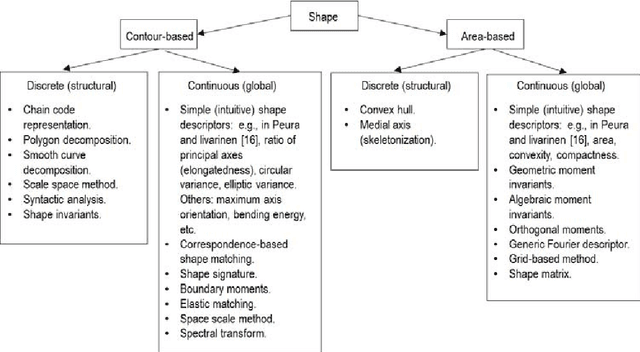
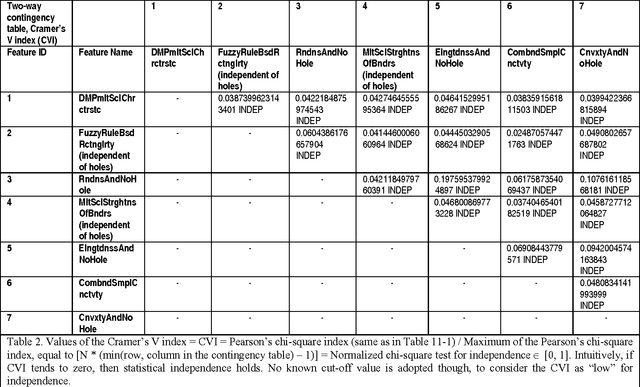
In recent years two sets of planar (2D) shape attributes, provided with an intuitive physical meaning, were proposed to the remote sensing community by, respectively, Nagao & Matsuyama and Shackelford & Davis in their seminal works on the increasingly popular geographic object based image analysis (GEOBIA) paradigm. These two published sets of intuitive geometric features were selected as initial conditions by the present R&D software project, whose multi-objective goal was to accomplish: (i) a minimally dependent and maximally informative design (knowledge/information representation) of a general purpose, user and application independent dictionary of 2D shape terms provided with a physical meaning intuitive to understand by human end users and (ii) an effective (accurate, scale invariant, easy to use) and efficient implementation of 2D shape descriptors. To comply with the Quality Assurance Framework for Earth Observation guidelines, the proposed suite of geometric functions is validated by means of a novel quantitative quality assurance policy, centered on inter feature dependence (causality) assessment. This innovative multivariate feature validation strategy is alternative to traditional feature selection procedures based on either inductive data learning classification accuracy estimation, which is inherently case specific, or cross correlation estimation, because statistical cross correlation does not imply causation. The project deliverable is an original general purpose software suite of seven validated off the shelf 2D shape descriptors intuitive to use. Alternative to existing commercial or open source software libraries of tens of planar shape functions whose informativeness remains unknown, it is eligible for use in (GE)OBIA systems in operating mode, expected to mimic human reasoning based on a convergence of evidence approach.
Retinal Vessel Segmentation Using the 2-D Morlet Wavelet and Supervised Classification
May 11, 2006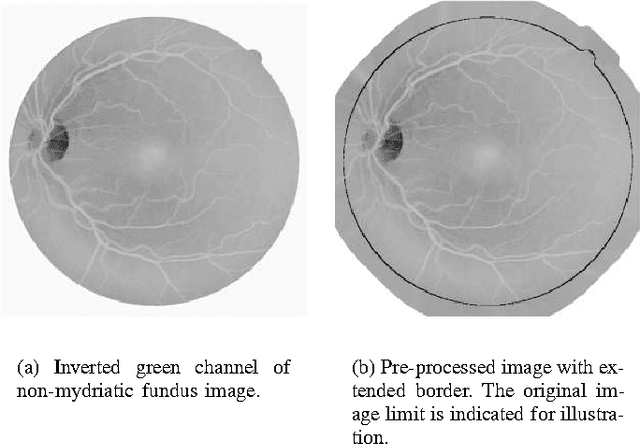

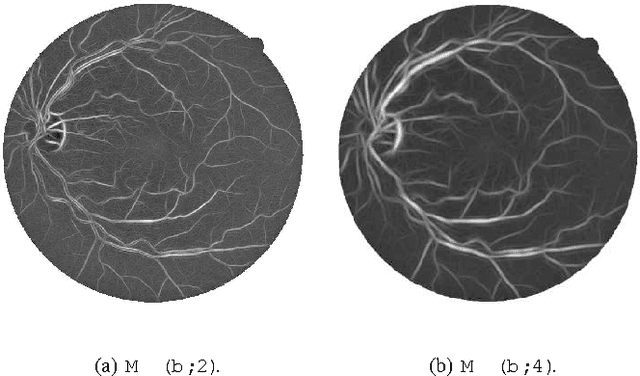
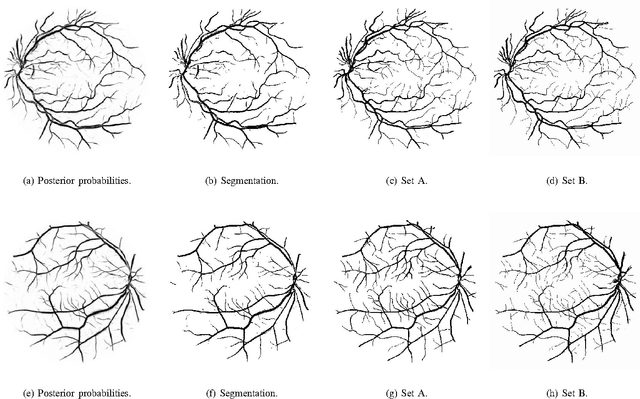
We present a method for automated segmentation of the vasculature in retinal images. The method produces segmentations by classifying each image pixel as vessel or non-vessel, based on the pixel's feature vector. Feature vectors are composed of the pixel's intensity and continuous two-dimensional Morlet wavelet transform responses taken at multiple scales. The Morlet wavelet is capable of tuning to specific frequencies, thus allowing noise filtering and vessel enhancement in a single step. We use a Bayesian classifier with class-conditional probability density functions (likelihoods) described as Gaussian mixtures, yielding a fast classification, while being able to model complex decision surfaces and compare its performance with the linear minimum squared error classifier. The probability distributions are estimated based on a training set of labeled pixels obtained from manual segmentations. The method's performance is evaluated on publicly available DRIVE and STARE databases of manually labeled non-mydriatic images. On the DRIVE database, it achieves an area under the receiver operating characteristic (ROC) curve of 0.9598, being slightly superior than that presented by the method of Staal et al.
* 9 pages, 7 figures and 1 table. Accepted for publication in IEEE Trans Med Imag; added copyright notice