 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoccerNet 2022 Challenges Results
Oct 05, 2022
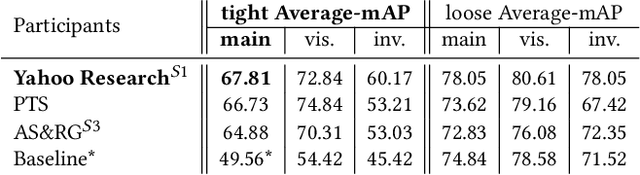
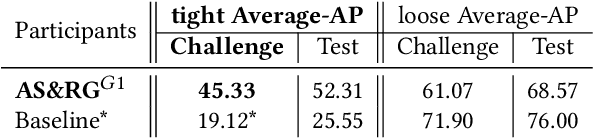
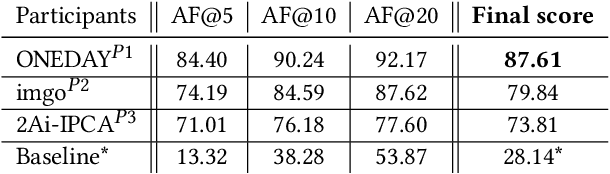
The SoccerNet 2022 challenges were the second annual video understanding challenges organized by the SoccerNet team. In 2022, the challenges were composed of 6 vision-based tasks: (1) action spotting, focusing on retrieving action timestamps in long untrimmed videos, (2) replay grounding, focusing on retrieving the live moment of an action shown in a replay, (3) pitch localization, focusing on detecting line and goal part elements, (4) camera calibration, dedicated to retrieving the intrinsic and extrinsic camera parameters, (5) player re-identification, focusing on retrieving the same players across multiple views, and (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams. Compared to last year's challenges, tasks (1-2) had their evaluation metrics redefined to consider tighter temporal accuracies, and tasks (3-6) were novel, including their underlying data and annotations. More information on the tasks, challenges and leaderboards are available on https://www.soccer-net.org. Baselines and development kits are available on https://github.com/SoccerNet.
Action Spotting using Dense Detection Anchors Revisited: Submission to the SoccerNet Challenge 2022
Jun 15, 2022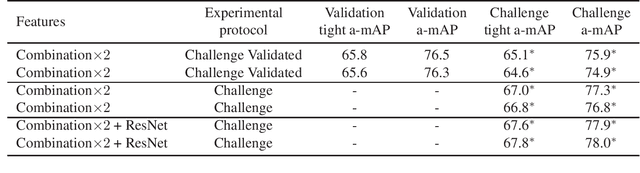
This technical report describes our submission to the Action Spotting SoccerNet Challenge 2022. The challenge is part of the CVPR 2022 ActivityNet Workshop. Our submission is based on a method that we proposed recently, which focuses on increasing temporal precision via a densely sampled set of detection anchors. Due to its emphasis on temporal precision, this approach is able to produce competitive results on the tight average-mAP metric, which uses small temporal evaluation tolerances. This recently proposed metric is the evaluation criterion used for the challenge. In order to further improve results, here we introduce small changes in the pre- and post-processing steps, and also combine different input feature types via late fusion. This report describes the resulting overall approach, focusing on the modifications introduced. We also describe the training procedures used, and present our results.
Temporally Precise Action Spotting in Soccer Videos Using Dense Detection Anchors
May 20, 2022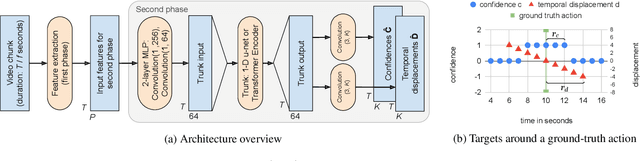
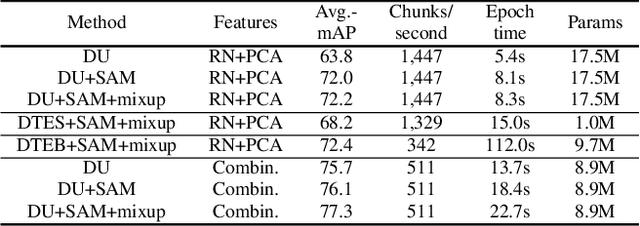
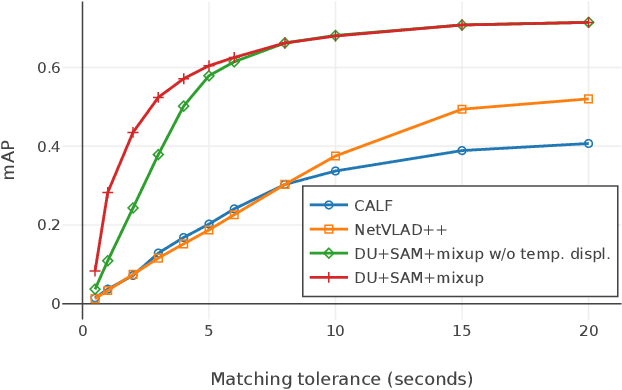
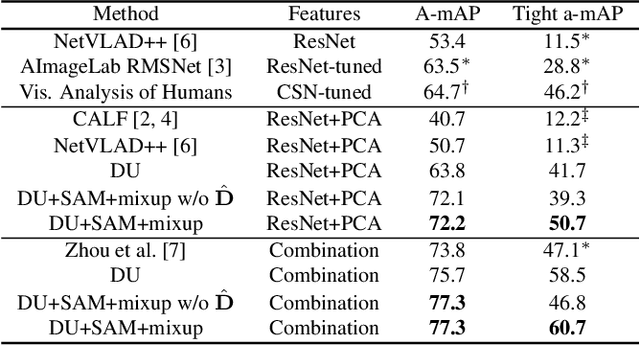
We present a model for temporally precise action spotting in videos, which uses a dense set of detection anchors, predicting a detection confidence and corresponding fine-grained temporal displacement for each anchor. We experiment with two trunk architectures, both of which are able to incorporate large temporal contexts while preserving the smaller-scale features required for precise localization: a one-dimensional version of a u-net, and a Transformer encoder (TE). We also suggest best practices for training models of this kind, by applying Sharpness-Aware Minimization (SAM) and mixup data augmentation. We achieve a new state-of-the-art on SoccerNet-v2, the largest soccer video dataset of its kind, with marked improvements in temporal localization. Additionally, our ablations show: the importance of predicting the temporal displacements; the trade-offs between the u-net and TE trunks; and the benefits of training with SAM and mixup.
Distantly Supervised Semantic Text Detection and Recognition for Broadcast Sports Videos Understanding
Oct 31, 2021
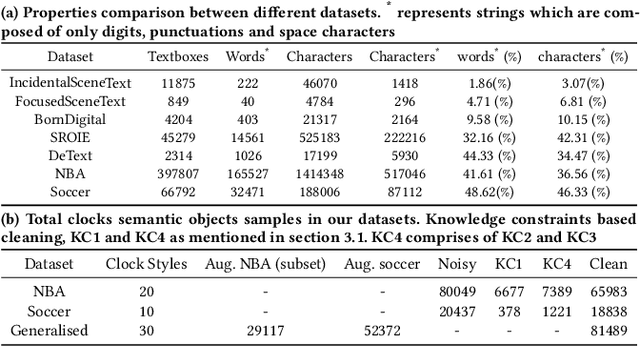
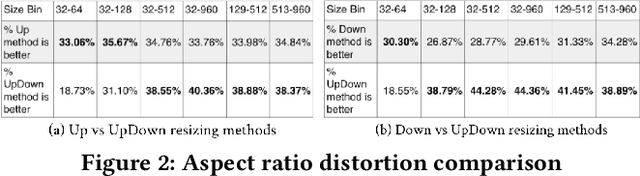
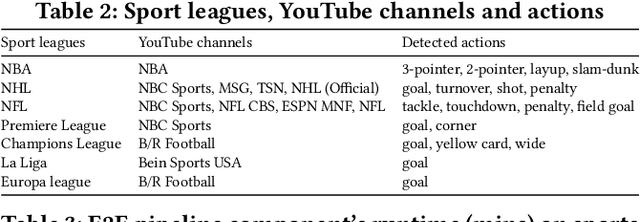
Comprehensive understanding of key players and actions in multiplayer sports broadcast videos is a challenging problem. Unlike in news or finance videos, sports videos have limited text. While both action recognition for multiplayer sports and detection of players has seen robust research, understanding contextual text in video frames still remains one of the most impactful avenues of sports video understanding. In this work we study extremely accurate semantic text detection and recognition in sports clocks, and challenges therein. We observe unique properties of sports clocks, which makes it hard to utilize general-purpose pre-trained detectors and recognizers, so that text can be accurately understood to the degree of being used to align to external knowledge. We propose a novel distant supervision technique to automatically build sports clock datasets. Along with suitable data augmentations, combined with any state-of-the-art text detection and recognition model architectures, we extract extremely accurate semantic text. Finally, we share our computational architecture pipeline to scale this system in industrial setting and proposed a robust dataset for the same to validate our results.