 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSign Language Recognition
Sign language recognition is a computer vision and natural language processing task that involves automatically recognizing and translating sign language gestures into written or spoken language. The goal of sign language recognition is to develop algorithms that can understand and interpret sign language, enabling people who use sign language as their primary mode of communication to communicate more easily with non-signers.
Papers and Code
Arabic Sign Language Recognition using Multimodal Approach
Jan 20, 2026Arabic Sign Language (ArSL) is an essential communication method for individuals in the Deaf and Hard-of-Hearing community. However, existing recognition systems face significant challenges due to their reliance on single sensor approaches like Leap Motion or RGB cameras. These systems struggle with limitations such as inadequate tracking of complex hand orientations and imprecise recognition of 3D hand movements. This research paper aims to investigate the potential of a multimodal approach that combines Leap Motion and RGB camera data to explore the feasibility of recognition of ArSL. The system architecture includes two parallel subnetworks: a custom dense neural network for Leap Motion data, incorporating dropout and L2 regularization, and an image subnetwork based on a fine-tuned VGG16 model enhanced with data augmentation techniques. Feature representations from both modalities are concatenated in a fusion model and passed through fully connected layers, with final classification performed via SoftMax activation to analyze spatial and temporal features of hand gestures. The system was evaluated on a custom dataset comprising 18 ArSL words, of which 13 were correctly recognized, yielding an overall accuracy of 78%. These results offer preliminary insights into the viability of multimodal fusion for sign language recognition and highlight areas for further optimization and dataset expansion.
Deaf and Hard of Hearing Access to Intelligent Personal Assistants: Comparison of Voice-Based Options with an LLM-Powered Touch Interface
Jan 21, 2026We investigate intelligent personal assistants (IPAs) accessibility for deaf and hard of hearing (DHH) people who can use their voice in everyday communication. The inability of IPAs to understand diverse accents including deaf speech renders them largely inaccessible to non-signing and speaking DHH individuals. Using an Echo Show, we compare the usability of natural language input via spoken English; with Alexa's automatic speech recognition and a Wizard-of-Oz setting with a trained facilitator re-speaking commands against that of a large language model (LLM)-assisted touch interface in a mixed-methods study. The touch method was navigated through an LLM-powered "task prompter," which integrated the user's history and smart environment to suggest contextually-appropriate commands. Quantitative results showed no significant differences across both spoken English conditions vs LLM-assisted touch. Qualitative results showed variability in opinions on the usability of each method. Ultimately, it will be necessary to have robust deaf-accented speech recognized natively by IPAs.
VGG Induced Deep Hand Sign Language Detection
Jan 13, 2026Hand gesture recognition is an important aspect of human-computer interaction. It forms the basis of sign language for the visually impaired people. This work proposes a novel hand gesture recognizing system for the differently-abled persons. The model uses a convolutional neural network, known as VGG-16 net, for building a trained model on a widely used image dataset by employing Python and Keras libraries. Furthermore, the result is validated by the NUS dataset, consisting of 10 classes of hand gestures, fed to the model as the validation set. Afterwards, a testing dataset of 10 classes is built by employing Google's open source Application Programming Interface (API) that captures different gestures of human hand and the efficacy is then measured by carrying out experiments. The experimental results show that by combining a transfer learning mechanism together with the image data augmentation, the VGG-16 net produced around 98% accuracy.
Evaluating Human and Machine Confidence in Phishing Email Detection: A Comparative Study
Jan 08, 2026Identifying deceptive content like phishing emails demands sophisticated cognitive processes that combine pattern recognition, confidence assessment, and contextual analysis. This research examines how human cognition and machine learn- ing models work together to distinguish phishing emails from legitimate ones. We employed three interpretable algorithms Logistic Regression, Decision Trees, and Random Forests train- ing them on both TF-IDF features and semantic embeddings, then compared their predictions against human evaluations that captured confidence ratings and linguistic observations. Our results show that machine learning models provide good accuracy rates, but their confidence levels vary significantly. Human evaluators, on the other hand, use a greater variety of language signs and retain more consistent confidence. We also found that while language proficiency has minimal effect on detection performance, aging does. These findings offer helpful direction for creating transparent AI systems that complement human cognitive functions, ultimately improving human-AI cooperation in challenging content analysis tasks.
Sign Language Recognition using Parallel Bidirectional Reservoir Computing
Dec 22, 2025



Sign language recognition (SLR) facilitates communication between deaf and hearing communities. Deep learning based SLR models are commonly used but require extensive computational resources, making them unsuitable for deployment on edge devices. To address these limitations, we propose a lightweight SLR system that combines parallel bidirectional reservoir computing (PBRC) with MediaPipe. MediaPipe enables real-time hand tracking and precise extraction of hand joint coordinates, which serve as input features for the PBRC architecture. The proposed PBRC architecture consists of two echo state network (ESN) based bidirectional reservoir computing (BRC) modules arranged in parallel to capture temporal dependencies, thereby creating a rich feature representation for classification. We trained our PBRC-based SLR system on the Word-Level American Sign Language (WLASL) video dataset, achieving top-1, top-5, and top-10 accuracies of 60.85%, 85.86%, and 91.74%, respectively. Training time was significantly reduced to 18.67 seconds due to the intrinsic properties of reservoir computing, compared to over 55 minutes for deep learning based methods such as Bi-GRU. This approach offers a lightweight, cost-effective solution for real-time SLR on edge devices.
Real-Time American Sign Language Recognition Using 3D Convolutional Neural Networks and LSTM: Architecture, Training, and Deployment
Dec 19, 2025This paper presents a real-time American Sign Language (ASL) recognition system utilizing a hybrid deep learning architecture combining 3D Convolutional Neural Networks (3D CNN) with Long Short-Term Memory (LSTM) networks. The system processes webcam video streams to recognize word-level ASL signs, addressing communication barriers for over 70 million deaf and hard-of-hearing individuals worldwide. Our architecture leverages 3D convolutions to capture spatial-temporal features from video frames, followed by LSTM layers that model sequential dependencies inherent in sign language gestures. Trained on the WLASL dataset (2,000 common words), ASL-LEX lexical database (~2,700 signs), and a curated set of 100 expert-annotated ASL signs, the system achieves F1-scores ranging from 0.71 to 0.99 across sign classes. The model is deployed on AWS infrastructure with edge deployment capability on OAK-D cameras for real-time inference. We discuss the architecture design, training methodology, evaluation metrics, and deployment considerations for practical accessibility applications.
Isolated Sign Language Recognition with Segmentation and Pose Estimation
Dec 16, 2025
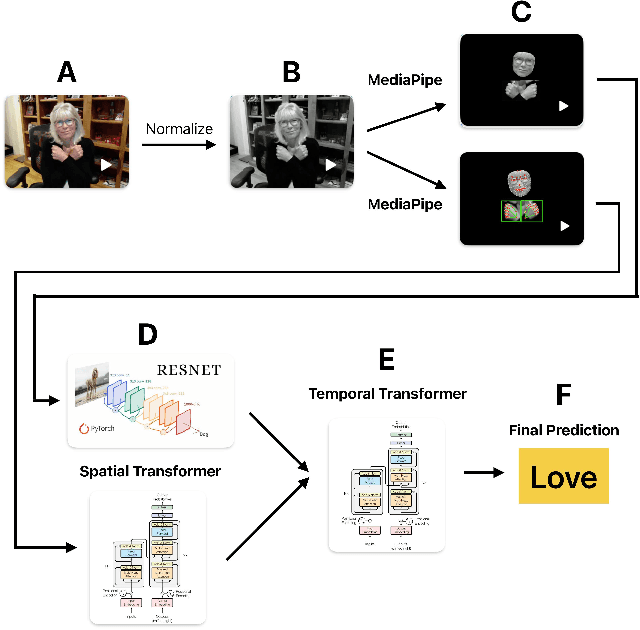
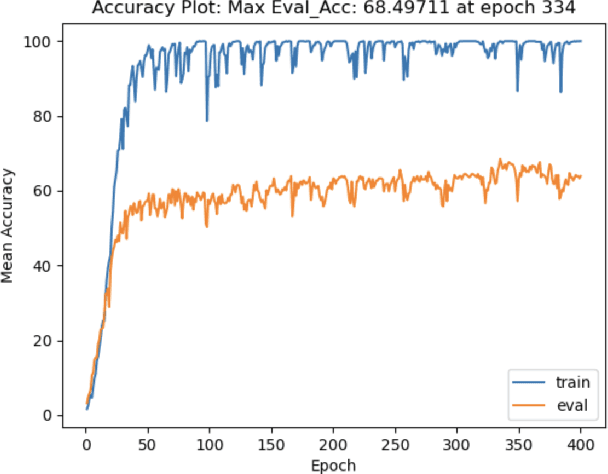
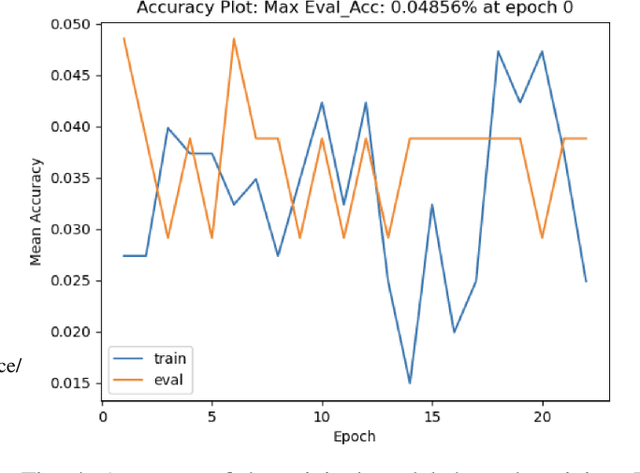
The recent surge in large language models has automated translations of spoken and written languages. However, these advances remain largely inaccessible to American Sign Language (ASL) users, whose language relies on complex visual cues. Isolated sign language recognition (ISLR) - the task of classifying videos of individual signs - can help bridge this gap but is currently limited by scarce per-sign data, high signer variability, and substantial computational costs. We propose a model for ISLR that reduces computational requirements while maintaining robustness to signer variation. Our approach integrates (i) a pose estimation pipeline to extract hand and face joint coordinates, (ii) a segmentation module that isolates relevant information, and (iii) a ResNet-Transformer backbone to jointly model spatial and temporal dependencies.
SignIT: A Comprehensive Dataset and Multimodal Analysis for Italian Sign Language Recognition
Dec 16, 2025In this work we present SignIT, a new dataset to study the task of Italian Sign Language (LIS) recognition. The dataset is composed of 644 videos covering 3.33 hours. We manually annotated videos considering a taxonomy of 94 distinct sign classes belonging to 5 macro-categories: Animals, Food, Colors, Emotions and Family. We also extracted 2D keypoints related to the hands, face and body of the users. With the dataset, we propose a benchmark for the sign recognition task, adopting several state-of-the-art models showing how temporal information, 2D keypoints and RGB frames can be influence the performance of these models. Results show the limitations of these models on this challenging LIS dataset. We release data and annotations at the following link: https://fpv-iplab.github.io/SignIT/.
USTM: Unified Spatial and Temporal Modeling for Continuous Sign Language Recognition
Dec 15, 2025Continuous sign language recognition (CSLR) requires precise spatio-temporal modeling to accurately recognize sequences of gestures in videos. Existing frameworks often rely on CNN-based spatial backbones combined with temporal convolution or recurrent modules. These techniques fail in capturing fine-grained hand and facial cues and modeling long-range temporal dependencies. To address these limitations, we propose the Unified Spatio-Temporal Modeling (USTM) framework, a spatio-temporal encoder that effectively models complex patterns using a combination of a Swin Transformer backbone enhanced with lightweight temporal adapter with positional embeddings (TAPE). Our framework captures fine-grained spatial features alongside short and long-term temporal context, enabling robust sign language recognition from RGB videos without relying on multi-stream inputs or auxiliary modalities. Extensive experiments on benchmarked datasets including PHOENIX14, PHOENIX14T, and CSL-Daily demonstrate that USTM achieves state-of-the-art performance against RGB-based as well as multi-modal CSLR approaches, while maintaining competitive performance against multi-stream approaches. These results highlight the strength and efficacy of the USTM framework for CSLR. The code is available at https://github.com/gufranSabri/USTM
Emotion Recognition in Signers
Dec 17, 2025Recognition of signers' emotions suffers from one theoretical challenge and one practical challenge, namely, the overlap between grammatical and affective facial expressions and the scarcity of data for model training. This paper addresses these two challenges in a cross-lingual setting using our eJSL dataset, a new benchmark dataset for emotion recognition in Japanese Sign Language signers, and BOBSL, a large British Sign Language dataset with subtitles. In eJSL, two signers expressed 78 distinct utterances with each of seven different emotional states, resulting in 1,092 video clips. We empirically demonstrate that 1) textual emotion recognition in spoken language mitigates data scarcity in sign language, 2) temporal segment selection has a significant impact, and 3) incorporating hand motion enhances emotion recognition in signers. Finally we establish a stronger baseline than spoken language LLMs.